AI虚拟主播数字人技术实现Wav2Lip
发布时间:2024年06月06日
本篇是关于AI主播虚拟人的Wav2Lip技术实现与评测,后续还会有其他的相关技术实现与评测。本文主要实现图片说话(如下图的蒙娜丽莎)、视频融合语音(这里的核心都是人物口型与音频中的语音唇形同步)。
主要通过将两个不相关的人的视频、音频,采用Wav2Lip技术,最终得到一个完整的视频文件,且视频的人物口型与音频内容一致。举例:小A的语音、加上小B的视频,融合为一个最终的视频;那么人小A在发出“啊”声音的时候,小B的嘴应该是张开的,以下是一张效果图),本文第五本部分是效果评测!

AI蒙娜丽莎虚拟数字人-虚拟主播
本文目录
第一部分:深度伪造技术概述
第二部分:Wav2lip技术概述
第三部分:使用Wav2Lip进行AI主播虚拟人的深度实践
第四部分:效果评测
第五部分:Wav2Lip完整版教程的下载
注:本案例涉及到所有内容,包括教程、图片、视频、Wav2Lip等均集中打包分享给大家,可自行复现。
正文
第一部分:深度伪造技术概述
深度伪造一词译自英文“Deepfake”(“deep learning”和“fake”的组合)。它是一种利用机器学习的子领域——深度学习创建合成媒体的技术。

公众所熟知知道的一个常见用例是面部交换的应用。目标面孔被交换和合并,通常在第一眼看来是无缝的,以创建一个改变的事件。

在高层次上,Deepfake 可以根据媒体的关注点分为 3 个方向进行更改,即伪造视觉(例如伪造图片或者视频)、伪造音频(例如伪造语音内容等)、伪造视觉及音频(即前两者的结合了,完全都是伪造)。
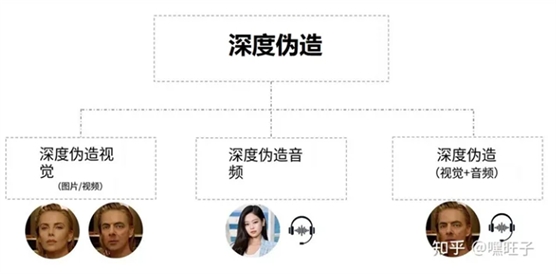
前面提到的用例(面部交换)属于 Deepfake 视觉,其中图像或视频流是目标。 另一方面,Deepfake 音频将来自第三方来源的语音克隆给感兴趣的人。在仅通过电话交流的场景下,可能无法分辨声音的真伪。

