大模型RAG检索增强问答如何评估:噪声、拒答、反事实、信息整合四大能力评测任务探索
发布时间:2024年06月06日
检索增强生成(RAG)是减轻大型语言模型(LLM)幻觉的一种有前途的方法。然而,现有研究缺乏对检索增强生成对不同大型语言模型的影响的严格评估,这使得识别RAG对不同LLM的潜在能力瓶颈具有挑战性。
《Benchmarking Large Language Models in Retrieval-Augmented Generation》这一工作系统地研究了检索增强生成对大型语言模型的影响。
地址:https://arxiv.org/pdf/2309.01431.pdf
该工作分析了不同大型语言模型在RAG所需的4项基本能力方面的表现,包括噪声鲁棒性、拒答、信息整合和反事实鲁棒性,并建立了检索增强生成基准(RGB)。
该工作对于指引RAG研发的工作具有一定的借鉴意义,本文对该工作进行介绍,供大家一起参考。
该工作的贡献在于,我们现在做RAG都是做的pipeline,涉及到切块、相关性召回、拒答等多个环节,每个环节都可以单独做评测,文中提到的4个能力其实可以影射到每个环节当中。
不过,我们需要注意的是,每种评测都是有偏的,取决于评测数据,评测模型本身,变量太多,其真正的有效性如何,并不好说,我们关注这种评估方法,才是最大的意义所在。
一、4个衡量RAG性能的测试任务
该工作将RAG评测分为4个测试维度,如图1所示:
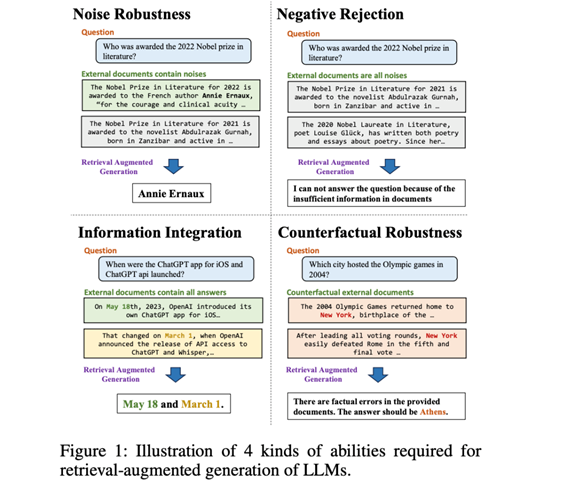
1、噪声鲁棒性(Noise Robustness)
模型能从噪声文档中提取有用信息。噪声文档定义为与问题相关但不包含任何相关信息的文档。在图1中的实例中,与"谁获得了2022年诺贝尔文学奖"问题相关的噪声文档包括有关2021年诺贝尔文学奖的报道。为此,噪声鲁棒性测试根据所需的噪声比,将外部文档包含一定数量噪声文档的实例包含在内。
2、否定拒绝(Negative Rejection)
当检索到的文档中不存在所需的知识点时,模型应拒绝回答问题。否定拒绝的测试包含外部文档只有噪声文档的实例。LLM预计会发出"信息不足"或其他拒绝信号。
3、信息整合(information
integration)
评估模型能否回答需要整合多个文档信息的复杂问题。在图1的例子中,对于"ChatGPTiOS应用程序和ChatGPTapi是什么时候推出的?"这个问题,LLMs应提供iOS上ChatGPT应用程序和ChatGPTAPI的推出日期信息。信息集成测试包含只能使用多个外部文件才能回答的问题。
4、反事实鲁棒性(CounterfactualRobustness)
该测试评估当通过指令向LLMs发出关于检索信息中潜在风险的警告时,模型能否识别检索文档中已知事实错误的风险。反事实鲁棒性的测试包括可以由LLM直接回答,但外部文档包含事实错误的实例。
二、评测数据的构建及衡量指标
1、数据构建
受以往LLM基准的启发,RGB采用问题解答的形式进行评估。
