深度好文,Agent盛行前传
发布时间:2024年06月06日
前几天有看微软CEO纳德拉(Satya Nadella)发布的Copliot的服务,不仅是我们原来理解的服务体验更好的GPT agent, 在发布会的结尾,放映的“AI for frontline”极大地震撼了在座的嘉宾,还有我;这意味着多年前我们坐在电影院里看到了科幻电影或者英雄电影里主人公使用各种酷炫的科技装备打败敌人或者征服星际似乎不再遥不可及了,一切皆可智能(everything can be intelligent)。

在这篇文章里我将借助引用量较高的论文“Reward is enough”并结合近期使用的MindOS(一款以GPT为大模型底层的agent应用)来说说agent是怎么发展起来的。
Agent从何定义
Agent中文是代理,你可以理解成有一个具体的对象在完成某个任务;agent在某个时间点收到一个观测值后,基于以往在此时间点及之前接收观测值和做出的动作做出新的动作反馈。agent本身是决策主体,除此之外甚至包括传感器和执行器都算在环境(environment)里。
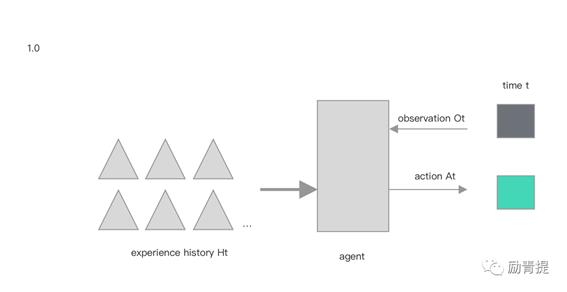
奖赏对agent的学习和成长的重要性
当agent接收到奖赏(reward)信号时,它“心动”了,因为它会把这种奖赏信号看作是给自己到达目标过程中的间接反馈,意味着它做得很不错,奖赏信号包括即时反馈类的,如点赞,延迟反馈类的,如调研;agent继续全力产出动作反馈,直到达成目标。
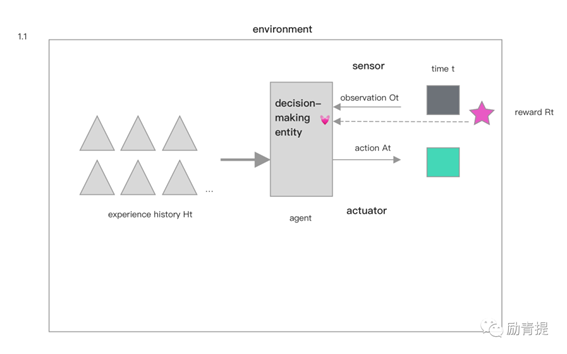
智力的发展本身是在追求奖赏
智力的发展可以拆分为知识与学习、洞察力、社会智力、语言、概括、模仿和通用智力的发展。第一是知识与学习(knowledge and learning),在agent角度,知识分为与生俱来的知识和后期学习的知识,与生俱来的知识需要在训练前就嵌入agent体内,为了应对最紧急的需求,比如躲避危险;后期学习的知识更多的是为了适应未来复杂的、随机性强的和多元的环境和诉求;对于与生俱来的知识,奖赏发生在成功躲避猛兽的追捕;对于后期学习的知识,奖赏在未来解决一个之前并不擅长的疑问。
第二是洞察力(perception),洞察力主要分为视觉、听觉、嗅觉、体感等,而这种能力的获得由于agent本身有趋利(奖赏)避害的需求,而趋利的动机又会强化洞察力的使用和提升,比如动物采摘食物,会发现果子是否成熟、有无异味、是否在可触及的范围。
第三是社会智力(social intelligence),社会智力脱胎于博弈论,在不确定环境优劣的情况,较强的鲁棒性相对更可取一些,举例来说,当一个agent最大化自己奖赏时,它身处有其他agents的环境时,更有可能采取一个鲁棒性强的策略。
第四是语言(language),语言能力的获取已经在agent的大型数据语料库中的语言预测建模的工作中初见成效,但由于语言有自身的上下文属性、顺序性以及不同场景对语言的需求不一样,在训练语言能力会付出一定的机会成本,也带来了相对的限制性。agent在使用语言时更多是把它看作一种工具,在工具的使用时趋利避害,从而获得奖赏。
第五是概括能力(generalisation),概括能力通常是指可以整理总结过去的成功经验并且应用在新的场景上,而由于世界里状态的多变和复杂,对概括能力的需求一直巨大,比如一只以水果为主要食物的动物也许每天都会碰到一棵新的树,它也许需要在环境里快速适应,像受伤、缺水或者入侵物种。而应用概括能力就可以获得奖赏。
第六是模仿能力(imitation),它和概括能力相似的点是它们同属基础能力,好的模仿能力能够促进语言、知识和运动技能的提升,“元能力”(参考“元认知”,我来给它起了个名字),行为克隆和观察式学习是习得模仿能力的两种途径,其中行为克隆已经成功应用在机器学习上,尤其是当老师足够多但互动数据有限且成本昂贵的情况下。而观察式学习本身并不需要奖赏,这是一个很有趣的点,原作者并没有阐述原因,据我的理解,观察后学习到的知识、技能本身就是一种奖赏,因此agent不需要单独奖赏。
第七是通用智力(general intelligence), 所谓的通用智力,是能够在不同语境下灵活地达成不同目标的能力,一般是使用不同的环境借助不同的目标和语境来评估agent的能力;而在大量的经验的前提下,例如有一个总的目标是“生存下去”,需要通用智力来达成这个“生存下去”的能力的子目标,以这种方式可以达到奖赏最大化。
强化学习代理(reinforcement learning agents)
强化学习代理是以奖赏为动机去训练的代表,它会不断地从符合条件的经历中学习,这些经历会包含它所需要的技能的展现,例如前面提到的洞察力、语言、社会智力等等,而在提供奖赏和奖赏信号层面,或者直接通过修改agent协议的方式去最大化奖赏,或者用间接的方式去拆解目标,以子目标的达到来获取奖赏或收到奖赏信号。(可以理解为有一个进度条,能够看到不同子目标的进度和总目标的进度)
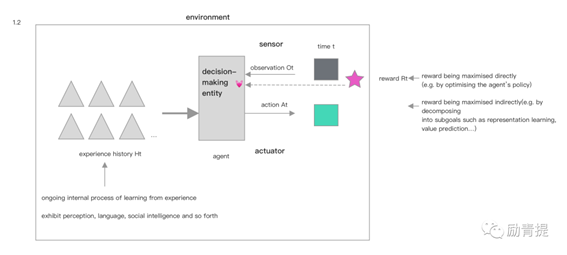
假设:人工智能将在agent追求最大化奖赏时出现
我最近有经常看到“智能涌现”这个词,而通读论文后,能够知道了底层原因是什么,结合七大智力发展和驱动agent习得能力的奖赏,如果要完成一项具体任务,通常都不是单一智力可以做到的,比如收集圆形鹅卵石,每次收集到一颗,则代理收到1分奖励,代理为了最大化地获得奖励,可能需要对卵石进行分类、导航到卵石海滩、存储卵石、了解波浪和潮汐及其对卵石分布的影响,说服人们帮助收集卵石,使用用于收集更多数量、采石和塑造新卵石、发现和构建新技术的工具和车辆收集鹅卵石,或建立一家收集鹅卵石的公司等。看起来仅仅是收集鹅卵石,代理却有可能提升七大智力里的大部分,因此“人工智能将在agent追求最大化奖赏时出现”看起来成立的可能性很大。
Agent试用和搭建方法
笔者在一个社群中收到的推荐,体验了一款agent生成和使用服务,MindOS,如果是自己搭建,需要选择声音风格、形象等,还可以搭建自己的团队,添加市场中的其他agent,类似一个虚拟团队在为你的工作和生活赋能提效。
我有尝试新闻、金融、论文等的agent,在生成新闻简报方面,已经是驾轻就熟的水平了。

