大模型微调应用实践,没那么简单,看看曾经踩过的坑
发布时间:2024年06月06日
随着各大模型开源免费商用,应该会有更多的企业参与到大模型的微调应用,也许会碰到各种问题。刚好近期对大模型实践方面踩过的坑进行了总结,分享出来,希望可以给同行些参考,加快大家迭代的速度,如对您有一定的帮助,那就更好了。
一、大模型训练稳定性方面
单机训练不起来,环境配置问题:
GPU的CUDA驱动需和深度学习框架版本拉齐,否则模型跑不起来如GPU的CUDA verison是11.4,那就选择pytorch的版本为1.12.1。
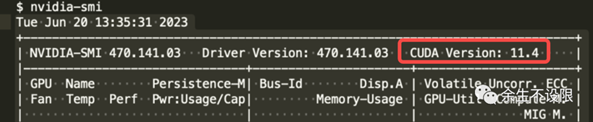
多机训练不通,DeepSPeed配置问题:
多机间NCCL 不能打通解决方法:新建 .deepspeed_env 文件,写入如下内容NCCL_IB_DISABLE=1NCCL_DEBUG=INFONCCL_SOCKET_IFNAME=eth0NCCL_P2P_DISABLE=1
多机训练效率不如单机:
多机训练可以跑起来,但是在多机上模型训练的速度比单机上还慢。
通过查看服务器相关监控,发现是网络带宽打满,上不去了,其他系统监控基本正常。原理初始的多机之间的网络带宽是64Gps,后面把多机之间的网络带宽调整为800Gps,问题解决。
实验验证,多机训练的效率,和使用的机器数成线性关系,每台机器的配置一样,如一台GPU机器跑一个epoch需要2小时,4台GPU机器跑一个epoch需要半小时。除了训练速度符合需求,多机训练模型的loss下降趋势和单机模型训练的趋势基本一致,也符合预期。
样本量规模增大,训练出现OOM错:
模型训练的样本数量从10万,增大300万,训练任务直接报OOM了。
解决方案,对数据并行处理,具体实现参考海量数据高效训练,核心思想自定义数据集本次的主要目标是使向量化耗时随着处理进程的增加线性下降,训练时数据的内存占用只和数据分段大小有关,可以根据数据特点,灵活配置化。核心功能分为以下几点:
均分完整数据集到所有进程(总的GPU卡数)
每个epoch训练时整体数据分片shuffle一次,在每个进程同一时间只加载单个分段大小数据集
重新训练时可以直接加载向量化后的数据。
训练过程,报找不主机:
解决方法,deepspeed的关联的多机的配置文件,Hostfile 配置中使用ip,不使用hostname。
训练加速:
可采用deepspeed进行训练加速,目前行业开源的大模型很多都是采用的基于deepspeed框架加速来进行模型训练的。如何进行deepspeed训练,可以参考基于deepspeed构建大模型分布式训练平台。
deepspeed在深度学习模型软件体系架构中所处的位置:
DL model—>train opitimization(deepspeed)—>train framework —> train instruction (cloud)—>GPU
device
当然需要对比验证deepspeed 的不同参数,选择合适的参数。分别对比stage 2,3进行验证,在GPU显存够的情况下,最终使用stage 2。
推理速度验证:
大模型的推理性能和输出答案的字数相关,大概是输出100字答案需要1秒。具体细节参考大模型推理性能评测。
结论:A100的推理耗时约是V100推理耗时的60%,A800和A100基本相近。
二、大模型训练效果方面
样本优化:
·对于输入历史对话数据进行左截断,保留最新的对话记录。
·去掉样本中明显的语气词,如嗯嗯,啊啊之类的。
·去掉样本中不合适的内容,如AI直卖,就不应出现转人工的对话内容。
·样本中扩充用户特征标签,如年龄,性别,地域,人群等
模型参数迭代实验:
验证历史对话轮次是否越长越好,通过训练两个模型,控制变量max_source_length|max_target_length,对训练好之后的模型从Loss、Bleu指标、离线人工评估等角度进行对比分析。
结论:从人工评估少量样本以及loss下降来看,历史对话长度1024比512长度好,后续如果训练可能上线模型,可以扩大到1024长度。
三、大模型应用方面
大模型输出合规化:
根据用户的输入问题内容,大模型进行生成回答的内容,但是生成的回答,不直接对外输出给用户。需要进行合规的处理,因为大模型的输出内容不可控,对于严肃的场景,以免引起用户的投诉。所以需要进合并处理。
目前处理的方法,模型生成内容,再把这些内容生成向量,再查询话术向量库,得到最相似的话术。如果查询结果或相似得分比较阈值低或者查询不到结果,则走兜底策略。兜底策略按用户所在的对话阶段,实验不同的兜底话术。或者使用万能兜底话术。
应用模式变更:
机器人销售场景的case:
纯大模型AI模式,最初直接是大模型机器人直接和用户对话,全流程都是大模型对话走流程。
对比之前的AI(小模型意图、话术策略)+人工模式,发现之前的初始阶段通过率高些,初步判断可能是用户说的太发散,大模型不好收敛。
就调整为AI+大模型AI模式。这样前面的AI主要是小模型意图、话术策略模式,任务引导更明确。大模型可以更好的和有意向的用户进行交互,更容易引导用户成单。
四、大模型训练平台建设方面
资源管理:
开始是命令行训练模式,算法人员多了,对GPU资源的使用有点混乱了。
切换到可视化web交互模式,建立统一的可视化pipeline配置训练任务。
统一GPU资源管理,资源分配,资源回收,资源监控。
大模型训练平台架构:
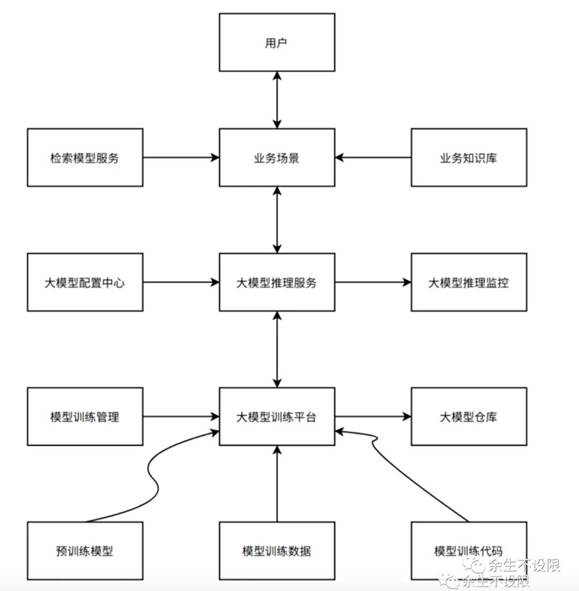
大模型平台的建设的细节参考大模型平台的建设文章。
大模型训练pipleline流程:
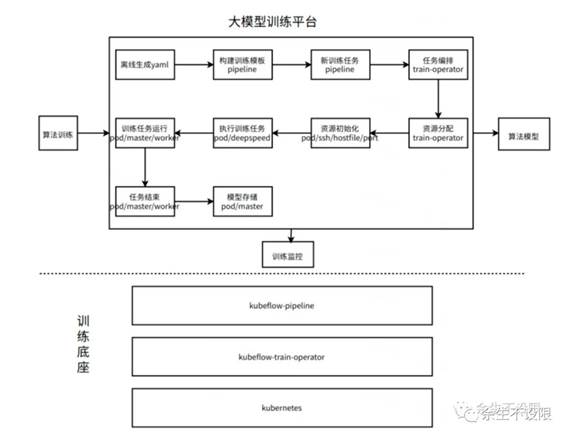
大模型训练pipleline的实现细节可参考基于kubeflow流水线构建大模型训练平台实践
总之,随着各大模型开源免费商用,更多的企业会加大对大模型应用的投入,大模型的应用发展也会更加繁荣。虽然本文提到了一些大模型应用实践中踩过的一些坑,后面应该会有更多的坑需要去踩,踩的坑多了,说明大模型的应用就更加成熟了,持续关注大模型的发展和应用实践。
出自:https://mp.weixin.qq.com/s/pdhOWBb9G0UFCZFxe3K0iQ
小库AI云,一站式泛建筑AIGC创享平台。集设计分享于一体的建筑共创社区。