万字长文-大语言模型指令调优综述
发布时间:2024年06月06日
写在前面
大模型纵横的时代,不仅大模型越来越卷,就连大模型相关综述也是越来越卷。今天给大家带来一篇大语言模型指令调优最新综述,全名为《Instruction Tuning for Large Language Models: A Survey》,来自知乎@龟壳,刘聪整理。
Paper: https://arxiv.org/pdf/2308.10792.pdf知乎:https://zhuanlan.zhihu.com/p/656733177
指令调优(Instrunction Tuning, IT)是提高大型语言模型的能力和可控性的关键技术。该综述主要介绍了IT的一般方法论、IT数据集的构建、IT模型的训练、不同模式、领域和应用的应用,以及对影响IT结果的方面的分析(例如,生成指令输出、指令集的大小等等),还回顾了IT的潜在缺陷以及对它的批评,指出了现有策略的不足,并提出了一些有成果的研究途径。
长文警告!建议收藏后慢慢阅读!!
1.
简介
近年来,大型语言模型(LLMs)研究取得了显著进展,LLMs的一个主要问题是训练目标和用户目标之间的不匹配:LLMs通常是在大型语料库上进行语境词预测使得误差最小化的训练,而用户则希望模型“有用且安全地”遵循他们的指示。为了解决这一问题,提出了指令调优技术,这是一种提高大型语言模型的能力和可
控 性 的 有 效 技 术 。它 涉 及 到 使 用(Instruction, output)对LLMs进行进一步的训练,其中Instruction表示针对模型的人工指令,而output 表示指令对应的期望输出。IT的好处有三方面:(1)在指令数据集上对LLMs进行微调,弥补了 LLMs预测下一个单词目标与用户遵循指令目标之间的差距;(2)与标准 LLMs相比,IT 允许更可控和可预测的模型行为。指令的作用是约束模型的输出,使其符合预期的响应特征或领域知识,为人类干预模型的行为提供一个通道;(3) IT 具有计算效率,可以帮助 LLMs快速适应特定领域,而无需大量的再训练或架构更改。
尽管它的有效性,IT也带来很多挑战:(1)制作高质量的指令,适当地覆盖预期的目标行为是不简单的:现有的指令数据集通常在数量、多样性和创造性上是有限的;(2)越来越多的人担心,IT只会在 IT 训练数据集大量支持的任务上得到改善;(3) IT 只能捕捉表面的模式和风格而不是理解和学习任务,这一直是一个强烈的批评。提高指令依从性和处理意料之外的模型响应仍然是开放性的研究问题。这些挑战突出了在这一领域进一步调查、分析和总结的重要性,以优化微调过程,更好地理解指令微调LLMs的行为。
2.研究方法
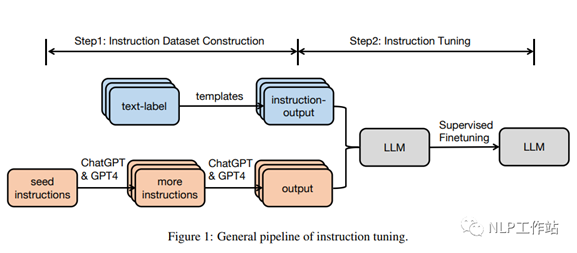
2.1 指令数据集构建
指令数据集中的每个实例由三个元素组成:一条指令,它是一个指定任务的自然语言文本序列(例如,为XX写一封感谢信给 XX,写一篇关于 XX主题的博客,等等); 一个为上下文提供补充信息的可选输入,以及基于指令和输入的预期输出。
通常有两种构造指令数据集的方法:
o从带注释的自然语言数据集集成数据。在这种方法中,通过使用模板将文本标签对转换为(指令、输出)对。
o使用LLMs 生成输出:给定指令,使用
LLMs ,如 GPT-3.5-Turbo 或GPT4,快速生成输出。指令有两种来源:(1)手工收集; (2)使用 llm扩展一个手写的小种子指令。接下来,将收集到的指令发送给 llm以获得输出。
2.2 指令调优
基于收集到的 IT 数据集,一个预先训练的模型可以直接以全监督的方式进行 fine-tuned,在给定指令和输入的情况下,通过预测输出中的每个token来训练模型。
3.
