【语音识别】OpenAI语音力作Whisper
发布时间:2024年06月06日
一、介绍
Whisper 是一系列用于自动语音识别 (automatic speech
recognition,ASR) 的预训练模型,它由来自于
OpenAI 的 Alec Radford 等人于2022年9月发布。与Wav2Vec 2.0等前作不同,以往的模型都是在未标注的音频数据上预训练的,而 Whisper 是在大量的已标注音频转录数据上预训练的。其用于训练的标注音频时长高达68万小时,比Wav2Vec 2.0使用的未标注训练数据 (6 万小时) 还多一个数量级。更妙的是,该预训练数据中还含有11.7万小时的多语种数据。因此,Whisper 训得的checkpoint可应用于超过96种语言,这其中包含不少数据匮乏的小语种。
这么多的标注数据使得我们可以直接在
有监督 语音识别任务上预训练Whisper,从标注音频转录数据中直接习得语音到文本的映射。因此,Whisper几乎不需要额外的微调就已经是高性能的 ASR 模型了。这让Wav2Vec 2.0相形见绌,因为Wav2Vec 2.0是在无监督 码预测任务上预训练的,所以其训得的模型仅从未标注的纯音频数据中习得了从语音到隐含状态的中间映射。虽然无监督预训练能产生高质量的语音表征,但它学不到语音到文本的映射,要学到语音到文本的映射只能靠微调。因此,Wav2Vec 2.0需要更多的微调才能获得较有竞争力的性能。
在68万小时标注数据的加持下,预训练 Whisper 模型表现出了强大的泛化到多种数据集和领域的能力。其预训练 checkpoint 表现出了与最先进的ASR系统旗鼓相当的性能。与人类相比,在语音识别和语音翻译(x→en)上,模型的准确性和稳健性接近人类。
whisper下载安装地址:https://github.com/openai/whisper
二、数据处理
利用互联网上的网络规模文本(人类/机器生成的混合数据)来训练,但存在大量低于标准的转录文本,所以开发了几种自动过滤方法来提高转录质量:
1. 全大写或全小写的转录本不太可能是人类生成的,剔除它们;
2. 基于数据集VoxLingua107W微调音频语言检测器(audio language detector),若文本转写语言和音频语言不匹配,则剔除;
3. 模糊去重转写文本,减少训练数据集中的重复量和自动生成的内容;
4. 将音频文件分成30秒的片段,并与该时间片段内出现的转写子集配对。我们对所有音频进行训练,包括没有语音的片段,并将这些片段用作语音活动检测模型(voice activity detection)的训练数据。
5. 训练初始模型后,查看不同训练数据源的错误率,优先对高错误率和大数据尺寸的数据源进行手动检查,剔除低数据质量的数据源。这项检查发现了大量仅部分转录或对齐不良/未对齐的转写文本,以及前面方法无法检测到的剩余低质量机器生成的文本。
三、模型
