RAG从入门到精通-RAG简介
发布时间:2024年06月06日
前言
RAG(Retrieval Augmented Generation,检索增强生成)是一个将大规模语言模型(LLM)与来自外部知识源的检索相结合的框架,以改进问答能力的工程框架。本文讲对RAG进行简单介绍。
LLM的知识更新难题
在进入RAG的介绍之前,需要读者首先理解一个概念,LLM的知识更新是很困难的,主要原因在于:
1.LLM的训练数据集是固定的,一旦训练完成就很难再通过继续训练来更新其知识。
2.LLM的参数量巨大,随时进行fine-tuning需要消耗大量的资源,并且需要相当长的时间。
3.LLM的知识是编码在数百亿个参数中的,无法直接查询或编辑其中的知识图谱。
因此,LLM的知识具有静态、封闭和有限的特点。为了赋予LLM持续学习和获取新知识的能力,RAG应运而生。
工作原理
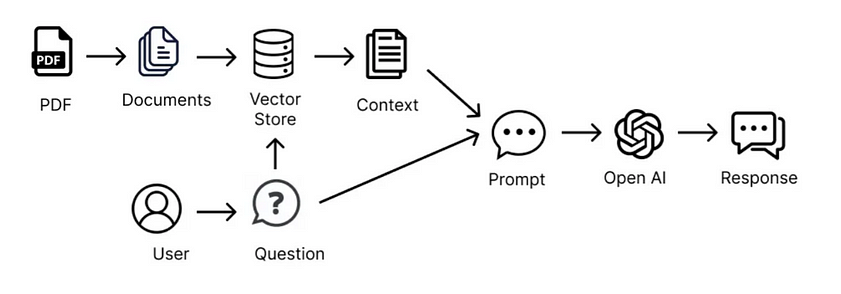
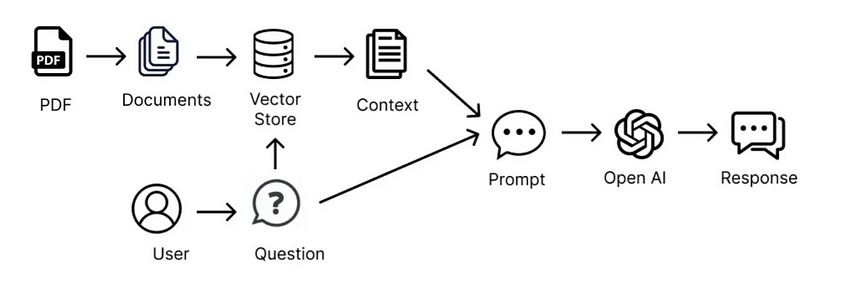
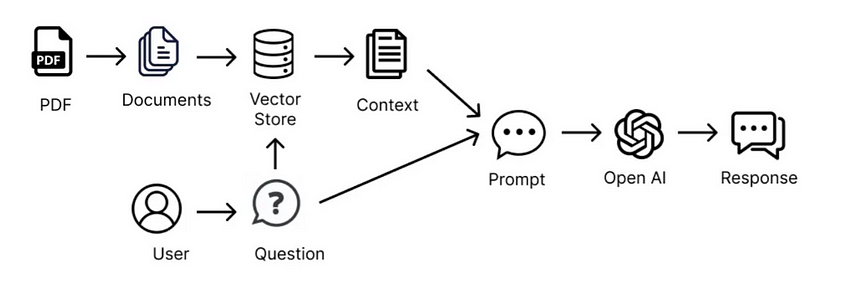
RAG本质上是通过工程化手段,解决LLM知识更新困难的问题。其核心手段是利用外挂于LLM的知识数据库(通常使用向量数据库)存储未在训练数据集中出现的新数据、领域数据等。通常而言,RAG将知识问答分成三个阶段:索引、知识检索和基于内容的问答。
第一阶段是知识索引,需要事先将文本数据进行处理,通过词嵌入等向量化技术,将文本映射到低维向量空间,并将向量存储到数据库中,构建起可检索的向量索引。在这个阶段,RAG涉及数据加载器、分割器、向量数据库、提示工程等组件以及LLM本身。
第二阶段是知识检索,当输入一个问题时,RAG会对知识库进行检索,找到与问题最相关的一批文档。这需要依赖于第一阶段建立的向量索引,根据向量间的相似性进行快速检索。
第三阶段是生成答案,RAG会把输入问题及相应的检索结果文档一起提供给LLM,让LLM充分把这些外部知识融入上下文,并生成相应的答案。RAG控制生成长度,避免生成无关内容。
这样,LLM就能够充分利用外部知识库的信息,而不需要修改自身的参数。当知识库更新时,新知识也可以通过prompt实时注入到LLM中。这种设计既发挥了LLM强大的语言生成能力,又规避了其知识更新的困境,使之能更智能地回答各类问题,尤其是需要外部知识支持的问题。
优点
RAG的优点主要体现在以下几个方面:
可以利用大规模外部知识改进LLM的推理能力和事实性。
使用LangChain等框架可以快速实现原型。
第一阶段的知识索引可以随时新增数据,延迟非常低,可以忽略不计。因此RAG架构理论上能做到知识的实时更新。
可解释性强,RAG可以通过提示工程等技术,使得LLM生成的答案具有更强的可解释性,从而提高了用户对于答案的信任度和满意度。
缺点
RAG的缺点主要表现在以下几个方面:
知识检索阶段依赖相似度检索技术,并不是精确检索,因此有可能出现检索到的文档与问题不太相关。
在第三阶段生产答案时,由于LLM基于检索出来的知识进行总结,可能缺乏一些基本世界知识,从而导致无法应对用户询问知识库之外的基本问题。
向量数据库是一个尚未成熟的技术,缺乏处理大量数据规模的通用方案,因此数据量较大时,速度和性能存在挑战。
在推理时需要对用户输入进行预处理和向量化等操作,增加了推理的时间和计算成本。
外部知识库的更新和同步,需要投入大量的人力、物力和时间。
需要额外的检索组件,增加了架构的复杂度和维护成本。
如何改进
由于上诉缺点的存在,直接使用LangChain等框架实现的RAG框架几乎无法直接在生产中使用,需要进行大量的工程化优化,总得来说,至少包括如下内容:
检查和清洗输入数据质量。
调优块大小、top k检索和重叠度。
利用文档元数据进行更好的过滤。
优化prompt以提供有用的说明。
总结
RAG是一种前景广阔但仍在发展的技术,需要仔细调优与优化才能达到可靠的性能。随着研究的继续,它可能会变得更加稳健,适合工业应用。
SheetAI 应用程序是一个 Google Workspace 插件,可让您直接在电子表格中运行 GPT并自动执行任务并生成公式。