姜子牙大模型系列 | 为知识检索而生,Ziya-Reader开源,多个长文本中文任务第一
发布时间:2024年06月06日
我们几乎每天都使用搜索引擎,搜索是大模型需求最多的落地应用之一。另外,大模型本身有着幻觉问题,检索增强也是最直接的解决方案。此外,基于大模型进行知识库问答、基于大模型的智能客服也是火热的创业项目。因此,关于检索增强的大模型的研究如火如荼,为了能从多个文档或超长文档中找到答案,各种超长上下文窗口的模型已经陆续发布。
但是研究者们发现了一个问题,即使是额外扩展上下文窗口的大模型,从16k的GPT3.5到100k的Claude,面对多文档问答任务时,如果正确答案不在第一个或末尾的文档中,模型的回答准确率就会急剧下降。如下图所示[1]。这个问题极大地限制了大模型在搜索中的应用。
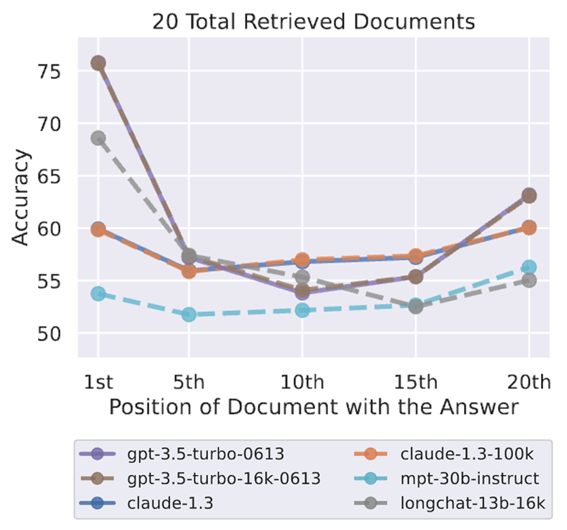
图1
这个现象在中文模型上同样存在。我们在权威数据集,LongBench多文档问答任务中测试了GPT3.5-turbo-16k和ChatGLM2-6B-32k[2]。结果显示,只需打乱文档的顺序,模型的回答Rouge指标就会下降多达17%。似乎,模型并非真的知道哪个答案相关,只是根据位置进行猜测。
为了解决这个问题,推进大模型在搜索中的应用,我们的Ziya-Reader应运而生。当给出问题和多个检索结果时,Ziya-Reader可以从多个候选中找到正确的答案,准确地回答问题。该模型具有8k的上下文窗口,相比其他具有更长窗口的模型,我们在多个长文本任务的评测中胜出。
Ziya-Reader-13B-v1.0开源地址
Hgggingface地址:
https://huggingface.co/IDEA-CCNL/Ziya-Reader-13B-v1.0
ModelScope地址:
https://modelscope.cn/models/Fengshenbang/Ziya-Reader-13B-v1.0/
多项长文本中文任务第一
清华大学发布的公开数据集LongBench用于衡量长上下文的情况下模型的各项能力。在其中的中文多文档问答的测试集上,Ziya-Reader的RougeL最高达到45.1%,中位数为42.8%,领先此前最强的ChatGLM2-6B-32k达7.5%,相较于GPT3.5绝对提升16.4%,见表1。
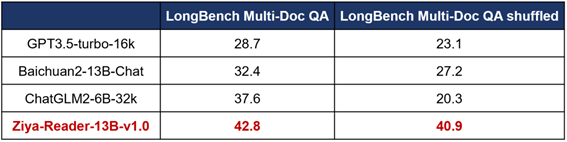
我们发现LongBench的Multi-Doc QA测试集中正确文档往往排在前面的问题,不能准确反映模型甄别相关文档的能力,对文档打乱顺序,再次测试各个模型的效果,见表2。结果发现Ziya-Reader的效果降幅不到2%,达到40.9%,非常鲁棒。而ChatGLM2-6B-32k、GPT3.5-turbo-16k等模型有显著下降,绝对降幅分别达到17.3%和5.6%。因此,Ziya-Reader面对无论是准确排序的还是相对乱序的文档,均优势显著,可用于各种检索结果问答。
表1
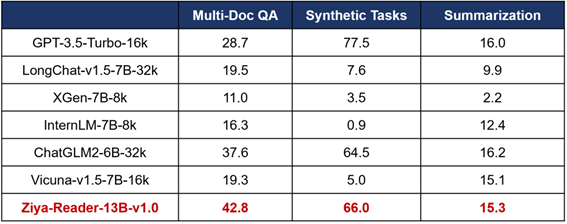
另外,在中文合成任务(摘要检索任务)上,Ziya-Reader以66%的得分超越ChatGLM2-6B-32k,成为开源模型第一名。该任务给定一个摘要,需要从众多段落中找出该摘要对应的出处,考验模型的语义匹配能力,显示了Ziya-Reader在这方面依然强大。
而在长文档摘要生成任务中,Ziya-Reader同样出色,在同样8k上下文窗口上的模型中第一。即使只有8k的“内存”,与16k或更长窗口相比差距不到1%。这显示了模型扎实的记忆力和注意力,并不会长而不实用。
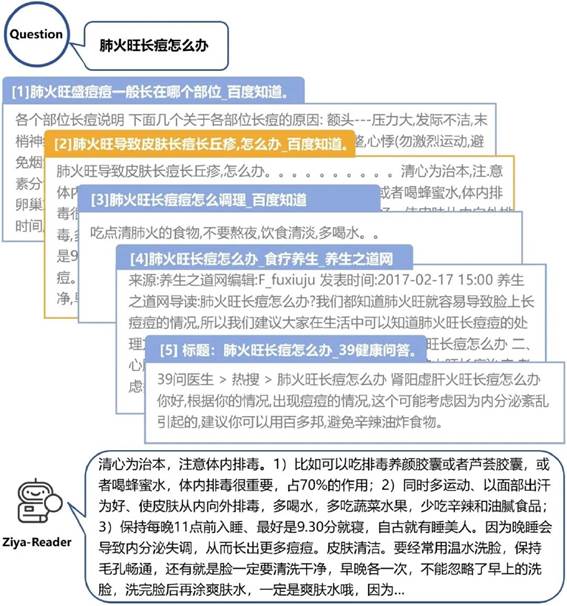
图2.多文档问答样例
搜索Agent 超越OpenAI,开源最强
