硬核解读Stable Diffusion(系列三)
发布时间:2024年06月06日
SD 2.0
Stability AI公司在2022年11月(stable-diffusion-v2-release)放出了SD 2.0版本,这里我们也简单介绍一下相比SD 1.x版本SD 2.0的具体改进点。SD 2.0相比SD 1.x版本的主要变动在于模型结构和训练数据两个部分。 首先是模型结构方面,SD 1.x版本的text encoder采用的是OpenAI的CLIP ViT-L/14模型,其模型参数量为123.65M;而SD 2.0采用了更大的text encoder:基于OpenCLIP在laion-2b数据集上训练的CLIP ViT-H/14模型,其参数量为354.03M,相比原来的text encoder模型大了约3倍。两个CLIP模型的对比如下所示:
首先是模型结构方面,SD 1.x版本的text encoder采用的是OpenAI的CLIP ViT-L/14模型,其模型参数量为123.65M;而SD 2.0采用了更大的text encoder:基于OpenCLIP在laion-2b数据集上训练的CLIP ViT-H/14模型,其参数量为354.03M,相比原来的text encoder模型大了约3倍。两个CLIP模型的对比如下所示: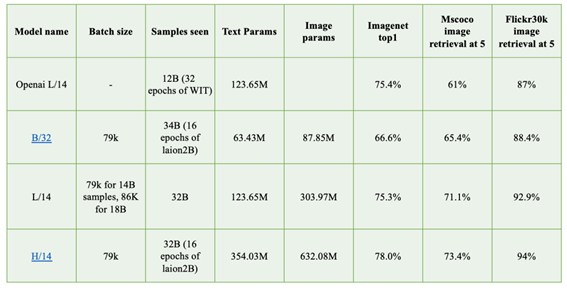 可以看到CLIP
可以看到CLIP
ViT-H/14模型相比原来的OpenAI的L/14模型,在imagenet1K上分类准确率和mscoco多模态检索任务上均有明显的提升,这也意味着对应的text encoder更强,能够抓住更准确的文本语义信息。另外是一个小细节是SD
2.0提取的是text encoder倒数第二层的特征,而SD
1.x提取的是倒数第一层的特征。由于倒数第一层的特征之后就是CLIP的对比学习任务,所以倒数第一层的特征可能部分丢失细粒度语义信息,Imagen论文(见论文D.1部分)和novelai
然后是训练数据,前面说过SD 1.x版本其实最后主要采用laion-2B中美学评分为5以上的子集来训练,而SD 2.0版本采用评分在4.5以上的子集,相当于扩大了训练数据集,具体的训练细节见model card。
另外SD 2.0除了512x512版本的模型,还包括768x768版本的模型(https://huggingface.co/stabilityai/stable-diffusion-2),所谓的768x768模型是在512x512模型基础上用图像分辨率大于768x768的子集继续训练的,不过优化目标不再是noise_prediction,而是采用Progressive Distillation for Fast Sampling of Diffusion Models论文中所提出的 v-objective。
下图为SD 2.0和SD 1.x版本在COCO2017验证集上评测的对比,可以看到2.0相比1.5,CLIP score有一个明显的提升,同时FID也有一定的提升。但是正如前面所讨论的,FID和CLIP score这两个指标均有一定的局限性,所以具体效果还是上手使用来对比。(见novelai
blog)均采用了倒数第二层特征。对于UNet模型,SD
2.0相比SD 1.x几乎没有改变,唯一的一个小的变动是:SD
2.0不同stage的attention模块是固定attention head dim为64,而SD 1.0则是不同stage的attention模块采用固定attention head数量,明显SD 2.0的这种设定更常用,但是这个变动不会影响模型参数。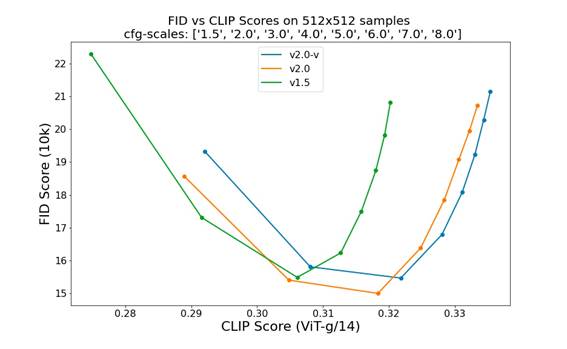 Stability AI在发布SD 2.0的同时,还发布了另外3个模型:stable-diffusion-x4-upscaler,stable-diffusion-2-inpainting和stable-diffusion-2-depth。stable-diffusion-x4-upscaler是一个基于扩散模型的4x超分模型,它也是基于latent diffusion,不过这里采用的autoencoder是基于VQ-reg的,下采样率为。在实现上,它是将低分辨率图像直接和noisy latent拼接在一起送入UNet,因为autoencoder将高分辨率图像压缩为原来的1/4,而低分辨率图像也为高分辨率图像的1/4,所以低分辨率图像的空间维度和latent是一致的。