你是否发现ChatGPT甚至不能按字数要求回复问题?有人做了评测并讨论了可能的原因
发布时间:2024年06月06日

Evaluating Large Language Models on Controlled
Generation Tasks
你是否发现ChatGPT甚至不能按字数要求回复问题?有人做了评测并讨论了可能的原因
最近在群里和朋友圈看大家都提到让LLM写固定字数的回复时模型几乎都失效了,在网上看到这篇论文的时候就想怎么这么巧就有人针对这个事情发了论文,合着好像就是群友发的。
虽然最近的研究探讨了LLM在各种基准任务中的能力,但很少有研究探讨LLM在生成任务上的可控性。先前的工作有通过在特定任务上做微调如controlled
paraphrase generation受控改述生成或设置受限解码策略如look-back decoding
strategy回顾式解码策略,作者在这篇工作中在十个基准上对LLM的可控性进行了系统而广泛的分析,包括一个新的简单但具有挑战性的不同粒度的数值规划基准。在将大型语言模型与初始微调的较小模型比较后,作者提出了一个频谱,显示大型语言模型何时落后、可比或超过较小模型的能力。她们得出的结论是,LLM难以满足细粒度的硬约束。
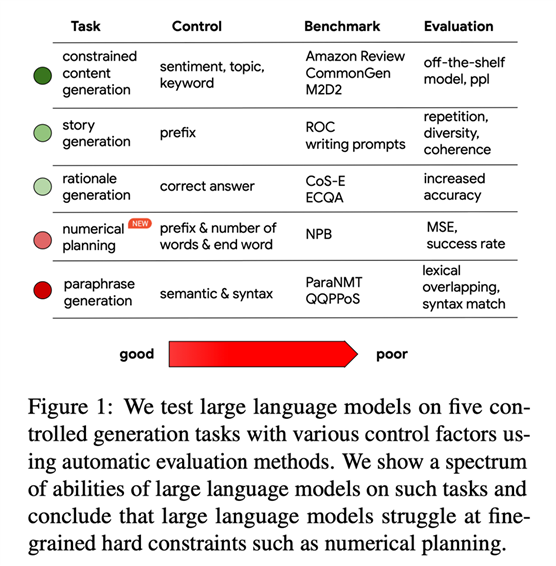
该工作的主要贡献是对LLM在五个任务和十个生成基准上的可控性进行全面分析,其中包括受控故事生成、受控带有情感和主题的自由格式生成、受控改述生成和受控基本原理生成,见figure1。作者进一步设计了一个新的简单但具有挑战性的基准,名为数值规划基准(NPB),其任务是让生成内容满足四个粒度(词级、音节级、句子级和段落级)的数学约束且满足不同的内容约束(例如前缀和结尾)。为进行评估,作者使用自动指标,虽然不完善但方便且可重复。
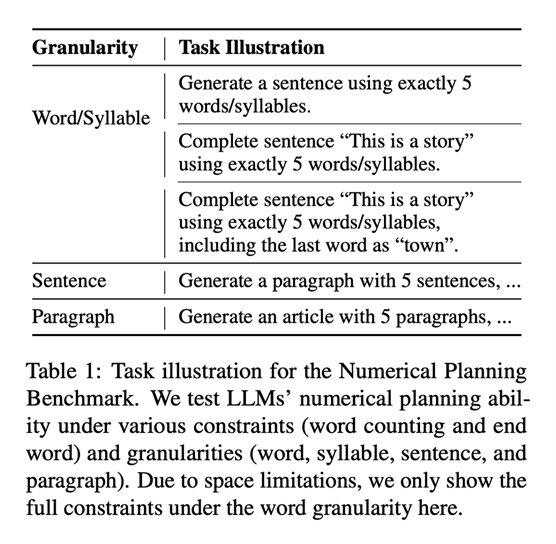
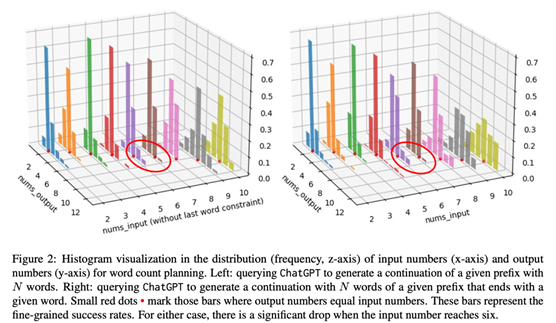
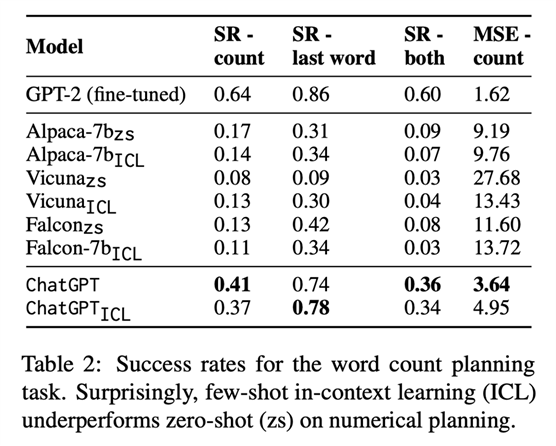