模型结构是encoder-decoder transformer,中间attention模块前后有残差链接,encoder用的是self attention,decoder用的是cross attention。。首先,通过特征提取器将原始音频输入变换为对数梅尔声谱图 (log-Mel spectrogram)。然后,transformer 编码器对声谱图进行编码,生成一系列编码器隐含状态。最后,解码器基于先前输出的词以及编码器隐含状态,自回归地预测下一个输出词。具体看开源仓库代码,这里不做详解。
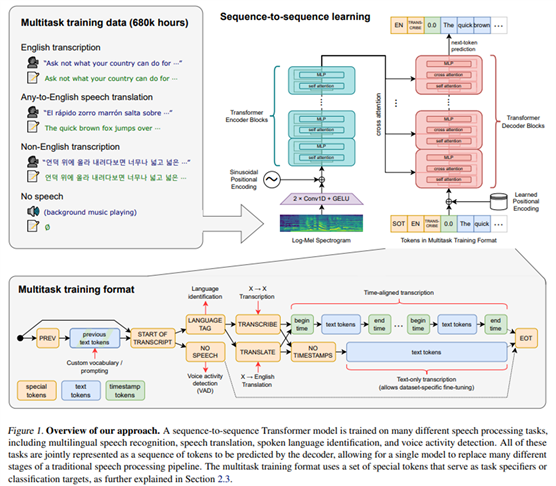
模型结构(融入了多任务:多语种的语音识别,语音翻译,语音语言识别,声音活动检测)
模型有5个版本,参数量、支持语言、显存和速度如下:
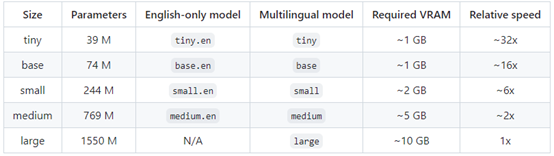
其中,token解释:
- context: 当前待转写音频片段之前的转写文本;
- SOT和EOT: <|startoftranscript|>正式转写的分隔符,<|endoftext|>结束转写的分割符;
- 语言token:供99种语言可选或无检测出语音<|nospeech|>;
- 任务token:<|transcribe|> or
<|translate|>。
- 时间token: 转写文本token前后会有起始时间和结尾时间token标识
- 文本token: 转写文本token。
在开源仓库有提供一个notebook 韩语音频数据案例,看了就指导大概multitask的token格式了:
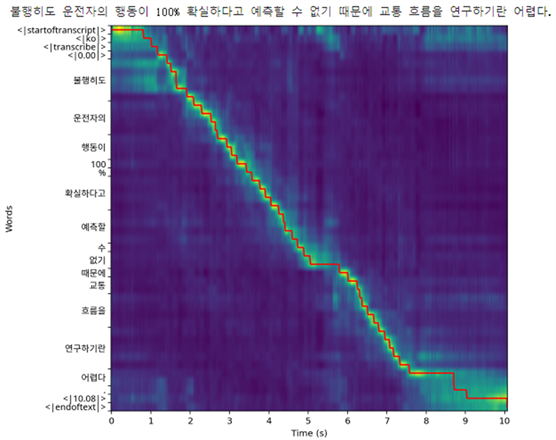
关于具体作者是如何训练,作者没详解,不过可以通过文章【使用
🤗 Transformers 为多语种语音识别任务微调
Whisper 模型】[2] 管中窥豹。
Q:为啥有些ASR模型转写的结果不带标点符号?
A:因为许多ASR的训练语料都对转写文本做了标准化,比如删除或规范化了从音频信号中难以预测的方面,例如复杂的标点符号(感叹号、逗号和问号)、格式化空白(例如段落)或风格大小写等方面。然后预测时,需要配合额外的逆文本标准化(inverse text normalization)来生成自然转写(比如加标点符号)。但Whisper不同,他直接训练模型去预测转写的原始文本。但有时训练也会去标点符号,应为他们不好预测(个人实践下来发现whisper版本越高,对标点符号的预测能力越强)。
四、难点
1. 规避讲话者身份预测
作者在查看模型效果是发现,因为数据集庞杂,模型很难预测好讲话者姓名。于是用一个不带讲话者姓名标注的数据集微调Whisper模型,移除对讲话者姓名的预测。(个人想法:角色分离得单独做,科大讯飞有专门做这个,好像是基于聚类的思想,后续待深入了解)。
2. 实现长音频转写
Q:学术数据集大多数由简短话语组成,但真实场景往往需要转写几分钟或几小时的音频,怎么办?