另外,这个超分模型也采用了Cascaded Diffusion Models for High Fidelity Image Generation所提出的noise conditioning augmentation,简单来说就是在训练过程中给低分辨率图像加上高斯噪音,可以通过扩散过程来实现,注意这里的扩散过程的scheduler与主扩散模型的scheduler可以不一样,同时也将对应的noise_level(对应扩散模型的time step)通过class labels的方式送入UNet,让UNet知道加入噪音的程度。stable-diffusion-x4-upscaler是使用LAION中>2048x2048大小的子集(10M)训练的,训练过程中采用512x512的crops来训练(降低显存消耗)。SD模型可以用来生成512x512图像,加上这个超分模型,就可以得到2048x2048大小的图像。
Stability AI在发布SD 2.0的同时,还发布了另外3个模型:stable-diffusion-x4-upscaler,stable-diffusion-2-inpainting和stable-diffusion-2-depth。stable-diffusion-x4-upscaler是一个基于扩散模型的4x超分模型,它也是基于latent diffusion,不过这里采用的autoencoder是基于VQ-reg的,下采样率为。在实现上,它是将低分辨率图像直接和noisy latent拼接在一起送入UNet,因为autoencoder将高分辨率图像压缩为原来的1/4,而低分辨率图像也为高分辨率图像的1/4,所以低分辨率图像的空间维度和latent是一致的。另外,这个超分模型也采用了Cascaded Diffusion Models for High Fidelity Image Generation所提出的noise conditioning augmentation,简单来说就是在训练过程中给低分辨率图像加上高斯噪音,可以通过扩散过程来实现,注意这里的扩散过程的scheduler与主扩散模型的scheduler可以不一样,同时也将对应的noise_level(对应扩散模型的time step)通过class labels的方式送入UNet,让UNet知道加入噪音的程度。stable-diffusion-x4-upscaler是使用LAION中>2048x2048大小的子集(10M)训练的,训练过程中采用512x512的crops来训练(降低显存消耗)。SD模型可以用来生成512x512图像,加上这个超分模型,就可以得到2048x2048大小的图像。 在diffusers库中,可以如下使用这个超分模型(这里的noise level是指推理时对低分辨率图像加入噪音的程度):
在diffusers库中,可以如下使用这个超分模型(这里的noise level是指推理时对低分辨率图像加入噪音的程度):
importrequests
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionUpscalePipeline
import torch# load model and scheduler
model_id ="stabilityai/stable-diffusion-x4-upscaler"
pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")# let's download an image
url ="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
response = requests.get(url)
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
low_res_img = low_res_img.resize((128,128))
prompt ="a white cat"
upscaled_image = pipeline(prompt=prompt, image=low_res_img, noise_level=20).images[0]
upscaled_image.save("upsampled_cat.png")
stable-diffusion-2-inpainting是图像inpainting模型,和前面所说的runwayml/stable-diffusion-inpainting基本一样,不过它是在SD 2.0的512x512版本上finetune的。 stable-diffusion-2-depth是也是在SD 2.0的512x512版本上finetune的模型,它是额外增加了图像的深度图作为condition,这里是直接将深度图下采样8x,然后和nosiy latent拼接在一起送入UNet模型中。深度图可以作为一种结构控制,下图展示了加入深度图后生成的图像效果:
stable-diffusion-2-depth是也是在SD 2.0的512x512版本上finetune的模型,它是额外增加了图像的深度图作为condition,这里是直接将深度图下采样8x,然后和nosiy latent拼接在一起送入UNet模型中。深度图可以作为一种结构控制,下图展示了加入深度图后生成的图像效果: 你可以调用diffusers库中的
你可以调用diffusers库中的StableDiffusionDepth2ImgPipeline来实现基于深度图控制的文生图:
importtorch
import requests
from PIL import Image
from diffusers import StableDiffusionDepth2ImgPipeline
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
).to("cuda")
url ="http://images.cocodataset.org/val2017/000000039769.jpg"
init_image = Image.open(requests.get(url, stream=True).raw)
prompt ="two tigers"
n_propmt ="bad, deformed, ugly, bad anotomy"
image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
除此之外,Stability AI公司还开源了两个加强版的autoencoder:ft-EMA和ft-MSE(前者使用L1 loss后者使用MSE loss),前面已经说过,它们是在LAION数据集继续finetune decoder来增强重建效果。
SD 2.1
在SD 2.0版本发布几周后,Stability AI又发布了SD 2.1。SD 2.0在训练过程中采用NSFW检测器过滤掉了可能包含色情的图像(punsafe=0.1),但是也同时过滤了很多人像图片,这导致SD 2.0在人像生成上效果可能较差,所以SD 2.1是在SD 2.0的基础上放开了限制(punsafe=0.98)继续finetune,所以增强了人像的生成效果。 和SD 2.0一样,SD 2.1也包含两个版本:512x512版本和768x768版本。
和SD 2.0一样,SD 2.1也包含两个版本:512x512版本和768x768版本。
SD unclip
Stability AI在2023年3月份,又放出了基于SD的另外一个模型:stable-diffusion-reimagine,它可以实现单个图像的变换,即image variations,目前该模型已经在在huggingface上开源:stable-diffusion-2-1-unclip。
这个模型是借鉴了OpenAI的DALLE2(又称unCLIP),unCLIP是基于CLIP的image encoder提取的image embeddings作为condition来实现图像的生成。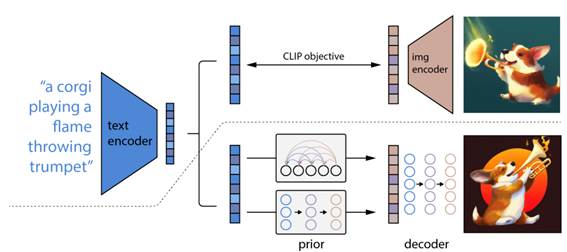 SD unCLIP是在原来的SD模型的基础上增加了CLIP的image
SD unCLIP是在原来的SD模型的基础上增加了CLIP的image
encoder的nosiy image embeddings作为condition。具体来说,它在训练过程中是对提取的image embeddings施加一定的高斯噪音(也是通过扩散过程),然后将noise level对应的time embeddings和image embeddings拼接在一起,最后再以class labels的方式送入UNet。在diffusers中,你可以调用StableUnCLIPImg2ImgPipeline来实现图像的变换:
importrequests
import torch
from PIL import Image
from io import BytesIO
from diffusers import StableUnCLIPImg2ImgPipeline#Start the StableUnCLIP Image variations pipeline
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
)
pipe = pipe.to("cuda")#Get image from URL
url ="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")#Pipe to make the variation