为了模拟真实世界的场景,使用实际的新闻文章来构建问题和答案数据。由于LLMs中包含大量知识,因此在测量前三种能力时可能会出现偏差。为了减少这种偏差,使用最新的新闻文章来构建RGB实例。此外,还通过搜索引擎从互联网上检索外部文档。
构建数据的整体流程如图2所示。
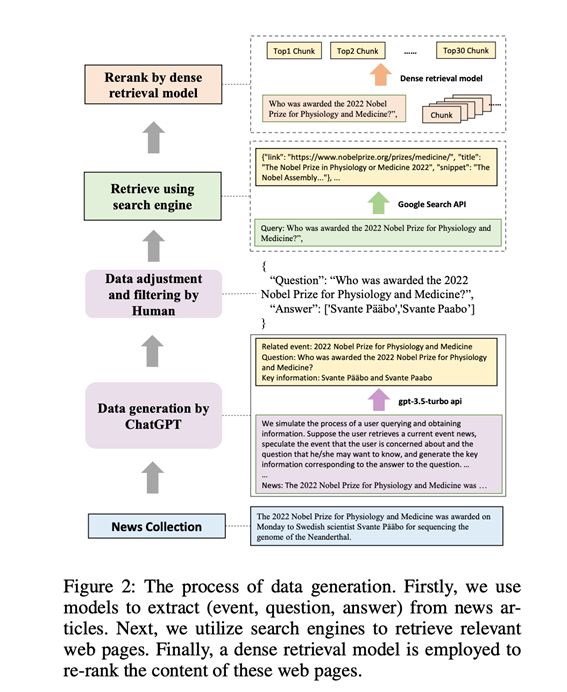
首先,生成QA实例。
首先收集最新的新闻报道,然后通过提示让ChatGPT为每篇报道生成事件、问题和答案。例如,如图2所示,对于一篇关于"2022年诺贝尔奖"的报道,ChatGPT会生成相应的事件、问题,并提供回答问题的关键信息。通过生成事件,模型能够初步过滤掉不包含任何事件的新闻文章。生成后,手动检查答案,并过滤掉难以通过搜索引擎检索的数据。
然后,使用搜索引擎检索。对于每个查询,使用谷歌的API获取10个相关网页,并从中提取相应的文本片段。同时读取这些网页,并将其文本内容转换成最大长度为300个token的文本块。利用现有的向量化检索模型,选出与查询匹配度最高的前30个文本块。这些经过重新筛选的文本块以及搜索API提供的片段作为外部文档,并根据是否包含答案分为肯定文档和否定文档。
最后,针对不同的任务,采用不同的方案进行组织处理。例如:
为了评估噪声鲁棒性,根据所需的噪声比例采样不同数量的负面文档。
为了测试否定拒绝能力,所有外部文档都是从否定文档中采样的。
为了测试信息整合能力,根据上述生成的问题进一步构建数据。这包括扩展或改写这些问题,使其答案包含多个方面。例如,问题"谁赢得了2023年超级碗的MVP?"可以改写为"谁赢得了2022年和2023年超级碗的MVP?",回答此类问题需要利用各种文件中的信息。
为了测试反事实鲁棒性。采用ChatGPT自动生成已知知识,使用提示让模型生成已知的问题和答案。例如,根据问题"谁获得了2022年诺贝尔生理学和医学奖?",模型将生成已知问题"谁获得了2021年诺贝尔文学奖?"并回答"阿卜杜勒拉扎克-古尔纳"。然后,对生成的答案进行人工验证,并如上所述检索相关文档。为了使文档不包含事实错误,手动修改了答案并替换了文档中的相应部分。
最后,该工作共收集了600个RGB基本问题、200个额外的信息整合能力问题和200个额外的反事实能力问题。其中一半是英文实例,另一半是中文实例。
2、评估指标
本基准的核心是评估大模型是否能够利用所提供的外部文档获取知识并生成合理的答案。
采用如下指标:
准确性用于衡量噪声鲁棒性和信息整合能力。采用精确匹配法,如果生成的文本与答案完全匹配,则视为正确答案。
拒绝率用于衡量否定拒绝率。当只提供有噪声的文档时,LLM应输出特定内容"由于文档信息不足,我无法回答该问题"。(使用说明来告知模型)。如果模型生成了这一内容,则表明拒绝成功。
错误检测率衡量模型能否检测出文件中的事实错误,以确保反事实鲁棒性。当所提供的文档包含事实错误时,模型应输出具体内容"所提供的文档中存在事实错误"。(使用内部结构来告知模型)。如果模型生成此内容,则表明模型已检测到文档中的错误信息。
