ComfyUI初学者指南
发布时间:2024年06月06日
ComfyUI初学者指南
ComfyUI 是一个基于节点的Stable Diffusion的 GUI。本教程适合以前没有使用过 ComfyUI 的人。我会涵盖
- 文本转图像
- 图像到图像
- SDXL 工作流程
- 修复
- 使用 LoRA
- ComfyUI Manager – 在 GUI 中管理自定义节点。
- Impact Pack – 有用的 ComfyUI 节点的集合。
什么是 ComfyUI?
ComfyUI 是一个基于节点的Stable Diffusion GUI。您可以通过将不同的块(称为节点)链接在一起来构建图像生成工作流程。
一些常用的块包括加载checkpoint、输入提示、指定采样器等。ComfyUI 将工作流程分解为可重新排列的元素,以便您可以轻松创建自己的元素。
从哪儿开始?
学习 ComfyUI 的最佳方法是通过示例。因此,我们将学习如何在 ComfyUI 中以最简单的文本到图像工作流程进行操作。
我们将介绍一些基本的工作流程示例。在学习了一些必要的内容之后,您将开始了解如何制作自己的内容。
在本教程结束时,您将有机会制作一个非常复杂的教程。将提供答案。
基本控制
使用鼠标滚轮或两指捏合来放大和缩小。
拖动并按住输入或输出的点以形成连接。只能在相同类型的输入和输出之间进行连接。
按住并左键单击拖动可在工作区中移动。
按 Ctrl-0 (Windows) 或 Cmd-0 (Mac) 显示“队列”面板。
文生图
我们首先看一下最简单的情况:从文本生成图像。
经典吧?
通过这个例子,你也会了解到ComfyUI之前的想法(它与Automatic1111 WebUI有很大不同)。作为奖励,您将更多地了解Stable Diffusion的工作原理!
在 ComfyUI 上生成您的第一张图像
第一次启动 ComfyUI 后,您应该看到默认的文本到图像工作流程。它应该看起来像这样:
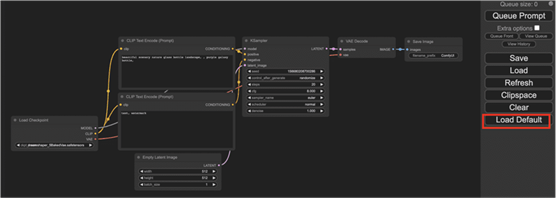
如果这不是您所看到的,请单击右侧面板上的“加载默认值”以返回此默认的文本到图像工作流程。
如果看不到右侧面板,请按 Ctrl-0 (Windows) 或 Cmd-0 (Mac)。
您将看到工作流程由两个基本构建块组成:节点和边。
节点是矩形块,例如加载检查点、剪辑文本编码器等。每个节点执行一些代码。如果您有一些编程经验,您可以将它们视为函数。每个节点需要三件事
- 输入是电线进入左侧的文本和点。
- 输出是电线右侧的文本和点。
- 参数是块中心的字段。
边是连接节点之间的输出和输入的电线。
这就是整个想法!剩下的就是细节了。
如果节点上的术语看起来令人生畏,请不要担心。我们将介绍一个使用 ComfyUI
的简单示例,介绍一些概念,然后逐渐转向更复杂的工作流程。
以下是使用 ComfyUI 的最简单方法。您应该处于默认工作流程中。
- 选择型号

暂时无法在飞书文档外展示此内容
首先,在“Load Checkpoint”节点中选择“Stable Diffusion Checkpoint”模型。单击型号名称可显示可用型号的列表。
如果节点太小,可以使用鼠标滚轮或在触摸板上用两根手指捏合来放大和缩小。
如果单击模型名称没有任何反应,则您可能尚未安装模型或将其配置为使用 A1111
中的现有模型。首先返回安装指南修复它。
- 输入提示和否定提示
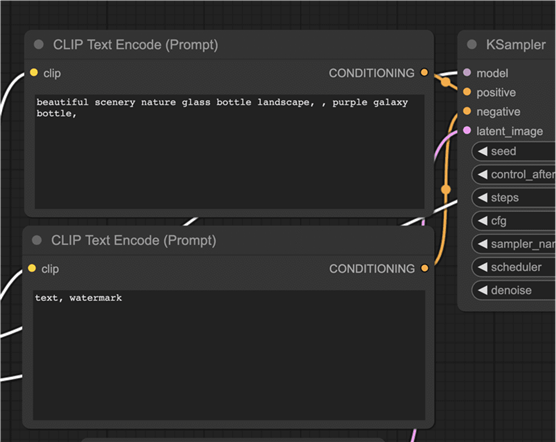
您应该看到两个标记为CLIP Text Encode (Prompt)的节点。在顶部输入您的提示,在底部输入您的否定提示。
CLIP Text Enode节点首先将提示转换为标记,然后使用文本编码器将它们编码为嵌入。
您可以使用语法(keyword:weight)来控制关键字的权重。例如(关键字:1.2)以增加其效果。(关键字:0.8)以减少其影响。
为什么最上面的是提示?查看CONDITIONING输出。它连接到KSampler 节点的正输入。最下面的一个与负极相连,所以是负极提示用的。
- 生成图像
单击队列提示运行工作流程。短暂等待后,您应该会看到生成的第一张图像。
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
刚刚发生了什么?
