Stable Diffusion高级教程 – 图生图(img2img)模式
发布时间:2024年06月06日
前言
现在终于可以介绍 Stable Diffusion 除了文生图 (txt2img) 之外最重要的功能:图生图 (img2img)。顾名思义,除了根据正向和反向提示词之外,还需要基于一张图片生成图。这个模式下功能很多我们挨个说
img2img
图生图模式下的默认功能,我们先看一下主界面:
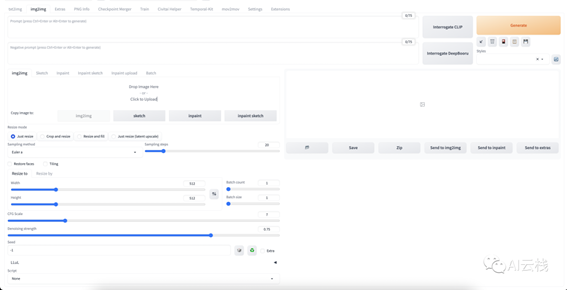
上面还是正面提示词和负面提示词,接着是一个上传图片的区域,写着「Drop Image Here - or - Click to Upload」。然后就是相关参数,大部分在文生图里面已经见过,只有Resize、
modeDenoising是新增的,我们挨个介绍:
strength
1.Resize mode。当上传图片尺寸和要生成的图的尺寸不同时,需要选择调整大小方案。
2.Sampling Method 用于去噪,平衡生成图的速度和质量。内置多种算法可供选择。目前看起来 DPM++ 2M
Karras 用的比较多。
3.Sampling Steps 是去噪过程的采样步骤数。越多越好,但需要更长的时间。一般在 20-28 之间。
4.宽度和高度 (Width/Height),输出图像的大小。按需调整即可。
5.Batch Count 批次数量,我更愿意用下面的 Batch size 调整生产图的总数。
6.Batch size,每一批次要生成的图像数量。可以在测试提示时多生成一些,因为每个生成的图像都会有所不同。生成的图像总数等于 Batch Count 乘以 Batch size。
7.CFG (Classifier Free Guidance) scale,提示词相关性, 用于控制模型应在多大程度上遵从您的提示。他有几个只可选: 1 (大多忽略你的提示),3 (更有创意),7 (遵循提示和自由之间的良好平衡),15 (更加遵守提示),30 (严格按照提示操作),常用的是 7,做个平衡。测试时可以换这个值体验区别。
8.Denoising strength。降噪强度,常翻译成「重绘幅度」,取值范围是 0-1,描述新生成的图片与原图的相似程度,数值越小,采样越少,相似度越高,算的越快 (采样数 = Denoising strength* Sampling Steps)
9.Seed,生成的每个图像都有自己的种子值,修改这个值可以控制图像的内容。
10.Script。用户可以编写脚本代码,以实现一些特殊定制的功能。这个未来可以具体说,目前还没有遇到。
先具体说说Resize mode(当然上传的图片最好与生图设置的一致):
1.Just resize:调整图片为生图设置的宽高。若上传图片的宽高与生成设置的宽高不一致,则该图片会被压扁。这个我非常不推荐使用,会让图片非常奇怪。
2.Crop and resize:裁切图片以符合生图的宽高,我最推荐的方式。
