PostgreSQL的三位一体——在大模型应用中结合关系型、向量和时间序列数据
发布时间:2024年06月06日
·我们为什么在AI应用中准备选择PostgreSQL
·基于PostgreSQL的Timescale
Vector的优势
·DiskANN算法介绍
·结合LlamaIndex使用Timescale
Vector的实例
尝试PostgreSQL的原因
最近两周我和小明在研究基于大模型的检索应用RAG,小明在实操层面有一些显著的突破,RAG性能应该已经超过了绝大部分目前开源市场上的同类产品,已经可以让我们有一些小小的满意了。但是优化创新的路依然可谓道阻且长,接下来我们准备在数据库上做一些新的尝试。
基于大模型的RAG应用,我们用到的数据库类型还是挺多的,主要有以下三种:
·向量(Vector)数据库:大模型和深度学习的都知道,这波AI浪潮中向量是基础,是对现实时间的语义级别的表示。区别于之前的关键词搜索的字面量搜索,向量搜索(相似度)可以认为是一种懂思想的搜索;
·关系型数据库(RDB):这是最传统和广泛的数据库,比如传统的PostgreSQL、MySQL、Oracle数据库等,即使在现在,关系型数据库依然是当今绝大多数应用系统运行的架构基础;
·时间序列数据库:时序数据库在元数据过滤中发挥了重大作用,它是一种记录事件和发生时间的数据库,对于时间序列的搜索速度非常快。在RAG应用中,如果行业知识文件被切分出几万个,那么使用时间过滤就会非常重要,比如我们只需要检索2023年3月份的合同文件,那么就可以用时序数据将目标chunk从几万个里面先挑出来,再进行向量计算。
目前我们用的数据看包括MySQL、elasticsearch和redis等,因为说整体的程序体量会变得非常大,结构松散,部署难度激增。而且对于后续的内部API管理也会感觉到非常杂乱。所以我们尝试使用PostgreSQL及其扩展,这样就可以在一个数据库上搞定了。
PostgreSQL介绍
对于熟悉PostgreSQL的朋友可以不用看这一节,前面的MySQL和PostgreSQL大战(口水战)我相信也会让很多人对PostgreSQL有一些关注。我不站任何一边,因为两个数据库在不同的应用中都在被使用。
PostgreSQL是世界上最受欢迎的数据库,它有一个很好的优点:它已经在生产中使用了30多年,强大而可靠,并且它有一个丰富的工具、驱动程序和连接器生态系统。之前除了关系型数据库,我们还用过PostGIS做地图导航应用,2018年转载过PostgreSQL的时序数据库Timescaledb的中文手册。面对AI,PostgreSQL其实已经有一个向量扩展——pgvector。虽然pgvector是一个很棒的扩展(它的所有功能都是作为Timescale vector的一部分提供的),但它只是为PostgreSQL上的AI应用程序开发人员提供生产级体验的一块拼图。在向企业技术人员调研中,发现pgvector需要增强的地方还有很多。
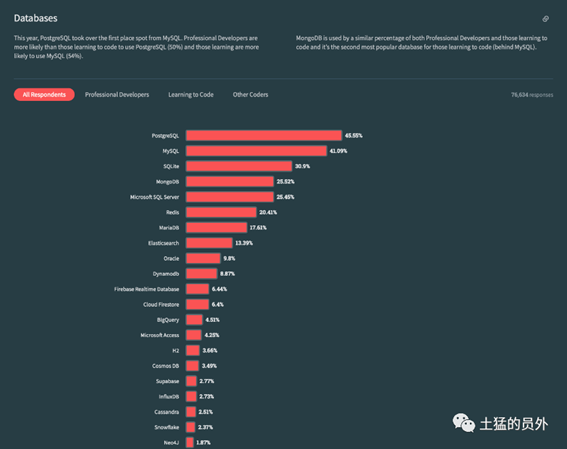
Postgresql的受欢迎程度
下面我们来看看PostgreSQL在向量领域的一些优劣势。
专用Vector数据库的问题
像Pinecone、Weaviate、Qdrant和Zilliz这样的向量数据库受益于人们对AI应用的兴趣激增,它们专门用于大规模存储和查询矢量数据,具有独特的功能,如近似最近邻(ANN)搜索和混合搜索的索引。但随着开发人员开始在他们的AI应用程序中使用它们,使用这些数据库构建的显著缺点变得清晰起来:
·操作复杂性:仅为向量数据持续维护单独的数据库增加了另一层操作开销,要求团队跨多个系统复制、同步和跟踪数据。更不用说备份、高可用性和监控了。
·学习曲线:工程团队浪费时间学习新的查询语言、系统内部、api和优化技术。
·可靠性:从头开始构建一个健壮的数据库是一个巨大的挑战,而且在生产环境中尤其注重健壮。大多数小众向量数据库都是未经证实的新兴技术,长期的稳定性和可靠性值得怀疑。
