张嘴就能生图?这已经不是科技,这是魔法!(Stable Diffusion进阶篇:SDXL-Turbo)
发布时间:2024年06月06日
天气冷了,人就容易偷懒,尤其是像我这种被窝里还有小猫咪的人来说,被窝就是抵御寒冷最结实的堡垒。
之所以今天能让我从被窝里爬起来是因为我被外面上学铃吵醒了,谁也睡不着了所以干脆起来学习。
今天要学习的就是我上一篇笔记中所提到的Turbo,在官方的演示中这款软件实现了一打字就会出画面,画面随着提示词的更改实时变化。
https://youtu.be/adDyTzBdUcg
其生图的速度远远超过了传统生成的速度,都什么年代还在边等图边打星穹铁道?
不过就我目前看来的大部分演示都是通过ComfyUI,当然WebUI也可以使用不过好像暂时没ComfyUI那么顺。
Turbo具备了最新的快速扩散蒸馏技术(Adversarial Diffusion Distillation),这个技术可以在保持图像生成质量的同时大幅度降低采样步数(生成速度)

比较明显的比对就是SDXL-Turbo一步就可以达成基础版SD50步的采样效果:
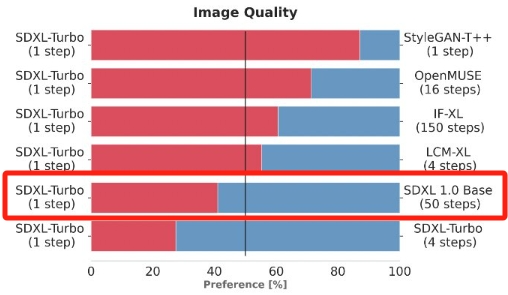
这个还是很厉害的,SD官方也提供了SDXL-Turbo的线上体验渠道,只需要去到官方的Clipdrop(非VIP有次数限制)

https://clipdrop.co/stable-diffusion?utm_campaign=stable_diffusion_promo&utm_medium=cta_button&utm_source=stability_ai

明显地快速生成
而来到Hugging face的页面可以找到SXDL Turbo的下载地址。
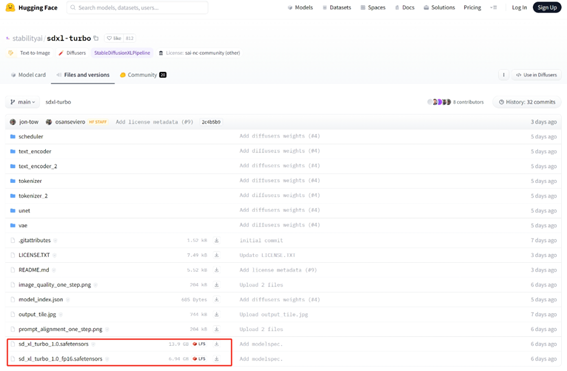