3.Resize and fill:裁切并调整图片宽高,若上传图片的宽高与生成设置的宽高不一致,则多出来的区域会自动填满。
4.Just resize (latent upscale):调整图片大小为生图设置的宽高,并使用潜在空间放大。
这个模式下最主要的就是调Denoising参数。我们用下面这张从网上找的新垣结衣的照片来体验:
strength

首先注意,我选择这个图是有 2 个原因的:
1.这个一张人像正面近像,在生成新图后更容易感受到 SD 的模型的作用
2.照片可以看到手部有动作,我会生成一张有问题的图让你感受到目前图生图模式的问题
我希望通过 SD 把这个真人照片做出动漫的效果,咱们先来个较大的Denoising的值,为了方便对比我用了固定的 Seed:
strength
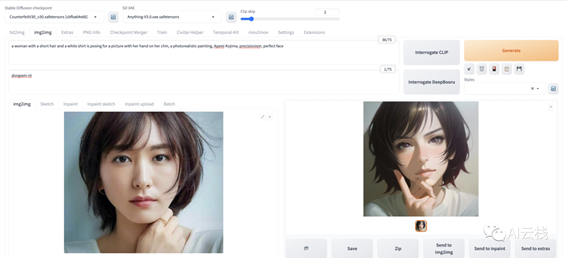
我直接把生成参数列出来:
a woman with a short hair and a white shirt is posing for a picture with her hand on her chin, a photorealistic painting, Ayami Kojima, precisionism, perfect face
Negative prompt: dongwm-nt,bad finger, bad body
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 8, Seed: 2345567052, Size: 512x512, Model hash: cbfba64e66, Model: CounterfeitV30_v30, Denoising strength: 0.65, Clip skip: 2这里有一点需要特别的提一下,正面提示词不是我写的。在图生图模式里,生成按钮左边有 2 个选项,分别是「Interrogate CLIP」和「Interrogate DeepBooru」。在上传图片后,可以通过「Interrogate
CLIP」反推出提示词,我这个就是这么生成的。另外也说一下「Interrogate DeepBooru」,这说的是一个开源的女孩图片特征提取器,上传图片可以获得图片的标签,我已经把链接都放在了延伸阅读里面:
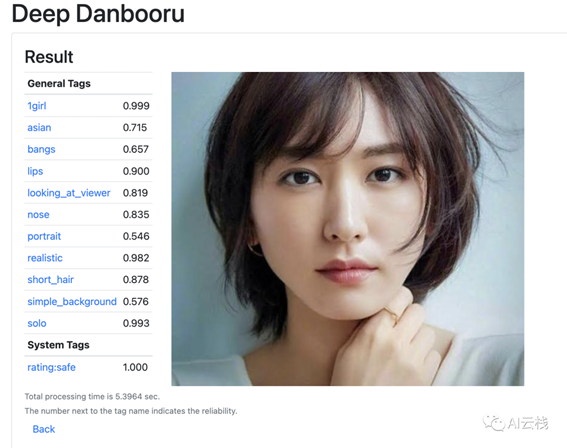
PS: 如果你选择DeepBooru反推,不能直接使用那些标签,你需要从中筛选需要的、合理的标签,否则结果会完全偏离。
好的,说回来。之前已经说过,Denoising的值越大越和原图不符,所以如果你希望「微调」,这个值不应该大于 0.4,现在我们先取了一个更大的值,你可以看到生成图的人物手部的结果是有问题的。而且注意,负面提示词
strengthdongwm-nt本身是包含bad finger,bad这些的。
body
图生图不是万能的甚至很难达到你的预期
