stable diffusion如何确保每张图的面部一致?
发布时间:2024年06月06日
本文给大家分享 Stable
Diffusion 的基础能力:ControlNet
之图片提示。
这篇故事的主角是 IP-Adapter,它的全称是 Text Compatible Image
Prompt Adapter for Text-to-Image Diffusion Models,翻译成中文就是:用于文本到图像扩散模型的文本兼容图像提示适配器,名字很长很拗口,我们只要记住四个字就行了:图像提示,如果还觉得长,那就两个字:垫图。记不住也没关系,下面我会带大家一步步体会它的图片生成能力。
使用过 Stable Diffusion 的同学对提示词的重要程度应该深有体会,无论是文生图还是图生图,我们想要在图片上展现某些元素,都需要编写对应的提示词,有时候为了避免生成一些不想要的东西,我们还需要编写反向提示词。某种程度上可以说提示词就是图片的灵魂。
不过 Stable Diffusion 本身支持的提示词都是文本提示词,文本到图像的映射存在很大的不确定性。而IP-Adapter 可以一定程度上解决这个问题,它提供了一种图像提示的方法,让新生成的图片可以直接使用参考图中的某种主题元素,很多同学也称这个能力为垫图。从描述上看 IP-Adapter 的能力类似 Reference,不过它更高级,最主要的区别就是不用怎么编写提示词。百闻不如一见,先看看官方给的效果图。




