Stable Diffusion教程:文生图
发布时间:2024年06月06日
最近几天AI绘画没有什么大动作,正好有时间总结下Stable Diffusion的一些基础知识,今天就给大家再唠叨一下文生图这个功能,会详细说明其中的各个参数。
文生图是Stable Diffusion的核心功能,它的核心能力就是根据提示词生成相应的图片。
本文以 Stable Diffusion
WebUI 为例,使用方法参考下图:
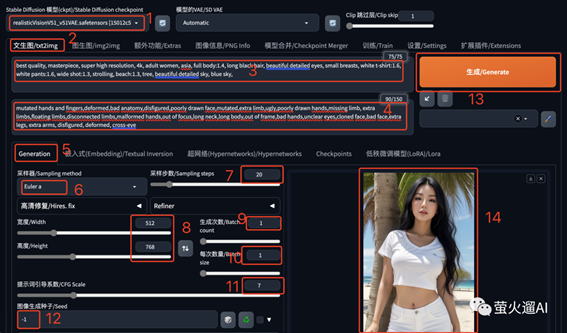
1、基础模型:选择一个用来生成图片的模型,不同的模型可以生成不同风格的图片。
2、文生图/txt2img:这一排是 WebUI 的主功能菜单,默认选中的就是文生图。
3、提示词:提示词就是我们的绘画指令,描述图片中的内容,描述越详细则生成的图片越符合预期。可以使用中文,不过建议用英文,网上分享的提示词也都是英文的。
例子中的提示词是:
best quality, masterpiece, super high
resolution, 4k, adult women, asia, full body:1.4, long black hair, beautiful
detailed eyes, small breasts, white t-shirt:1.6, white pants:1.6, wide
shot:1.3, strolling, beach:1.3, tree, beautiful detailed sky, blue sky,
提示词很重要,后边会有专门的文章来介绍它,这里分享一个提示词的常用套路:图片的质量、主体、细节,比如这里 best quality, masterpiece 都是用来声明图片质量的,adult
women, asia, full body 是主体,后边的 long black hair,
beautiful detailed eyes, small breasts 都是细节描述。
4、反向提示词:描述不希望在图片中出现的内容,比如画面模糊,多手多脚等问题。
例子中的反向提示词是:
mutated hands and fingers,deformed,bad
anatomy,disfigured,poorly drawn face,mutated,extra limb,ugly,poorly drawn
hands,missing limb, extra limbs,floating limbs,disconnected limbs,malformed
hands,out of focus,long neck,long body,out of frame,bad hands,unclear
eyes,cloned face,bad face,extra legs, extra arms, disfigured, deformed,
cross-eye
5、Generation:Stable Diffusiion 文生图生成页签。
6、采样器:用来一步步生成图片的算法,默认的 Euler a 可以适用于绝大多数的场景,一般先用它就行了;其它SDE的采样器也不错,可以多试试
。后边会有专门的文章来介绍采样器。
7、采样步数:采样器使用多少步来生成图片,不同的采样器表现各异,一般使用 20-50 步,步数越多越慢,Euler a 使用20步基本就够了。
8、图片尺寸:对于SD 1.5的模型默认是 512*512,对于SD XL的模型默认是 1024*1024。如果想生成其它比例的图片,比如3:4、16:9,需要注意不要把尺寸调得太大,生成的图片中可能出现多个主体或者多余的肢体。如果想要大尺寸的图片,可以到“额外功能/Extras”中放大,后续文章会有介绍。
9、生成次数:设置连续生成几次,默认为1,次数越多需要的时间越长。
10、每次数量:每次生成同时出图的数量,数量越大,占用的显存越大。
11、提示词引导系数:提示词对生成图片的重要程度,值越大,图片中的内容越贴近提示词的描述,反之则Stable Diffusion 自由发挥的多。
12、图像生成种子:参与图片初始化的一个参数。默认为-1,则每次自动生成一个随机数,在其它参数都不改变的情况下,它会给图片带来一些随机性,这也是AI绘画的魅力所在,总会有一些新的变化。在其它参数和种子都不变的情况下,Stable
Diffusion 可以生成完全一致的图片,这就是稳定扩散的意思。
13、点击“生成”,会有进度条出现,坐等图片生成就可以了。
14、生成好的图片会出现在这里。
出自:https://mp.weixin.qq.com/s/z6HrxC02da5vcY5ZNwC0Vg
Daft Art 是一个可帮助您借助人工智能创建精美而独特的专辑封面的网站