各个语种互相翻译:Meta推出NLLB-200 AI模型,可实现200种语言互译
发布时间:2024年06月06日
开源地址:GitHub - facebookresearch/fairseq at nllb
https://github.com/facebookresearch/fairseq/tree/nllb
这个翻译模型,不仅支持200+语言之间任意两两互译,还是开源的。
Meta AI在发布开源大型预训练模型OPT之后,再次发布最新成果NLLB。
NLLB的全称为No Language Left Behind,如果套用某著名电影,可以翻译成“一个语言都不能少”。

这其中,中文分为简体繁体和粤语三种,而除了中英法日语等常用语种外,还包括了许多小众语言。
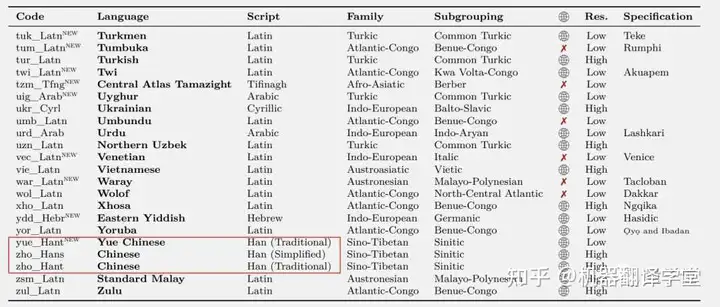
由于这些语言之间都可以两两互译,所以咱们能用NLLB把阿斯图里亚语、卢甘达语、乌尔都语等地球上的小众语言直接译成中文了。
一位用粤语的靓仔看到这里直接喜大普奔。
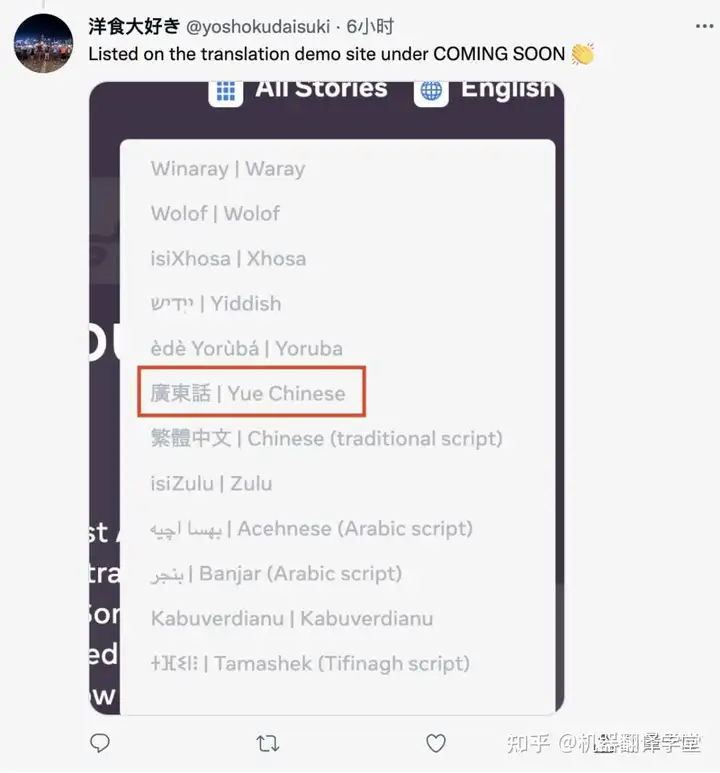
要知道,此前的众多语言模型,要么不支持这么多种语言,要么不能直接完成小众语言之间的两两翻译。
有了NLLB,世界各地的人都有机会以自己的母语访问和分享网络内容;并且无论他们的语言偏好如何,都可以与他人在任意地方沟通。
Meta称,他们计划先将这个技术应用于Facebook和Instagram,以提升这些平台上小众语言的计算机翻译水平。
同时,这也是他们元宇宙计划的一部分。
据了解,NLLB-200 AI模型不仅将应用于Meta旗下的Facebook、Instagram平台,Meta更是宣布对外开源NLLB-200 AI模型,并向非营利机构提供20万美元补助金,借此推广NLLB-200 AI模型的实际应用。
官方对外宣称,这是全球第一个以单一模型对应多数语言翻译的设计,希望借此能够帮助更多人在社群平台上进行跨语言互动,同时,也能提高未来元宇宙中的互动体验。客观来看,语言是不同文化之间交流的最大壁垒,如今,借助AI技术的帮助,这一壁垒有望被有效地打破。
Facebook 利用反向翻译对低资源语言的数据进行了补充,这种方法包括用一种语言培训模型,并利用它翻译单语数据,以便用另一种语言创建合成的反向翻译数据。例如,如果目标是培训一个中文到法文的翻译模型,Facebook 的研究人员将培训一个法文到中文的模型,并将所有单语法文数据翻译成中文。在 M2M-100 的开发过程中,Facebook 将合成数据添加到语言挖掘中,并为以前未见的语言对创建数据。
M2M-100 基于 XLM-R,Facebook 的多语言模型,可以从一种语言的数据中学习,并用 100 种语言执行任务。
今年 7 月,Facebook 发布了一个支持 51 种不同语言的语音识别模型。最近,该公司详细介绍了 CRISS 系统,该系统从许多不同语言中挖掘未标记的数据,从而跨语言挖掘句子,并训练出优秀的模型。