数据集
3.1 Natural Instructions
自然指令是一个人工制作的英语指令数据集,包含了来自 61 个不同的NLP 任务的193K个实例。数据集由“指令”和“实例”组成。“指令”中的每个实例都是一个任务描述,由 7个部分组成:标题、定义、要避免的事情、强调/警告、提示、正面例子和负面例子。图2中的子图(a)给出了一个“指令”的例子。“实例”由(“输入”、“输出”)对组成,它们是正确地遵循给定指令的输入数据和文本结果。图2中的子图(b)给出了实例的一个例子。

3.2 P3
P3 (Public Pool of Prompts)是一个由170 个英语NLP 数据集和 2052
个英语提示构建的指令微调数据集。提示符有时被称为任务模板,是将传统NLP任务(例如,问题回答、文本分类)中的数据实例映射到自然语言输入-输出对的函数。
P3 中 的 每 个 实 例 都 有 三 个 组件:“inputs”、“answer_choices”和“targets”。“输入”是一个用自然语言描述任务的文本序列(例如,“如果他喜欢玛丽是真的,那么他喜欢玛丽的猫也是真的吗?”)。“答案选择”是一个文本字符串列表,对给定的任务(例如,["yes", "no", "undetermined"])适用的响应。“Targets”是一个文本字符串,它是对给定“输入”(例如“yes”)的正确响应。作者构建了
PromptSource,这是一个用于协作创建高质量提示词的工具,也是一个用于开源高质量提示的存档。P3 数据集是通过从 PromptSource 中的多个提示符中随机抽样一个提示符来构建的,并将每个实例映射为(“输入”、“答案选择”、“目标”)三元组。
3.3 xP3
xP3(跨语言公共提示池)是一个多语言指令数据集,由 46 种语言的 16 种不同的自然语言任务组成。数据集中的每个实例都有两个组件:“输入”和“目标”。“输入”是一种自然语言的任务描述。“Targets”是正确地遵循“inputs”指令的文本结果。
xP3 中的原始数据有三个来源:英语指令数据集P3、P3 中的 4 个英语隐性任务(如翻译、程序合成 ) 和 30 个多语言 NLP 数据集。作者通过从PromptSource 抽取人工编写的任务模板,然后填充模板来将不同的NLP任务转换成统一的形式化,从而构建了 xP3 数据集。例如,自然语言推理任务的任务模板如下:“如果前提为真,那么假设也为真吗?”;“是”、“可能”、“否”相对于原来的任务标签“蕴涵(0)”、“中立(1)”和“矛盾(2)”。
3.4 Flan 2021
Flan 2021是一个由 62 个广泛使用的NLP基准(如 SST-2、SNLI、AG News、MultiRC)转换成语言输入-输出对而构建的英语指令数据集。Flan 2021 中的每个实例都有“输入”和“目标”组件。“输入”是一个文本序列,通过自然语言指令来描述一个任务(例如,“确定句子‘他喜欢猫’的情感。积极还是消极?”)。“目标”是正确执行“输入”指令的文本结果(例如,“积极”)。将传统的自然语言处理数据集转换为输入-目标对:步骤 1:人工编写指令和目标模板;步骤 2:用数据集中的数据实例填充模板。
3.5 Unnatural Instructions
非自然指令是一个有大约 24 万个实例的指令集,使用 InstructGPT (text-
davinci-002)构建。数据集中的每个实例有四个组件:指令、输入、约束和输出。“指令”是用自然语言对教学任务的描述。输入在自然语言中是一个参数,用于实例化指令任务。约束是对任务输出空间的限制。输出是一个文本序列,它在给定输入参数和约束条件的情况下正确地执行指令。作者首先从人工构建的超自然指令数据集中采样种子指令。然后,他们提InstructGPT引出一个新的(指令、输入、约束)对,其中包含三个种子指令作为示范。接下来,作者通过随机改写指令或输入来扩展数据集。指令、输入和约束的连接被送入 InstructGPT以获得输出。
3.6 Self-Instruct
Self-Instruct (Wang et al. , 2022c) 是使用InstructGPT构建的英语教学数据集,包含52K个训练指示和252个评价指示。每个数据实例由“指令”、“输入”和“输出”组成。“指令”是自然语言中的任务定义(例如,“请回答以下问题”)。“Input”是可选的,用作说明的补充内容(例如,“哪个国家的首都是北京?”),“output”是符合说明的文本结果(例如,“北京”)。根据以下步骤生成完整数据集:
o步骤1:作者从 175个种子任务中随机抽取 8 条自然语言指令作为示例,并提示InstructGPT生成更多的任务指令。
o步骤2:作者确定步骤1中生成的指令是否是一个分类任务。如果是,他们要求 InstructGPT 根据给定的指令为输出生成所有可能的选项,并随机选择特定的输出类别,提示 InstructGPT 生成相应的“输入”内容。对于不属于分类任务的指令,应该有无数的“输出”选项。作者提出了“输入优先”策略,首先提示 InstructGPT根据给定的“指令”生成“输入”,然后根据“指令”和生成的“输入”生成“输出”。
o步骤3:基于第 2 步的结果,作者使用 InstructGPT 生成相应指令任务的“输入”和“输出”,采用“输出优先”或“输入优先”的策略。
o步骤4:作者对生成的指令任务进行了后处理(例如,过滤类似指令,去除输入输出的重复数据),最终得到52K条英文指令。
3.7 Evol-Instruct