A:作者开发了一种策略,通过连续转录 30 秒的音频片段并根据模型预测的时间戳移动窗口来执行长音频的缓冲转写。同时,作者观察到,为了可靠地转写长音频,基于模型预测的重复性和对数概率,进行Beam Search和温度调度至关重要。
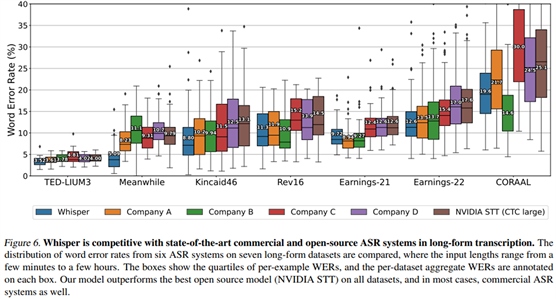
Whisper在长音频转写方面与最先进的商业和开源ASR系统具有竞争力
使用Whisper转写长音频依赖于时间戳token的准确预测,以确定模型的30秒音频上下文窗口的移动量,一个窗口中的不准确转写可能会对后续窗口中的转写产生负面影响。为此,作者开发了一套启发式方法,有助于避免长音频转录的失败案例。
1)beam decoding: 作者用温度系数调控解码方式(需要调控的原因是因为贪心解码算法在每个时间步只选择概率最高的输出,而不考虑后续时间步的影响。这导致模型容易陷入生成内容重复循环,重复生成相似的输出,所以需要引入使用对数概率作为得分函数的Beam Search,因为它会在生成序列的过程中保留多个候选项,并根据更全面的得分函数进行选择。这样可以增加生成多样性,减少重复,并提供更多有趣的输出选项):
- 当温度=0时,采用beam decoding,选择概率top beam_size个tokens;
- 当温度>0时,采用greedy decoding,选择概率top best_of个tokens;
目前代码默认best_of和beam_size都为5。
2)temperature fallback: 从温度0开始,按0.2间隔逐步增加到1,但只有当生成token的平均对数概率低于-1或生成文本的gzip压缩率高于2.4时,
看作解码失败,作者会将逐步增加温度 (可以直观理解为,beam search解码失败就走greedy search,前者搜索空间没有后者大)。另外,温度数值还会作用于GreedyDecoder()采样。在whisper/decoding.py里有相关代码:
1 if self.temperature == 0:
2 # 选择top概率的tokens
3 next_tokens = logits.argmax(dim=-1)
4 else:
5 # 这是一种采样技术,被称为"温度调整"。通过改变温度参数,我们可以改变概率分布的形状。
6 # 当温度接近0时,模型会更加确信其最初的预测。
