推荐智能体:利用大模型进行交互式推荐
发布时间:2024年06月06日
推荐模型通过利用广泛的用户行为数据,擅长为特定领域提供个性化的商品推荐。尽管它们能够作为轻量级的领域专家,但在提供解释和参与对话方面则力不从心。另一方面,大型语言模型(LLM)代表了人工通用智能的重大进步,展示了在指令理解、常识推理和人机交互方面的卓越能力。但是,LLM缺乏对特定领域的海量训练数据形成的商品目录知识和行为模式知识,特别是在那些偏离一般世界知识的领域,如在线电子商务。针对每个领域微调LLM既不经济也不高效。在本文中,我们架起了推荐模型和LLM之间的鸿沟,将各自的优势融合以创建一个多功能和交互式的推荐系统。我们提出了一个高效的框架InteRecAgent,其将LLM用作大脑,将推荐模型用作工具。我们首先概述了将LLM转换为InteRecAgent所需的一组最基本的工具。然后,我们提出了InteRecAgent内高效的任务执行工作流程,包括记忆总线、动态示范增强的任务规划和反思等关键组件。InteRecAgent使得传统的基于ID的矩阵分解等推荐系统能够通过集成LLM而具有自然语言交互界面。实验结果表明,在多个公开数据集上,InteRecAgent在会话式推荐任务中取得满意的性能,明显优于通用LLM。
论文原文地址:2308.16505.pdf
(arxiv.org)

一、介绍
推荐系统在各种领域中发挥着重要作用,例如电子商务和娱乐,通过分析用户偏好、历史数据和上下文信息,为用户提供个性化的推荐。多年来,推荐系统从简单的协同过滤算法发展到更先进的混合方法,整合了深度学习技术。然而,随着用户越来越依赖会话界面来发现和探索产品,开发更复杂和交互式的推荐系统以有效地理解和响应各种用户查询和意图的需求日益增长。
大语言模型(LLM)代表了自然语言处理领域的重大飞跃,展示了在人工智能方面的卓越能力,包括在语境学习、指令遵循和推理计划方面。通过与AI助手ChatGPT等的对话,可以完成各种实际任务。凭借理解上下文、生成人类文本以及执行复杂推理任务的能力,LLM可以使用户与推荐系统之间的交互更具吸引力和直观,从而为推荐系统的新一代带来前景。通过将LLM集成到推荐系统中,用户体验可以更自然、更流畅,这超越了传统的推荐技术,增强了推荐系统的整体效果。
尽管LLM具有潜力,但是将其应用于推荐系统也存在挑战和局限。首先,尽管LLM在Internet上的大量文本数据上进行了预训练,涵盖了各种领域,展示了强大的一般世界知识,但它们可能无法捕捉特定领域的细粒度、域特定的行为模式,特别是在那些拥有海量训练数据的领域。其次,如果领域数据是私有的、不太公开可访问的,LLM可能难以很好地理解该领域。第三,LLM缺少预训练数据收集后发布的新商品的知识,针对最新数据的微调成本可能过高。相比之下,特定领域的模型天然可以解决这些挑战。克服这些局限性的一种常见范式是将LLM与特定领域的模型相结合,以填补差距并产生更强大的智能。
在本文中,我们采用类似的方法,旨在利用推荐模型和LLM的优势来构建会话式推荐系统。我们提出了InteRecAgent,一个明确设计用于适应推荐系统的特定要求和细微差别的系统,从而在语言模型的一般能力和推荐领域的专业需求之间建立更有效的连接。为实现这一目标,我们开发了一个紧凑的框架,其中包含三个不同的工具集,旨在将用户的查询转换为框架内的一系列工具执行。通过有效地整合推荐模型和LLM的优势,InteRecAgent为会话式推荐系统的发展铺平了道路,能够在各种领域提供个性化和交互式的推荐建议。
二、相关工作
2.1 会话式推荐系统
现有的会话式推荐系统研究可以主要分为两个主要领域(Gao et al. 2021):基于属性的问答(Zou and Kanoulas
2019; Zou, Chen, and Kanoulas 2020; Xu et al. 2021)和开放式对话(Li et al. 2018; Wang et al. 2022b, 2021)。在基于属性的问答CRS中,系统的目标是在尽可能少的轮次内为用户推荐合适的商品。系统和用户之间的交互主要围绕所需商品属性的问答,逐步细化用户兴趣。这一领域的关键研究挑战包括开发用于选择查询属性的策略(Mirzadeh,
Ricci, and Bansal 2005; Zhang et al. 2018)以及解决探索与利用之间的权衡(Christakopoulou, Radlinski, and Hofmann 2016; Xie et al. 2021)。在开放式对话CRS中,系统处理自由格式的对话数据。这一领域的初期研究工作侧重于利用预训练语言模型进行对话理解和响应生成(Li et al. 2018; Penha and Hauff 2020)。后续研究则将外部知识引入开放式CRS中以提高性能(Chen et al. 2019; Wang, Su, and
Chen 2022; Wang et al. 2022b)。然而,这些方法在处理复杂的用户查询和与用户保持流畅交流方面仍存在困难。大语言模型的出现为会话式推荐系统的构建带来了革命性的机遇,可能解决现有方法的局限性,增强整体用户体验。
2.2 加强LLM
参数和数据量级的提升导致了LLM能力的重大进步,包括语境学习(Brown et al. 2020; Liu et al. 2021;
Rubin, Herzig, and Berant 2021)、指令遵循(Ouyang et al.