是的,这是我的体验。这个模式下如果你想要生成你想要的效果,对于大模型、微调模型、提示词、参数等都有要求,在前期,你很可能生成奇怪的图,你需要不断尝试总结经验。
不同的 Denoising
strength 效果的区别
我们使用 x/y/z 脚本试试不同的重绘幅度值看看生成的效果:

可以看到随着 Denoising strength 变大,越来越不像原图了。
同时,我们还可以重叠各种微调模型,下面是使用了 VAE、Lora 和 HyperNetwork 后的效果:

这就是微调模型的作用,不过注意,微调后手部后两张还是会有问题。
PS,这个例子用的主模型是:https://civitai.com/models/4468/counterfeit-v30
绘图 (Sketch)
第二个 Tab 是 Sketch,他适合有美术基础的用户,可以给一张现有的图加东西,或者画出你想要的东西,然后再输入提示词完善,我这个没有画画细胞的人基本不用,在这里也举 2 个例子 (我也就这个水平啦)。
因为我们一会要用笔刷编辑图片,我需要用到颜色,所以加启动参数,重启 webui:
./webui.sh --disable-safe-unpickle --gradio-img2img-tool color-sketchOk, 先尝试基于现有图做修改的,我用了下面这张图:

上传后就进入了编辑模式,然后我用笔刷选了个粉色的把头发涂变色
(当然提示词中并没有提到粉色头发):
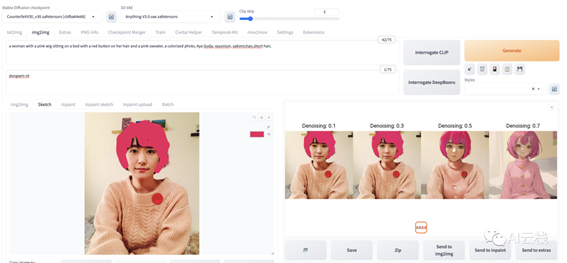
可以看到Denoising到了 0.7 才看起来正常,前面的那个「涂」的效果很明显。所以如果你使用和原图差别很大的颜色涂,那么需要更大的重绘幅度值,但是相对的,生成图和原图差别很大。如果选择对比色较少的例如黑色,那么重绘幅度 0.4 可能就够了。
strength
接着我们试试完全从零画一幅画 (叫「涂鸦」更合适),为了展示 SD 的厉害之处,我特意选择了一个「复杂」的构图,在本灵魂画手非常努力作画后,看一下生成图的效果这样的:
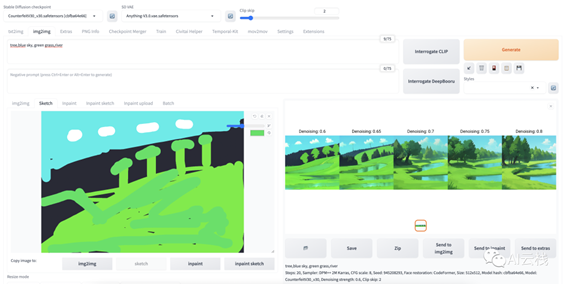
注意哈,因为这个模式需要上传图,所以我这里只是截了个终端的黑色区域作为背景图。我知道大家看不懂我的 Sketch🤦🏻 ♀️,解释一下,这幅画我希望展示蓝天白云,下面是草地和几棵树 (提示词也非常直白),草地中间还有一点小溪(实在不知道溪水用什么颜色就直接换个绿区别一下)中间黑色的是背景我没涂东西,主要想看看 SD 会怎么理解。
这个效果我还是很满意的,可以说 0.65 的图已经完全达到我的预想了。
PS: 这种绘画的方法需要更大的Denoising值,否则用户就得具有极强的画画天赋啦
strength
局部绘制 (Inpaint)
用户指定在图像中特定区域进行修改,而保证其他区域不变。这个我认为图生图模式下最又实用价值的模式,类似换脸、换衣服、换背景等等需要都可以通过它来实现。在上面的 Sketch 里面的例子一,我曾经想给新垣结衣换头发颜色,但是需要Denoising值比较大才会看起来正常,但是通过也和原图差别非常大了。而局部绘制可以平缓的给新垣结衣换头发颜色。来试试:
strength
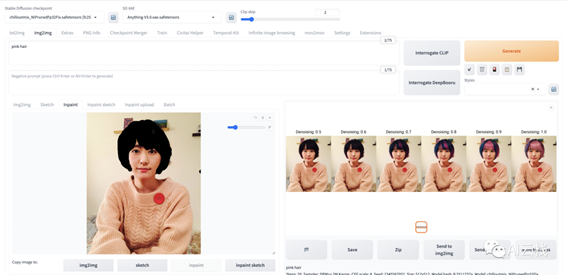
我涂黑了头发,当然差不多就可以,SD 会清楚你想把头发改颜色,另外要在提示词加上pink让 SD 朝着粉色头发来。可以看到随着
hairDenoising增大,头发越来越粉。
strength
接着看一下参数:
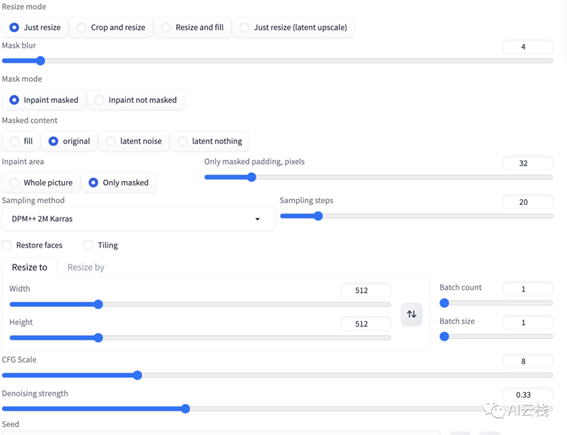
这次新增 5 个参数:
1.Mask blur。图片上的笔刷毛边柔和程度。我一般默认
2.Mask mode。选择要让 AI 填满涂黑区域
(Inpaint masked),或是填满未涂黑区域 (Inpaint not masked)。
3.Masked content。要填充的内容类型。Fill:让 AI 参考涂黑附近的颜色填满区域;Original:在填满区域的时候参考原图底下的内容;latent noise:使用潜在空间填满,可能会生出跟原图完全不相关的内容;latent nothing:使用潜在空间填满,不加入噪声
4.Inpaint area。选择要填满整张图片 (Whole picture) 或是只填满涂黑的区域 (Only masked)
5.Only masked padding, pixels。像素内距。
局部绘制 - 涂鸦蒙版 (Inpaint sketch)
局部绘制 Inpaint 的一个更细的分类,它们的区别是局部绘制中,用户涂黑的部分表示该部分可以被重绘,而在局部绘制 - 涂鸦蒙版(inpaint sketch)中,用户涂鸦的部分不仅表示可以重绘,用户涂鸦的内容还会成为图像生成的内容来源,换个表达方法,局部绘制 - 涂鸦蒙版是「局部绘制 (Inpaint)」+「绘图 (Sketch)」的组合,通过一个例子来理解:
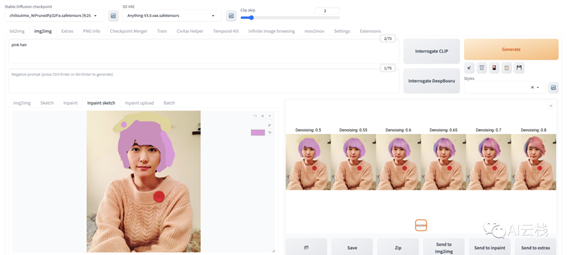
我涂了 2 个地方:1. 头发上的墙上背景,我希望它被 P 掉,2 粉色头发。然后提示词加了pink hair让 SD 能更理解我表达。所以最终生成的图里面的特点:
1.除了头发和背景改变,对人物外貌动作等未改变 (因为没有产生绘制),而且头发形状整体保持住了。
2.我 sketch 使用了一个偏紫的颜色,所以生成的图的头发颜色参考了这个颜色生成的微紫的粉色
3.可以看到 0.6 的效果是最好的,值越小越偏原图就能看出我涂鸦的痕迹,值越大头发走的越偏离我的意思
局部绘制 - 上传蒙版 (Inpaint upload)
可以在其他工具里 (例如 PS) 做好蒙版上传,而不是在 SD 里面创建蒙版。对于一些专业的用户这是一种更好的选择,因为在浏览器绘制蒙版的功能很简陋,其他专业软件做出来的效果会好得多。不过我不会 PS 这里就不举例了。
出自:https://mp.weixin.qq.com/s/akrfFa3sE3w8ACbrN1_Rvg
百度旗下 - 全流程AI创作工具