Evol-Instruct是由 52K 指令的训练集和218条指令的评价集组成的英语指令数据集。作者促使ChatGPT (OpenAI, 2022)使用深度和吸气式进化策略重写指令。深度演化策略包含了增加约束、增加推理步骤、增加输入复杂度等五种操作类型。吸气进化策略将简单指令升级或直接升级为复杂指令生成一个新的指令来增加多样性。作者首先使用 52K(指令、响应)对作为初始集合。然后,他们随机抽取一种进化策略,并要求ChatGPT根据选择的进化策略重写最初的指令。利用 ChatGPT和规则过滤掉非进化指令对,用新生成的进化指令对更新数据集。重复上述过程 4 次后,作者收集了250K条指令对。除了训练集,作者还从真实的场景(例如,开源项目、平台和论坛)中收集了
218 条人类生成的指令,称为Evol-Instruct测试集。
3.8 LIMA
LIMA 是一个英语指令数据集,由一个拥有1K实例的训练集和300 个实例的测试集组成。训练集包含 1K 对(“指令”、“响应”)。对于训练数据,75%的样本来自三个社区问答网站(即Stack Exchange、wikiHow和PushshiftReddit 数据集(Baumgartner et al., 2020),20%是由一组作者在他们的兴趣启发下手工编写的,5%的样本来自超自然指令数据集(Wang 等人,2022d)。对于验证集,作者从A组作者编写的集合中抽样 50个实例。测试集包含 300 个示例,其中 76.7%由另一组(B 组)作者编写, 23.3% 的样本来自 Pushshift Reddit 数据集,这是Reddit社区内的问题和答案的集合。
3.9 Super-Natural Instructions
超自然指令(Wang et al., 2022f)是一个多语言指令集合,由 1,616 个NLP 任务和 5M任务实例组成,涵盖76种不同的任务类型(例如,文本分类、信息提取、文本重写、文本创作等)和55种语言。数据集中的每个任务都由一个“指令”和“任务实例”组成,具体来说,“指令”有3部分组成:用自然语言描述任务的“定义”;正面例子,即正确输出的样本,并对每个样本进行简短的解释;以及“负例子”,即输入和不期望输出的样本,以及对每个样本的简短解释,如图 3 (a)所示。“任务实例”是由文本输入和可接受文本输出列表组成的数据实例,如图 3 (b)所示。《超自然指令》中的原始数据来自三个来源:(1)现有的公共NLP数据集(如CommonsenseQA);(2)通过众包过程生成的适用中间标注(例如,在众包QA数据集中对给定问题进行释义);(3)合成任务,由符号任务转化而来,用几句话来表达(如数字比较等代数运算)。

3.10 Dolly
Dolly是一个英语指令数据集,包含 15000个人类生成的数据例,旨在使 LLMs能够与用户进行类似ChatGPT 的交互。该数据集旨在模拟广泛的人类行为,包括 7 种特定类型:开放问答、封闭问答、从维基百科中提取信息、从维基百科中总结信息、头脑风暴、分类和创造性写作。数据集中每种任务类型的示例如表2所示。

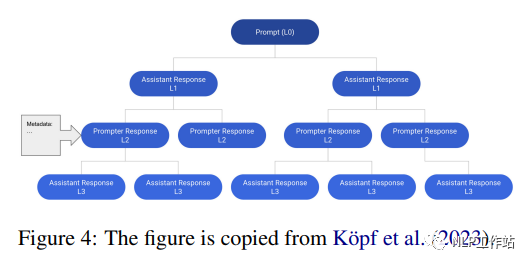
3.11 OpenAssistant Conversations
OpenAssistant Conversations是一个人工构建的多语言助理风格的会话语料库,由来自35种语言的66497 个会话树的161,443
条消息(即 91,829个用户提示,69,614个助理回复)组成,以及461292
个人工标注的质量评级。数据集中的每个实例都是一个会话树(conversation tree,CT)。具体来说,会话树中的每个节点表示会话中角色(即提示符、助手)生成的消息。CT 的根节点表示来自提示器的初始提示,而其他节点表示来自提示器或助手的回复。从根到CT中任何节点的路径表示提示符和助手之间依次进行的有效对话,称为线程。图 4 显示了会话树的示例,其中包含
6个线程中的12条消息。作者首先收集了基于五步流程的对话树:
o步骤1:提示:贡献者充当提示符,精心制作初始提示;
o步骤2:标签提示:参与者从第一步开始对初始提示进行评分,作者选择高质量的提示作为根节点,采用均衡抽样策略;
o步骤3:展开树节点:贡献者添加回复消息作为提示符或助手;
o步骤4:回复标注:贡献者对已有的节点回复进行打分;
o步骤5:排名:根据贡献者指南对贡献者进行排序。
树状态机在整个会话构造过程中管理和跟踪状态(例如,初始状态、增长状态、结束状态)。随后,通过过滤掉冒犯性和不恰当的会话树来构建 OpenAssistantConversations数据集。
3.12 Baize
Baize (Conover et al., 2023b)是一个英语多回合聊天语料库,使用 ChatGPT 构建 111.5K 实例。每一轮都由用户的提示和助手的回答组成。Baize v1中的每个实例包含3.4轮会话。为了创建Baize 数据集,作者提出了自我聊天的建议,ChatGPT轮流扮演用户和人工智能助手的角色,并以会话的形式生成消息。具体来说,作者首先设计了一个任务模板,定义了ChatGPT的角色和任务(如表 3所示)。接下来,他们从Quora 和Stack
Overflow数据集中取样问题(例如,“你如何修复一个不工作的谷歌 Play Store帐户?”)作为对话种子(例如,话题)。随后,他们用模板和取样的种子提示ChatGPT。ChatGPT不断地为双方生成消息,直到达到自然停止点。

4.