2022; Touvron et al. 2023a; OpenAI 2023)和计划与推理(Wei et
al. 2022; Wang et al. 2022a; Yao et al. 2022; Yang et al. 2023; Wang et al.
2023)。在推荐系统领域,应用LLM也正在成为一个快速增长的趋势(Liu et al. 2023; Dai et al. 2023; Kang et al. 2023; Wang and Lim
2023)。
作为具有一般智能和自然语言处理能力的模型,LLM不可避免地缺乏特定领域的技能,如编辑图像或回答专业领域的问题。为弥补这些弱点,研究人员已经开始探索使用外部工具来增强LLM的能力(Qin et al. 2023)。例如,(Nakano et al. 2021; Shuster et al. 2022)为LLM配备了网页搜索引擎,使最初离线的LLM能够访问在线资源。其他人采用数学计算工具来增强LLM的数学能力(Schick et al. 2023; Thoppilan et
al. 2022),并通过Python解释器提高编码能力(Gao
et al. 2023; Chen et al. 2022)。为了集成视觉功能,Visual ChatGPT
(Wu et al. 2023)和HuggingGPT (Shen et al. 2023)结合了视觉模型作为工具,使LLM能够生成和处理图像。据我们所知,这篇论文是第一个探索LLM + 工具范式在推荐系统领域的应用。
三、方案
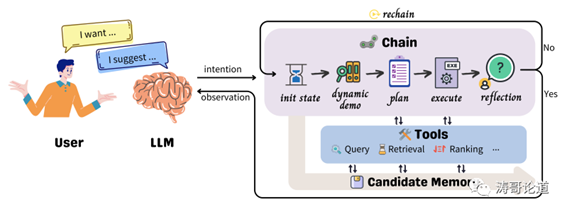
InteRecAgent框架的整体结构:
1. 语言模型作为“大脑”,负责解析用户意图和生成响应。
2. 提供三类工具:信息查询工具、物品检索工具和物品排序工具。这些工具分别负责信息查询、根据硬条件和软条件检索候选项,以及根据用户偏好排序候选项。
3. 用户与语言模型进行对话交流。如果需要使用工具,语言模型会生成工具使用计划,并提供每个工具的输入。
4. 共享内存总线负责存储当前候选项,被各工具共享调用。检索工具从中获取输入,更新输出,排序工具排序其中候选项。
5. 语言模型观察工具执行结果,生成响应给用户。如果通过反馈策略判断有误,语言模型会重复第一步骤。
6. 语言模型计划调用顺序和提供输入,工具执行体按顺序执行返回观察结果。执行过程与共享内存总线进行交互。
7. 用户与语言模型的对话可以进行多轮交流,以深入挖掘用户需求并提供个性化推荐。
所以该框架将语言模型、推荐工具及其相互交互规则联系起来,实现更智能化的对话式推荐系统。
3.1 总体框架
InteRecAgent框架的全貌如图1所示。从根本上讲,LLM起大脑的作用,而推荐模型充当提供域特定知识的工具。用户通过自然语言与LLM进行交互。LLM解释用户的意图,判断当前对话是否需要工具的帮助。例如,在闲聊中,LLM将根据自身知识做出回应;而对于领域内的推荐,LLM启动一系列工具API调用,随后通过观察工具执行结果生成回应。因此,推荐质量高度依赖于工具,使工具的组成成为整体性能的关键因素。为确保InteRecAgent在闲聊和商品推荐之间保持无缝沟通,我们建议最小化工具集应包含以下方面:
- 信息查询。在会话交互中,InteRecAgent不仅处理商品推荐任务,还经常处理用户的查询。例如,在游戏平台内,用户可以询问类似“这个游戏的发布日期是什么,需要多少钱?”等问题。为适应这种查询,我们为LLM配备了商品信息查询模块。该模块可以使用SQL表达式高效地从后端商品信息数据库中检索详细的商品信息。