使用 ComfyUI 的优点是它的可配置性很强。值得了解每个节点的作用,以便您可以使用它们来满足您的需求。
如果您对理论不感兴趣,可以跳过本节的其余部分。
加载检查点节点
使用“加载检查点”节点选择模型。Stable Diffusion模型由三个主要部分组成:
- 模型:潜在空间中的噪声预测模型。
- CLIP:语言模型对正面和负面提示进行预处理。
- VAE:变分自动编码器在像素和潜在空间之间转换图像。
MODEL 输出连接到采样器,在采样器中完成反向扩散过程。
CLIP 输出连接到提示,因为提示需要经过 CLIP 模型处理才能有用。
在文本到图像中,VAE仅用于最后一步:将图像从潜在空间转换到像素空间。换句话说,我们只使用自动编码器的解码器部分。
CLIP 文本编码
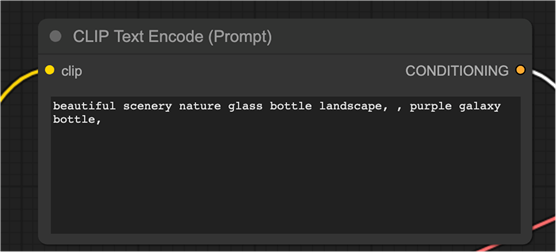
CLIP文本编码节点获取提示并将其输入 CLIP 语言模型。CLIP 是
OpenAI 的语言模型,将提示中的每个单词转换为嵌入。
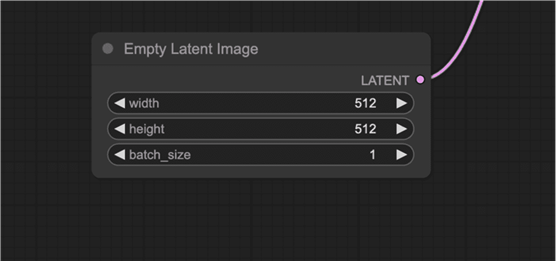
空潜像
暂时无法在飞书文档外展示此内容
文本到图像的过程从潜在空间中的随机图像开始。
潜像的大小与像素空间中的实际图像成正比。因此,如果您想更改图像的大小,请更改潜在图像的大小。
您可以设置高度和权重来更改像素空间中的图像大小。
在这里,您还可以设置批量大小,即每次运行生成的图像数量。
KS采样器
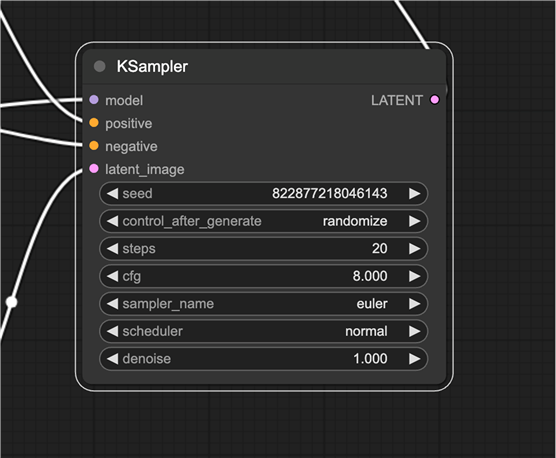
KSampler 是Stable Diffusion图像生成的核心。采样器将随机图像去噪为与您的提示相匹配的图像。
KSampler 指的是在此代码存储库中实现的采样器。
以下是 KSampler 节点中的参数。
- 种子:随机种子值控制潜在图像的初始噪声,从而控制最终图像的组成。
- Control_after_ Generation:种子在每一代之后应如何变化。它可以获取随机值(随机化)、增加 1(增量)、减少 1(减量)或不变(固定)。