用我们采访的一位开发者的话来说:
“与几乎任何其他矢量存储相比,Postgres更适合生产,更可配置,并且在操作上更透明。”- LegalTech创业公司软件工程师
使用基于PostgreSQL的Timescale Vector的优势
借助PostgreSQL在关系型数据库方面的企业级应用优势,再加上Timescale Vector的向量特性,以及时间序列数据的结合,在AI应用中使用PostgreSQL是非常划算的,特别是在RAG等检索应用中。对于关系型数据库特性和时间序列数据特性我就不在这里介绍了,下面我们看看Timescale Vector的优势:
·对数百万个向量的更快的相似性搜索:由于引入了一种受DiskANN算法启发的新搜索索引,Timescale
Vector在99%的召回率下实现了比专用数据库快3倍的搜索速度,并且在100万个OpenAI Embeddings(1536维)数据集上比全部现有的PostgreSQL搜索索引高出39.39%到1590.33%。此外,与pgvector相比,启用产品量化可以节省10倍的索引空间。Timescale Vector还提供pgvector的Hierarchical Navigable Small
Worlds (HNSW,分层导航)和 Inverted File Flat(IVFFlat,倒置文件平面)索引算法。
·Timescale Vector优化了基于时间的向量搜索查询:利用Timescale的超级表的自动基于时间的分区和索引,有效地找到最近的Embeddings,通过时间范围或文档存在年份约束向量搜索,并轻松存储和检索大型语言模型(LLM)响应和聊天历史。基于时间的语义搜索还使您能够使用检索增强生成(Retrieval
Augmented Generation, RAG)和基于时间的上下文检索,从而为用户提供更有用的LLM响应。
·简化的AI基础设施堆栈:通过将向量Embeddings,关系型数据和时间序列数据组合在一个PostgreSQL数据库中,Timescale vector消除了大规模管理多个数据库系统所带来的操作复杂性。
·简化元数据处理和多属性过滤:开发人员可以利用所有PostgreSQL数据类型来存储和过滤元数据,并将向量搜索结果与关系数据连接起来,以获得更多上下文相关的响应。在未来的版本中,Timescale Vector将进一步优化丰富的多属性过滤,在过滤元数据时实现更快的相似性搜索。
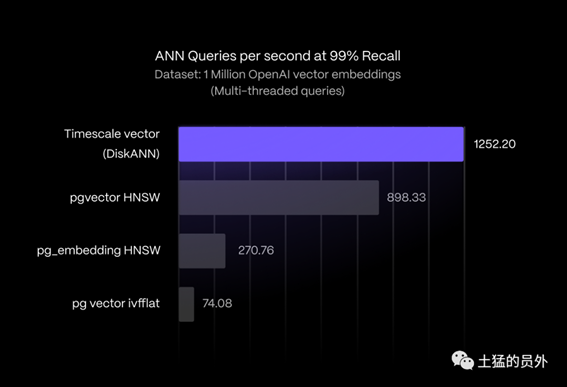
基于DiskANN的Timescale
Vector在性能上优势明显
在这些针对矢量工作负载的创新之上,Timescale vector提供了一个强大的、生产就绪的PostgreSQL云平台,具有灵活的定价、企业级安全性和免费的专家支持。
简单介绍一下DiskANN算法
上面提到了DiskANN算法,那我在文章中就必须简要补充一下。
当前最先进的近似最近邻搜索(ANNS)算法生成的索引,必须存储在主存储器中,以实现快速查全率搜索——这使得它们非常昂贵,并且限制了数据集的大小。
DiskANN基于图形的索引和搜索系统,它只需要64GB
RAM和廉价的固态硬盘(SSD),就可以在一个工作站上索引、存储和搜索十亿个点的数据库。与之前的认知相反,我们证明了DiskANN构建的基于SSD的索引可以满足大规模神经网络的所有三个要求:
·高召回率
·低查询延迟
·高密度(每个节点索引的点)。
在十亿个点SIFT1B大神经网络数据集上,DiskANN服务QPS>5000;在16核机器上,平均延迟为3ms, 95%+ 1-recall@1,其中最先进的十亿点ANNS算法具有类似的内存占用,如FAISS[18]和IVFOADC+G+P[8],稳定在50%左右1-recall@1。另外,在高召回率的情况下,与最先进的基于图的方法(如HNSW[21]和NSG[13])相比,DiskANN在每个节点上可以索引和服务5 - 10倍的点。最后,作为整个DiskANN系统的一部分,我们引入了Vamana,这是一个新的基于图的ANNS索引,它比现有的图索引更通用,甚至对于内存索引也是如此。