- 商品检索。检索工具旨在根据当前对话提出满足用户意图的商品候选列表。这些工具可比作实际推荐系统的检索阶段,其作用是将相关候选项缩小到较小的列表以实现大规模服务。在InteRecAgent中,我们考虑用户意图可能表达的两类需求:硬条件和软条件。硬条件是指用户对商品的明确要求,如“我想要一些流行的运动游戏”或“给我推荐一些低于100美元的RPG游戏”。软条件是指无法明确表达的需求,需要使用语义匹配模型,如“我想玩一些类似使命召唤和要塞英雄的游戏”。为处理这两种条件,集成多种工具至关重要。因此,我们使用SQL工具处理硬条件,从商品数据库中查找候选项。对于软条件,我们采用项目间工具,基于潜在嵌入匹配相似项目。
- 商品排名。排名工具在会话中发挥着重要作用,通过考虑用户的历史数据和偏好来定制个性化内容。排名模块旨在分析用户的历史记录和对话中提到的具体兴趣,并将这些信息作为输入来优先考虑候选集中的项目。此过程确保提供的推荐与用户当前的意图相关,并符合其整体偏好和品味。
通过这些不同的工具的支持,如果给予适当的提示,LLM有可能处理各种用户查询。例如,一个用户可能问,“我以前玩过使命召唤和要塞英雄。现在我想玩一些要塞英雄发布之后发行的益智游戏,你有什么推荐吗?”在这种情况下,工具执行顺序将是“SQL查询工具→ SQL检索工具→ 排序工具”。首先查询要塞英雄的发布日期,然后将发布日期和益智题材作为SQL检索的硬条件。最后,将使命召唤和要塞英雄视为排序模型的用户配置文件。
通常,工具增强是通过ReAct实现的,其中LLM以交织的方式生成推理痕迹、操作和观察结果。我们称此执行方式为逐步方式。我们的初步实现也采用了逐步方法。但是,我们很快观察到了一些局限性,这是由于各种挑战。首先,检索工具可能返回大量商品,导致LLM的观察提示过长。此外,在提示中包含许多实体名称会降低LLM的性能。其次,尽管LLM具有强大的智能,但在完成任务时可能会错误使用工具,如选择不存在的工具调用或省略关键执行步骤。为解决这些挑战,我们提出以下机制:
- 候选记忆总线。我们为当前的候选商品分配一个单独的内存来存储,无需将它们追加到提示输入中。所有工具都可以访问和修改候选记忆。
- 带动态示范的先策划后执行。我们采用两阶段方法,而不是逐步方法。在第一阶段,我们强制LLM根据对话中派生的用户意图,一次性制定完整的工具执行计划。在第二阶段,LLM严格遵循该计划,顺序调用工具,同时允许它们通过候选记忆总线进行通信。为帮助LLM制定更合理的计划,我们采用动态示范策略进行语境学习。具体来说,我们首先生成各种可能的用户意图形式及相应的执行计划。在处理用户意图时,我们从这些样本中检索与当前用户意图最相似的示例,并将其合并为提示中的示范。
- 反思。计划执行完成后,我们允许LLM反思观察结果,以识别任何异常(例如由于数据格式失败导致的结果质量差或错误)。如果必要,InteRecAgent将启动另一个⟨计划,执行⟩过程链,为LLM提供生成高质量答案的额外机会,这称为rechain。
在后续章节中,我们将详细介绍这三个机制。
3.2 候选记忆总线的翻译如下:
大量商品带来的挑战是当试图将工具生成的项目作为观察提示的一部分包含在LLM的提示中时,由于输入上下文长度限制,可能会导致过长的提示。同时,后续工具的输入通常依赖于先前工具的输出,这需要工具之间进行有效的通信。因此,我们设计了一个候选记忆总线,以促进候选商品在工具之间的流通。记忆总线可被所有工具访问,包含两部分:一个数据总线用于存储候选商品,以及一个追踪器用于记录每个工具的输出。
默认情况下,数据总线中的候选商品在每轮对话开始时被初始化为包含所有商品。在每个工具执行开始时,从数据总线中读取候选商品,并在每个工具执行结束时使用过滤的商品刷新数据总线。这种机制允许候选商品以流式方式依序通过各种工具。值得注意的是,用户可以在对话中明确指定一组候选商品,如“你认为这些电影中哪部最适合我:[电影列表]?”。在这种情况下,LLM将调用一个特殊的工具 - 内存初始化工具 - 来将用户指定的商品设置为初始候选商品。