着重提一下作者提出的数值规划基准,她们将其定义为测试LLM的基础数值规划能力,见table1,比如让模型补全某个句子且必须用5个词。因为受现实中大家可能会想要生存特定结构如特定词数的句子或诗的启发,还比如有时候我们可能想要每行开头或结尾遵循某些规则,因此作者将NPM设置成四个粒度,包含对前缀或后缀的要求。她们用成功率与MSE来作为自动化指标。作者对ChatGPT和Alpaca-7b作评估,结果见figure2(可以看到随着被要求词数的变多模型效果在变差,且被要求按某个词作为结尾生成词数一定的句子时比不附加该条件效果会好一些)和table2(可以惊讶地看到在数值规划任务上少样本ICL的结果反而比零样本差)。
作者还对figure1上其他任务做了更多评测,结果详见论文。作者在最后还在文中探讨了大模型缺陷的各种原因,简单总结如下:
1.分词:有分词确实让这些任务更具挑战性(比如子词级别的生成),但作者假定分词不一定影响到了词规划能力,因为分词都会用特殊符号指明词的开始,她们也没发现证据能表明子词对应于音节单位,有研究发现在音节相关数据上进行微调的较小模型如GPT-2-large可以在相同的音节规划任务上实现接近90%的成功率,而ChatGPT 的最多只有37%。
2.解码方法:作者的结果基于温度为0.3的采样,他们也通过更换解码策略如贪心、束搜索和温度分别为0.3、0.7和1.0的采样,对前两者生成方式,结果都很相似与平平无奇,而对于不同温度的采样,作者认为0.3达成了多样性与质量的合理均衡。作者认为他们做了足够多的实验来减少噪声,但仍没有实验证明LLM能比微调的GPT-2做更好。
3.ICL:作者尝试在提示中提供更多NPB示例,但她们惊讶地发现,一旦数字N没出现在示例里,示例都没卵用。该结果和其他论文中认为LLM并没有通过ICL真正理解任务定义相呼应。
关于如何提高:作者鼓励两个方向的探索:1)链/树/思维图推理,2)结合LLM与非自回归生成能力(如,NADO)。对于第一个,可以尝试简单的思维链/树/思维图提示,甚至可以尝试使用思维链/暂存对进行预训练的LLM,毕竟这些可能有利于数学推理。但这并非从根本上解决规划问题。显然,自回归生成下一个标记将导致模型不“回顾”并因此不遵守细粒度控制信号的问题。
因此,作者鼓励研究人员利用LLM研究多步骤规划和迭代修正,或更根本地改变LLM的自回归架构。
出自:https://mp.weixin.qq.com/s/bLg-yYUscrrG5Ps8FUwO2Q
抖抖侠,它可以帮助商家更加高效地进行短视频数据运营,并且助力达人数据增长。