images = pipe(init_image).images
images[0].save("tarsila_variation.png")
其实在SD unCLIP之前,已经有Lambda Labs开源的sd-image-variations-diffusers,它是在SD 1.4的基础上finetune的模型,不过实现方式是直接将text embeddings替换为image embeddings,这样也同样可以实现图像的变换。 这里SD
这里SD
unCLIP有两个版本:sd21-unclip-l和sd21-unclip-h,两者分别是采用OpenAI CLIP-L和OpenCLIP-H模型的image embeddings作为condition。如果要实现文生图,还需要像DALLE2那样训练一个prior模型,它可以实现基于文本来预测对应的image embeddings,我们将prior模型和SD unCLIP接在一起就可以实现文生图了。KakaoBrain这个公司已经开源了一个DALLE2的复现版本:Karlo,它是基于OpenAI CLIP-L来实现的,你可以基于这个模型中prior模块加上sd21-unclip-l来实现文本到图像的生成,目前这个已经集成了在StableUnCLIPPipeline中,或者基于stablediffusion官方仓库来实现。
SD的其它特色应用
在SD模型开源之后,社区和研究机构也基于SD实现了形式多样的特色应用,这里我们也选择一些比较火的应用来介绍一下。
个性化生成
个性化生成是指的生成特定的角色或者风格,比如给定自己几张肖像来利用SD来生成个性化头像。在个性化生成方面,比较重要的两个工作是英伟达的Textual
Inversion和谷歌的DreamBooth。Textual Inversion这个工作的核心思路是基于用户提供的3~5张特定概念(物体或者风格)的图像来学习一个特定的text embeddings,实际上只用一个word embedding就足够了。Textual Inversion不需要finetune UNet,而且由于text embeddings较小,存储成本很低。目前diffusers库已经支持textual_inversion的训练。 DreamBooth原本是谷歌提出的应用在Imagen上的个性化生成,但是它实际上也可以扩展到SD上(更新版论文已经增加了SD)。DreamBooth首先为特定的概念寻找一个特定的描述词[V],这个特定的描述词只要是稀有的就可以,然后与Textual Inversion不同的是DreamBooth需要finetune UNet,这里为了防止过拟合,增加了一个class-specific prior preservation loss(基于SD生成同class图像加入batch里面训练)来进行正则化。
DreamBooth原本是谷歌提出的应用在Imagen上的个性化生成,但是它实际上也可以扩展到SD上(更新版论文已经增加了SD)。DreamBooth首先为特定的概念寻找一个特定的描述词[V],这个特定的描述词只要是稀有的就可以,然后与Textual Inversion不同的是DreamBooth需要finetune UNet,这里为了防止过拟合,增加了一个class-specific prior preservation loss(基于SD生成同class图像加入batch里面训练)来进行正则化。
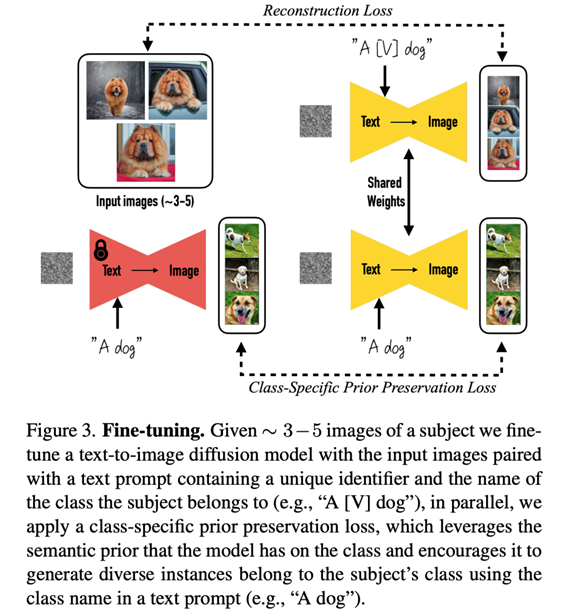 由于finetune了UNet,DreamBooth往往比Textual
由于finetune了UNet,DreamBooth往往比Textual
Inversion要表现的要好,但是DreamBooth的存储成本较高。目前diffusers库已经支持dreambooth训练,你也可以在sd-dreambooth-library中找到其他人上传的模型。 DreamBooth和Textual Inversion是最常用的个性化生成方法,但其实除了这两种,还有很多其它的研究工作,比如Adobe提出的Custom Diffusion,相比DreamBooth,它只finetune了UNet的attention模块的KV权重矩阵,同时优化一个新概念的token。
风格化finetune模型
SD的另外一大应用是采用特定风格的数据集进行finetune,这使得模型“过拟合”在特定的风格上。之前比较火的novelai就是基于二次元数据在SD上finetune的模型,虽然它失去了生成其它风格图像的能力,但是它在二次元图像的生成效果上比原来的SD要好很多。
