一文探秘LLM应用开发-Prompt(相关概念)
发布时间:2024年06月06日
本文旨在让无大模型开发背景的工程师或者技术爱好者无痛理解大语言模型应用开发的理论和主流工具,因此会先从与LLM应用开发相关的基础概念谈起,并不刻意追求极致的严谨和完备,而是从直觉和本质入手,结合笔者调研整理及消化理解,帮助大家能够更容易的理解LLM技术全貌,大家可以基于本文衍生展开,结合自己感兴趣的领域深入研究。若有不准确或者错误的地方也希望大家能够留言指正。
本文体系完整,内容丰富,由于内容比较多,分多次连载。
第一部分 基础概念1.机器学习场景类别2.机器学习类型(LLM相关)3.深度学习的兴起4.基础模型
第二部分 应用挑战1.问题定义与基本思路2.基本流程与相关技术1)Tokenization与Embbeding2)向量数据库3)finetune(微调)4)模型部署与推理
5)prompt6)编排与集成7)预训练第三部分 场景案例常用参考
第二部分 应用挑战
2.基本流程与相关技术4)Prompt在前面的内容里,我们提到过要使用模型完成下游任务,有两种方式,一种是通过收集标记样本针对不同的任务进行指令微调,另一种方式便是大模型特有的,可以通过将指令以对话的方式提供给模型,期待模型能够给我们返回预期的结果。相较于前者,后者具有更高的灵活性,使用成本也更低,因此,这一方式成了如今大语言模型区别于传统NLP模型的重要标志。在本章你将学习到:1)Prompt,In-Context-Learning等相关概念2)Prompt engineering(如何写好一个Prompt及相关Prompt调试工具)3)基于Prompt催生的一些新的编程范式
认识Prompt
Prompt,中文翻译为提示(词),在维基百科中,它的定义是这样的:
A prompt is natural language text describing the task that an AI should perform.
提示是描述人工智能应该执行的任务的自然语言文本。实际上,也很好理解,在原有通过指令微调的方式训练的模型,它要完成什么任务,前期已经通过微调内化到模型里,一个模型干一件事情,因此,在使用时直接使用即可,比如情感分析模型,输入“今天天气很不错”,模型自然就会按照约定回答“正向”。而利用提示的方法,模型本身是通用的,可以做很多任务,这时候,我们就需要告诉它,需要让它做什么,比如:“下面我将给你一个句子,请帮我判断它的情感是正向还是负向,仅回答,无须解释”。

实际上,prompt这个思路并不是近来有之,早在2015年就有人提出这一概念《Ask Me Anything:
Dynamic Memory Networks for Natural Language Processing》,因为所有的nlp任务都可以归纳为“问答”这样一种统一模式,那时候prompt还叫做“question”,这种做法叫做Prompt learning。

https://arxiv.org/pdf/1506.07285.pdf
但是,虽然想法很好,实现上却很困难,当下用历史后视镜来看,想要实现统一,一是要选对模型结构(GPT),二是要有足够的参数规模,学到足够多的世界知识,进行有效的指令微调对齐。当时,大部分企业和研究者选择了基于bert来解决nlp任务,相关bert的研究也是非常的多,网络上关于PLM(预训练大模型)的内容,百分之八十都是与此相关的。而OpenAI选择了一个当时看来很难但不一定正确的路线,2018年6月发布了GPT1,参数量1.17亿,模型大小5gb,而bert仅几百M,效果在具体任务上却比GPT好,但他们并没有放弃,也正是如此,在2023年,ChatGPT一炮而红,带领人类进入AI 2.0时代,众多NLP原本热门的子方向变得前景暗淡。
In-Context Learning
了解了prompt的由来和历史,我们接下来自然要问的问题是,如何让模型更有效的理解指令,并能够高质量的执行。
