自动优化Prompt:Automatic Prompt Engineering的3种方法
发布时间:2024年06月06日
引言
记得Zero-Shot COT[1]里的那句Let's think step by step吗?最近谷歌通过OPRO[2]找到了更好的一句:Take a deep breath and work on this,让GSM8K的结果直接从71.8% -> 80.2%。
problem step-by-step
好的prompt可以激发LLM的最大潜能,从而在下游任务取得好的效果。
Prompt的魅(玄)力(学)就在这里。在LLM还不够“聪明”之前,人类通过prompt
engineering来驯服LLM。
本文介绍3种automatic prompt engineering框架:APE[3]、APO[4]以及OPRO[2]。给定一个训练集,定义好评价指标,运行automatic
prompt engineering框架之后,将自动得到能取得最佳效果的prompt。
无论是想“提分”、还是想优化LLM标注器的效果、或是想根据用户反馈来优化Prompt进而提升产品体验,这些方法都可以借鉴。
APE:candidate -> selection -> resample
APE的核心思路是:从候选集中选出好的prompt,再在好的prompt附近进行试探性地搜索。
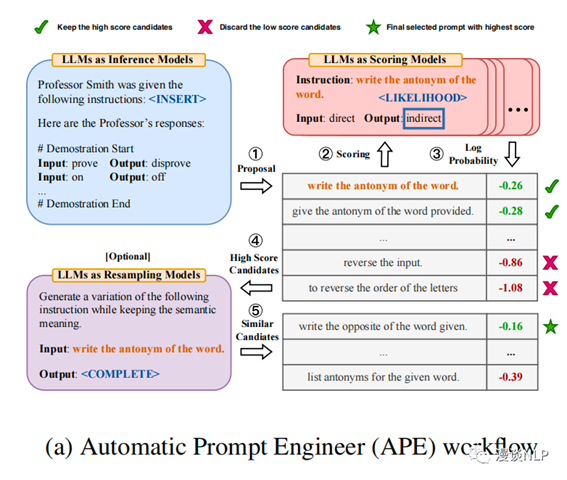
APE可分为以下3个步骤。
第一步:生成prompt candidates
生成prompt的工作也交给了无所不能的LLM,作者介绍了2大类生成方式:
·forward mode。常规生成模式,提供一些任务examples,让LLM在最后生成prompt。示例如下。

·reverse mode。即insert模式,将待生成的prompt放到examples前面,让LLM用填空的方式写prompt。示例如下。

直观理解,reverse mode更加自然,forward mode则更加考验模型的instruction following能力。
补充:GPT系列支持insert模式;Open
AI的这篇论文[5]讲解了insert模式的实现原理。
第二步:在训练集上打分,并保留高分prompt
打分方式有两种:
Execution accuracy。在训练集上执行prompt后,得到的任务metric(如Accuracy、F1等)
Log probability。不使用任务metric,而是评估生成desired answer的概率
实验表明,Execution
accuracy的效果更好。
另外,这一步如果在全量训练集上评估,则开销非常大,因此作者提出一种multi-stage策略。大致思想是先在少量subset上评估,然后过滤掉比较差的,循环这一过程直到候选集足够小,此时再在全量训练集上进行评价、挑选。
第三步:在高分prompt附近进行采样,模拟Monte-Carlo Search过程
这一步核心是尝试性地resample,生成语义相似的prompt,看看能否取得更好的效果。这一过程是可迭代的。
resample的工作仍然交由LLM,其prompt如下。

作者实验发现,对于比较难的任务,进行resample能够进一步提升效果。
APO:gradient descent in language space
APO的核心思路是在文本空间实现gradient
descent过程。

总体而言,APO分为以下3个步骤。
第一步:得到当前prompt的“gradient”
给定一批error samples(当前prompt无法预测正确的),让LLM给出当前prompt预测错误的原因,这一原因即文本形式的“gradient”。
生成gradient的prompt如下。