巴黎 Facebook 人工智能研究中心的数据科学家 Angela Fan 在一篇博文中写道:“多年来,人工智能研究人员一直致力于建立一个单一、通用的模型,能够在不同的任务中理解所有语言。一个支持所有语言、方言和模式的单一模式将有助于我们更好地为更多的人服务,保持最新的翻译,并为数十亿人平等地创造新的体验。”
对于 M2M-100,Facebook 的研究人员采用了新颖的语言识别技术,从一系列来源中挖掘表面上质量更高的数据。一是语言不可知的句子表示(LASER),二是开放源码的工具包,它执行自然语言处理模型的零发射传输。另外两个是 CCMatrix,一个用于培训翻译模型的“十亿规模”双语数据集,以及 ccaleign,一个跨语言 web 文档对的大型集合。

多语言翻译可处理模型从未见过的语言
多语言机器翻译的目标是建立一个可以在世界上 7000 多种语言之间进行一对一翻译的模型,在相似的语言之间共享信息,这有益于资源匮乏的语言对,并可以将其翻译为该模型从未见过的语言。
想得到能力更强的翻译模型就需要更大的数据集训练,但这些数据集创建起来非常费力,所以一些研究人员会将重点放在英语数据集和建模技术上。例如,支持 100 种语言将需要 1000 亿个句子对,但是数据和建模方面的这种偏向并不能反映人们如何使用翻译,并且会导致非英语翻译的性能下降。
相比之下,Facebook 的 M2M-100 在包含 100 种不同语言的超过 75 亿个句子的数据集上进行了训练。为了构建它,Facebook 研究人员确定了三个标准来指导他们的语言选择,包括来自不同家族的语言,这些语言具有地域多样性,并被广泛使用。
然后他们把范围缩小到那些有评估数据的项目,以便更容易量化模型的性能。最后,在剩下的种语言中,他们排除了那些无法获得单语数据的语言。
语言分类得到大量数据集
Facebook 的研究人员避免了那些在统计学上很少需要翻译的对子,比如冰岛语、尼泊尔语、僧伽罗语和爪哇语。研究人员还引入了一种新的“桥梁挖掘策略”,根据分类、地理位置和文化相似性将语言分为14个类别。
生活在同一个语言群体中的国家的人们会更经常地交流,并从高质量的翻译中受益。例如,一个印度家庭可能包括一系列在印度使用的语言,如孟加拉语、印度语、马拉地语、尼泊尔语、泰米尔语和乌尔都语。
为了将不同家族的语言联系起来,Facebook 的研究人员确定了一小部分“桥梁语言” ,即每个家族中的一到三种主要语言。例如,印度语、孟加拉语和泰米尔语在数据集中成为了印度-雅利安语支的桥接语言。
然后,他们从这些桥接语言的所有可能组合中挖掘训练数据,得到了前面提到的 75 亿句数据。
Facebook表示,M2M-100 已经在其新闻源上平均每天处理200亿次翻译,并希望新系统能够提供更好的结果。
开源人工智能软件的创建是为了帮助庞大的社交网络以不同的语言更好地向全球用户提供内容服务。Facebook 的新翻译模型不需要依赖英语作为中间的翻译步骤,可以更好地保留语义。
UniDream,输入文字或者上传图片即可快速生成由你创造的专属AI绘画作品,多种绘画风格包含动漫、3D、真人摄影等多领域大模型随你挑选。