指令微调LLMs
4.1 InstructonGPT
InstructGPT (176B) (Ouyang et al., 2022)使用GPT-3(176B)
(Brown et al., 2020b)初始化,然后根据人类指令进行微调。该微调过程包括以下三个步骤:
o(1)基于 Playground API 历史记录的人工过滤指令数据集的监督微调(SFT);
o(2)通过人工对一个指令的多个反应进行采样,并对其进行排序,建立基于标注数据集的奖励模型来预测人类的偏好;
o(3)使用新的指令进一步优化第 1 步的模型和第 2 步的训练奖励模型。使用近端策略优化(PPO)(Schulman et al., 2017)方法更新参数,这是一种策略梯度强化学习方法。步骤(2)和步骤(3)交替多次直到模型性能没有显著改善。
总的来说,InstructGPT优于GPT-3。在自动评估方面,在TruthfulQA (Lin et al., 2021)数据集上,InstructGPT 的真实性比 GPT-3 高出 10% ,在RealToxicityPrompts (Gehman et al., 2020)数据集上,其毒性比GPT-3 高出7%。在NLP数据集(即WSC)上,InstructGPT实现了与GPT-3相当的性能。在人类评估中,在遵循正确指示、遵循明确约束、减少幻觉、产生适当反应四个方面,InstructGPT分别优于GPT-3 +10%、+20%、-20%和+10%。
4.2 BLOOMZ
BLOOMZ (176B) (muenighoff等人,2022)用 BLOOM(176B) (Scao 等人,2022)初始化,然后在指令数据集xP3上进行微调(muenighoff等人,2022),这是一个46种语言的人类指令数据集集合,来自两个来源:
o(1)P3,它是(英语指令,英语响应)对的集合;
o(2)一个(英语指令,多语言响应)集,通过在任务模板中填充预定义的英语指令,从多语言NLP数据集(如中文基准)转换而来。
在自动评价方面,在零样本设置下,BLOOMZ在共指消解、句子完成度和自然语言推理数据集上分别比 BLOOM 提高了10.4%、20.5%和 9.8%。在HumanEval 基准测试中(Chen 等人,2021 年),在Pass@100 指标方面,BLOOMZ 的表现比 BLOOM高出10%。对于生成任务,在 lm-evaluation-harness 基准测试中,与 BLOOM 相比,BLOOMZ 获得了+9%的BLEU改进。
4.3 Flan-T5
FLAN -T5 (11B)是一个由T5 (11B)初始化的大型语言模型(Raffel et al., 2019),然后在FLAN数据集上进行微调(Longpre et al., 2023)。FLAN 数据集是由 12 个NLP任务(如自然语言推理、常识推理、释义生成等)的62 个数据集组成的(指令、对)对集合,通过在统一任务形式化下填充各种指令模板来构建。在微调过程中,FLAN-T5对基于JAX的T5X框架进行了调整,每隔 2k步,就会根据所评估的保留任务选取最优模型。与 T5 的训练前阶段相比,微调需要0.2%的计算资源(约128个TPU v4芯片37小时)。在评估方面,FLAN-T5 (11B)优于 T5 (11B),并在少样本设 置 下 取
得 了 与 包 括 PaLM (60B)(Chowdhery 等人,2022)在内的更大模型的可比结果。在MMLU (Hendrycks et al., 2020)、BBH (Suzgun etal., 2022)、TyDiQA (Clark et al., 2020)、MGSM(Shi et al., 2022)、开放式生成和RealToxicityPrompts (Gehman 等人,2020 年),FLAN- T5 比 T5表现+18.9%、+12.3%、+4.1%、+5.8%、+2.1%和+8%。在少数情况下,FLAN-T5在BBH和TyDiQA数据集上的表现优于PaLM +1.4%和+1.2%。
4.4 Alpaca
Alpaca (7B) (Taori 等人,2023)是在 InstructGPT (175B,text-davinci- 003)
(Ouyang 等人,2022)生成的构建指令数据集上通过微调LLaMA
(7B) (Touvron 等人,2023a)训练的语言模型。在带有混合精度训练和完全共享数据并行的8卡80GB A100设备上,微调过程大约需要3个小时。在人类评价方面,Alpaca (7B)取得了与 InstructGPT(175B,text-davinci-003) 相 当 的 性 能 。具 体 来 说 ,Alpaca 在 自 我 指 导 数 据 集 上 的 表 现 优 于InstructGPT,获得了90个胜利实例,而不是89个。
4.5 Vicuna