IP-Adapter 是一个目前比较新的 ControlNet 类型,是由腾讯AI实验室发布的一个开源项目,项目地址:https://github.com/tencent-ailab/IP-Adapter,懂技术的同学可以去研究研究。
下面开始我们的使用之旅。
安装
ControlNet 安装
工欲善其事必先利其器,ControlNet 还是先要安装好的,已经安装好的请跳过这一步。
之前的文章已经介绍过相关安装方法,大家请点击这个链接移步过去:ControlNet 安装与基本使用方法
注意需要将 ControlNet 插件升级到 v1.1.410 这个版本,这个版本支持新的 ControlType 类型。
IP-Adapter 安装
使用 IP-Adapter 前,还需要先安装两个预处理器,三个模型。
两个预处理器:
<stable-diffusion-webui>/extensions/sd-webui-controlnet/annotator/downloads/clip_vision/clip_g.pth
<stable-diffusion-webui>/extensions/sd-webui-controlnet/annotator/downloads/clip_vision/clip_h.pth
三个模型:
<stable-diffusion-webui>/extensions/sd-webui-controlnet/models/ip-adapter_sd15.pth
<stable-diffusion-webui>/extensions/sd-webui-controlnet/models/ip-adapter_sd15_plus.pth
<stable-diffusion-webui>/extensions/sd-webui-controlnet/models/ip-adapter_xl.pth
不方便访问 huggingface 的同学可以通过我整理的资源下载,下载方式见文章最后;或者直接使用
AutoDL 上我发布的镜像:https://www.codewithgpu.com/i/AUTOMATIC1111/stable-diffusion-webui/yinghuoai-sd-webui-fast
基本使用
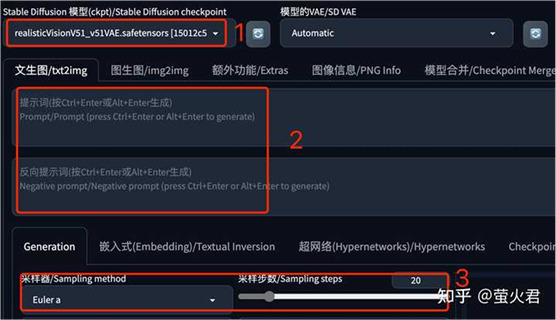
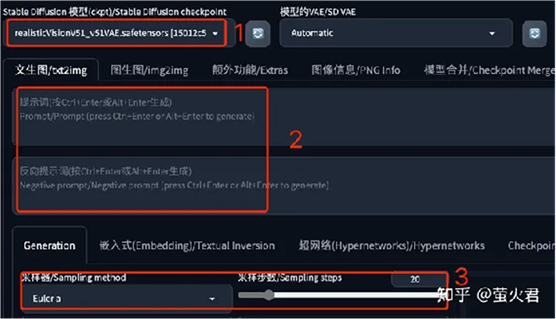
先选择一个大模型,提示词和反向提示词都不需要填写,采样器和采样部署都使用默认的就行。提示词也可以填写,会产生一些生图效果,后面会有相关介绍,这里先从最简单的开始。
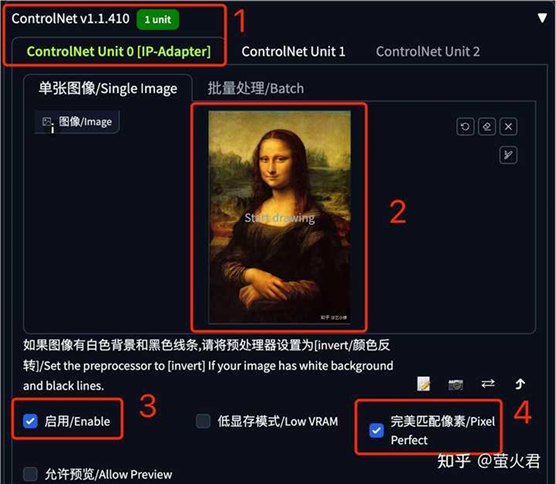
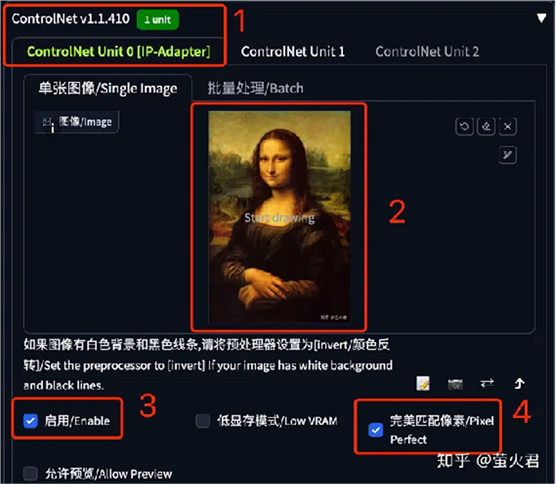
在第一个 ControlNet 单元中上传一张照片,这里以大家都熟悉的蒙娜丽莎为例,这张照片就是用来做图像提示的,别忘了勾选“启用”和“完美匹配像素”。
然后是 IP-Adapter 的几个设置:Control Type 中选中 “IP-Adapter”,预处理器和模型会自动带出,如果没有带出,请检查上一步的模型是否正确安装。
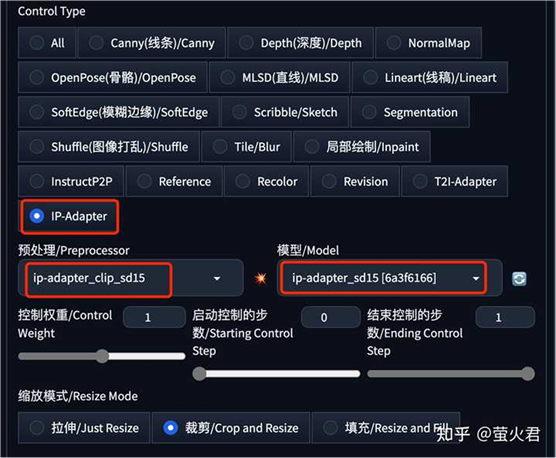
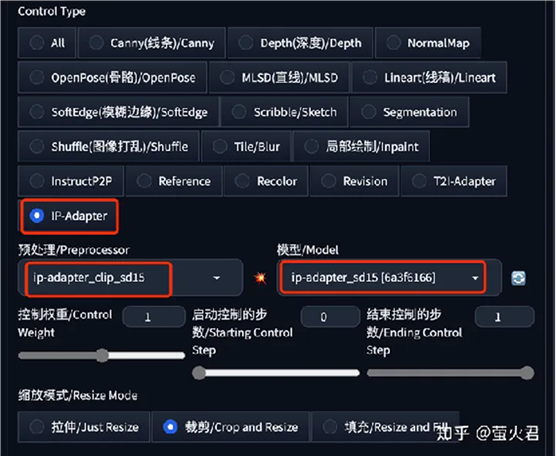
预处理器有两个:
- ip-adapter_clip_sd15:适用于 Stable Diffusion 1.5 模型。
- ip-adapter_clip_sdxl:适用于 Stable Diffusion XL 模型。
模型有三个:
- ip-adapter_sd15:适用于Stable Diffusion 1.5。
- ip-adapter_sd15_plus:适用于 Stable Diffusion 1.5,更细粒度的提示,生成图片和原画更接近。
- ip-adapter_xl:适用于 Stable Diffusion XL。
然后点击生成就可以了,我这里对你了几个模型,大家看看效果。


