无限逼近真人效果的“超真实人像大模型”,或许它才是你一直在寻找的真爱!
发布时间:2024年06月06日
“虽然网络上面的文本生成图片的扩散大模型已经铺天盖地,但是使用过的朋友应该都知道它们大多数的实际应用效果并不尽人意!大模型生成的很多图片的真实性与细节还有待进一步的改进,距离真正的零门槛上手还有一些难度。本文给大家推荐一个针对超高清人像的扩散大模型-HyperHuman,或许它才是你一直在寻找的真爱!”
项目主页-https://snap-research.github.io/HyperHuman/
论文链接-https://arxiv.org/abs/2310.08579
代码链接-https://github.com/snap-research/HyperHuman
01-人像生成模型发展历程
o
2023年,Dustin
Podell, Zion English等人提出“ Sdxl: Improving latent diffusion models for high-resolution image
synthesis. ”算法。该论文的核心内容是关于改进潜在扩散模型(latent diffusion models)以提高高分辨率图像合成的能力。作者提出了一种名为Sdxl的模型,通过在低分辨率图像上进行多步骤的潜在扩散操作,逐渐生成高分辨率图像。为了改进模型的性能,作者还引入了一种新的损失函数,用于在训练过程中对生成图像进行优化。
o

o
o
2023年,由DeepFloyd实验室开源了DeepFloyd算法。DeepFloyd I是一种新颖的开源文本到图像模型,具有高度的照片真实性和语言理解能力。DeepFloyd IF是一个由一个冻结文本编码器和三个级联像素扩散模块组成的模块:一个基于文本提示生成64x64像素图像的基础模型和两个超分辨率模型,每个模型都设计用于生成分辨率不断提高的图像:256x256像素和1024x1024像素。模型的所有阶段都使用基于T5转换器的冻结文本编码器来提取文本嵌入,然后将其输入到通过交叉注意力和注意力池增强的UNet架构中。
o
o
2023年,Xuan
Ju, Ailing Zeng等人提出“ Humansd:
A native skeleton-guided diffusion model for human image generation.
”算法。HumanSD是一种用于可控HIG的原生骨架引导扩散模型。作者没有使用双分支扩散来执行图像编辑,而是使用一种新的热图引导的去噪损失来微调原始SD模型。该策略在模型训练过程中有效地增强了给定的骨架条件,同时减轻了灾难性的遗忘效应。
o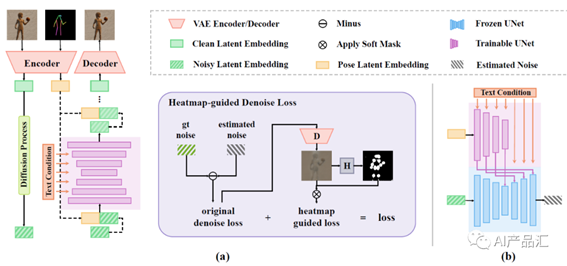
2023年,Lvmin
Zhang and Maneesh Agrawala等人提出“Adding
conditional control to text-to-image diffusion models.”算法。该论文的核心内容是在文本到图像扩散模型中添加条件控制,以提高生成图像的质量和多样性。该论文提出了一种新的条件控制方法,通过将文本向量和图像向量进行拼接,将文本信息引入到生成图像的过程中。此外,该论文还引入了一个新的条件控制方式,即在生成图像的过程中,通过动态地调整条件向量的值来控制生成图像的属性。
o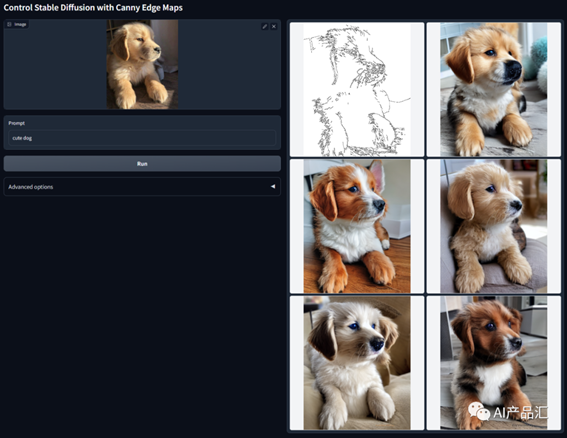
o2023年,Chong Mou, Xintao Wang等人提出“T2i-adapter: Learning
adapters to dig out more controllable ability for text-to-image diffusion
models.”算法。该论文的核心内容是通过学习适配器来挖掘更多的可控能力,以提高文本到图像扩散模型的性能。该论文使用适配器网络来学习文本到图像扩散模型中的可控属性。适配器网络是一种轻量级的网络结构,通过在主网络中添加适配器模块来实现对特定属性的控制。通过在适配器网络中引入属性嵌入向量和属性控制向量,可以在生成图像的过程中控制特定属性的表达。该方法能够通过学习适配器网络来挖掘更多的可控能力,提高生成图像的质量和多样性。
02-HyperHuman算法简介