而在论文内容的总结和进一步的提问上,尽管基于GPT的技术,agent表现的风格更浓烈、回答得更精准,也可以克服GPT3.5不能查询最新数据的难点。
以MindOS为例,agent提供的能力包括处理待办事项、管理日历、管理邮件、管理联系人、搜索实时信息、协同编程和导览地区,虽然没有使用GPT的渠道,不过通过发布会的演示,能了解和MindOS展示的能力大体接近,GPT的基于单个应用的私有知识库体验更好些。
(注:图片为网站截图,侵删)
而在一位博主的视频中,他演示了如何搭建个人agent, 可以用来生成图表、写代码或学习等,核心原理是Assistnat agent基于LLM分析并用文本来解答疑问,将解决方案提交给User proxy agent来解决,User Proxy agent 获取用户反馈或代替用户执行。这可以实现自动化地完成任务,而且比以往我们说使用脚本或者其他方式的自动化,解释性更强。
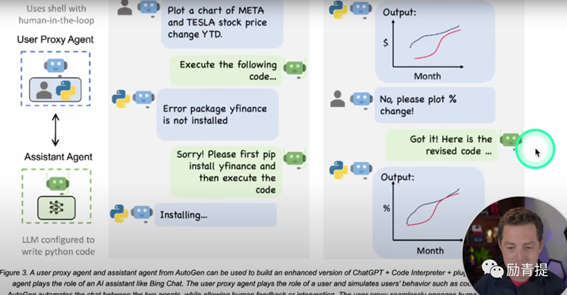
(注:图片为视频截图,侵删)
总结一下,以Copliot或其他agent,极有可能是基于奖赏最大化的原则实行的训练,并且它们的能力是全面发展的,在与人的交互中也可以学习,获得奖赏,不断成长。目前的agent已经可以发展为自动化或半自动化地帮助人类完成一些时间管理、任务管理和查找提取信息的任务,说“助理”绝不过分,说“伙伴”也是指日可待。agent,加油!

彩蛋时刻,如果将此文章分享到朋友圈,并将分享截图发送消息给公众号,即可获得作者独家论文相关流程图、思维导图(中英版本),快来参加吧
出自:https://mp.weixin.qq.com/s/zAYK2Um7kR8cObWsxS6Fyw
千象是由智象未来(HiDream.ai)倾力打造的基于国际领先且自主可控生成式人工智能(AIGC)多模态大模型的全中文易上手AIGC创作平台和社区。