- 步骤:采样步骤数。越高,数值过程中的伪影越少。
- Sampler_name:在这里,您可以设置采样算法。请阅读采样器文章以获取入门知识。
- 调度程序:控制每个步骤中噪声级别的变化方式。
- 去噪:去噪过程应消除多少初始噪声。1 表示全部。
图像到图像的工作流程
Img2img工作流程是Stable Diffusion中的另一个主要工作流程。它根据提示和输入图像生成图像。
您可以调整降噪强度来控制Stable Diffusion应遵循基础图像的程度。
将此工作流程图像拖放到 ComfyUI 中进行加载。
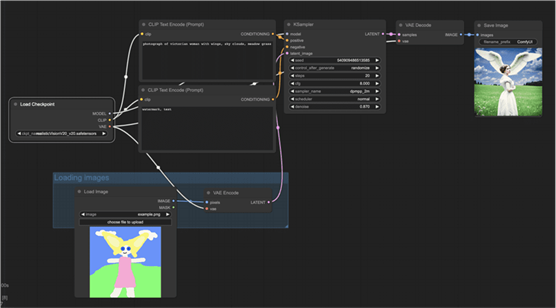
要使用此 img2img 工作流程:
- 选择检查点 模型。
- 修改正面和负面提示。
- 可以选择调整KSampler 节点中的降噪(降噪强度)。
- 按队列提示开始生成。
舒适UI管理器
ComfyUI 管理器是一个自定义节点,可让您通过 ComfyUI
界面安装和更新其他自定义节点。
安装 ComfyUI 管理器
要安装此自定义节点,请转到PowerShell (Windows) 或终端(Mac) 应用程序中的自定义节点文件夹:
cd ComfyUI/custom_nodes
并将节点克隆到本地存储。
git clone
https://github.com/ltdrdata/ComfyUI-Manager
完全重新启动 ComfyUI。
使用 ComfyUI 管理器
安装后,您应该在“队列提示”菜单上看到一个额外的“管理器”按钮。单击它会显示一个
GUI,可让您
- 安装/卸载自定义节点。
- 安装当前工作流程中缺少的节点。
- 安装检查点模型、AI upscalers、VAE、LoRA、ControlNet 模型等模型。
- 更新 ComfyUI 用户界面。
- 阅读社区手册。
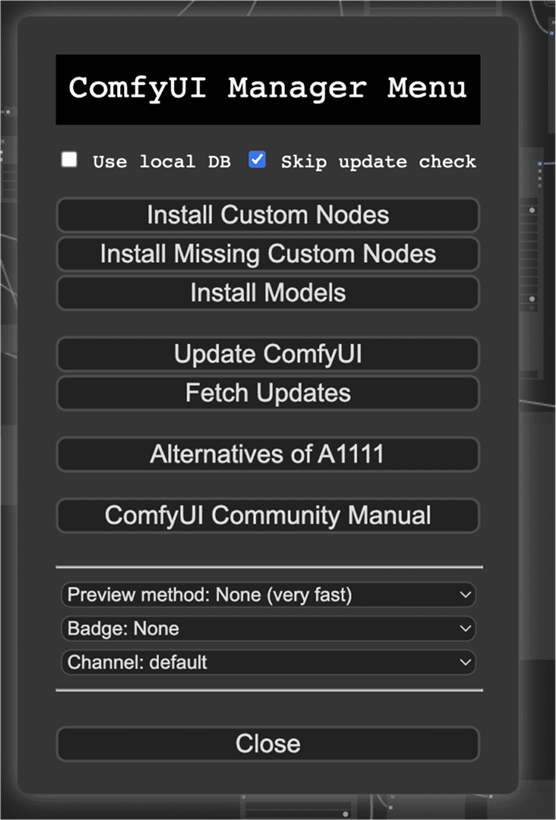