记忆中的追踪器用于记录工具执行。每个工具调用记录表示为三元组(f_k,o_k),其中f_k表示第k个工具的名称,o_k是工具执行的输出,如剩余候选项的数量、运行时错误。追踪器的主要功能是帮助评论员在反思机制中进行判断,充当反思(·)中的o_t,如第3.4节所述。
借助候选记忆总线组件,商品可以以流式方式在各种工具之间传输和持续过滤,呈现漏斗式推荐流程结构。追踪器的记录可以视为进一步反思的短期记忆。
3.3 动态示范增强的先策划后执行
在会话场景中,一个关键挑战是如何使LLM指定正确的工具执行路径来处理各种用户意图。与ReAct中采用的逐步策略不同,我们引入了一个两阶段方法,该方法使LLM一次性制定工具使用计划,然后严格执行该计划以完成任务,称为先策划后执行。我们在附录中概括了我们的先策划后执行策略与ReAct的区别,并通过实验证明了我们策略的优越性。具体来说,先策划后执行由以下两个阶段组成。
- 策划:LLM接受当前输入x_t,对话上下文C_(t-1),各种工具的描述F以及用于语境学习的示范D_x_t。LLM根据用户意图和偏好制定工具使用计划,为每个工具提供输入,即p_t =
{p_t1,...,p_tn} = plan(x_t, C_(t-1), F, D_x_t),其中p_tk =
(f_k,i_k)由工具f_k和其输入i_k组成。
- 执行:工具执行器根据计划p_t顺序调用工具,并从每个工具获取输出,即o_t = {o_t1,...,o_tn} = exec(p_t, F)。每个工具f_k的输出反馈定义为o_tk,其中只有来自最后一个工具输出的商品信息o_tn用作LLM生成响应y_t的观察结果。其余信息由候选记忆总线跟踪以供进一步反思(见第3.4节)。
为提高LLM的计划能力,将动态检索的示范D_x_t注入提示以进行语境学习。每个示范由用户意图x和工具执行路径p组成。但是,由于LLM可以处理的上下文长度严格有限,示范的数量也受到严格限制,这使得示范的质量至关重要。为解决这一挑战,我们引入了动态示范策略,其中只选取与当前用户意图最相关的几个示例并将其纳入提示中。例如,如果当前用户输入是“我以前玩过使命召唤和要塞英雄,现在请给我一些建议”,则可能检索到具有“我以前喜欢ITEM1、ITEM2,给我一些建议”用户意图的示范作为高质量示范。我们受Self-Instruct(Madaan et al. 2023)的启发,使用LLM生成数百个示范以获得更多用户意图和执行路径。我们使用Self-Instruct中提出的输入优先和输出优先策略来生成示范,详见附录。由于执行路径仅与用户意图格式相关,而与特定项目或属性无关,我们通过使用占位符ITEM和TYPE等来代替特定项目和属性来限制生成,这确保检索侧重于用户意图的结构,而不会受到具体细节的影响。
3.4 反思机制
尽管LLM具有强大的智能,但它在推理和工具利用方面仍然偶尔出现错误(Madaan et al. 2023;
Shinn et al. 2023)。例如,它可能违反提示中的指令,选择不存在的工具,省略或过多使用一些工具,或未能以适当的格式准备工具输入,从而导致工具执行错误。
为减少这种错误的发生,一些研究采用了自我反思(Shinn et al. 2023)机制,使LLM在决策过程中具有一定的错误修正能力。在InteRecAgent中,我们利用演员-评论家反思机制来增强代理的鲁棒性和错误修正能力。在下面部分,我们将形式化这个自我反思机制。
假设在第t轮,对话背景是C_(t-1),当前用户输入是x_t。演员是一个配备工具的LLM,受先策划后执行机制的启发。对于用户输入,演员将制定计划p_t,获得工具输出o_t并生成响应y_t。评论家评估演员的行为决策。反思执行步骤如下:
- 步骤1:评论家在当前对话背景下评估演员的输出p_t、o_t和y_t,并获得判断γ =
reflect(x_t, C_(t-1), p_t, o_t, y_t)。