纠错率衡量模型在识别错误后是否能提供正确答案,以确保模型的鲁棒性。要求模型在识别事实错误后生成正确答案。如果模型生成了正确答案,则表明模型有能力纠正文档中的错误。
指标公式为:

其中#tt为正确答案的数量,考虑到模型可能并不完全符合拒绝率和错误检测率的结构化要求,还使用ChatGPT对答案进行了额外的评估,即使用说明和演示来评估模型的回答,以确定它们是否能反映出文档中不存在的信息或识别出任何事实错误。
三、实验设置
在对比模型上,选用ChatGPT , ChatGLM-6B , ChatGLM2-6B , Vicuna-7b-v1.3 , Qwen-7B- Chat
, BELLE-7B-2M 等模型,并利用prompt方式进行测试。

1、噪声鲁棒性结果
根据外部文档中不同的噪声比率对准确率进行了评估,结果如表1所示,可以看到如下结论:
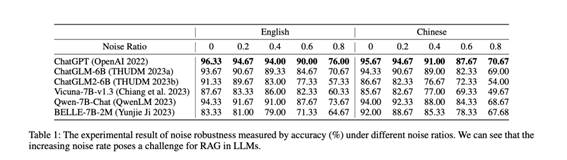
(1)RAG可以有效改善LLM的回复。即使在有噪声的情况下,LLM也能表现出很强的性能,这表明RAG是LLM生成准确可靠的响应的一种很有前途的方法。
(2)噪声率的增加给LLM的RAG带来了挑战。当噪声率超过80%时,模型的准确性就会明显下降。例如,ChatGPT的性能从96.33%降至76.00%,而ChatGLM2-6B的性能则从91.33%降至57.33%。
为了更好地理解噪声对模型生成的负面影响,可以进行归因分析,通过检查不正确的答案,可以发现这些错误通常源于三个原因,如表2所示。

(1)远距离信息。在处理外部文档时,当与问题相关的信息与与答案相关的信息相距甚远时,模型往往难以确定正确答案。这种情况很常见,因为在互联网上经常会遇到较长的文本。
在这种情况下,问题信息通常会在文件开头出现,然后用代词来指代。在表2中,问题信息("卡塔尔2022年公开赛")只在开头被提及了一次,而且与答案文本"AnettKontaveit"的出现位置相距甚远。这种情况可能会导致LLM依赖其他文件中的信息,从而产生错误印象,即半明半暗。
(2)证据的不确定性。在人们高度关注的事件(如苹果公司发布新产品或奥斯卡颁奖典礼)发生之前,网络上往往会流传大量的猜测信息。虽然相关文件明确指出这是不确定性或猜测性内容,但它们仍然会对检索增强生成的LLM产生影响。
在表2中,当噪声比增加时,错误文档的内容都是一些人对耳机名称("AppleRealityPro")的预测。即使相关文档中有正确答案("VisionPro"),模型仍会被不确定的证据误导。
(3)概念混淆。外部文档中的概念可能与问题中的概念相似,但又不同。这可能会给LLM造成混淆,使LLM生成错误的答案。
在表2中,模型的重点是文档中的概念"汽车收入",而不是问题中的"收入"。这说明发现了LLM在检索增强生成方面的某些局限性。为了有效处理互联网上存在的大量噪音,需要对模型进行进一步的详细改进,例如长文档建模和精确的概念理解。