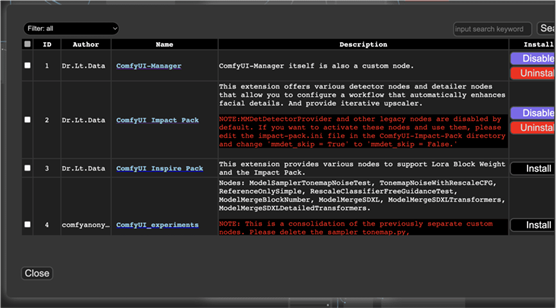
“安装缺失节点”功能对于查找当前工作流程中所需的自定义节点特别有用。
“安装自定义节点”菜单允许您管理自定义节点。您可以卸载或禁用已安装的节点或安装新节点。
暂时无法在飞书文档外展示此内容
升级
有多种方法可以在Stable Diffusion中进行升级。出于教学目的,让我们进行升级
AI高档
AI upscaler是一种用于放大图像并填充细节的 AI 模型。它们不是Stable Diffusion模型,而是经过训练以放大图像的神经网络。
首先下载页面上的图像来加载此放大工作流程。将图像拖放到 ComfyUI。
提示:拖放使用 ComfyUI 制作的图像会加载生成该图像的工作流程。
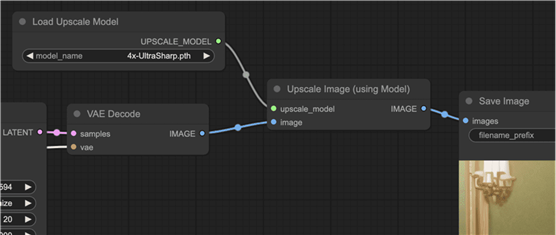
在这个基本示例中,您会看到文本到图像的唯一添加是
- 加载升级模型:用于加载 AI 升级模型。
- 高档图像(使用模型):该节点现在位于 VAE 解码器和保存图像节点之间。它采用图像和升级模型。并输出放大的图像。
要使用此
upscaler 工作流程,您必须从Upscaler Wiki下载 upscaler 模型,并将其放入文件夹models > upscale_models中。
或者,将 ComfyUI 设置为使用 AUTOMATIC1111 的模型文件。
选择一个放大器并单击“队列提示”以生成放大的图像。该图像应该已被 AI 放大器放大 4 倍。
练习:重新创建从文本到图像的 AI 放大工作流程
通过将升级器添加到默认的文本到图像工作流程来创建您的第一个自定义工作流程是一个很好的练习。
- 单击“加载默认值”返回基本的文本到图像工作流程。
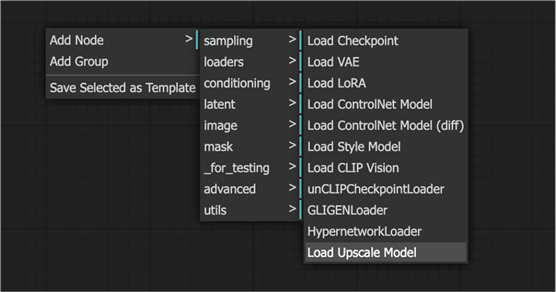
- 右键单击“保存图像”附近的空白区域。选择“添加节点”>“加载器”>“加载高档模型”。
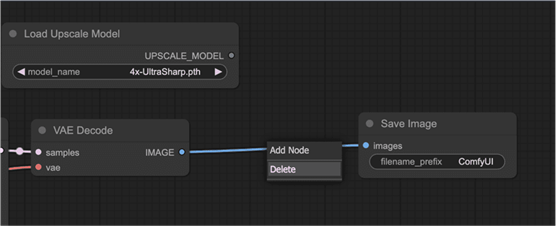