主体的长相、表情、发型、衣着、姿态和参考图都挺像的,背景也基本都是相同的内容,只是不同的大模型也会有大模型各自的特色。
到这里大家应该能感受到 IP-Adapter 的图像提示能力了。
用途演示
更换主体的形态
这种方法是将图像提示应用到某个新的结构中,这需要再增加一个Control Type 用于控制图片的结构。
这个演示在文生图中进行,还是不需要填写任何提示词,第一个 ControlNet 单元选择 IP-Adpater,用作新生成图片的提示。
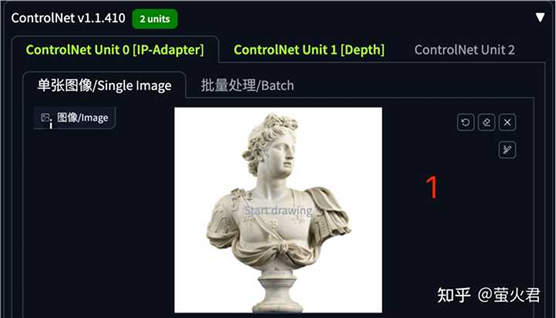
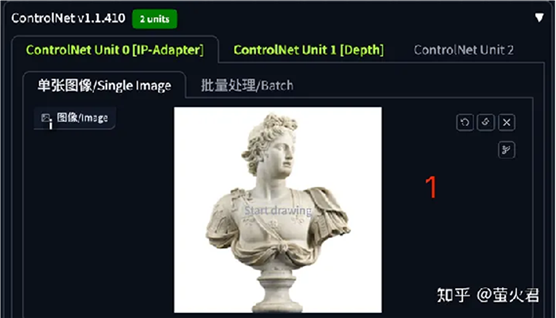
第二个 ControlNet 单元是 Depth,他将从图片中提取深度信息,用于控制图片的结构。

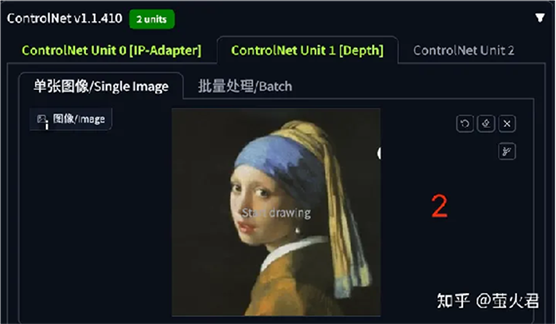
生成图片的效果如下:


除了 Depth,我们也可以使用 Canny、Lineart、SoftEdge、OpenPose 等来控制图片中的元素结构。
这里给出一个使用 IP-Adapter +
OpenPose 的出图效果,人物的外形来源于参考图,姿势是 OpenPose 控制的。有了这个我们就可以在保持小姐姐外形不变的情况下,灵活的摆出各种姿势了,这对于绘本故事、小说推文一类的比较有意义。