结合LlamaIndex使用Timescale Vector
以下结合LlamaIndex实操的内容摘自LlamaIndex创始人Jeff Liu的blog。

LlamaIndex:个人觉得比Langchain会更好用一些
在LlamaIndex中使用Timescale Vector的DiskANN、HNSW或IVFFLAT索引非常简单。
简单地创建一个Timescale Vector矢量存储,并添加数据节点,你想查询如下所示:
fromllama_index.vector_storesimportTimescaleVectorStore# Create a timescale vector store with specified params
ts_vector_store = TimescaleVectorStore.from_params(
service_url=TIMESCALE_SERVICE_URL,
table_name="your_table_name",
time_partition_interval= timedelta(days=7),
)
ts_vector_store.add(nodes)
然后运行:
# Create a timescale vector index (DiskANN)
ts_vector_store.create_index()
这将使用默认参数创建一个Timescale Vector索引。
我们应该指出,“索引”这个术语有点过多了。对于许多vectorstore,索引是存储数据的东西(在关系数据库中通常称为表),但在PostgreSQL世界中,索引是加速搜索的东西,我们在这里使用后一种含义。
我们还可以在create_index 命令中指定创建索引的确切参数,如下所示:
# create new timescale vector index (DiskANN) with specified parameters
ts_vector_store.create_index("tsv", max_alpha=1.0, num_neighbors=50)
这个Timescale
Vector的新DiskANN启发矢量搜索索引的优点包括:
·在PostgreSQL中以99%的准确率更快地进行向量搜索。
·优化运行在磁盘上,而不仅仅是在内存使用。
·量化优化兼容PostgreSQL,减少向量大小,从而缩小索引大小(在某些情况下10倍!),加快搜索。
·高效的混合搜索或过滤附加维度。
有关Timescale
Vector的新索引如何工作的更多信息,请参阅这篇博客文章。
Pgvector被打包为Timescale Vector的一部分,因此您也可以在LlamaIndex应用程序中访问Pgvector的HNSW和IVFFLAT索引算法。从LlamaIndex应用程序代码中方便地创建ANN搜索索引的能力使得创建不同的索引和比较它们的性能变得容易:
# Create an HNSW index# Note: You don't need to specify m and ef_construction parameters as we set smart defaults.
ts_vector_store.create_index("hnsw", m=16, ef_construction=64)# Create an IVFFLAT index# Note: You don't need to specify num_lists and num_records parameters as we set smart defaults.
