SDXL模型lora训练参数详细设置,显存占用22G,不用修脸原图直出
发布时间:2024年06月06日
很多人纠结lora训练用谁的脚本比较好,比如kohya_ss的、秋葉aaaki的、赛博炼丹炉的……
昨天我看了下kohya_ss的,感觉界面还是有点复杂,所以我还是最推荐秋叶的,秋叶也是用的kohya的脚本集成的,现在更新到最新版本,就可以训练SDXL模型的lora了。
还没装的,去秋叶大佬视频详情里找一下哈~
https://www.bilibili.com/video/BV1AL411q7Ub/?spm_id_from=333.999.0.0&vd_source=18caf3a918a59f150e3802eab1fc119e
想训练SDXL的模型,首先要调到专家模式,然后从上到下讲一下我的设置。
第一行模型种类的选项,选择sdxl-lora就可以了。

底模路径写好,选择SDXL的底模,我没有用VAE。
训练路径写好,比如我的训练路径是./train/star9,那么star9下应该包含20_star9的文件夹,在文件夹下才是我的图片和标签。
注意,训练SDXL的图片要是1024*1024的。
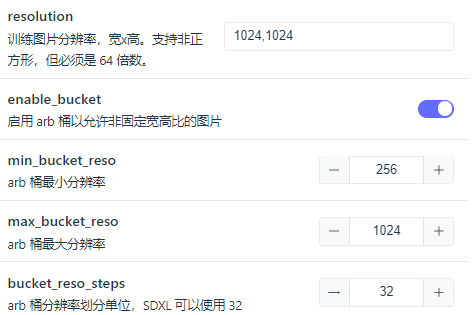
bucket_reso_steps这个设置,提示SDXL可以用32的,我就调成了32。
保存设置,这里我的模型保存精度选择bf16:

因为我训练的精度也选的是bf16,速度优化选项里可以看到:
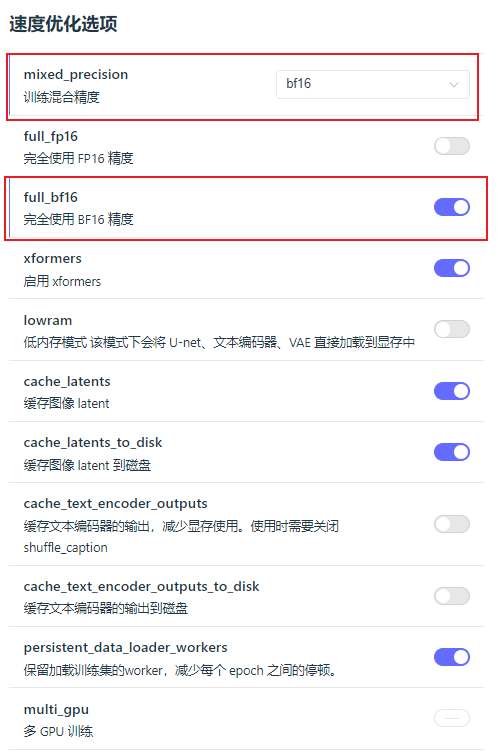
如果显存小点,16G的话选择fp16就行。
训练相关参数没改啥,一般我都是step20,epoch10。
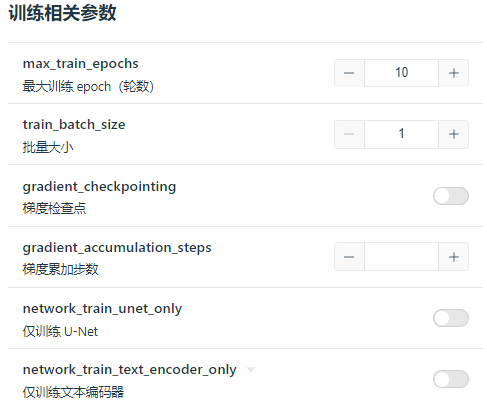
如果显存小,也可以只训练unet试试。
优化器选择的经验,我之前在纯小白想开训lora?参数设置看这一篇就够用了这里讲过DAdaptation,而Prodigy是DAdaptation的升级版,它会随着步数增加寻找最优的学习率。