Vicuna (13B) (Chiang 等人,2023)是在 ChatGPT 生成的会话数据集上通过微调 LLaMA (13B) (Touvron 等人,2023a)训练出来的语言模型。作者从 http://ShareGPT.com 网站上收集了用户共享的ChatGPT会话,过滤掉低质量的样本后,得到了 70K会话记录。LLaMA (13B)在构建的会话数据集上使用一个为多回合会话量身定制的修正损失函数进行微调。为了更好地理解跨多回合对话的长上下文,作者将最大上下文长度从512 扩展到 2048。在训练方面,作者采用了梯度检查点(the gradient checkpointing)和flash attention
(Dao et al., 2022)技术来降低微调过程中的
GPU 内存成本。在完全共享数据并行的 8×80GB A100设备上,微调过程需要24小时。作者们建立了一个专门用于测量聊天机器人性能的测试集。他们收集了一个由 8 个问题类别组成的测试集,如费米问题、角色扮演场景、编程/数学任务等,然后要求GP-4 (OpenAI, 2023)考虑帮助性、相关性、准确性和细节来评估模型的回答。在构建的测试集上,Vicuna (13B)优于Alpaca (13B) (Taori 等人,2023)并且LLaMA (13B)在
90%的测试问题中,与 ChatGPT在45%的问题中产生相同或更好的评分响应。
4.6 GPT-4-LLM
GPT-4-LLM(7B) (Peng et al., 2023)是在GPT-4 (OpenAI,2023) 生成的指令数据集上通过微调 LLaMA (7B)(Touvron et al., 2023a)来训练的语言模型。GPT-4-LLM用 LLaMA 初始化,然后通过以下两个步骤进行微调:
o对构造的指令数据集进行监督微调。作者使用了Alpaca 的指令(Taori 等人,2023 年),然后使用 GPT-4收集反馈。LLaMA在GPT-4
生成的数据集上进行了微调。在具有混合精度和完全共享数据并行性的 8*80GBA100 机器上,微调过程大约需要 3 个小时。
o利用近端 策 略 优 化 (proximal policy optimization,
PPO)(Schulman et al., 2017)方法优化
step-1模型,作者首先通过收集 GPT-4、InstructGPT
(Ouyang et al., 2022)和OPT-IML
(Iyer et al., 2022)的响应来建立一个比较数据集,然后让GPT-4 对每个响应从 1 到 10 进行评分。使用评级,基于 OPT 训练奖励模型 (Zhang et al. ,2022a)。利用奖励模型计算策略梯度对第 1步调整后的模型进行优化。
在评估方面,GPT-4-LLM (7B)不仅优于基准模型Alpaca (7B),而且优于更大的模型,包括 Alpaca (13B)和 LLAMA (13B)。在自动评估方面,GPT-4-LLM (7B)在User-Oriented-Instructions-252
(Wang et al., 2022c)、Vicuna-Instructions(Chiang
et al., 2023)和Unnatural
Instructions(Honovich et al.,2022)数据集上分别比Alpaca高出 0.2、0.5和 0.7倍。在人类评价方面,GPT-4-LLM在帮助性、真诚度、无害方面的表现分别比Alpaca高出11.7、20.9和 28.6。
4.7 Claude
Claude 是一种语言模型,通过在指令数据集上对预训练语言模型进行微调来训练语言模型,目的是生成有益和无害的反应。微调过程包括两个阶段:
o(1)对指令数据集进行监督微调。作者通过收集52K条不同的指令并与GPT-4生成的响应配对创建了一个指令数据集。在具有混合精度和完全共享数据并行性的8卡80GB A100 机器上,微调过程大约需要8 小时。
o(2)利用近端策略优化方法优化 step-1 模型。作者首先通过收集多个大型语言模型(如 GPT-3)对给定指令集合的响应来建立一个比较数据集,然后让 GPT-4对每个响应进行评分。使用评级,一个奖励模型被训练。然后,利用奖励模型和近端政策优化方法对第 1 步的微调模型进行优化。与主干模型相比,Claude 产生了更多有益和无害的反应。
在自动评估方面,Claude 在RealToxicityPrompts上的毒性表现比 GPT-3 高出 7% 。对于人类评估,在四个不同方面,包括遵循正确的指示、遵循明确的约束、减少幻觉和产生适当的反应,Claude 的表现分别优于 GPT-3+10%、+20%、-20%、+10%。
4.8 WizardLM
WizardLM (7B) (Xu 等人,2023a)是一种通过 LLaMA(7B) 对 ChatGPT 生成的指令数据集Evol-Instruct进行微调来训练的语言模型。它在Evol-Instruct的一个子集(70K)上进行了微调,以便与 Vicuna 进行公平的比较。基于Deepspeed Zero-3 技术的8卡V100 GPU,微调3个epoch大约需要70小时。在推理过程中,最大的生成长度是2048。为了评估LLMs在复杂指令上的性能,作者从真实的场景(例如,开源项目、平台和论坛)收集了218条人类生成的指令,称为Evol-Instruct测试集。