- 步骤2:当判断γ为正时,表示演员的执行和响应是合理的,y_t直接提供给用户,结束反思阶段。当判断γ为负时,表示演员的执行或响应不合理。反馈γ用作信号指示演员进行rechain,作为plan(·)的输入。
在演员-评论家反思机制中,演员负责具有挑战性的计划制定任务,而评论家负责相对简单的评估任务。两者在不同类型的任务上进行合作,通过语境交互实现互相强化。这为InteRecAgent带来了增强的鲁棒性和改进的错误修正能力,最终带来更精确的工具利用和推荐。
3.5 对话压缩
将LLM用作对话模块面临另一个相当大的挑战:对话长度的增加与LLM输入上下文固定长度限制之间的不协调。这个问题在工具学习中尤为突出,其中任务和工具描述需要特定数量的标记。在InteRecAgent中,我们利用另一个LLM在对话长度达到限制时压缩对话。
四、实验
4.1 实验设置
评估策略。评估会话式推荐系统具有挑战性,因为求助者通过自然的开放式对话传达其偏好,而InteRecAgent则通过自然的开放式对话为其提供相关建议。为了定量评估InteRecAgent,我们设计了两种评估策略:
用户模拟器。我们设计了一个角色扮演提示,以指导GPT-4模拟与会话式推荐系统交互的用户。用户的历史行为被整合到提示中作为其配置文件,其历史中的最后一个项目用作目标项目。以这种方式,GPT-4从用户的角度出发行事,并及时响应推荐结果,创造更真实的对话场景。这一策略用于在多轮对话设置中评估InteRecAgent的性能。
单轮推荐。遵循ReDial(Li et al.
2018)上的传统会话式推荐系统的设置,我们整合了单轮推荐策略:给定用户的历史记录,我们设计一个提示,使GPT-4可以生成对话,模拟用户和推荐系统之间的交流。目标是测试推荐系统是否可以在下一轮中准确推荐真实项目。我们评估了整个空间检索任务和候选项提供的排名任务。具体来说,对话上下文供给推荐系统,以及请根据聊天历史记录给我k条推荐的指令用于检索任务,以及请根据聊天历史记录对这些候选项目进行排名的指令用于排名任务。
所使用的提示可在附录中找到。
数据集。为了评估我们的方法在不同领域的有效性,我们在三个数据集上进行实验:Steam,MovieLens和Amazon Beauty。每个数据集都包含用户-商品交互历史数据和商品元数据。我们采用留一法将交互数据分割为训练集、验证集和测试集。所有使用的工具都是在训练集和验证集上训练的。由于预算限制,我们从测试集中随机抽样100个和500个实例用于用户模拟器和单轮基准测试。
基线。作为对话推荐系统,我们将我们的方法与几个通用LLM进行了比较,包括四个开源和两个闭源LLM。
- 随机:从商品集中均匀随机抽样k个商品。
- 流行度:根据商品流行度分布对k个商品进行采样。
-
Llama-2-7B-chat,Llama-2-13B-chat(Touvron et al. 2023b):来自Meta的Llama的第2个版本。
- Vicuna-v1.5-7B,Vicuna-v1.5-13B(Chiang
et al. 2023):基于Llama-2系列模型在ShareGPT用户共享数据上微调的开源模型。
- ChatGPT(gpt-3.5-turbo),GPT-4(OpenAI
2023):来自OpenAI的SOTA LLM。
对于Llama和Vicuna模型,我们使用FastChat(Zheng
et al. 2023)软件包建立本地API,以确保它们的使用方式与ChatGPT和GPT-4一致。
指标。由于我们的方法和基线都利用LLM生成响应,这展示了状态最先进的文本生成能力,我们的实验主要比较不同方法的推荐性能。对于用户模拟器策略,我们采用两个指标:Hit@k和AT@k,分别表示在k轮内成功推荐目标项目的次数和平均轮数(AT)所需的成功推荐次数。在计算AT@k时,k轮内不成功的推荐被记录为k+1。在单轮策略中,我们关注检索任务的Recall@k和排名任务的NDCG@k指标。在Recall@k中,k表示检索k个项目,而在NDCG@k中,k表示要对候选项目进行排名的数量。