替换主体到目标图中
在图生图页面中,选择“局部绘制”,上传一张图片,我们要把她的面部替换掉,这里用局部绘制自带的涂抹工具把脸涂上。
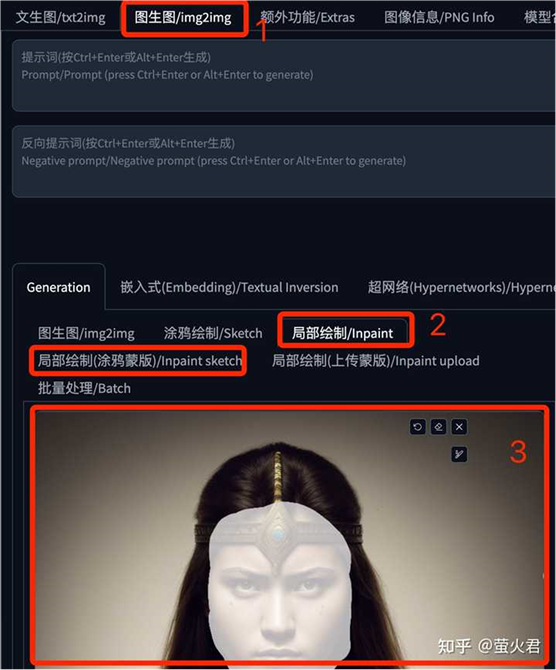
ControlNet 单元这里还是要启用 IP-Adapter,上传一张要换脸的参考图。

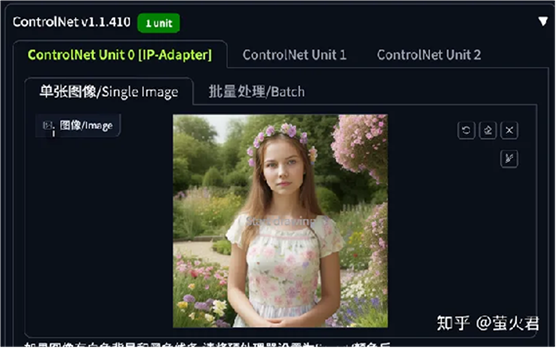
最终处理效果:


改变画面元素
这里需要使用 文本提示+图像提示 一起发挥作用。看下面这个例子,在图生图中,给图片人物增加一顶帽子,同时背景设置为海滩。
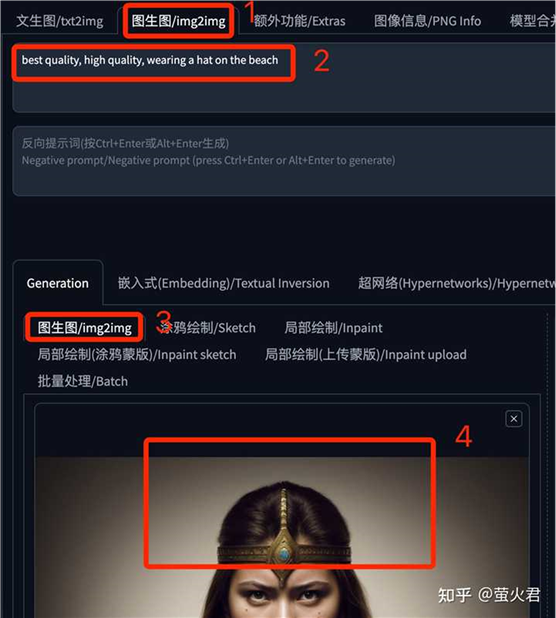
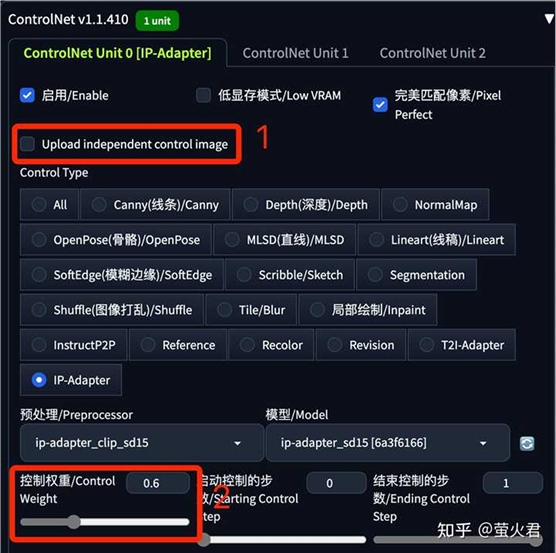
ControlNet 单元中不需要再设置参考图,因为我们要修改的就是当前要图生图的图片,另外下边这个控制权重可以根据实际需要调整下,这里需要调整的小一些,问题提示词的作用才更明显。
看效果:


融合主体到画面中
这里以著名的坤图为例。还是在图生图中,这里不需要提示词,上传一张要融合到图像提示生成画面的图片。
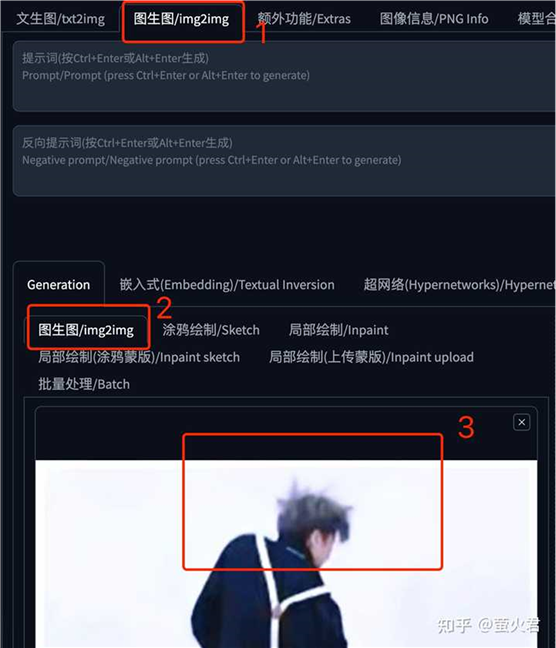
注意重绘强度,太低了,人物融合不到图片中,太高了画面中看不出来人物的形态,根据经验,从 0.55 开始比较方便调整。


ControlNet 这里上传一张参考图,新生成的图片要按照它的提示进行处理。
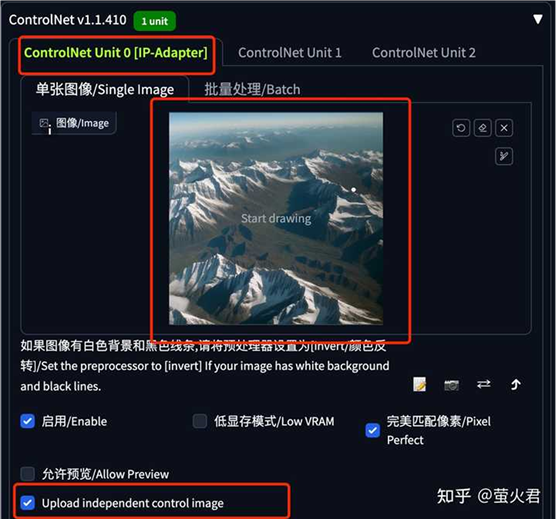
看一下生成效果:


再看这张戴珍珠耳环的少女:


出自:https://www.zhihu.com/question/592715753/answer/3215647789
PhotoEditor.ai 是一款可以快速从图片中移除不想要的对象、文字或人物的AI 图片编辑工具,高效易用。