在Evol-Instruct测试集和 Vicuna测试集上进行评估。在人类评价方面,WizardLM大大超过了Alpaca(7B) 和Vicuna(7B),相比于ChatGPT在67%的测试样例中产生了相同或更好的响应。自动评估是通过让GPT-4对LLMs的回答进行评级来实现的。具体说,与Alpaca相比,WizardLM 的性能分别提高了6.2%、5.3%在 Evol-Instruct测试集和Vicuna测试集上。与Vicuna相比,在 Evol-Instruct测试集上高出 5.8%,在Vicuna测试集上高出 1.7%。
4.9 ChatGLM2
ChatGLM2 (6B) (Du et al., 2022)是在包含中英文指令的双语数据集上通过微调 GLM (6B) (Du et
al., 2022)训练的语言模型。双语指令数据集包含
1.4T标记,英汉比例为 1:1。数据集中的指令是从问答和对话完成任务中取样的。ChatGLM使用GLM进行初始化,然后使用与 InstructGPT类似的三步微调策略进行训练(Ouyanget al., 2022)。为了更好地模拟多回合对话中的上下文信息,作者将最大上下文长度从1024 扩展到 32K。为了降低GPU微调阶段的内存成本,采用了multi-query attention和causal mask strategies。在推理过程中,使用 FP16 的ChatGLM2需要13GB的GPU内存,使用模型INT4量化技术后可以用6GB GPU内存支持长达8K的会话。评估以四种英语和汉语基准进行,包括MMLU(英语)、C-Eval(汉语)、GSM8K(数学)和 BBH(英语 )。在所有基准测试中,ChatGLM2
(6B)优于 GLM (6B)和基线模型
ChatGLM(6B)。具体来说,ChatGLM2 在MMLU上比GLM好+3.1,在 C-Eval 上比 GLM 好+5.0,在 GSM8K 上比GLM 好 +8.6 , 在 BBH 上
比 GLM 好 +2.2 。在MMLU、C-Eval、GSM8K和BBH上,ChatGLM2 比ChatGLM
的性能分别提高了+2.1、+1.2、+0.4、+0.8。
4.10 LIMA
LIMA (65B) (Zhou et al., 2023)是在指令数据集上通过微调 LLaMA (65B) (Touvron et
al., 2023a)训练的大型语言模型,它是基于提议的表面对齐假设构建的。表面对齐假设是指模型的知识和能力几乎在预训练阶段就已经获得,而对齐训练(例如,指令微调)则会让模型在用户偏好的形式化状态下产生响应。基于表面对齐假设,作者声称大型语言模型可以通过对一小部分指令数据进行微调来生成用户满意的响应。因此,作者构建了指令训练集/有效集/测试集来验证这一假设。对构造的测试集进行评估。在人类评估方面,LIMA的表现分别比 InstructGPT 和 Alpaca 好 17%和 19%。此外,LIMA与BARD、Cladue和GP-4取得了可比的结果。对于自动评估,这是通过询问GPT-4对反应进行评分来进行的,评分越高表示表现越好,LIMA 比 InstructGPT 和Alpaca
分别高出 20%和 36%,与BARD达到了可比的结果,同时比Claude 和GP-4效果差。实验结果验证了所提出的表面对准假设。
4.11 Others
还有一些其他模型,不做过多介绍,模型如下:
oOPT-IML (175B)
oDolly 2.0 (12B)
oFalcon-Instruct (40B)
oGuanaco (7B)
oMinotaur (15B)
oNous-Herme (13B)
oTÜLU (6.7B)
oYuLan-Chat (13B)
oMOSS (16B)
oAiroboros (13B)
oUltraLM (13B)
5.多模态指令微调
5.1 多模态数据集
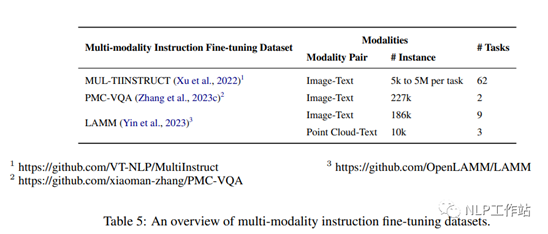
oMUL-TIINSTRUCT (Xu et al., 2022)是一个多模式指令调整数据集,由 62 个不同的多模式任务以统一的序列到序列格式组成。该数据集涵盖了10大类,其任务来源于21个现有的开源数据集。每个任务都配有 5 个专家编写的说明。对于现有的任务,作者使用他们可用的开源数据集的输入/输出对来创建实例。对于每个新任务,作者通过从现有任务的实例中提取必要的信息或重新构造它们,创建了 5k 到 5M实例。MUL-TIINSTRUCT数据集在增强各种迁移学习技术方面的有效性得到了验证。例如,使用多种迁移学习策略,如 MUL-TIINSTRUCT上的混合指令调整和顺序指令调整,对OFA模型(930M)进行微调(Wang等人,2022a),可以在所有未见过的任务中提高零样本性能。在常规 VQA 任务中,在MUL-TIINSTRUCT上优化的OFA在RougeL 上达到 50.60,准确率为 31.17,而原 OFA RougeL为 14.97,准确率为0.40。