实现详情。我们采用GPT-4作为InteRecAgent的大脑,用于解析用户意图和工具规划。关于工具,我们使用SQL作为信息查询工具,使用SQL和ItemCF(Linden, Smith, and York 2003)作为硬条件和软条件项目检索工具,使用不带位置嵌入的SASRec(Kang and McAuley 2018)作为排序工具。 SQL使用pandasql中的集成SQLite实现,检索和排名模型使用PyTorch实现。 InteRecAgent的框架使用Python和LangChain实现。对于动态示范选择,我们使用sentence-transformers对示范进行编码为向量,并使用ChromaDB存储,这有助于运行时的近似最近邻搜索。关于超参数设置,我们将动态示范的数量设置为3,硬条件检索的最大候选数设置为1000,软条件检索的截止阈值设置为前5%。 InteRecAgent的源代码发布在https://aka.ms/recagent。
4.2 使用用户模拟器进行评估
表1展示了使用用户模拟器策略进行的评估结果。我们的方法在三个数据集的命中率和平均轮数方面都优于其他LLM。这些结果表明,与通用LLM相比,我们的InteRecAgent能够在对话中提供更准确、更高效的推荐。
总体而言,参数量越大的LLM表现越好。ChatGPT和GPT4的参数量超过100B,其性能明显优于Llama2和Vicuna-v1.5。来自同一系列的13B模型几乎总是优于7B模型,除了Llama2-7B和Llama2-13B在Beauty数据集上的表现非常糟糕。
另一个有趣的观察结果是,在相对私密的领域改进更加明显,如亚马逊美妆。与游戏和电影领域相比,美妆产品领域更加私密,具有大量未被世界知识很好覆盖或是新的项目。表1显示,ChatGPT和GPT-4在游戏和电影领域展示了具竞争力的表现。然而,在亚马逊美妆领域,由于商品名称极长且复杂,大多数LLM遭受严重的幻想问题,导致性能明显下降。这一现象凸显了我们的InteRecAgent在私有领域的重要性。
4.3 使用单轮推荐进行评估
在这部分,我们评估检索和排名推荐任务。对于检索任务,我们为所有方法将推荐预算k设置为5,使用Recall@5作为评估指标。对于排名任务,我们随机采样19个负样本,加上1个正样本,它们一起形成用户主动提供的候选列表。此任务的评估指标为NDCG@20。
结果如表2所示。根据结果,我们可以得出与第4.2节相似的结论。首先,我们的方法优于所有基线,这表明我们的工具增强框架的有效性。其次,几乎所有LLM在亚马逊美妆数据集上遭遇严重挫败,但我们的方法在私有领域仍然取得了高精度,进一步证明了我们方法的优越性。值得注意的是,与随机和热门方法相比,一些LLM在排名任务中的表现较差,特别是在亚马逊数据集上。这主要是由于LLM没有遵循排名指令,这源于LLM的不确定性,并生成与范围无关的项目,尤其是对于较小的LLM。
4.4 消融实验
本文介绍了几个关键机制,以增强LLM更好地利用工具的能力。为了研究它们的重要性,我们进行了消融实验,结果如图2所示。我们分别考虑去除先策划机制(P)、动态示范机制(D)和反思机制(R)。实验是在用户模拟器评估设置下进行的,因为它提供了一个更全面的评估,包括准确性(命中率)和效率(平均轮次)指标。
结果表明,去除任何机制都会导致性能下降。在这些机制中,去除反思机制对性能影响最大,因为它可以纠正工具输入格式错误和工具误用。消除先策划机制和动态示范机制导致性能略有下降,但结果仍优于大多数基线。然而,去除先策划机制导致API调用次数大幅增加,例如在Steam数据集中平均每轮增加从2.78增加到4.51,导致大约10-20秒的延迟增加。
五、结论