这一问题如果改为“如何在github上有效提交一个issue?”,可能比较容易理解,那么自然就是首先清晰的描述自己的问题,进一步的提供自己的环境信息,以及你的输入,预期的输出等信息。而这些附加的信息我们叫做“context”,即上下文。对于模型来讲,我们仍然可以以这样人类熟悉的方式与模型进行交互,让它按照我们的预期工作,这就是上下文学习(In-Context-Learning),缩写为ICL。

生物学家、物理学家、生态学家和其他科学家使用「涌现」一词来描述当一大群事物作为一个整体时出现的自组织、集体行为。
比如无生命的原子组合产生活细胞; 水分子产生波浪; 椋鸟的低语以变化但可识别的模式在天空中飞翔; 细胞使肌肉运动和心脏跳动。
通过上面的描述可以知道,上下文学习是一种智能涌现(emergence),其发生的前提是它拥有了和人类似的思维模式。虽然当下还无法完全知道智能涌现的原因。但就目前研究表明,模型发生智能涌现可能的原因是当学习的资料及模型参数规模大到一定程度(10B以上),引发了质变,从而将模型中本来蕴含的知识和逻辑激发出来,表现出了智能。另一方面,近期的研究也表明涌现和训练资料的质量也有一定的关系,因此,高质量的数据是大模型智能程度的一个重要因素,其研究结果表明,综合语言能力的表现在很大程度上取决于训练前语料的来源而不仅仅是规模。就像人脑也是由一个个的神经元构成,当神经元多到一定程度,脑容量大到一定程度,人就出现了意识。
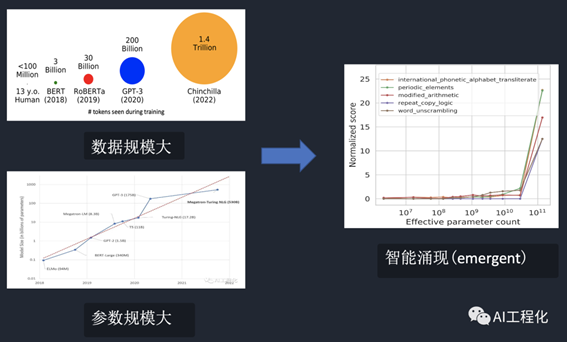
确切的讲,In-Context learning(ICL)是在大模型发生智能涌现的前提下的一种新的模型学习任务处理的范式,在GPT-3论文发布后,这一方法被广泛被接受。它允许语言模型通过以演示的形式组织若干个示例或者指令来学习任务。
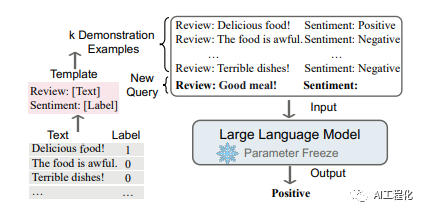
可以看出,In-context-learning作为Prompt Learning的一个部分,通过将上下文信息提供给大模型,能够大大的提升了操纵大模型的方式,从而更好的挖掘大模型的潜力。
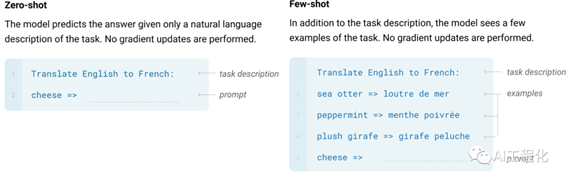
In-context Learning在基础形式及例子的数量上分有三类:zero-shot(零示例),one-shot(一个示例),fewshot(一些示例)。
·
zero-shot,实际上在本文最开始例子里就属于这种形式,我并没有提供大模型情感分析的例子的上下文,而是直接问问题。
·

在zero-shot中,没有提供例子,并不表示不能给它提供一些其他的信息,比如,我不希望它对它的回答进行解释,如前面例子,在提供prompt时,我增加了“仅回答,无须解释”这样的约束性质的要求,大模型能够很好的遵从。

但假如我们仍然觉得它的回答有点啰嗦,希望对回复格式有要求,就希望它回复“正向”或者“负向”,那又应该怎么做呢?这里就用到了“few-shot和one -shot”。
·
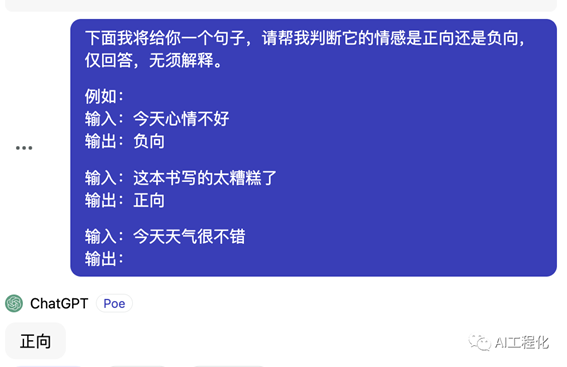
few-shot及one-shot,one-shot可以理解为few-shot的一个特例,它提供给大模型仅一个例子,而few-shot可以是多个。以刚才问题为例:我们提供这样的prompt:
·
 文心一言
文心一言
ChatGPT
可以看出,大模型一定程度遵从了指令,并且我在例子里并没有完全正确给出结果,如“这本书写的太糟糕了”,例子输出是“正向”,但大模型在实际任务输出过程中,仍然能够正确输出,这体现了大模型的性能具有较强的的鲁棒性和智能性。不过遗憾的是,文心一言未能完全按照例子输出,在后面增加了标点符号,而ChatGPT正确执行了指令。因此,指令遵从的程度也反映了大模型的智能程度。
看到这里,一定会有一个疑问:In-Context learning仅仅是提供给大模型一些上下文输入,并没有修改模型的权重,那么,为什么它会有效呢?