7 # 而当温度变大时,所有可能结果的概率会变得更加平均,也就是说,模型的预测会更加不确定。
8 # (个人理解:因为贪心解码会有重复循环问题,所以温度>0搞采样的目的是为了增加生成token的不确定性,避免重复循环)
9 next_tokens = Categorical(logits=logits / self.temperature).sample()
3)voice activity detection: 若||token的概率>阈值,会跳出温度调整,则认作silence状态。
4)previous text conditioning: 当温度低于0.5时,提供来自先前窗口的生成的转录文本作为上文context prompt,进一步提高了性能(语句会变连贯,但也可能会诱发陷入重复转写的风险),而温度高于0.5,就不提供上文context prompt。此外,针对第一个转写窗口,你也能提供initial_prompt,比如“这是一段演讲,里面会提到大数据和ChatGPT是如何结合的”,你可以通过prompt引导提高特定场景和术语下的语音识别表现,这点就很openAI了。
使用prompt时要注意:如果你用model.transcribe(),就用initial_prompt,如果你用whisper.decode(),就在options用prompt,两边prompt的传参入口是不一样的,但作用是一样的。另外,还有个prefix参数,我感觉实践下来prefix没啥用。总之如下图所示:
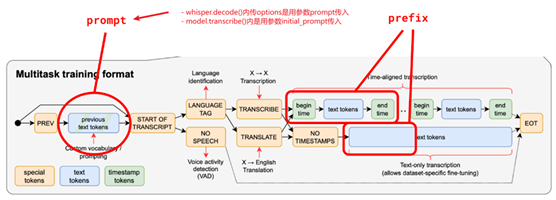
感兴趣请移步:https://github.com/openai/whisper/discussions/117
5)Initial timestamp constraint: 为了避免模型忽略输入中前几个单词,我们将初始时间戳token限制在0.0到1.0秒之间。
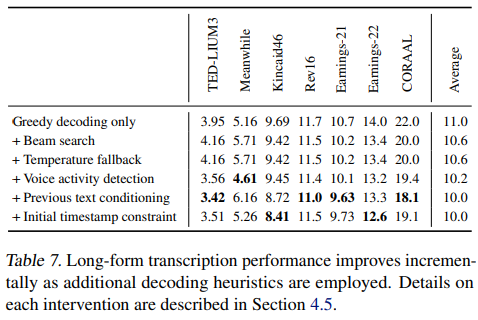
下表显示,添加上述每项干预措施会逐渐降低总体WER:
五、训练方式
我们使用具有动态损失缩放,参数精度为FP16。使用AdamW和梯度范数裁剪,在第一个2048次更新的warmup后,线性学习率朝0衰减。使用256个音频片段的作为一个batch,一共2^20次更新,即2-3 epochs,避免过拟合。同时也没使用任何数据增强或正则化,而是依靠如此大的数据集中包含的多样性来鼓励泛化和鲁棒性。
