大模型检索增强生成RAG的优化
发布时间:2024年06月06日
RAG优化分为两个方向:RAG基础功能优化、RAG架构优化。我们分别展开讨论。
一、RAG基础功能优化
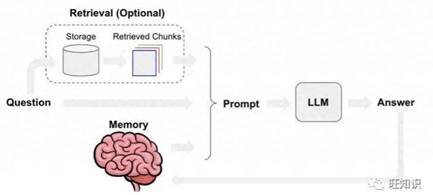
对RAG的基础功能优化,我们要从RAG的流程入手[1],可以在每个阶段做相应的场景优化。
![]()
![]()
![]()
RAG工作流程(with memory)
从RAG的工作流程看,能优化的模块有:文档块切分、文本嵌入模型、提示工程优化、大模型迭代。下面针对每个模块分别做说明(备注:以下内容部分参考了检索增强生成技术(RAG)深度优化指南:原理、挑战、措施、展望)。
·文档块切分:设置适当的块间重叠、多粒度文档块切分、基于语义的文档切分、文档块摘要。
·文本嵌入模型:基于新语料微调嵌入模型、动态表征。
·提示工程优化:优化模板增加提示词约束、提示词改写。
·大模型迭代:基于正反馈微调模型、量化感知训练、提供大context
window的推理模型。
此外,还可对query召回的文档块集合进行处理,比如:元数据过滤[7]、重排序减少文档块数量[2]。
二、RAG架构优化
2.1 Vector+KG RAG
经典的RAG架构中,context增强只用到了向量数据库。这种方法有一些缺点,比如无法获取长程关联知识[3]、信息密度低(尤其当LLM context window较小时不友好)。
![]()
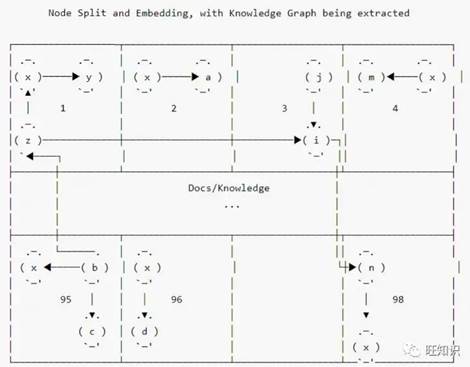
跨chunk的关联知识向量库无法获取
那此题是否可解?答案是肯定的。一个比较好的方案是增加一路与向量库平行的KG(知识图谱)上下文增强策略。其技术架构图大致如下[4]:
![]()
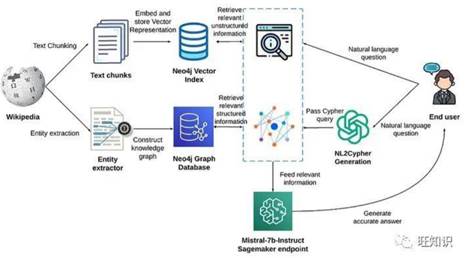
基于KG+VS进行上下文增强
图3中query进行KG增强是通过NL2Cypher模块实现的。根据我的实践,我们可用更简单的图采样技术来进行KG上下文增强。具体流程是:根据query抽取实体,然后把实体作为种子节点对图进行采样(必要时,可把KG中节点和query中实体先向量化,通过向量相似度设置种子节点),然后把获取的子图转换成文本片段,从而达到上下文增强的效果。
LangChain官网提供了一个通过Graph对RAG应用进行增强的DevOps的例子,感兴趣的读者可以详细研究[5]。
2.2 Self-RAG
经典的RAG架构中(包括KG进行上下文增强),对召回的上下文无差别地与query进行合并,然后访问大模型输出应答。但有时召回的上下文可能与query无关或者矛盾,此时就应舍弃这个上下文,尤其当大模型上下文窗口较小时非常必要(目前4k的窗口比较常见)。
那有解决办法吗?答案又是肯定的,一个较好的解决方案是Self-RAG技术。由于篇幅所限,此处介绍其推理过程,训练过程需要借助GPT4进行辅助打标,就不展开说了。详细过程可参考我对Self-RAG的总结[6]。
![]()
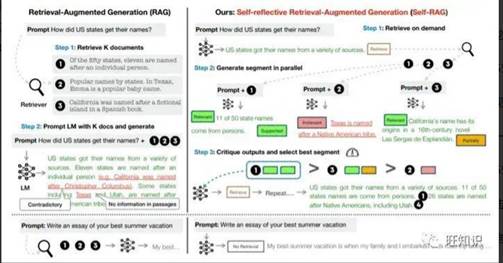
图4
RAG vs Self-RAG
如图4所示,右侧就是Self-RAG的工作流程。首先,根据query判断是否需要检索。如果需要,才检索若干passage,然后经一系列处理生成若干next segment候选。最后,对这些候选segment进行排序,生成最终的next segment。
Self-RAG的推理过程相对训练较简单,其算法内容如下:
![]()

图5
Self-RAG推理算法
2.3 多向量检索器多模态RAG
本小节涉及三种工作模式[7],具体为:
·半结构化RAG(文本+表格)
·多模态RAG(文本+表格+图片)
·私有化多模态RAG(文本+表格+图片)
1)半结构化RAG(文本+表格)
![]()
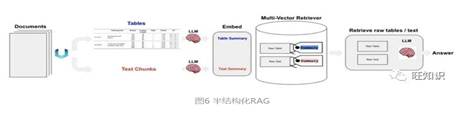
图6 半结构化RAG
此模式要同时处理文本与表格数据。其核心流程梳理如下[8]:
.将原始文档进行版面分析(基于Unstructured工具[9]),生成原始文本 和 原始表格。
.原始文本和原始表格经summary LLM处理,生成文本summary和表格summary。
.用同一个embedding模型把文本summary和表格summary向量化,并存入多向量检索器。
.多向量检索器存入文本/表格embedding的同时,也会存入相应的summary和raw data。
.用户query向量化后,用ANN检索召回raw text和raw