ts_vector_store.create_index("ivfflat", num_lists=20, num_records=1000)
结合LlamaIndex添加高效的基于时间的搜索功能
Timescale
Vector优化了基于时间的向量搜索,利用Timescale的超级表的自动基于时间的分区和索引来有效地按时间和相似度搜索向量。
时间通常是矢量Embeddings的重要元数据组成部分。Embeddings的来源,如文档、图像和网页,通常都有一个与之相关的时间戳,例如,它们的创建日期、发布日期或最后更新日期等等。
我们可以利用向量Embeddings集合中的时间元数据,通过检索不仅在语义上相似而且与特定时间框架相关的向量来丰富搜索结果的质量和适用性。
以下是一些基于时间的矢量检索可以改进LlamaIndex应用程序的示例:
·查找最近的Embeddings:查找语义上与查询向量相似的最近的Embeddings。例如,查找与选举有关的最新新闻、文件或社交媒体帖子。
·时间范围内搜索:限制相似性搜索仅针对相关时间范围内的向量。例如,询问关于知识库的基于时间的问题(“在2023年1月到3月之间添加了哪些新功能?”)。
·聊天记录:存储和检索LLM响应历史。例如,聊天机器人的聊天记录。
让我们看一个在git日志数据集上执行基于时间的搜索的例子。在git日志中,每个条目都有时间戳、作者和有关提交的一些信息。
为了说明如何使用TimescaleVector的基于时间的矢量搜索功能,我们将询问有关TimescaleDB的git日志历史的问题。每个git提交条目都有一个与之相关的时间戳,以及消息和其他元数据(例如,作者)。
我们将演示如何使用基于时间的UUID创建节点,以及如何使用Timescale Vector Vector存储运行带有时间范围过滤器的相似性搜索。
从git日志中的每个提交创建节点
首先,我们使用Pandas从demo CSV文件(链接见文末引用7)加载git日志条目:
importpandasaspdfrompathlibimportPath# Read the CSV file into a DataFrame
file_path = Path("../data/csv/commit_history.csv")
df = pd.read_csv(file_path)
接下来,我们将为git日志数据集中的每个提交创建类型为TextNode的节点,提取相关信息并分别将其分配给节点的文本和元数据。
fromllama_index.schemaimportTextNode, NodeRelationship, RelatedNodeInfo# Create a Node object from a single row of datadefcreate_node(row):
record = row.to_dict()
record_name = split_name(record["author"])
record_content = str(record["date"]) +" "+ record_name +" "+ str(record["change summary"]) +" "+ str(record["change details"])
node = TextNode(
id_=create_uuid(record["date"]),
text= record_content,
metadata={
'commit': record["commit"],
'author': record_name,
'date': create_date(record["date"]),
}
)
returnnode
nodes = [create_node(row)for_, rowindf.iterrows()]
Note:上面的代码引用了两个辅助函数来获得正确格式的内容(split_name()和create_date()),为了简洁起见,我们省略了它们。完整的代码包含在本文末尾参考资料部分链接的教程中。
根据每个git提交的日期为每个节点创建uuid
我们将仔细研究用于创建每个节点的id_的辅助函数。对于LlamaIndex中基于时间的搜索,Timescale Vector使用UUID v1的“datetime”部分将向量放置在正确的时间分区中。Timescale Vector的Python客户端库提供了一个简单易用的函数,名为uuid_from_time,用于从Python DateTime对象创建UUID v1,然后我们将使用它作为TextNodes的ids。
fromtimescale_vectorimportclient# Function to take in a date string in the past and return a uuid v1defcreate_uuid(date_string: str):
ifdate_stringisNone:
returnNone
time_format ='%a %b %d %H:%M:%S %Y %z'
datetime_obj = datetime.strptime(date_string, time_format)
uuid = client.uuid_from_time(datetime_obj)
returnstr(uuid)
由于我们过去处理的是时间戳,因此我们利用uuid_from_time函数来帮助为每个节点生成正确的uuid。如果希望将当前日期和时间与节点(或文档)相关联,以便进行基于时间的搜索,则可以跳过此步骤。默认情况下,当节点被添加到Timescale Vector中的表中时,将自动生成与当前日期和时间相关联的UUID。
让我们看一下节点的内容:
print(nodes[0].get_content(metadata_mode="all"))
commit:44e41c12ab25e36c202f58e068ced262eadc8d16
author: Lakshmi Narayanan Sreethar
date:2023-09-521:03:21+0850
Tue Sep521:03:212023+0530Lakshmi Narayanan Sreethar Fix segfaultinset_integer_now_func When an invalid function oidispassed to set_integer_now_func, it finds out that the function oidisinvalid but before throwing the error, it calls ReleaseSysCache on an invalid tuple causing a segfault. Fixed that by removing the invalid call to ReleaseSysCache. Fixes#6037
为每个节点的文本创建矢量Embeddings
接下来,我们将创建每个节点内容的向量Embeddings,这样我们就可以对与每个节点相关联的文本执行相似性搜索。我们将使用OpenAIEmbedding模型来创建Embeddings。
# Create embeddings for nodesfromllama_index.embeddingsimportOpenAIEmbedding
embedding_model = OpenAIEmbedding()fornodeinnodes:
node_embedding = embedding_model.get_text_embedding(
