玩一玩ChatGLM3,1660s即可流畅运行!
发布时间:2024年06月06日
ChatGLM应该是最早支持低配显卡运行的大语言型。首个开源版本大概在半年前就发布了。
发布之后,在同类模型中各项测试都表现优异。
同时,也出现了大量的配套项目,比如运行库,微调,知识库等...
甚至发展出了一个专门编写代码的项目codegeex,我在VS已经白嫖好一段时间了。
现在ChatGLM已经发展了到了3.0版本,期间也有也有不少人问我,能不能搞个ChatGLM的整合包,今天终于可以交作业了。

根据官方资料介绍:
ChatGLM3 是智谱AI和清华大学KEG实验室联合发布的新一代对话模型。在保留了前两代模型 对话流畅,部署门槛低等众多优秀特性的基础上,又引入了新的特征。
更强大的基础模型。ChatGLM3在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,它是100亿参数以下模型中最强。
更完整的功能支持,原生支持工具调用(Function
Call)、代码执行(Code Interpreter)和
Agent 任务等复杂场景。
更全面的开源序列,除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K
介绍就说这么多,下面说说怎么把这个东西玩起来!我先简单的介绍下安装配置,看不懂的直接拉到最后。我会提供一键运行包,下载解压运行即可使用。
1. 硬件配置
下面是运行不同模型需要的显存配置表格。
可以看到一张3090就可以轻松玩转不同量化等级的模型。没有3090也没关系,只要一张6G+显存的显卡也能玩起来,比如1660s,现在闲鱼价格大概在几百块的样子。
我之前介绍过的千问(Qwen)和百川(baichuan)运行要求就是8G+显存。也就是说在运行要求上,ChatGLM系列更具优势。
2. 安装配置
默认的安装配置并不复杂,只要先克隆项目,然后创建虚拟环境,最后根据配置文件安装依赖就可以了。
按照惯例最好是使用conda 创建一个虚拟环境。
conda create -n chatglm python=3.10conda activate chatglm
把项目克隆到本地:
git clone https://github.com/THUDM/ChatGLM3.git
进入本地目录并安装依赖:
cd ChatGLM-6B3pip install -r requirements.txt
Windows下配置,注意要单独安装一下Torch的GPU版本,推荐安装2.0以上版本,另外transformers
推荐为 4.30.2 的版本。
3. 代码调用
测试代码不用自己写,直接抄就好了。
1 from transformers import AutoTokenizer, AutoModel
2 tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
3 model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
4 model = model.eval()
5 response, history = model.chat(tokenizer, "你好", history=[])
6 print(response)
7 #你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
8 response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
9 print(response)
10 #.....
创建一个test.py把代码放到里面。
然后执行命令:
·
python test.py
由于默认代码使用的是transformers
库,所以默认回去HF自动下载模型,模型大小大概在11G。
比较不幸的是,国内已经无法正常访问HF,文件又特别大,所以要自备魔法工具,还得流量多网速快的那种。也可以通过国内的modelscope来下载模型。
另外一个问题是,代码中默认的模型为6B,大概需要13G显存,所以只有3090,4090等卡可以运行。
为了解决这个问题可以用4bit量化版,但是....ChatGLM3好像还没有提供离线量化版。
所以,最后我是使用了在线量化的方式。
只需要修改一行代码即可。
·
model = AutoModel.from_pretrained("THUDM\chatglm3-6b",trust_remote_code=True).quantize(4).cuda()
4. 运行Demo
上面的代码只能回答两个预设的问题,然后整个程序就结束了。如果要持续对话,可是使用项目自带的demo。有一个命令行版和两个网页版。
运行方法
·
python web_demo.py
运行之后,会需要一段时间加载模型,加载成功之后就会出现一个网址。复制网址在浏览器中打开就可以了。
核心的安装流程就都在上面了。配置这个东西只能自己去琢磨,没问题就是一行命令的事情,有问题,就是千奇百怪。
我遇到的问题,全网都没有搜到答案,然后我把本地的VS文件改了名字就一切正常了。
5. 一键运行包
玩项目,第一步呢是要玩起来,才能深入研究。而这第一步,往往没啥技术含量,但是搞起来又很麻烦。我可以助你们一臂之力。
根据提示获取软件包,并解压。
找到run.bat 直接双击运行既可以了。默认是基于gradio的网页版。
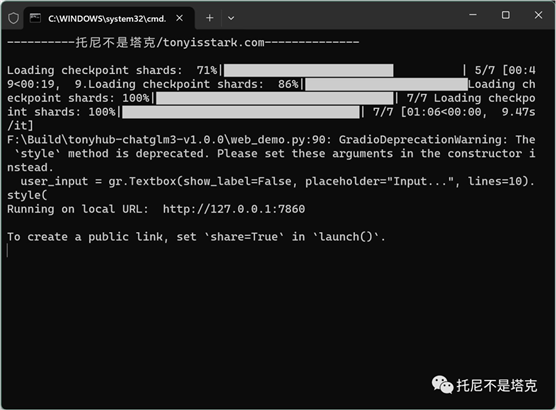
双击之后就立马开始加载模型,需要一些时间,电脑最好是有32G+的内存。加载完成之后出现Running on local URL,证明加载成功了,复制后面的网址,在浏览器中打开即可。
打开之后,左下方直接输入问题,点击提交,坐等回答就可以了。
可以根据上下文进行多轮问答。这个界面还提供了三个参数设置,一般不用动。修改top p和Temperature可以控制模型随机性和确定性。
run2.bat是基于streamlit的网页版。
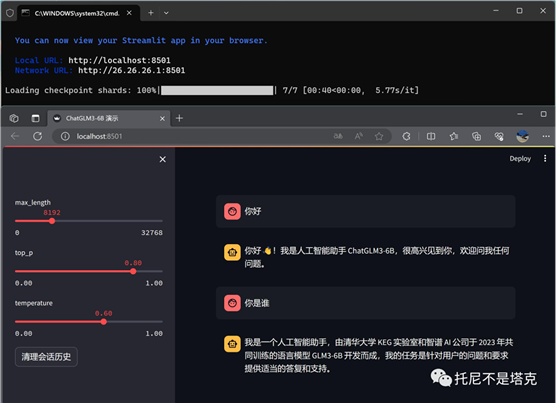
这个demo的加载逻辑和上面有点不同。双击之后会先打开一个网页,然后加载模型。加载完成之后,可以显示类似的参数和聊天窗口。然后就可以开始对话了。
软件包的获取方式:
给公众号托尼不是塔克发送chatglm即可直接获取下载链接。
另外预告一下,我会把这个ChatGLM系列的模型,还有一个千问的财务模型,一个最强的数学模型,全部加入到“Jarvis”中!这样一个包就可以运行各类最新最强的大语言模型了。
收工!大家可以活动一下大拇指咯!
出自:https://mp.weixin.qq.com/s/DtyWLUhFSrKvfKkCXGHRKA
Dreamer是一个集成了 Notion 和 Stable Diffusion 的AI生成图像的一种工具,无需在不同的应用程序或网站之间切换。