一般地,deepfake可划分为如下四类:重现(reenactment),替换(replace),编辑(editing)和合成(synthesis)。 deepfake很重要的一个技术是表情重现,让目标身份的表情模仿源身份的表情(极端一致,很自然与原始目标人物能够表情自然一致)。这在电影和视频游戏行业中具有极大的应用价值,如对演员的表情表演进行后期调整。
第二部分:Wav2lip技术概述
Wav2Lip技术是一个基于GAN的唇形动作迁移算法,实现生成的视频人物口型与输入语音同步。Wav2Lip不仅可以基于静态图像来输出与目标语音匹配的唇形同步视频,还可以直接将动态的视频进行唇形转换,输出与输入语音匹配的视频,俗称「对口型」。该技术的主要作用就是在将音频与图片、音频与视频进行合成时,口型能够自然。
如果您质疑要使用哪个模型文件,存储库中的 readme.md 会指出每个模型的关键属性,如下面的屏幕截图所示。
项目地址:https://github.com/baoxueyuan/Wav2Lip
|
Model |
Description |
Link to the model |
|
Wav2Lip |
高度精确的唇同步 |
Link |
|
Wav2Lip + GAN |
嘴唇同步稍差,但视觉质量更好 |
Link |
|
Expert Discriminator |
专家鉴别器的权重 |
Link |
|
Visual Quality |
在GAN设置中训练的视盘重量 |
Link |
本文着重演示:Wav2Lip与Wav2Lip + GAN,Wav2Lip与Wav2Lip + GAN模型最终的效果对比,可见3.6部分。
第三部分:使用Wav2Lip进行AI主播虚拟人的深度实践
AI主播虚拟人(也可以理解为数字人)是利用人工智能技术创建的一种虚拟角色,可以模拟人类的语言、动作和外貌。它们使用先进的语音合成、人脸识别和动画技术,以逼真的方式与观众互动。AI虚拟主播可以通过深度学习从现实主播的样本中学习,并生成自己的语音和表情。这种技术的应用包括娱乐、广告和教育领域,它们可以在直播平台、游戏或虚拟现实环境中担任主持人、演员或导师角色。AI虚拟主播的出现改变了传统媒体和娱乐产业的格局,并具有巨大的潜力在未来发展。
整个演示实操主要分为以下部分:
3.1 硬件环境准备(智星云)
3.2 下载Wav2Lip包
3.3 Wav2Lip运行环境准备
3.4 上传原视频、音频
3.5 运行
3.1 硬件环境准备
可以用自己电脑,我这边直接用的其他的服务器,是小时付费,价格不等,相对比较划算,我选的是一两块一个小时,这里不做展开
3.2 下载Wav2Lip包
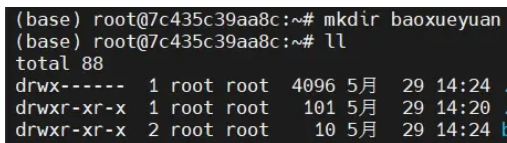
首先创建一个目录:
mkdir baoxueyuan
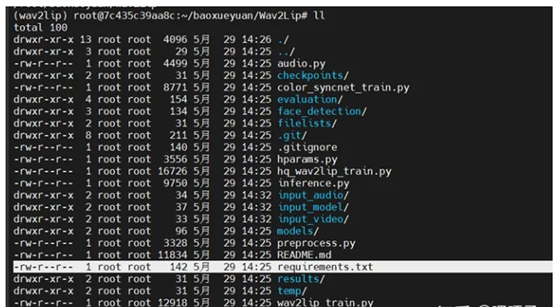
下载:执行下面命令,下载完成之后,用ll看一下,即可看到Wav2Lip
cd baoxueyuan git clone https://github.com/Rudrabha/Wav2Lip.git
https://github.com/Rudrabha/Wav2Lip
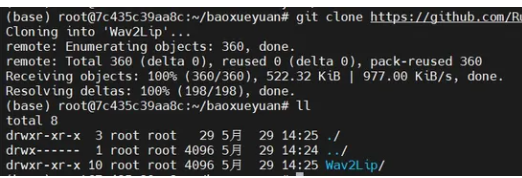
Wav2Lip的文件整体结构
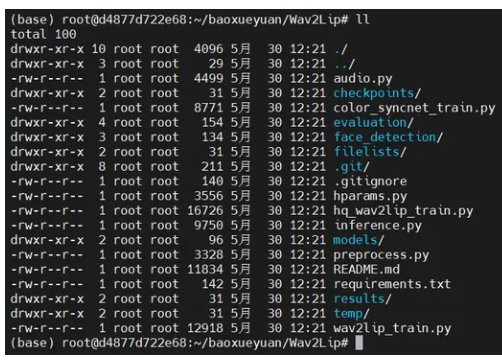
3.3 Wav2Lip运行环境准备
首先运行以下命令
apt-get update apt-get install ffmpeg
进入Wav2Lip目录下,执行以下命令:
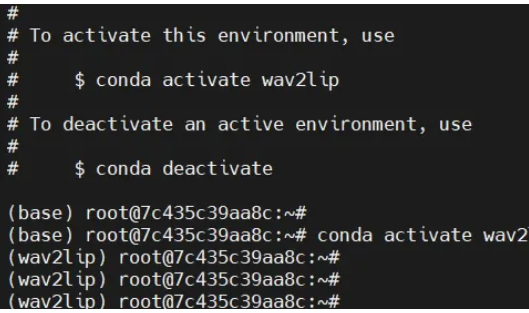
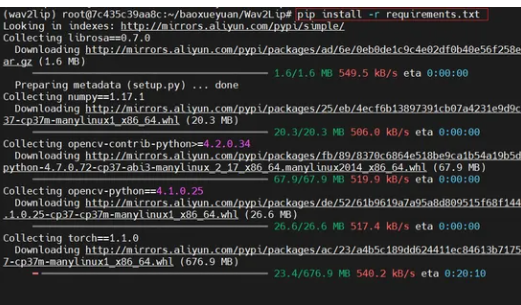
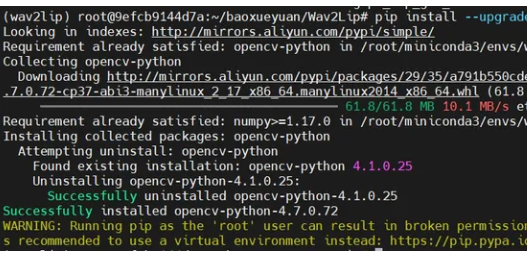
#创建虚拟环境 conda create -n wav2lip python=3.7.1 #激活环境 conda activate wav2lip #安装依赖 pip install -r
requirements.txt #更新一下opencv-python版本 pip install --upgrade opencv-python
以下是相关5张截图供参考:
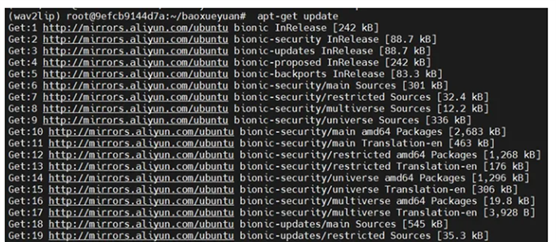
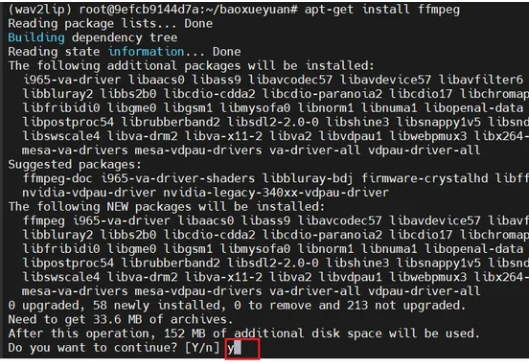
![]()
3.4 上传原视频、音频
创建文件夹
mkdir input_model mkdir input_video mkdir input_audio mkdir input_image
将本地准备好的模型、音频、图片、视频分别上传至上述对应的文件夹下:input_model、input_image、input_video、input_audio。