3. 单击VAE Decode和Save Image之间连线上的点。单击删除以删除连线。
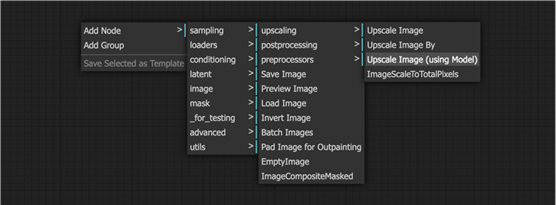
- 右键单击空白处,然后选择“添加节点”>“图像”>“放大”>“放大图像(使用模型)”以添加新节点。
- 拖动并按住Load Upscale Model的UPSCALE_MODEL输出。将其放在Upscale
Image (using Model)节点的upscale_model处。 - 拖动并按住VAE Decode的IMAGE输出。将其放在Upscale Image (using
Model)的图像输入处。
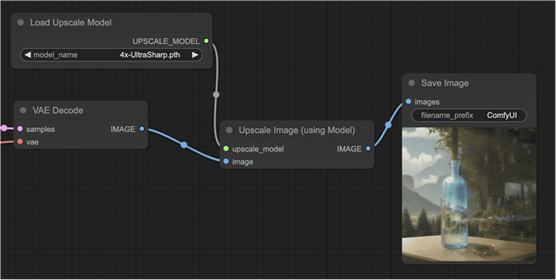
- 拖动并按住Upscale Image (uisng Model)节点的IMAGE输出。将其放在“保存图像”节点的图像输入处。
- 单击“队列提示”以测试工作流程。
现在您知道如何创建新的工作流程了。这项技能可以派上用场来创建您自己的工作流程。
高分辨率修复
下载此页面上的第一张图像并将其放入 ComfyUI 中以加载高分辨率修复工作流程。
这是一个更复杂的示例,但也向您展示了 ComfyUI 的强大功能。研究完节点和边后,您就会确切地知道什么是 Hi-Res Fix。
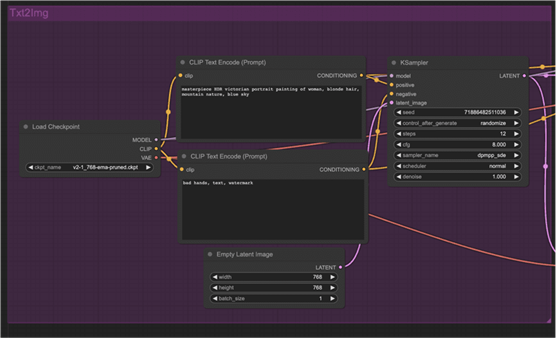
第一部分与文本到图像相同:您使用采样器对潜在图像进行去噪,并以正面和负面提示为条件。
然后,工作流程会放大潜在空间中的图像并执行一些额外的采样步骤。它给图像添加一些初始噪声,并以一定的去噪强度对其进行去噪。
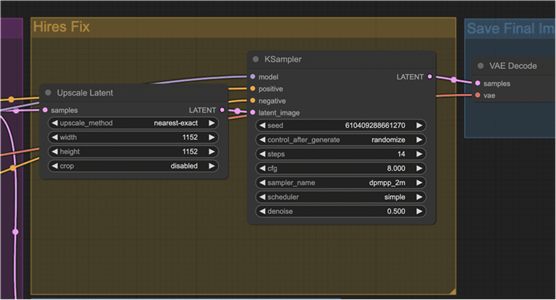
然后,VAE 解码器对较大的潜在图像进行解码以生成放大的图像。
SD Ultimate 高档 – ComfyUI 版
SD Ultimate upscale是AUTOMATIC1111 WebUI的流行升级扩展。您也可以在 ComfyUI 上使用它!