node.get_content(metadata_mode="all")
)
node.embedding = node_embedding
加载节点到Timescale Vector矢量存储
接下来,我们将创建一个“TimescaleVectorStore”实例,并将我们创建的节点添加到其中。
# Create a timescale vector store and add the newly created nodes to it
ts_vector_store = TimescaleVectorStore.from_params(
service_url=TIMESCALE_SERVICE_URL,
table_name="li_commit_history",
time_partition_interval= timedelta(days=7),
)
ts_vector_store.add(nodes)
为了利用Timescale Vector高效的基于时间的搜索,我们需要在实例化Timescale
Vector Vector存储时指定time_partition_interval参数。此参数表示按时间划分数据的每个间隔的长度。每个分区将包含在指定时间长度内的数据。
在上面的例子中,为了简单起见,我们使用7天,但是您可以为您的应用程序使用的查询选择任何有意义的值—例如,如果您经常查询最近的向量,您可能希望使用较小的时间增量,例如一天,或者如果您查询长达十年的时间周期的向量,那么您可能希望使用较大的时间增量,例如六个月或一年。根据经验,普通查询应该只涉及几个分区,同时您的完整数据集应该适合1000个分区,但不要太过强调—系统对这个值不是很敏感。
带时间过滤器的相似度搜索
现在我们已经将包含向量Embeddings数据和元数据的节点加载到Timescale vector
vector store中,并在存储向量和元数据的表上启用了自动基于时间的分区,我们可以使用基于时间的过滤器查询我们的vector store,如下所示:
# Query the vector database
vector_store_query = VectorStoreQuery(query_embedding = query_embedding, similarity_top_k=5)# Time filter variables for query
start_dt = datetime(2023,8,1,22,10,35)# Start date = 1 August 2023, 22:10:35
end_dt = datetime(2023,8,30,22,10,35)# End date = 30 August 2023, 22:10:35# return most similar vectors to query between start date and end date date range# returns a VectorStoreQueryResult object
query_result = ts_vector_store.query(vector_store_query, start_date = start_dt, end_date = end_dt)
让我们看一下查询返回的节点的日期和内容:
# for each node in the query result, print the node metadata datefornodeinquery_result.nodes:
print("-"*80)
print(node.metadata["date"])
print(node.get_content(metadata_mode="all"))
--------------------------------------------------------------------------------2023-08-314:30:23+0500
commit:7aeed663b9c0f337b530fd6cad47704a51a9b2ec
author: Dmitry Simonenko
date:2023-08-314:30:23+0500
Thu Aug314:30:232023+0300Dmitry Simonenko Feature flagsforTimescaleDB features This PR adds..
--------------------------------------------------------------------------------2023-08-2918:13:24+0320
commit: e4facda540286b0affba47ccc63959fefe2a7b26
author: Sven Klemm
date:2023-08-2918:13:24+0320
Tue Aug2918:13:242023+0200Sven Klemm Add compatibility layerfor_timescaledb_internal functions With timescaledb2.12all the functions presentin_timescaledb_internal were…
--------------------------------------------------------------------------------2023-08-2212:01:19+0320
commit: cf04496e4b4237440274eb25e4e02472fc4e06fc
author: Sven Klemm
date:2023-08-2212:01:19+0320
Tue Aug2212:01:192023+0200Sven Klemm Move utility functions to _timescaledb_functions schema To increase schema security we donotwant to mix…
--------------------------------------------------------------------------------2023-08-2910:49:47+0320
commit: a9751ccd5eb030026d7b975d22753f5964972389
author: Sven Klemm
date:2023-08-2910:49:47+0320
Tue Aug2910:49:472023+0200Sven Klemm Move partitioning functions to _timescaledb_functions schema To increase schema security…
--------------------------------------------------------------------------------2023-08-915:26:03+0500
commit:44eab9cf9bef34274c88efd37a750eaa74cd8044
author: Konstantina Skovola
date:2023-08-915:26:03+0500
Wed Aug915:26:032023+0300Konstantina Skovola Release2.11.2This release contains bug fixes since the2.11.1release…
成功!