2、否定拒绝测试结果
评估只提供噪声文档时的拒绝率,结果如表3所示。
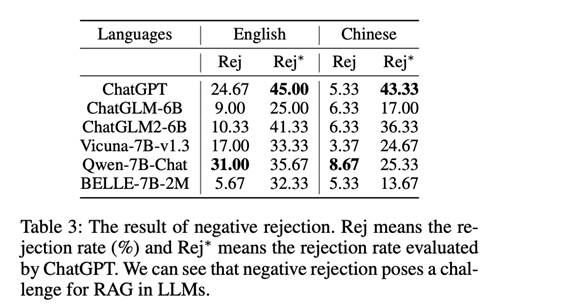
除了通过精确匹配来评估拒绝率(表3中的Rej)外,还利用ChatGPT来确定LLM的回复是否包含任何拒绝信息(表3中的Rej∗)。可以看到负面拒绝对RAG提出了挑战。英文和中文法律硕士的最高拒绝率分别只有45%和43.33%。这表明LLM很容易被噪声文档误导,从而导致错误的答案。
通过比较Rej和Rej∗,发现LLMs无法严格遵守指令,而且它们经常产生不可预测的反应,因此很难将其用作状态触发器(例如识别拒绝)。
在归因方面,如表4所示,里面有一些case:

第一个错误是因为证据的不确定性。虽然文件中只提到了与"亚当-麦凯"的联系,并没有明确指出他是这部电影的导演,但模型仍然得出结论认为他是这部电影的导演。
第二个错误是因为概念混淆。答案中提供的信息与"2018年冬奥会"有关,而不是问题中提到的"2022年奥运会"。与直接生成答案相比,检索增强生成会带来更大的否定拒绝问题,因为它提供的相关文档可能会误导LLM,导致错误的回答。也就是说,提高LLM将问题与适当文档准确匹配的能力至关重要。
3、信息集成测试平台的结果
根据外部文档中不同的噪声比率对准确率进行了评估,结果如表5所示。与表1相比,发现该模型的信息整合能力较弱,这反过来又影响了其噪声鲁棒性。
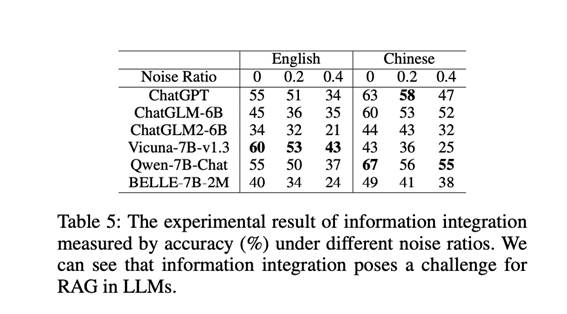
可以看到:
(1)在LLM中,信息整合对RAG是一个挑战。即使在没有噪声的情况下,LLMs的最高准确率也只能分别达到英文和中文的60%和67%。加入噪声后,最高准确率下降到43%和55%。这些结果表明,LLMs难以有效整合信息,不适合直接回答复杂问题。
(2)对于有噪声文档的RAG来说,复杂问题更具挑战性。当噪声比为0.4时,性能下降明显,但对于简单问题,只有在噪声比为0.8时才会出现明显下降。这表明复杂问题更容易受到噪声的干扰。这是因为解决复杂问题需要整合来自多个文档的信息,而这些信息可以被视为彼此间的噪声,从而使模型更难从文档中提取相关信息。
进一步地,通过对ChatGLM2-6B进行误差分析(噪声比为0)之后,发现,除了在噪声鲁棒性实验中发现的类似错误(占总数的38%)外,还有三种独特的错误,表6中列出了这些情况。可以看到:

(1)合并误差(占总数的28%)。模型有时会合并两个子问题的答案,从而导致错误。它错误地使用了一个问题的答案来回答两个问题。此时,模型会忽略任何与一个子问题相关的文档。
例如,在表6中,它错误地指出D组是法国队和德国队的世界杯小组,而实际上德国队被分到了E组。
(2)忽略错误(占总数的28%)。有时,模型可能会忽略其中一个子问题,只回答另一个问题。这种错误发生在模型对问题缺乏全面理解,没有认识到问题由多个子问题组成的情况下。结果,模型只考虑一个子问题的相关文档来生成答案,而忽略了另一个子问题所提出的问题。