六、评估方式
Q:单词错误率 (WER)
作为语音识别的评估指标准确吗?若不准确,该怎么办?
A:基于字符串编辑距离的WER会惩罚模型输出与转写标签文本之间的所有差异,包括转写文本样式中无害的差异。因此,输出被人类判断为正确的转写文本的系统仍然可能由于微小的格式差异而产生较大的WER。所以作者使用了文本标准化,区分英文和非英文,做了些文本格式处理(个人体会:如作者附录所说,他的文本标准化比较粗略,我想若以后有水论文“心机”针对性调整文本格式处理方案,那WER的提升就有些水分了,并不是模型猛,二而是后处理强):

附录C:英文文本标准化

附录C:非英文文本标准化
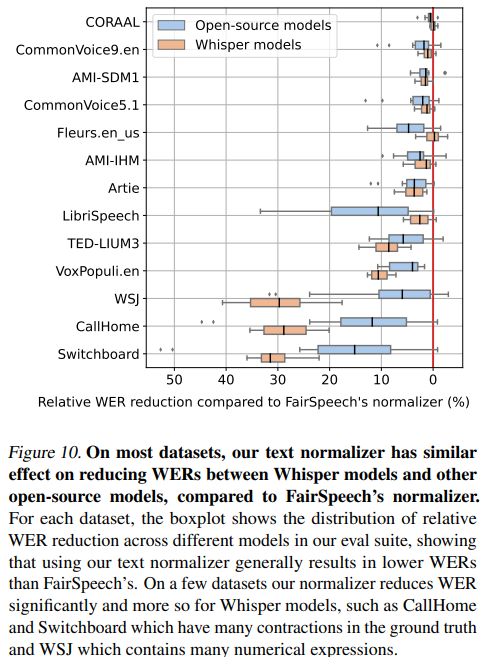
对此作者对比了FairSpeech’s的文本标准化器,结果显示与 FairSpeech 的标准化器相比,我们的文本标准化器在减少Whisper模型和其他开源模型之间的WE 方面具有相似的效果。在一些数据集上,我们的标准化器显着降低WER,对于Whisper模型来说更是如此,例如CallHome和Switchboard。
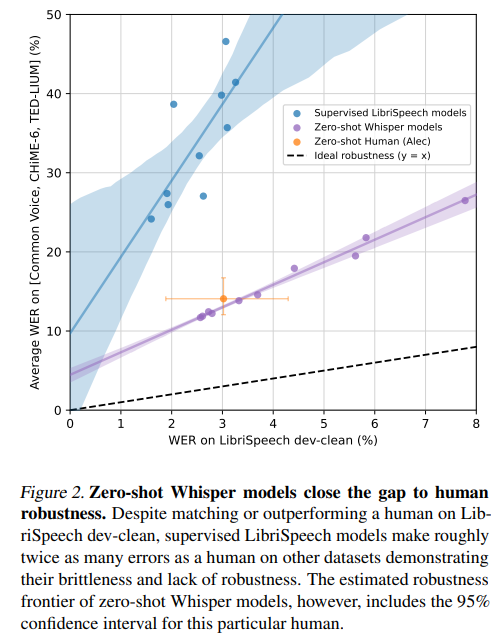
在零样本设置下评估,不用训练集的数据源上做评估。因为在相同数据分布下做评估,看不出泛化性,如下图所示,尽管有监督的LibriSpeech模型在LibriSpeech dev-clean上的表现与人类相匹配或优于人类,但在其他数据集上犯下的错误大约是人类的两倍,这证明了它们的脆弱性和缺乏鲁棒性。
七、实验效果
在语音识别上,英文很不错,中文处于中游。而且从下图的线性拟合估计来看,训练数据每增加16倍,WER预计就会减半。
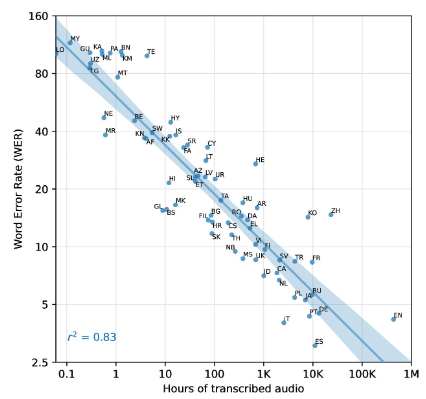
Whisper在各语种下的语音识别的WER(越小越好)
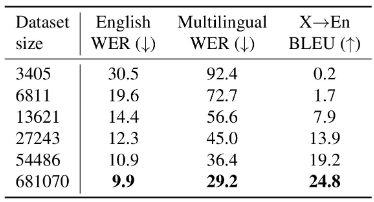
数据集越大,语音识别效果越好
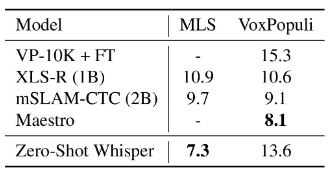
Whisper在Multilingual LibriSpeech (MLS)上表现超过其他模型,在
VoxPopuli 上表现不佳,可能是由于其他模型,将此分布作为其无监督预训练数据的主要来源,并且数据集具有明显更多的监督数据,这有利于微调。