请注意,只有在指定的开始和结束日期范围(2023年8月1日和2023年8月30日)内具有时间戳的向量才会包含在结果中。
下面是一些直观的原因,说明为什么Timescale Vector的基于时间的分区可以加速使用基于时间的过滤器的ANN查询。
Timescale
Vector按时间对数据进行分区,并在每个分区上分别创建ANN索引。然后,在搜索过程中,我们执行一个三步过程:
·步骤1:过滤不匹配时间谓词的分区。
·步骤2:对所有匹配分区执行相似度搜索。
·步骤3:合并步骤2中每个分区的所有结果,重新排序,并按时间过滤结果。
Timescale
Vector利用TimescaleDB的超级表,它根据时间戳自动划分向量和相关元数据。这使得通过与查询向量的相似性和时间对向量进行高效查询成为可能,因为不在查询时间窗口内的分区被忽略,通过一次过滤掉整个数据条,使得搜索效率大大提高。
当在TimescaleVectorStore上执行向量相似性搜索时,我们也可以指定一个时间过滤器,提供开始日期和时间增量,而不是指定搜索的开始和结束日期:
# return most similar vectors to query from start date and a time delta later
query_result = ts_vector_store.query(vector_store_query, start_date = start_dt, time_delta = td)
我们还可以在提供的end_date和时间增量中指定时间过滤器。此语法对于过滤搜索结果以在特定日期截止之前包含向量非常有用。
# return most similar vectors to query from end date and a time delta earlier
query_result = ts_vector_store.query(vector_store_query, end_date = end_dt, time_delta = td)
基于TimescaleVector的LlamaIndex应用中基于时间的上下文检索增强检索生成
让我们把所有内容放在一起,看看如何使用TimescaleVectorStore在我们上面检查的git日志数据集上为RAG提供动力。
为此,我们可以使用TimescaleVectorStore作为QueryEngine。在创建查询引擎时,我们使用TimescaleVector的时间过滤器,通过将时间过滤器参数vector_strore_kwargs传递,将搜索限制在相关的时间范围内。
fromllama_indeximportVectorStoreIndexfromllama_index.storageimportStorageContext
index = VectorStoreIndex.from_vector_store(ts_vector_store)
query_engine = index.as_query_engine(vector_store_kwargs = ({"start_date": start_dt,"end_date":end_dt}))
query_str ="What's new with TimescaleDB functions? When were these changes made and by whom?"
response = query_engine.query(query_str)
print(str(response))
我们问了LLM一个关于我们的git日志的问题,即“What's
new with TimescaleDB functions? When were these changes made and by whom?”(“TimescaleDB函数有什么新功能?”这些改动是什么时候做的,是谁做的?”)
下面是我们得到的响应,它综合了从语义搜索返回的节点和在Timescale Vector存储上基于时间的过滤:
TimescaleDB functions have undergone changes recently. These changes include the addition of several GUCs (Global User Configuration) that allowforenablingordisabling major TimescaleDB features. Additionally, a compatibility layer has been addedforthe"_timescaledb_internal"functions, which were moved into the"_timescaledb_functions"schema to enhance schema security. These changes were made by Dmitry SimonenkoandSven Klemm. The specific dates of these changes are August3,2023,andAugust29,2023, respectively.
这是一个强大概念的简单示例——在您的RAG应用程序中使用基于时间的上下文检索可以帮助为您的用户提供更相关的答案。这种基于时间的上下文检索对任何具有自然语言和时间成分的数据集都很有帮助。由于其高效的基于时间的相似性搜索功能,Timescale Vector可以独特地实现这一点,并且由于Timescale
Vector集成,在LlamaIndex应用程序中利用它很容易。
今年我深耕于大模型(LLM)应用,特别是RAG方向的研究与实践。
引用
1.Timescaledb的中文手册:https://www.luxiangdong.com/2018/09/09/timescaledb-what/
2.How We Made
PostgreSQL a Better Vector Database:https://www.timescale.com/blog/how-we-made-postgresql-the-best-vector-database/
3.Jeff Liu的Medium:https://medium.com/llamaindex-blog/timescale-vector-x-llamaindex-making-postgresql-a-better-vector-database-for-ai-applications-924b0bd29f0
4.微软的DiskANN算法介绍:https://www.microsoft.com/en-us/research/publication/diskann-fast-accurate-billion-point-nearest-neighbor-search-on-a-single-node/
5.Timescale
Vector:https://www.timescale.com/ai
6.Timescale
Vector Store的LlamaIndex教程:https://gpt-index.readthedocs.io/en/stable/examples/vector_stores/Timescalevector.html
7.CSV的下载地址:https://s3.amazonaws.com/assets.timescale.com/ai/commit_history.csv
出自:https://mp.weixin.qq.com/s/9wo1FHjOnZtZXYMUOw9Pag
一款免费的在线视频创作工具,它使用AI和智能自动化来创建引人入胜的视频,速度比传统视频创作方法快 10 倍。