3.5 运行
注:一定要cd到Wav2Lip的目录下执行
执行命令如下:
python inference.py --checkpoint_path <path-to-model-file> --face <path-to-video-file> --audio <path-to-audio-file>
本案例的命令:
python inference.py --checkpoint_path /root/baoxueyuan/Wav2Lip/input_model/wav2lip_gan.pth --face /root/baoxueyuan/Wav2Lip/input_video/xiaobao.mp4 --audio /root/baoxueyuan/Wav2Lip/input_audio/xiaobao.MP3python inference.py --checkpoint_path /root/baoxueyuan/Wav2Lip/input_model/wav2lip.pth --face /root/baoxueyuan/Wav2Lip/input_video/xiaobao.mp4 --audio /root/baoxueyuan/Wav2Lip/input_audio/xiaobao.MP3 python inference.py --checkpoint_path /root/baoxueyuan/Wav2Lip/input_model/wav2lip.pth --face /root/baoxueyuan/Wav2Lip/input_image/xiaobao.jpg --audio /root/baoxueyuan/Wav2Lip/input_audio/xiaobao.MP3
首次执行会出现一个下载(脸部监测模型):
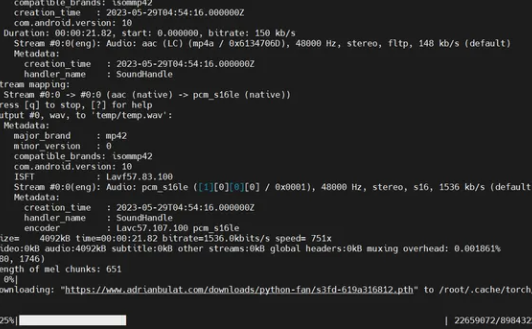
以下视频是执行记录(注意:执行命令中换成对应自己的文件就行,其他无区别)
运行结果,在wav2Lip的results目录下查看即可:
第四部分:效果评测

ImgUpscaler是一款免费的 AI 图像无损放大工具,放大倍数有两个选项:200%和400%