原版的Turbo已经接近14GB大小,远超之前下载的所有Checkpoint模型,而下方带fp16的是所谓的精简版本,这里推荐下载精简版本试试(放在以往的Checkpoint模型地址就好)。
先回到Stable Diffusion中,如果单单迭代一次的话生成的图片只会是十分模糊不清的。
这里将模型更改为Turbo
下方的参数需要进行一点点改动:
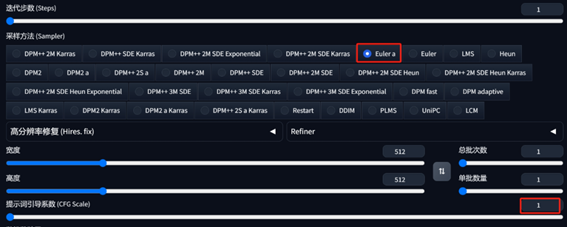
采样方法最好是Eluer a,并且提示词引导系数在2以下是比较好的,然后点击生成。
真的是一秒生成(这比我登录英雄联盟还快):
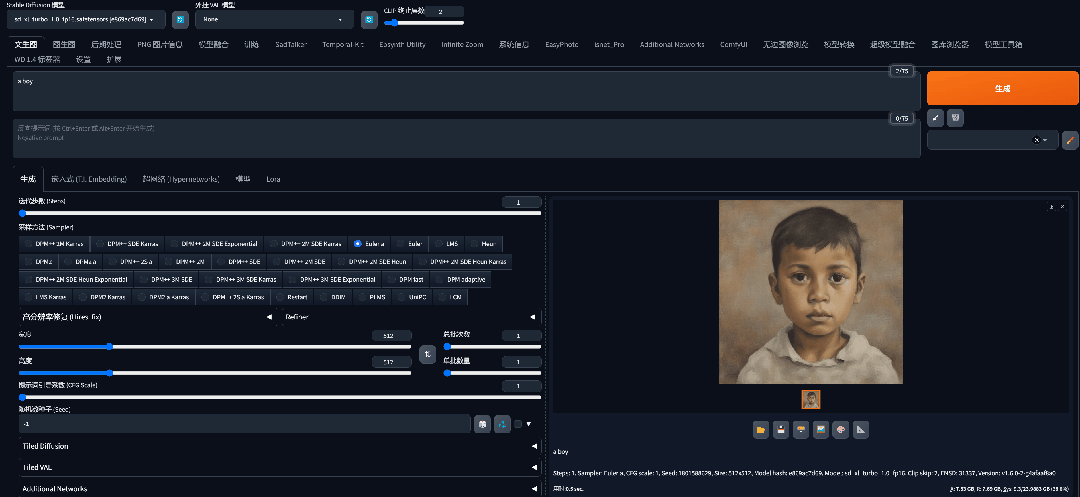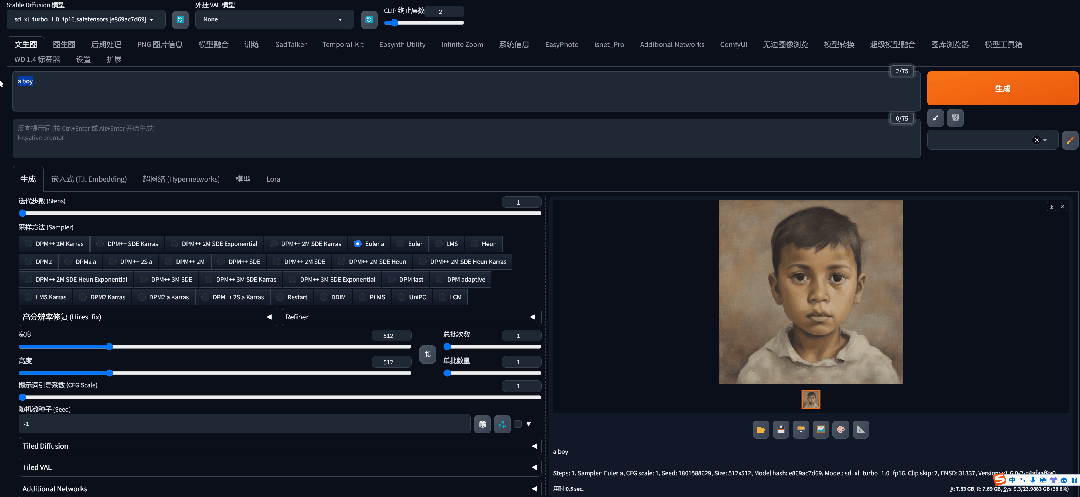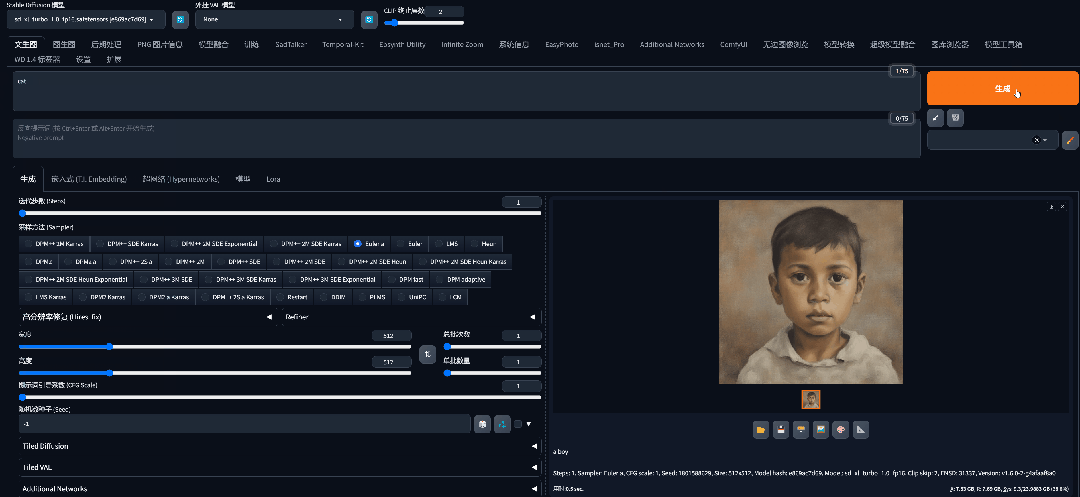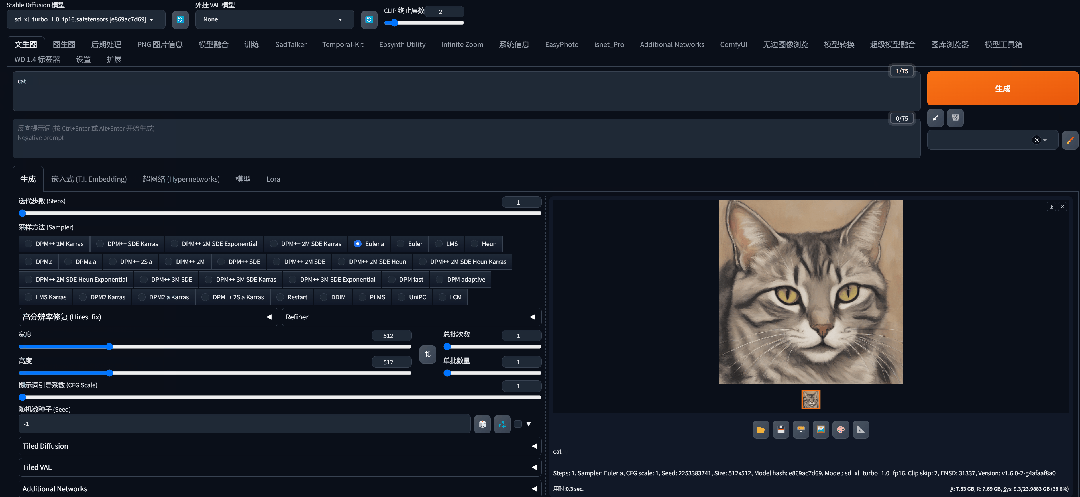
![]()
当然也可能是因为我的显卡比较好(没钱冲阿里云会员了不然我可以试试其他的显卡),但是我看了大多数的视频基本上比较普遍的显卡都是在4-5秒左右就能生成。
目前SDXL Turbo模型最理想的出图大小就是默认的512*512,该模型的分辨率还无法去到1024级别,强行拉上去会出现元素混乱的现象。
Turbo一步就能生成图片,更多的步数可以让图片的细节和清晰度有所提高。但是一般5步采样就够了,采样再多只会增加渲染时间。
当然还有一个东西速度更快,就是LCM技术,关于这方面可以看文末的视频。对于WebUI来说LCM技术更具优势,而Turbo较适合Comfyui上。
而目前市面上也有越来越多Turbo+LCM双融合的模型,在保持图片质量的同时以更快的速度出图,但是这样的融合模型需要至少5步以上的采样。好处是这类模型解决了Turbo清晰度不足的问题,可以实现1024分辨率的出图,也算是一个另类的解决方案。
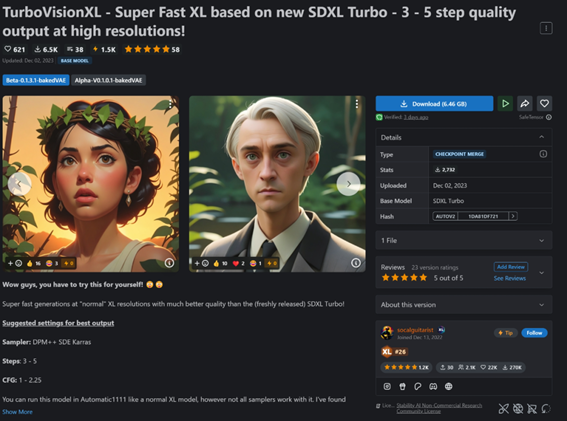