ComfyUI SD Ultimate 的
Github 页面
这也是安装自定义节点的一个很好的练习。
安装 SD Ultimate 高档节点
要安装此自定义节点,请转到PowerShell (Windows) 或终端(Mac) 应用程序中的自定义节点文件夹:
cd ComfyUI/custom_nodes
并将节点克隆到本地存储。
git clone
https://github.com/ssitu/ComfyUI_UltimateSDUpscale --recursive
完全重新启动 ComfyUI。
使用SD Ultimate高档
一个好的练习是从AI
upscaler 工作流程开始。添加 SD Ultimate
Upscale 并比较结果。
通过将图像拖放到 ComfyUI 或使用“加载”按钮加载来加载 AI
upscaler 工作流程。
右键单击空白处。选择“添加节点” > “图像” > “升级” > “Ultimate SD Upscale”。
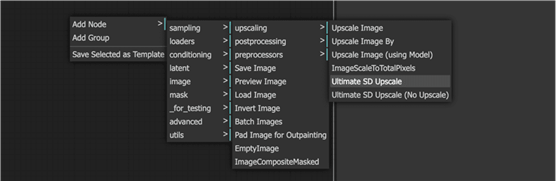
您应该会看到新节点 Ultimate SD Upscale。按如下方式连接其输入。
- 图像到 VAE 解码的图像。
- 模型加载检查点的模型。
- 积极的CONDITIONING的积极提示框。
- 否定提示框的CONDITIONING。
- vae加载检查点的 VAE。
- upscale_model加载高档模型的
UPSCALE_MODEL。
对于输出:
- IMAGE保存 Image 的图像。
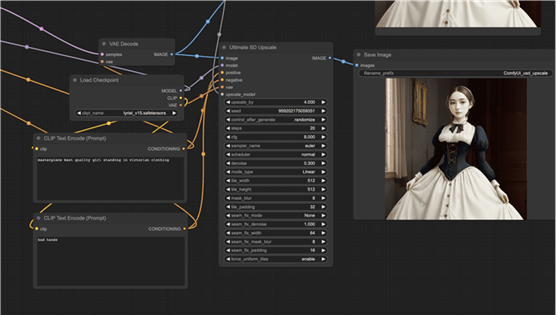
如果接线正确,单击“队列提示”应显示两张大图像,一张带有 AI upscaler,另一张带有 Ultimate Upscale。
您可以在下面下载此工作流程示例。将图像拖放到 ComfyUI 中进行加载。
ComfyUI 修复
您可以使用 ComfyUI 进行修复。重新生成图像的一部分是一项基本技术。
我不得不承认,使用 ComfyUI 进行修复并不是最简单的事情。但你来了……
第 1 步:创建修复蒙版
首先,选择要修复的图像。
刘德华准备进行修复工作。
您可以在此处下载 PNG 格式的图像。
我们将使用Photopea(一个免费的在线 Photoshop 克隆)来创建修复蒙版。蒙版需要在PNG 文件的Alpha 通道中绘制。
将 PNG 图像拖放到
Photopea。
选择橡皮擦工具(按 E)。
通过擦除图像的一部分来绘制蒙版。
将其另存为 PNG 文件。单击“文件” > “导出” > “PNG”。
第 2 步:打开修复工作流程
要使用修复,请首先下载修复工作流程。
通过拖放到 ComfyUI 中来加载修复工作流程。
第三步:上传图片
将带有蒙版的图像上传到“加载图像”节点。
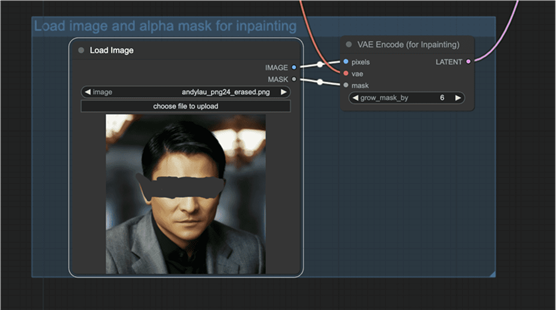
第四步:调整参数
更改提示:
x men 独眼巨人太阳镜,史诗风格,超级英雄
原始去噪强度(噪)太高。将其设置为 0.8。
第 5 步:生成修复
最后,按队列提示执行修复。
这对于一个小任务来说是一个相当大的考验……所以,我会坚持使用AUTOMATIC1111进行修复。
SDXL 工作流程
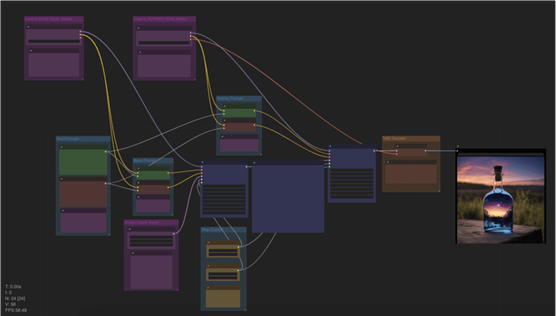
简单的 SDXL 工作流程。
由于其极高的可配置性,ComfyUI
是第一个使Stable Diffusion XL 模型发挥作用的 GUI 之一。
下载ComfyUI 的简单 SDXL 工作流程。将图像拖放到 ComfyUI 中进行加载。
你需要改变
- 积极提示
- 否定提示
就是这样!