除了Ziya-Reader,我们还自建了向量检索模型,用于从知识库中召回相关文档。我们构建了金融知识库和测试数据,用于测试在整个搜索系统流水线的效果。我们使用最强的开源向量模型M3E与ChatGLM2-6B-32k组成的检索系统作为基线,以及OpenAI最强向量模型Ada002和GPT3.5-turbo-16k作为上限,测试效果,发现超越了OpenAI,结果如图3所示。Ziya-Reader和我们的自建向量模型Ziya-Embedding达到90.8%的准确率,基于Ziya-Reader的Ziya-Searching-Agent则达到了92.5%。该Agent基于Ziya-Reader的判断能力,对无相关上下文的情况进行再次检索,有效提升效果。
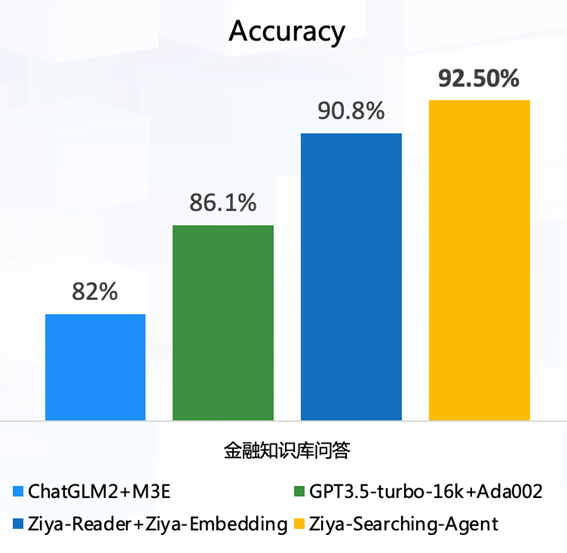
图3
通用能力大幅超越Ziya-Llama-v1.1
另外,Ziya-Reader的通用能力同样出色。我们在自建的通用能力测试集上进行评估(包括常识、代码、翻译、问答、写作、推理、数学、角色扮演、NLU 和无害性等方面),side-by-side效果显示,对比经过人类反馈学习的通用模型Ziya-Llama-v1.1,Ziya-Reader有着65.7%的胜率(超过50%为胜),如表2所示。
表2

Ziya-Reader是如何养成的
不仅搜索相关能力惊人,通用能力也超越通用模型的Ziya-Reader,堪称硬核小钢炮。那么它是如何炼成的呢?
首先,模型要有足够的上下文输入能力,因此我们使用了位置插值(PI)[3]的方式,在精选的长文档语料上进行微调,扩展上下文到8k大小。其次,模型靠数据喂养,我们从近千万数据中筛选高质量数据,仅用层层过滤的10万量级的数据即可将一个平平无奇的模型培养成知识问答小钢炮。另外,我们为搜索任务量身定做了特殊的任务,精心制作了数据,让模型学会从中寻找相关文档并回答问题。最后,借助问题感知的上下文表示以及思维链技术,让模型的效果锦上添花。更多的技术细节我们将会在技术报告中公布,敬请期待。
Ziya-Reader作为阶段性的成果,效果令人惊喜,但是依然存在着提升的空间,需要持续改进。我们未来会朝着有自我认知、全方位信息融合的知识问答智能体努力,最终解放用户、提供更智能的知识问答体验,请大家继续关注!
Ziya-Reader-13B-v1.0开源地址
欢迎点击下方链接体验

Hgggingface地址:
https://huggingface.co/IDEA-CCNL/Ziya-Reader-13B-v1.0
ModelScope地址:
https://modelscope.cn/models/Fengshenbang/Ziya-Reader-13B-v1.0/
参考文献
[1]Liu, NelsonF, et al. Lost in the Middle: How Language
Models Use Long Contexts.Jul 2023.
[2]Bai,Yushi,et al. LongBench: A Bilingual, Multitask
Benchmark for Long Context Understanding. Aug 2023.
[3]Chen, Shouyuan, et al. Extending Context Window of Large Language
Models via Positional Interpolation. Jun 2023
出自:https://mp.weixin.qq.com/s/ucrvoTKBgQZZJxbr2NFP6g
Ai工具集导航(AI-Bot.cn)专注于收录和推荐国内外热门、创意、有趣、前沿的AI工具和网站,致力于为大家提供一个快速访问任意人工智能网站的门户和入口。