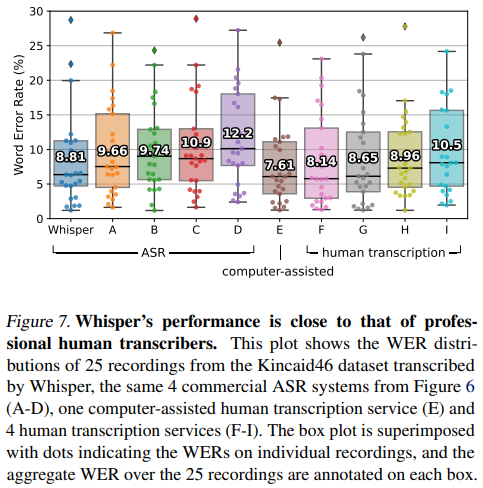
Whisper的英语ASR表现并不完美,但非常接近人类水平的准确性
在翻译X→en上,
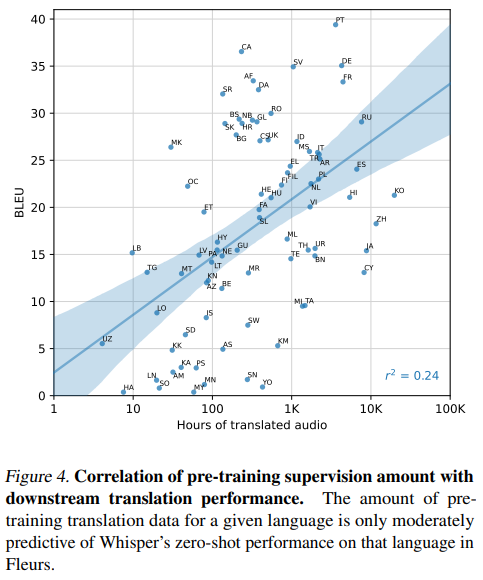
Whisper在X-en下的语音翻译的BLEU(越大越好)
在语言识别上,相比于其他模型,Whisper在Fleurs数据集上的语言识别方面处于严重不利地位,因为Whisper数据集不包含Fleurs 102种语言中20种的训练数据,上限准确度为80.4%。在82种重叠语言上,最好的Whisper模型达到了 80.3% 的准确率。
另外,作者分析了模型对附加噪声的鲁棒性,使用音频降级工具箱中的白噪声或酒吧噪声添加到音频中时,测试Whisper模型和14个LibriSpeech训练模型的噪声鲁棒性。下图显示了随着加性噪声变得更加密集,ASR性能如何下降。有许多模型在低噪声(40 dB SNR)下的性能优于Whisper的零样本性能,这并不奇怪,因为这些模型主要在 LibriSpeech 上进行训练,但随着噪声变得更加密集,所有模型都会迅速退化,性能比Whisper模型更差,这展示了 Whisper 对噪声的鲁棒性。
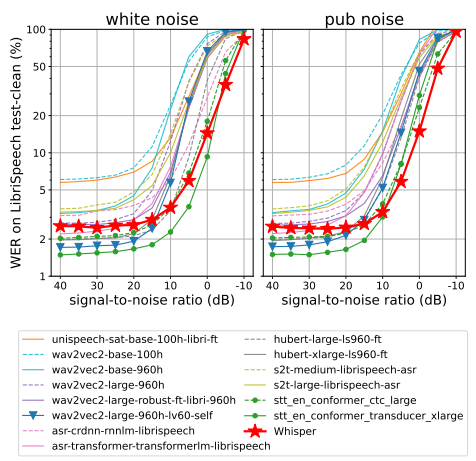
附加噪声的鲁棒性测试
作者分析多语言学习的负迁移,对于小型模型,在多任务和多语言设置中联合训练时,英语语音识别的性能会下降。然而,随着模型参数量增加,多语言和多任务模型从模型规模中获益更多,并最终优于仅使用英语数据训练的模型。
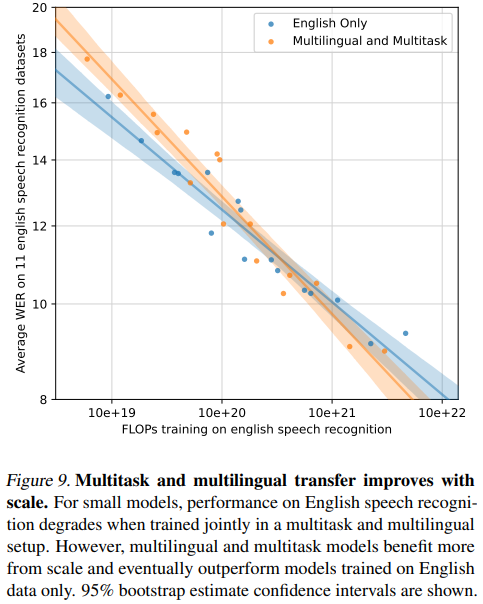
八、未来工作
- 在高质量监督数据集上微调
Whisper 模型和/或使用强化学习更直接地优化解码性能可能有助于进一步减少与感知相关的错误(例如混淆发音相似的单词,长音频转写时陷入重复循环、无法转录音频片段的第一个或最后几个单词或模型将完全产生幻觉等问题);
- 有针对性地增加稀有语言的数据量可能会导致平均语音识别性能的大幅提高;
- 添加辅助训练目标。
出自:https://mp.weixin.qq.com/s/HjExaK5cfIqXuCLIrb2TJQ
Excalidraw是一款免费的在线白板和手绘风格的绘图工具。