在本文中,我们介绍了InteRecAgent,一个紧凑的框架,通过利用LLM的力量,将传统的推荐模型转换为智能交互系统。我们确定了三组基本工具,分别分类为信息查询工具、检索工具和排序工具,在任务执行框架内被动态互连以完成复杂的用户查询。为提高任务执行准确率,我们提出了三种新颖的模块:候选记忆总线、动态示范增强的先策划后执行和反思。实验结果表明,与现有通用目的语言模型相比,InteRecAgent在推荐相关任务中具有卓越的性能。通过整合推荐模型和LLM的优势,InteRecAgent为会话式推荐系统的发展铺平了道路,有能力在各个领域提供个性化和交互式的推荐服务。
六、主要创新点总结
1. 创新提出了一个将大语言模型与推荐模型相结合的框架,实现对话推荐系统。将语言模型作为“大脑”,推荐模型作为“工具”有效地结合了两者各自的优势。
2. 创新提出了三类基本工具集,包括信息查询工具、项目检索工具和项目排序工具。这套工具集覆盖了处理用户请求的主要功能。
3. 创新设计了共享内存总线机制。它有效管理候选项目,优化了框架执行效率,消除了文件读写瓶颈。
4. 创新提出了“规划优先执行”策略。它让语言模型一次性生成完整的执行计划,并严格按计划执行,较step by
step更高效。
5. 创新采用动态展示增强理念。通过联想历史样本,它能指导语言模型学习如何根据不同用户意图制定执行计划。
6. 创新设计了反馈机制。它让语言模型在执行后反思,发现并纠正可能出现的错误,从而提高系统质量。
7. 在游戏、电影和电商3个领域进行实验验证。结果表明该框架在对话推荐任务上整体优于通用语言模型。
以上主要创新点从理论模型、关键机制到实践验证,全面提升了对话推荐系统水平。这一研究成果对推动此领域的发展具有重要意义。
七、论文不足之处
1. 论文仅验证了框架在三个数据集上的表现,领域和规模均 relatively 少,扩大数据集和不同类型数据集的实验需要进一步加强。
2. 论文使用的工具集取自具体实验,一个更通用的工具集定义需要进一步总结与优化。
3. 语言模型采取的是GPT-4, representation power 和计算能力有限,采用更大模型训练需进一步研究。
4. 动态展示策略依赖大量人工样本,自动样本生成方法的研究空间还很大。
5. 反馈机制使用独立模型,整合到主体框架中的研究还未展开。
6. 论文仅考察单轮对话情景,多轮对话情景下系统表现及用户体验如何需要进一步论证。
7. 安全性问题如用户隐私泄露风险等在系统设计中需要关注。
8. 不同类型用户需求如个人化程度等方面的研究不足。
以上不足给框架应用带来一定障碍,同时也为未来工作提供了可持续发展的机会,例如优化各模块、扩大验证与证明等。但总体来说,该工作提出了一个重要的方向。
八、实际场景落地
1. 模型训练数据获取。需要获取可观的对话日志、用户行为数据进行预训练和微调,这对实际业务系统有一定难度。
2. 工具开发。需要根据业务场景定制合适的工具集,如信息查询、内容检索等,这需要业务人员和技术人员深入共建。
3. 模型部署。如采用微服务方式部署各模块,不同模块间如何高效交互是重要问题。
4. 系统集成。需要将框架整合到网站APP客户端等业务系统中,提供透明的用户交互体验。
5. 动态采样。如何在实时对话过程中快速高效采样历史对话来指导规划,这个环节的优化需要研发支持。
6. 多轮交互。如何根据长期积累的对话历史提供个性化服务需要模型不断学习优化。
7. 安全保障。如何保障用户隐私和数据安全需要从技术和管理两个层面解决。
8. 查准率评估。如何在现实应用中定量或定性评估模型效果是关键。
9. 模型迭代。需要持续收集用户反馈迭代改进各模块以满足不断变化的业务需求。
综上,实际应用需要从机器学习、架构设计、产品应用三个层面进行系统定制和持续完善。
出自:https://mp.weixin.qq.com/s/xldRPTD1vepgrav2Z680aw
Pixelicious 是一个可让您将图像转换为像素图像的网站。