尽管在大规模文本到图像模型方面取得了重大进展,但实现超逼真的人体图像生成仍然是一项令人向往但尚未解决的任务。现有的模型,如稳定扩散和DALL·E2,倾向于生成具有不连贯部分或不自然姿势的人体图像。为了应对这些挑战,作者提出了一种新的思路:从粗略的身体骨架到细粒度的空间几何,人类图像在多个粒度上具有内在的结构。因此,在一个模型中捕捉外显外观和潜在结构之间的这种相关性对于生成连贯自然的人类图像至关重要。
HyperHuman是一个用来生成超逼真人像的结构扩散模型。具体而言,1)作者首先构建了一个大规模的以人为中心的数据集,名为HumanVerse,该数据集由340M张图像组成,其中包含人体姿态、深度和表面法线等全面注释。2) 作者提出了一个潜在结构扩散模型,该模型同时对深度和表面法线以及合成的RGB图像进行去噪。该模型在一个统一的网络中强制执行图像外观、空间关系和几何的联合学习,其中模型中的每个分支都以结构意识和纹理丰富性相互补充。3) 最后,为了进一步提高视觉质量,作者提出了一种结构引导的细化器来组成预测条件,以更详细地生成更高分辨率的图像。03-HyperHuman算法流程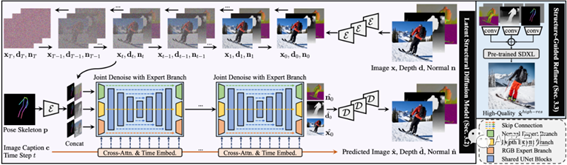
该算法主要由潜在结构扩散模型和结构引导细化器两部分组成。在潜在结构扩散模型(紫色)中,图像x、深度d和表面法线n是在字幕c和姿势骨架p的条件下联合去噪的。在结构引导细化器(蓝色)中,作者将根据多个输入信息获得了更高分辨率生成的预测条件。详细的步骤如下所示。
o首先,同时针对输入的深度图、表面法线图以及合成的RGB图像执行去噪操作;
o然后,将去噪之后的输出、经过变换之后位姿骨架p和t时刻的图片标注c 拼接起来;
o接着,将该特征映射送入多个Cross-Atten & Time Embed模块中获取特征表示,并输出预测的彩色图、深度图和表面法线图;
o
最后,分别针对上面的输出提取特征表示,并将其送入预训练的SDXL模型中,获取最终的高分辨率输出结果。
o
04-HyperHuman实现细节 上图展示了隐结构扩散模型和结构性导向细化器的实现细节。隐结构扩散模型的关键信息如下所示:
上图展示了隐结构扩散模型和结构性导向细化器的实现细节。隐结构扩散模型的关键信息如下所示:
o利用SD-2.0作为基础的预训练模型;
o利用OpenCLIP作为对应的文本编码器;
o该模型采用了SiLU激活函数,并添加了时间嵌入信息;
o
该模型的批大小为2048,衰减因子为0.01,学习率为1e-5,训练阶段每1000次采样一次,Adam优化器的关键参数为0.9和0.999;
o
05-HyperHuman性能比较
05.01-主观效果展示与分析

图5.1-不同算法比较效果1

图5.2-不同算法比较效果2

图5.3-不同算法比较效果3

图5.4-不同算法比较效果4

图5.5-不同算法比较效果5

图5.6-不同算法比较效果6

图5.7-不同算法比较效果7

图5.8-不同算法比较效果8

图5.9-不同算法比较效果9

图5.10-不同算法比较效果10

图5.11-不同算法比较效果11

图5.12-不同算法比较效果12
上图展示了该算法与ControlNet、T2I-Adapter、HumanSD、SD
v2.1、DeepFloyd-IF、SDXL、T2I-Adapter+SDXL多个STA算法根据相同的文本提升生成的输出图片效果。通过仔细观察与分析,我们可以得出以下的初步结论:
o输入相同的文本提示,HyperHuman与T2I-Adapter+SDXL算法生成的图片更加逼真,更符合文本描述;
oHumanSD算法生成的图片偏灰色系,更抽象一些,缺少一些细节信息;
o
虽然ControlNet也能生成较逼真的图片,但是有时生成的图片中包含着一些较明显的虚假信息;
o
05.02-客观指标评价与分析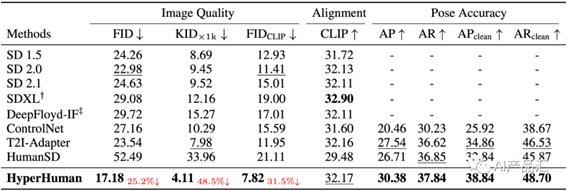 上表展示了该算法与ControlNet、T2I-Adapter、HumanSD、SD v2.1、DeepFloyd-IF、SDXL、T2I-Adapter+SDXL多个STA算法的客观评价指标。作者主要从图像质量、对齐、位姿准确率3个大的维度展开。通过观察与分析,我们可以得出以下的初步结论:
上表展示了该算法与ControlNet、T2I-Adapter、HumanSD、SD v2.1、DeepFloyd-IF、SDXL、T2I-Adapter+SDXL多个STA算法的客观评价指标。作者主要从图像质量、对齐、位姿准确率3个大的维度展开。通过观察与分析,我们可以得出以下的初步结论:
oHyperHuman算法生成的图像质量明显优于其它的STA算法,与第二名之间具有较大的差距;
o针对Alignment而言,HyperHuman获得了次优的结果,与第一名之间存在较小的差异;
o
从位姿准确率角度来讲,该算法输出的位姿准确率更高。
o
06-HyperHuman效果展示

图6.1-算法生成效果1

图6.2-算法生成效果2

图6.3-算法生成效果3

图6.4-算法生成效果4

图6.5-算法生成效果5

图6.6-算法生成效果6

图6.7-算法生成效果7
图6.8-算法生成效果8

图6.9-算法生成效果9

图6.10-算法生成效果10
上面展示了HyperHuman在一些文本提示下同时生成基于文本和骨架的粗略RGB、深度、法线和高分辨率图像的效果。看了这些输出效果之后,你是不是有跃跃一试的冲动。
人工智能加成的灵感和创作工具