oPMC-VQA (Zhang et al., 2023c)是一个大规模的医学视觉问答数据集,包含 149k幅图像的227k幅图像-问题对
,涵盖各种模式或疾病。该数据集既可用于开放式任务,也可用于多项选择任务。生成PMC-VQA数据集的流程包括从PMC-OA (Lin et al., 2023)数据集收集图像-标题对,使用 ChatGPT 生成问题-回答对,并手动验证数据集的子集的质量。作者提出了一种基于生成的医学视觉理解模型MedVInT,将视觉信息与大型语言模型进行对齐。在 PMC- VQA 上进行预训练的MedVInT 达到了最先进的性能,并在 VQA- rad (Lau等人,2018)和 SLAKE (Liu 等人,2021a)基准上优于现有模型,在VQA- rad上的精度为81.6%,在SLAKE的准确率为88.0%。
oLAMM (Yin et al., 2023)是一个全面的多模态指令调整数据集,用于理解二维图像和三维点云。LAMM包含 186K语言图像指令-响应对,10K语言点云指令-响应对。作者从公开的数据集中收集图像和点云,并使用GPT-API 和自指令方法,根据这些数据集的原始标签生成指令和响应。LAMM-Dataset
通过整合来自 Bamboo (Zhang etal.,
2022b)数据集的层次知识图标签系统和相应的维基百科描述,包括用于常识知识问题回答的数据对。作者还提出了LAMM-
Benchmark,用于评估现有的多模态语言模型(MLLM)在各种计算机视觉任务上的性能。它包括 9 个公共图像任务和 3 个公共点云任务,以及LAMM-框架,这是一个主要的MLLM训练框架,用于区分编码器、投影仪和 LLM微调块,以避免不同模式的模态冲突。
5.2 多模态指令微调模型
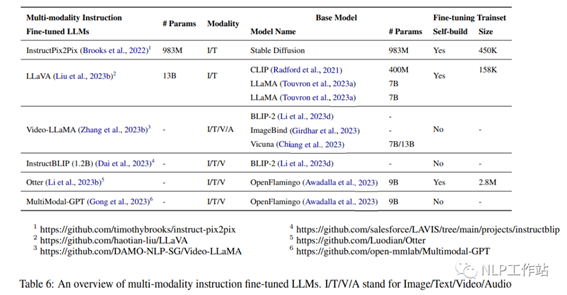
InstructPix2Pix (983M) (Brooks 等人,2022)是一个条件扩散模型,通过Stable Diffusion(983M)
(Rombach 等人,2022)在一个构建的多模态数据集上进行微调,该数据集包含超过 450K文本编辑指令和编辑前后的相应图像。作者结合了两个大规模预训练模型的能力,一个语言模型 GPT-3 (Brown et al.,2020b)和一个文本到图像模型Stable Diffusion(Rombach et al., 2022),来生成训练数据集。GPT-3经过微调,可以根据图像提示生成文本编辑,而 Stable Diffusion 用于将生成的文本编辑转换为实际的图像编辑。然后使用潜在的扩散目标在这个生成的数据集上训练InstructPix2Pix。图 5 为生成图像编辑数据集并在该数据集上训练扩散模型的过程。作者将本文提出的方法与之前的工作如 SDEdit(孟 et al.,
2022)和 Text2Live (Bar-Talet al., 2022)进行了定性比较,强调了模型遵循图像编辑指令而不是图像描述或编辑层的能力,。作者还通过使用度量图像一致性和编辑质量的指标,与 SDEdit(孟等人,2022 年)进行了定量比较。

LLaVA (13B) (Liu et al., 2023b)是一种多模态大模型,通过将 CLIP (400M)视觉编码器(Radford et al., 2021)与语言解码器LLaMA(7B) (Touvron 等,2023a)连接起来而开发。LLaVA使用生成的指示的视觉语言数据集进行微调,该数据集由158K唯一的语言图像指令跟随样本组成。数据收集过程包括创建对话、详细描述和复杂的推理提示。GPT-4用于将图像-文本对转换为该数据集适当的指令遵循格式。诸如标题和边框等视觉特征被用来对图像进行编码。与GPT-4 相比,LLaVA在基于数据集的合成多模态指令上的相对得分为 85.1%。当在Science QA上进行微调时,LLaVA和GPT-4的协同作用达到了最新的92.53%的精度。
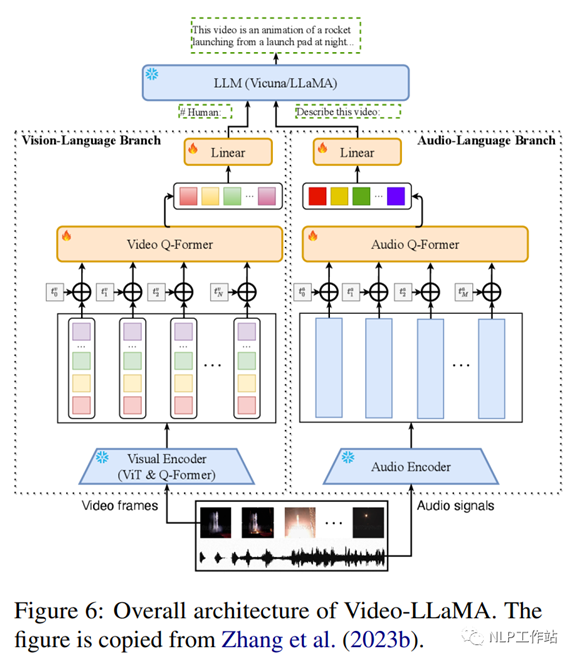
Video-LLaMA (Zhang et al., 2023b)是一个多模态框架,它增强了大型语言模型的理解视频中的视觉和听觉内容的能力。其包括两个分支编码器:视觉语言(VL)分支和视听语言(AL)分支,以及一个语言解码器(Vicuna (7B/13B),LLaMA (7B)。VL分支包括一个冻结的预训练图像编码器(BLIP-2 的预训练视觉组件,其中包括一个ViT-G/14和一个预训练Q-former),一个位置嵌入层,一个视频 Q-former 和一个线性层。AL 分支包括一个预先训练的音频编码器(ImageBind (Girdhar 等人,2023))和一个音频Q-former。图6 显示了Video-LLaMA的总体架构,包括视觉语言分支和视听语言分支。VL 分支在Webvid-2M (Bain et al., 2021)视频字幕数据集上进行训练,并执行视频到文本的生成任务,并对来自MiniGPT-4、LLaVA 和VideoChat的指令调优数据进行微调。在视频/图像描述数据上训练AL分支,将ImageBind的输出连接到语言解码器。经过微调,Video-LLaMA可以感知和理解视频内容,展示了其整合听觉和视觉信息、理解静态图像、识别常识概念和捕捉视频中时间动态的能力。