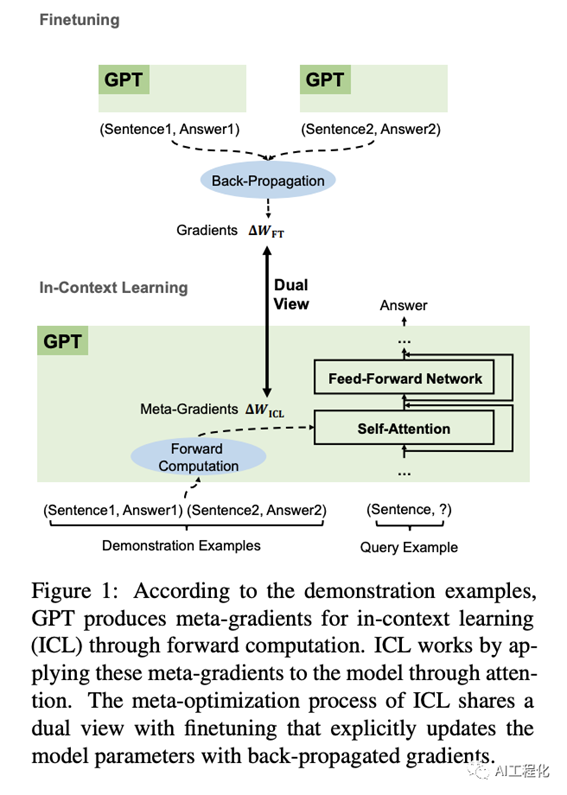
https://arxiv.org/pdf/2212.10559.pdf
Dai 等人的论文【Why Can GPT Learn In-Context? Language
Models Implicitly Perform Gradient Descent as Meta-Optimizers】探讨了这一问题的答案,他们在论文中探讨了在prompt中提供示例与使用相同示例进行微调之间的数学联系。作者证明,提示示例会产生元梯度(meta-gradients),这些元梯度会在推理时的前向传播过程中反映出来。而在微调时,示例实际上会产生真正的梯度,用于更新权重。因此,In-Context Learning能取得与微调类似的效果。
斯坦福大学的一篇文章【How does in-context learning work? A framework for understanding the
differences from traditional supervised learning】在论文《
An Explanation of In-context Learning as Implicit Bayesian Inference 》中的理论框架和《Rethinking the Role of Demonstrations: What Makes In-Context
Learning Work? 》中的实验的基础上,给出另一个角度的解释,把In-context
learning看作是一种隐式的贝叶斯推理。大模型在进行进行In-Context Learning时,可通过使用Prompt来 "定位
"它在预训练过程中学到的相关概念。从理论上讲,我们可以将其视为以Prompt为条件的潜在概念的贝叶斯推理,而这种能力来自于预训练数据的结构(长期一致性)。从这个角度讲,解释了角色扮演以及夸奖大模型的有效性,因为它影响到了条件概率分布。可参看文章:夸夸ChatGPT可提升回答质量,原来是有依据的,来看OpenAI创始成员Andrej的解释
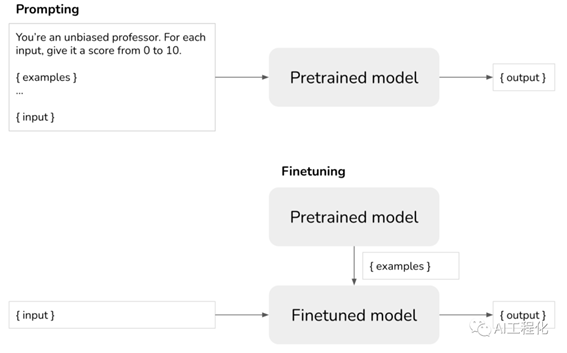
这时候,我们不难联想到另一个问题,就是怎么提升In-context learning的能力,这里就要提出Instruct
learning的概念。这里面有两个层面提升,一是尽可能提升模型的zero-shot的能力,这很显然,不用提供例子模型能够执行肯定比提供例子要更智能,另一方面,让模型能够识别更多的任务类型,以及回答方式。
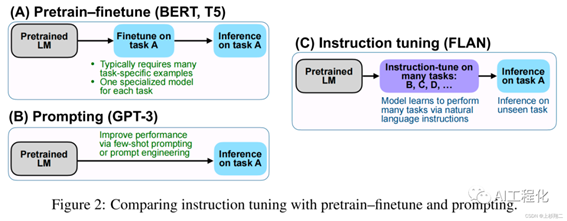
而这一切,就需要用到Instruct learning,所谓指令学习,它一般发生在微调阶段,所以通常也叫做指令微调(SFT),我们曾经在微调一章有介绍,区别于传统的模型微调,指令微调的核心不在于学习知识,而在于学习更多的任务类型及回答方式和风格,这里有个细节,如果留心的话,你会发现文心一言,chatgpt等大语言模型在回答不同类型问题时,它们的回答风格是不太一样的,比如让它写诗和写代码,甚至大模型之间在回答同类问题时表述风格也不相同,这本质上是因为指令微调的样本差异导致的。下面是两个指令学习数据样例。
1)llama Stanford Alpaca :
模版:
1 {
2
3 "description": "Template used by Alpaca-LoRA.",
4 "prompt_input": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n", 5 "prompt_no_input": "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:\n",
6 "response_split": "### Response:"
7 }
具体的数据:
1 [
2 {
3 "instruction": "Give three tips for staying healthy.",
4 "input": "",
5 "output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."