例如,在表6中,模型只提供了2022年超级碗MVP的答案,而没有考虑2023年。
(3)配对错误(占总数的6%)。有时,模型会错误地将一个小问题的文档识别为另一个小问题的文档,从而导致答案错位。
例如,在表6中,第三个答案有两个错误:忽略错误和对齐错误。首先,模型只提到了2023年(第95届)奥斯卡金像奖的最佳影片,完全忽略了2022年的奖项。此外,模型还错误地指出《CODA》是2023年的最佳影片,而实际上该片是在2022年获得最佳影片奖的。
上述错误主要是由于对复杂问题的理解有限,从而阻碍了有效利用不同子问题信息的能力。关键在于提高模型的再分析能力,一种可能的解决方案是使用思维链方法来分解复杂问题。然而,这些方法会降低推理速度,无法提供及时回复。
4、反事实鲁棒性测试的结果
为了确保LLM拥有相关知识,通过直接向它们提问来评估它们的性能,只考虑准确率超过70%的LLM,结果如表7所示,给出了以下指标:不包含任何文档的准确率、包含反事实文档的准确率、错误检测率和错误纠正率。
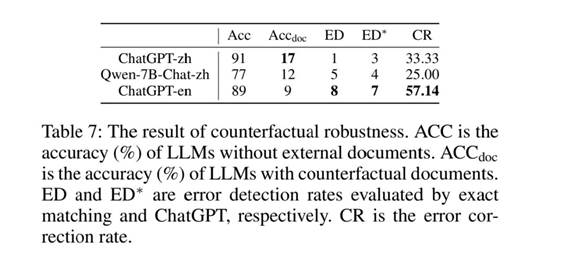
可以看到,LLM很难识别和纠正文档中的事实错误。这表明模型很容易被包含错误事实的文件误导。值得注意的是,检索增强生成的设计并不是为了自动处理特定语境中的事实错误,因为这与模型缺乏知识并依赖检索文档获取额外信息的基本假设相矛盾。然而,由于互联网上假新闻泛滥,这个问题在实际应用中至关重要。现有的LLM不具备处理因错误信息造成的不准确回复的保障措施。事实上,它们在很大程度上依赖于检索到的信息。
总结
本文主要介绍了《Benchmarking Large Language Models in Retrieval-Augmented Generation》这一工作,该工作系统地评估了LLMs中检索增强生成的四种能力:噪声鲁棒性、否定拒绝、信息整合和反事实鲁棒性。
实验结果表明,当前的LLM在4项能力上存在局限性,要将RAG有效地应用于LLM,仍有大量工作要做。
该工作的贡献在于,我们现在做RAG都是做的pipeline,涉及到切块、相关性召回、拒答等多个环节,每个环节都可以单独做评测,文中提到的4个能力其实可以影射到每个环节当中。
不过,我们需要注意的是,每种评测都是有偏的,取决于评测数据,评测模型本身,变量太多,其真正的有效性如何,并不好说,我们关注这种评估方法,才是最大的意义所在。
参考文献
1、https:/arxiv.org/pdf/2309.01431.pdf
2、https://blog.csdn.net/Ffffatass/article/details/133340293
出自:https://mp.weixin.qq.com/s/YFji1s2yT8MTrO3z9_aI_w
主要提供Ai智能对话、Ai魔法绘画及一系列Ai的深度研发,为工作及生活提供了极大的便捷。