此页面上有一些更复杂的 SDXL 工作流程。
ComfyUI 影响包
ComfyUI Impact pack是一组免费的自定义节点,可以极大地增强
ComfyUI 的功能。
Impact Pact 中的自定义节点数量超出了我在本文中所能描述的数量。看官方教程一一学习。如果您想有效地使用这组节点,请通读初学者教程。
安装
要安装 ComfyUI Impact Pack,请首先打开PowerShell应用程序 (Windows) 或终端应用程序(Mac 或 Linux)。
cd custom_nodes
将 Impact Pack 克隆到本地存储。
git clone https://github.com/ltdrdata/ComfyUI-Impact-Pack.git
克隆 Impact Pack 所需的工作流程组件。
git clone
https://github.com/ltdrdata/ComfyUI-Workflow-Component
完全重新启动 ComfyUI。
面部再生
您可以使用Impact Pack 中的此工作流程,通过Face
Detailer自定义节点以及 SDXL 基础和细化器模型重新生成面部。下载 JSON 文件并将其放入 ComfyUI 中。
要使用此工作流程,您需要设置
- Load Image节点中的初始图像。
- 上部负载检查点节点中的 SDXL 基本模型。
- 下部负载检查点节点中的 SDXL 精炼器模型。
- 新图像的提示和否定提示。
单击队列提示启动工作流程。
刘德华的脸不需要任何修饰(是吗??)。所以我利用提示把他变成了韩国流行歌星。
韩国流行音乐明星的特写照片
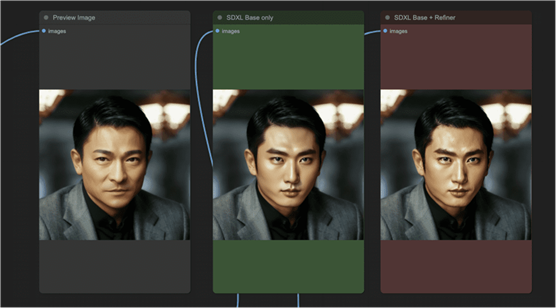
只有脸部发生变化,而背景和其他一切都保持不变。
洛拉
LoRA是一个修改检查点模型的小模型文件。它经常用于修改样式或将人物注入模型中。
其实LoRA的修改在ComfyUI中就很清楚了:
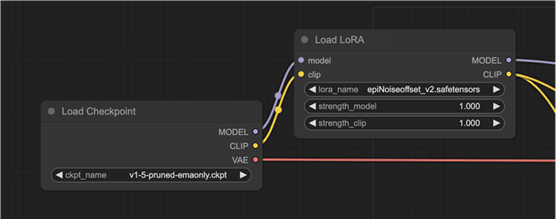
LoRA模型改变了检查点模型的MODEL和CLIP,但保持VAE不变。
简单的 LoRA 工作流程
这是最简单的 LoRA 工作流程:使用 LoRA 和检查点模型进行文本到图像。