所以在学习率优化器设置里,把学习率都设置为1,学习率调度器选择constant,优化器设置为Prodigy。
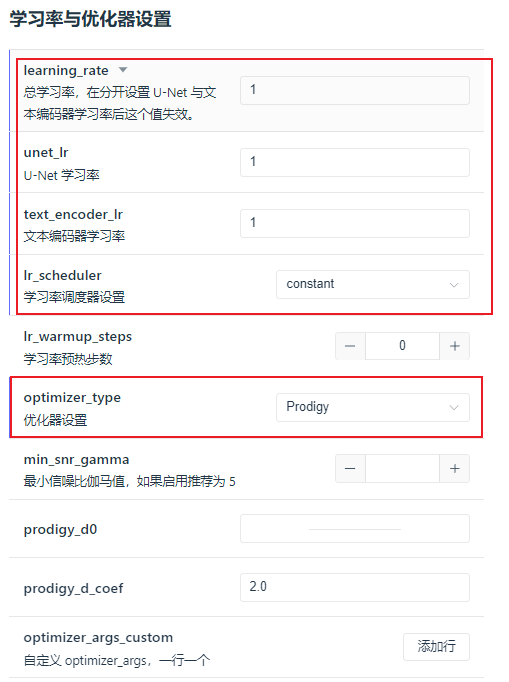
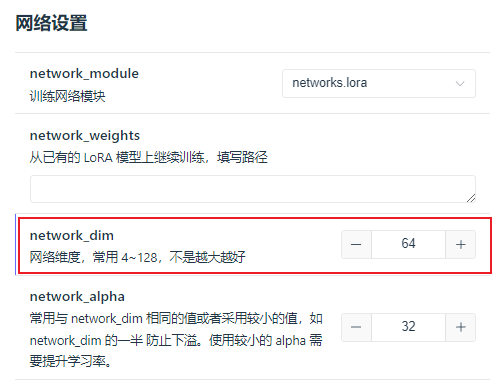
其他的,可以把网络维度改成64,再高就不需要了。如果dim是32,出来的lora模型是217MB,如果是64,出来的是435MB。
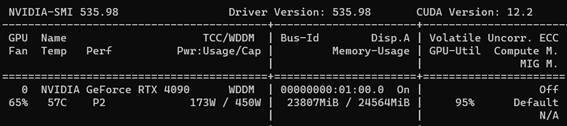
其他就不用改了,一键开训就行,然后我的显存占用就变成了这样:
今天只是教大家用神童优化器这个方法,用了它你会发现损失降了~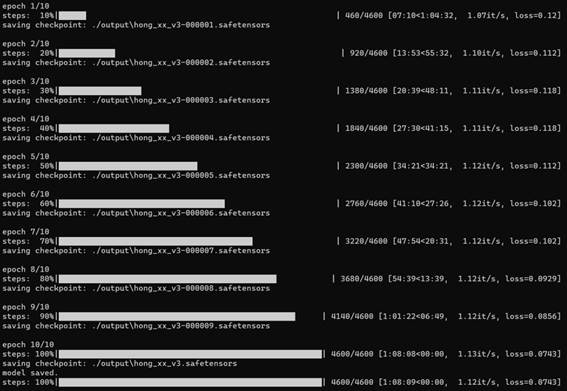 但是!这个数据集里有几张照片是糊的,所以这个版本学出来也是糊的,最后的结果还不如我用lr调度器cosine_with_restarts、优化器AdamW8bit,dim32,损失值在0.1的效果好……
但是!这个数据集里有几张照片是糊的,所以这个版本学出来也是糊的,最后的结果还不如我用lr调度器cosine_with_restarts、优化器AdamW8bit,dim32,损失值在0.1的效果好……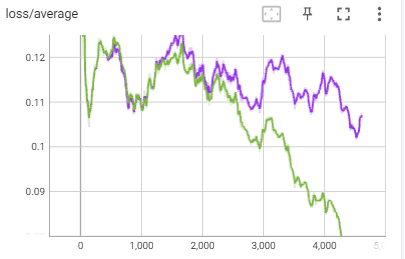 也就是紫色线那次训练,其实出图效果很不错,而且XL模型根本都不用AD修脸,直出就很绝。很多时候,不必太纠结于损失降没降,因为过低的损失可能就是过拟合了,尤其是你数据集有问题的时候,脏数据就直接把训练方向带偏了。
也就是紫色线那次训练,其实出图效果很不错,而且XL模型根本都不用AD修脸,直出就很绝。很多时候,不必太纠结于损失降没降,因为过低的损失可能就是过拟合了,尤其是你数据集有问题的时候,脏数据就直接把训练方向带偏了。
反而是默认优化器和学习率,训练出的效果更好。
出自:https://mp.weixin.qq.com/s/RBkReoa7dfNGKlA4vJ_CBg
Topjianli通过大量实用的提示及范例制作在线简历,可帮助您创建一份完美的个人简历,找到梦寐以求的工作。