table。
.根据query+raw
text+raw table构造完整prompt,访问LLM生成最终结果。
2)多模态RAG(文本+表格+图片)
对多模态RAG而言,有三种技术路线[10],见下图:
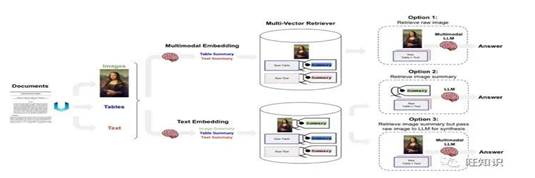
![]()
图7 多模态RAG
如图7所示,对多模态RAG而言有三种技术路线,如下我们做个简要说明:
·选项1:对文本和表格生成summary,然后应用多模态embedding模型把文本/表格summary、原始图片转化成embedding存入多向量检索器。对话时,根据query召回原始文本/表格/图像。然后将其喂给多模态LLM生成应答结果。
·选项2:首先应用多模态大模型(GPT4-V、LLaVA、FUYU-8b)生成图片summary。然后对文本/表格/图片summary进行向量化存入多向量检索器中。当生成应答的多模态大模型不具备时,可根据query召回原始文本/表格+图片summary。
·选项3:前置阶段同选项2相同。对话时,根据query召回原始文本/表格/图片。构造完整Prompt,访问多模态大模型生成应答结果。
3)私有化多模态RAG(文本+表格+图片)
如果数据安全是重要考量,那就需要把RAG流水线进行本地部署。比如可用LLaVA-7b生成图片摘要,Chroma作为向量数据库,Nomic's GPT4All作为开源嵌入模型,多向量检索器,Ollama.ai中的LLaMA2-13b-chat用于生成应答[11]。
参考资料
1.Chatbots | Langchain
2.Rerankers and Two-Stage Retrieval | Pinecone
3.Custom Retriever combining KG Index and VectorStore Index
4.Enhanced QA Integrating Unstructured Knowledge Graph Using Neo4j
and LangChain
5.https://blog.langchain.dev/using-a-knowledge-graph-to-implement-a-devops-rag-application/
6.AI pursuer:揭秘Self-RAG技术内幕
7.Multi-Vector Retriever for RAG on tables, text, and images:Multi-Vector Retriever for
RAG on tables, text, and images
8.https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_Structured_RAG.ipynb?ref=blog.langchain.dev
9.Unstructured | The Unstructured Data ETL for Your LLM
10.https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_and_multi_modal_RAG.ipynb?ref=blog.langchain.dev
11.https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_multi_modal_RAG_LLaMA2.ipynb?ref=blog.langchain.dev
出自:
https://www.toutiao.com/article/7319514097631019520/?app=news_article×tamp=1704616003&use_new_style=1&req_id=2024010716264298C87971AF4FBA48F1E0&group_id=7319514097631019520&share_token=F738CC49-B9B7-4198-A24B-907E621C76CF&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_ios&utm_campaign=client_share&wxshare_count=1&source=m_redirect
Learn Prompting课程为不熟悉 AI 和 PE 的初学者量身打造,它将是你完美的起点。Learn Prompting课程是目前最全面的提示工程课程,内容涵盖 AI 简介到高级 PE 技术。