https://civitai.com/models/215418/turbovisionxl-super-fast-xl-based-on-new-sdxl-turbo-3-5-step-quality-output-at-high-resolutions
目前的Turbo还处于BETA测试阶段,希望以后能给喜欢AI绘画的大伙带来更多的惊喜吧~
今天的内容就到这里结束啦!
其实学到现在绝大多数的Stable
Diffusion使用技巧已经学了很多了,需要的还是自己不断地去研究学习,当然我也会不断学习否则我就不知道文章要写啥了。
这篇文章内容比较少,主要是因为讲的是一个测试阶段的东西还有很多可能需要等到后续正式发布才能学到。
大伙下篇笔记见吧~拜了个拜!

Postivie:1girl, turbo byakuren, kneeling, shy,
Negative
prompt: EasyNegative,
(worst quality:1.4), (low quality:1.4), (normal quality:1.4), ((female pubic
hair:1.3)), lowres,animal ears, (missing fingers),
Steps:
30,
Sampler:
Euler a,
CFG
scale: 7,
Seed:
2441128734,
Size:
512x512,
Model
hash: e4a30e4607,
Model:
majicmixRealistic_v6
文章部分参考素材来源:
【1步出图 SDXL Turbo、LCM模型哪个更快?stablediffusion SDXL Turbo教程-哔哩哔哩】 https://b23.tv/8cF9MK6
出自:https://mp.weixin.qq.com/s/pArAPDESJXTG2OLzHjUbxQ
将AI快速集成到你自己的应用中