昆仑万维携Skywork-13B打造AI新纪元:600GB中文数据集全球开源
发布时间:2024年06月06日
引言
在人工智能的浪潮中,数据和算力是推动技术发展的两大驱动力。昆仑万维近期发布的「天工」Skywork-13B系列大模型,不仅是一个技术上的巨大飞跃,更是对全球AI社区的一次重要贡献。它不仅开源了130亿参数的大模型,更罕见地配套开源了600GB、150B Tokens的超大高质量中文数据集,为全球AI研究者提供了前所未有的资源。
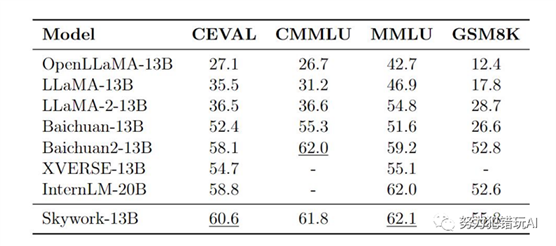
Skywork-13B系列大模型
「天工」Skywork-13B系列大模型包括Skywork-13B-Base模型和Skywork-13B-Math模型两大版本。这两个模型在CEVAL、GSM8K等多个权威评测与基准测试上展现了同等规模模型中的最佳效果,特别是在中文科技、金融、政务等领域的表现更是超越了其他开源模型。
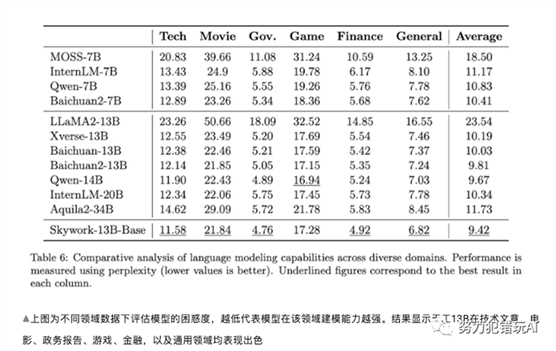
技术突破
Skywork-13B系列的成功,得益于昆仑万维在大数据处理和深度学习技术上的深厚积累。首先,在模型结构上,Skywork-13B采用了更为“瘦长”的设计,有效提升了模型在大批量数据训练下的泛化能力。其次,昆仑万维创新性地整合了3.2万亿个高质量多语言数据,为模型提供了丰富的学习素材。
开源中文数据集
昆仑万维此次开源的Skypile/Chinese-Web-Text-150B数据集是目前最大的开源中文数据集之一。这个数据集通过精心设计的数据处理流程从中文网页中筛选而来,为AI研究者提供了巨大的中文语料库。这一举措无疑将极大丰富中文AI模型的训练资源,推动中文自然语言处理技术的发展。
商业应用的门槛降低
昆仑万维「天工」Skywork-13B系列大模型的另一个突出特点是其对商业应用的开放性。昆仑万维简化了授权流程,取消了对行业、公司规模、用户等方面的限制,使得任何开发者或企业都能够轻松地将这一强大的AI模型应用于商业场景。
结语
Skywork-13B系列大模型的开源,标志着人工智能技术又迈出了一大步。这款模型的参数规模、性能表现、数据集规模等方面都具有领先优势,将为人工智能技术在各个领域的应用落地提供强有力的支持。同时,Skywork-13B系列大模型的开源,也将为开源社区的发展注入新的活力,推动人工智能生态建设。
模型下载
HuggingFace
https://huggingface.co/Skywork
AI快站模型免费加速下载
https://aifasthub.com/models/Skywork
Moonbeam 是唯一经过专门培训的 AI 写作助手,可帮助您撰写论文、故事、文章、博客和其他长篇内容。