第二步:应用“gradient”,得到new prompt
这一步还分为2个子步骤:
·子步骤1:使用LLM来edit原来的prompt,目标是修复“gradient”。给到LLM的prompt如下。


·子步骤2:和APE一样,进行resample,扩充相似语义的prompt。
第三步:挑选出好的prompt,进入下一轮迭代
这里面临的问题和APE一样:如果在全量训练集上评估各个prompt,花销太大。
作者提到,挑选prompt的过程就是多臂老虎机问题。
·n arms对应n个prompt candidates
·在任务数据集上的表现是这个arm的hidden
value
·pulling这个动作对应在随机采样的数据上评估prompt的效果
因此,作者试验了3种bandit selection技术:UCB、UCB-E和Successive Rejects。实验表明,UCB和UCB-E的效果比较好。
最后,需要补充的是,APO在每轮迭代中,最外层包含一个beam search过程,以便强化探索。
更详细的内容请读者参阅原论文。
OPRO:LLM as optimizer
APO本质上也是在构建一个optimizer,但其框架是参照gradient decent来设计的。
而谷歌提出的OPRO,其思路更为原生。
OPRO的核心思路是让LLM基于过往的迭代记录、优化目标,自己总结规律,逐步迭代prompt,整个过程在文本空间上完成。
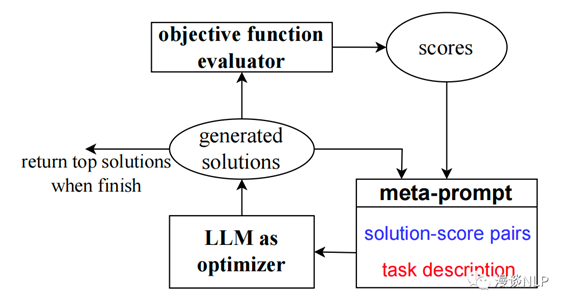
OPRO框架如下。
·使用meta-prompt,让LLM成为Optimizer LLM。meta-prompt包含两个核心部分:一个是solution-score pairs,即以往的迭代路径,包括solution(即prompt) + 分数(任务表现),实践中按照分数大小,从低到高排列top20的结果;另一个是task description,包含一些任务的examples、优化的目标等。GSM8K任务上的meta-prompt如下。

基于对过往迭代规律的理解,Optimizer LLM生成新的solution。即将meta-prompt给到Optimizer
LLM,生成的内容即为新的solution。在实践中,为了提升优化的稳定性,这一步重复了8次。
在Scorer LLM上应用prompt(即新的solution),评估效果并记录到meta-prompt中,然后继续下一轮迭代。注意,这里的Scorer LLM是实际使用prompt的LLM,与Optimizer
LLM可以是不同的。
当效果无法再提升、或者到达预先给定的step上限,整个迭代过程停止。返回得分最高的prompt作为优化结果。
OPRO的定位是基于文本的optimizer,prompt optimization只是其应用场景之一,论文作者还在linear
regression和traverling salesman problem上进行了实验。
总结
本文介绍了3种automatic prompt engineering框架,其中APE的主要思路是挑选+试探性优化,优化的方向性较弱;APO和OPRO则应用了更完整的optimizer框架,其中APO基于gradient descent,本质是基于error case来调优,而OPRO直接依靠LLM的逻辑推理能力,基于迭代过程的规律进行优化。
理论上,这些框架对各类任务(分类、抽取、生成等)是通用的,只需定义好评价指标即可。
因此,只要你的场景里使用了Prompt,都可以考虑使用这些方法、或者借鉴这些方法的思路。例如:在benchmark上提分、优化LLM标注器的效果、根据用户反馈优化Prompt等等。
以第三点为例,读者可以根据用户的反馈数据,训练一个reward model作为评价者,运行automatic prompt
engineering框架,优化现有的Prompt,这一点和RLHF有异曲同工之处。
出自:https://mp.weixin.qq.com/s/kbZZUoTjLGyU59B3strwVg
Blenny AI是一个截取网页的任何部分,Blenny 将立即帮助您总结、翻译、应用自定义代理等的AI工具