目前已经有很多风格化的模型在huggingface上开源,这里也列出一些:
·andite/anything-v4.0:二次元或者动漫风格图像
 grid-0018.png
grid-0018.png
·dreamlike-art/dreamlike-diffusion-1.0:艺术风格图像
 image.png
image.png
·prompthero/openjourney:mdjrny-v4风格图像
 更多的模型可以直接在huggingface
更多的模型可以直接在huggingface
text-to-image模型库上找到。此外,很多基于SD进行finetune的模型开源在civitai上,你也可以在这个网站上找到更多风格的模型。 值得说明的一点是,目前finetune
SD模型的方法主要有两种:一种是直接finetune了UNet,但是容易过拟合,而且存储成本;另外一种低成本的方法是基于微软的LoRA,LoRA本来是用于finetune语言模型的,但是现在已经可以用来finetune SD模型了,具体可以见博客Using LoRA for Efficient Stable Diffusion Fine-Tuning。
图像编辑
图像编辑也是SD比较火的应用方向,这里所说的图像编辑是指的是使用SD来实现对图片的局部编辑。这里列举两个比较好的工作:谷歌的prompt-to-prompt和加州伯克利的instruct-pix2pix。 谷歌的prompt-to-prompt的核心是基于UNet的cross attention maps来实现对图像的编辑,它的好处是不需要finetune模型,但是主要用在编辑用SD生成的图像。 谷歌后面的工作Null-text
谷歌后面的工作Null-text
Inversion有进一步实现了对真实图片的编辑: instruct-pix2pix这个工作基于GPT-3和prompt-to-prompt构建了pair的数据集,然后在SD上进行finetune,它可以输入text instruct对图像进行编辑:
instruct-pix2pix这个工作基于GPT-3和prompt-to-prompt构建了pair的数据集,然后在SD上进行finetune,它可以输入text instruct对图像进行编辑:
可控生成
可控生成是SD最近比较火的应用,这主要归功于ControlNet,基于ControlNet可以实现对很多种类的可控生成,比如边缘,人体关键点,草图和深度图等等。

 其实在ControlNet之前,也有一些可控生成的工作,比如stable-diffusion-2-depth也属于可控生成,但是都没有太火。我觉得ControlNet之所以火,是因为这个工作直接实现了各种各种的可控生成,而且训练的ControlNet可以迁移到其它基于SD finetune的模型上(见Transfer Control to Other
其实在ControlNet之前,也有一些可控生成的工作,比如stable-diffusion-2-depth也属于可控生成,但是都没有太火。我觉得ControlNet之所以火,是因为这个工作直接实现了各种各种的可控生成,而且训练的ControlNet可以迁移到其它基于SD finetune的模型上(见Transfer Control to Other
SD1.X Models):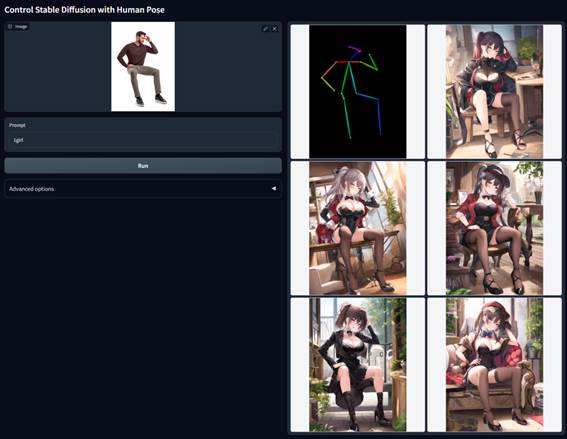 与ControlNet同期的工作还有腾讯的T2I-Adapter以及阿里的composer-page:
与ControlNet同期的工作还有腾讯的T2I-Adapter以及阿里的composer-page:
stable-diffusion-webui
最后要介绍的一个比较火的应用stable-diffusion-webui其实是用来支持SD出图的一个web工具,它算是基于gradio框架实现了SD的快速部署,不仅支持SD的最基础的文生图、图生图以及图像inpainting功能,还支持SD的其它拓展功能,很多基于SD的拓展应用可以用插件的方式安装在webui上。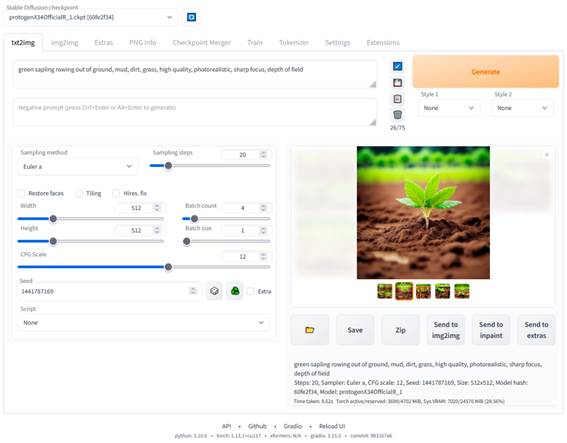
后话
在OpenAI最早放出DALLE2的时候,我曾被它生成的图像所惊艳到,但是我从来没有想到图像生成的AIGC会如此火爆,技术的发展太快了,这得益于互联网独有的开源精神。我想,没有SD的开源,估计这个方向可能还会沉寂一段时间。
出自:https://mp.weixin.qq.com/s/U13Si5nM12_b9WqGaXOMWg
PixWeaver是一个基于人工智能的图像创作平台。它能帮助用户无需学习复杂的设计软件,通过语音或文字描述就可以生成理想中的图像。