6 },
7 {
8 "instruction": "What are the three primary colors?",
9 "input": "",
10 "output": "The three primary colors are red, blue, and yellow."
11 },
12 ....
2)法律大模型LaWGPT中文微调数据:
模版:
1 {
2 "description": "Template used by Law Instruction Tuning",
3 "prompt_input": "你是中国顶尖智能法律顾问 LaWGPT,具备强大的中文法律基础语义理解能力,能够出色地理解和执行与法律问题和指令。你只能回答与中国法律领域相关的问题,其余领域的问题请礼貌地拒绝回答。接下来,请依据中国法律来回答下面这个问题。\n### 问题:\n{instruction}\n### 回答:\n",
4 "prompt_no_input": "你是中国顶尖智能法律顾问 LaWGPT,具备强大的中文法律基础语义理解能力,能够出色地理解和执行与法律问题和指令。你只能回答与中国法律领域相关的问题,其余领域的问题请礼貌地拒绝回答。接下来,请依据中国法律来回答下面这个问题。\n### 问题:\n{instruction}\n### 回答:\n",
5 "response_split": "### 回答:"
6 }
7
8
具体的数据:
1 [
2 {
3 "instruction": "酒驾撞人要判多久?",
4 "input": "",
5 "output": "《刑法》第一百三十三条规定:违反交通运输管理法规,因而发生重大事故,致人重伤、死广或者使公私财产遭受重大损失的,处三年以下有期徒刑或者拘役;交通运输肇事后逃逸,致人重伤的,处三年以上七年以下有期徒刑。交通肇事后逃逸致人死亡的,处七年以上有期徒刑。"
6 },
7 {
8 "instruction": "偷狗被派出所抓到,会怎么处理?",
9 "input": "",
10 "output": "取决于偷盗的狗的价值,可能按盗窃罪的罪名处理。如果价值达到犯罪标准,就构成盗窃罪,要承担刑事责任;如果不到犯罪标准,就是治安处罚、罚款或者拘留治安处罚这会涉嫌构成盗窃。如果不到一千元,则不会构成犯罪。如果超过一千元,则可能会是构成犯罪的。"
11 }
12 ...
通过例子也可以直观看到,通过指令微调和Prompt learning之间的协同关系,可以结合实际情况来灵活应用。
另外,需要注意的是context,并不局限于例子,还可以是一些其他的背景信息,比如一些提供给大模型参考的背景信息,也可以是一些状态信息,这里特别说明一下,常被提到的大模型记忆(Memory)的概念。大模型的记忆也是一种context,本质上就是将上下文会话信息作为context的一部分拼凑在Prompt中,然后大模型便能够知道前面的内容,进而变相有了记忆。下面是一个具体的例子:
1 The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
2
3 Current conversation:
4 Human: What's their issues?
5 AI: The customer is having trouble connecting to their Wi-Fi network. I'm helping them troubleshoot the issue and get them connected.
6 Human: Is it going well?
7 AI: Yes, it's going well so far. We've already identified the problem and are now working on a solution.
8 Human: What's the solution?
9 AI:
以上就是关于Prompt 和 In-Context Learning的一些常见概念,在后面将介绍In-context
learning的一些高阶方法挖掘大模型潜力,如COT,TOT等,另外也将介绍Prompt的一些局限性。
出自:https://mp.weixin.qq.com/s/dOWyO7eN3nowly5RZVsTxg
Podcast.ai是一个基于AI生成的在线播客,每周都会深入探讨一个新主题,为听众提供独特的见解。