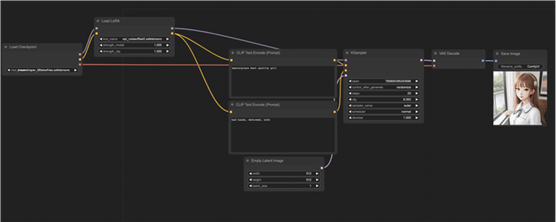
要使用工作流程:
- 选择检查点模型。
- 选择 LoRA。
- 修改提示和否定提示。
- 单击队列提示。
多个 LoRA
您可以在同一文本到图像工作流程中使用两个 LoRA。
用法与一个 LoRA 类似,但现在您必须选择两个。
两个LoRA相继应用。
练习:制作一个工作流程来比较使用和不使用
LoRA 的情况
要擅长 ComfyUI,您确实需要创建自己的工作流程。
一个很好的练习是创建一个工作流程来比较使用和不使用 LoRA 的文本到图像,同时保持其他所有内容相同。
为了实现这一点,您需要知道如何在两个节点之间共享参数。
在两个节点之间共享参数
让我们在两个 K 采样器中使用相同的种子。
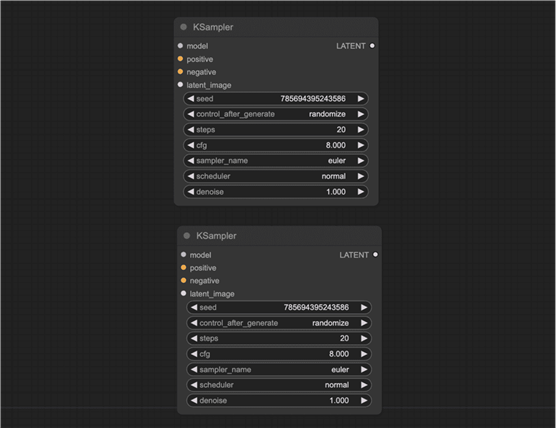
他们有自己的种子价值观。要在两者之间使用相同的种子值,请右键单击该节点并选择将种子转换为输入。
您应该获得一个名为Seed的新输入节点。
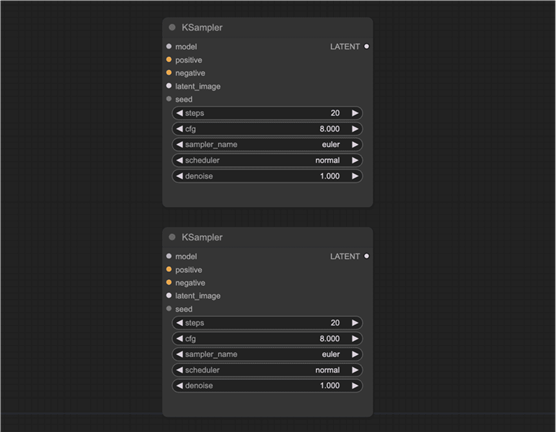
右键单击空白处。选择“添加节点” > “实用程序” > “基元”。将原始节点连接到两个种子输入。

现在,两个采样器之间共享一个种子值。
比较使用和不使用 LoRA 的图像的工作流程
仅使用此技术,您可以修改单个
LoRA示例,以创建一个工作流程来比较 LoRA 的效果,同时保持其他所有内容相同。
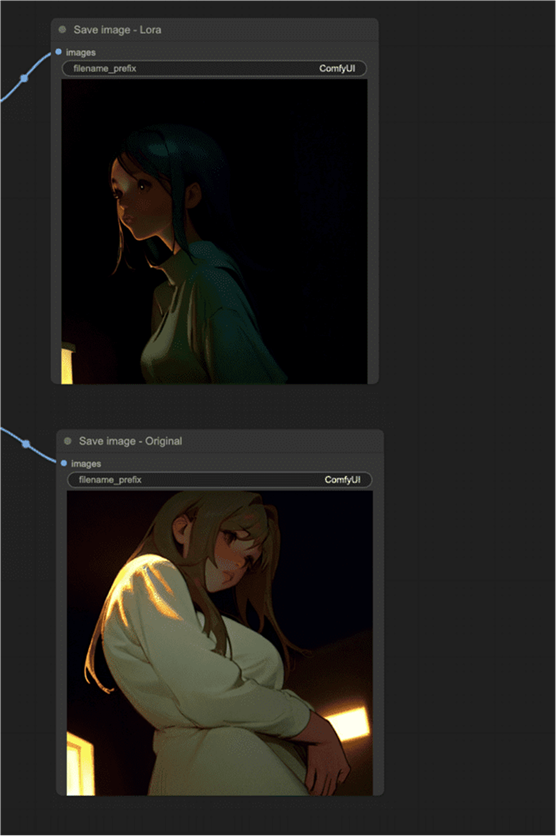
比较 Epilson 抵消 LoRA 的效果。上图:与 LoRA。底部:没有 LoRA。
暂时无法在飞书文档外展示此内容
您可以下载下面的答案。
ComfyUI_workflow_compare_with_and_without_Lora下载
推荐文章:《Best Stable Diffusion Models》,介绍了不同模型在图像生成中的应用,可以从中获得更多启发,提升对Stable Diffusion的使用体验。
爱改写(ai改写)是一款在线AI写作工具,基于NLP自然语言技术支持,为您提供中英文查词解释、释义改写、同义词识别、文本纠错、内容原创度查询一站式服务