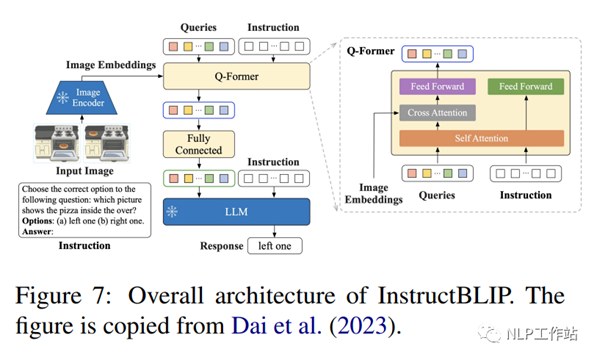
InstructBLIP (1.2B) (Dai et al. , 2023) 是视觉语言指令调优框架,用预先训练的 BLIP-2 进行初始化,模型由图像编码器、大语言模型(FlanT5 (3B/11B)
或 Vicuna (7B/13B)和查询转换器(Q-Former)去连接两者。如图 7 所示,Q-Former 从冻结图像编码器的输出嵌入中提取指令感知视觉特征,并将视觉特征作为软提示输入输入到冻结的LLM中。作者评估了InstructBLIP模型在各种视觉语言任务上的表现,包括图像分类、图像字幕、图像问答和视觉推理。他们使用 26 个公开可用的数据集,将它们分为 13 个训练数据集和 13 个评估数据集。作者证明,InstructBLIP在各种视觉语言任务中都能实现最先进的零样本性能。与 BLIP-2 相比,InstructBLIP的平均相对改进为15.0%, 最小的InstructBLIP (4B)在所有6 个共享评估数据集上的平均相对改进为 24.8%,优于Flamingo (80B) (Alayrac 等人,2022)。
Otter (Li et al., 2023b)是一个通过微调 OpenFlamingo (9B)(Awadalla
et al., 2023)训练的多模态模型,语言和视觉编码器是固定的,只微调感知器resampler 模块、交叉注意层和输入/输出嵌入。作者组织了涵盖11个类别的多种多模态任务,并构建了包含 2.8M多模态指令-响应对的多模态上下文指令调优数据集MIMIC-IT,该数据集由图像-指令-答案三联体组成,其中指令-答案是根据图像量身定制的。每个数据样本还包括上下文,其中包含一系列图像-指令-答案三元组 在上下文上与查询的三元组关联。与OpenFlamingo 相比,Otter 展示了更准确地遵循用户指示并提供更详细的图像描述的能力。
MultiModal-GPT (Gong et al., 2023)是一种多模态指令调整模型,能够执行不同的指令,生成详细的字幕,计算特定对象,并解决一般查询。MultiModal-GPT 是通过对OpenFlamingo (9B)开放数据集上对各种创建的视觉指令数据进行微调来训练的,包括VQA、图像字幕、视觉推理、文本OCR和视觉对话。实验证明了MultiModal-GPT在与人保持连续对话方面的熟练程度。
6.特定领域的指令微调
6.1 对话
InstructDial (Gupta 等人,2022 年)是一个为对话设计的指令调优框架。它包含由 59 个对话数据集创建的一致的文本到文本格式的 48 个对话任务集合。每个任务实例包括任务描述、实例输入、约束、指令和输出。为了保证指令的执行,该框架引入了两个元任务:(1)指令选择任务,模型选择与给定输入输出对相对应的指令;(2)指令二进制任务,如果指令从输入输出到给定的输出,模型会预测“是”或“否”。两个基本模型 T0-3B (T5 的 3B 参数版本)和BART0(基于 Bart-large的406M模型)在 InstructDial 的任务上进行了微调。InstructDial 在未见过的对话数据集和任务上取得了令人印象深刻的结果,包括对话评估和意图检测。此外,当应用于少样本头时,它提供了更好的结果。
6.2 意图分类和槽位标记(Slot Tagging)
LINGUIST,基于AlexaTM 5B微调,是一个 50亿参数的多语言模型,用于意图分类和插槽标记的指令数据集任务。每条指令由五个块组成:(i)生成输出的语言,(ii)意图,(iii)输出中包含的槽类型和值(例如,[3,snow]中的数字 3 对应槽类型,snow是该槽使用的值),(iv)从槽类型标签到数字的映射和(v)最多10个示例指示输出的格式。在使用 SNIPS 数据集的 10 个镜头的新意图设置中,LINGUIST 与最先进的方法相比有显著改进。在mATIS++数据集的零概率跨语言设置中, LINGUIST在保持意图分类性能的同时,跨越 6 种语言的槽对齐机器翻译的基线值超过了强基线值。
6.3 信息提取
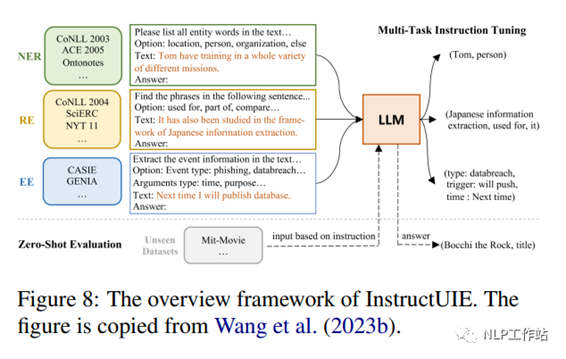
InstructUIE (Wang et al., 2023b)是一个基于指令调优的统一信息提取(information
extraction,IE)框架,它将 IE任务转换为seq2seq格式,并通过在构建的 IT 数据集上微调11B FlanT5来解决这些问题。图8 显示了 InstructUIE 的总体架构。本文介绍了 IE指令,它是一基于统一文本到文本格式的 32 种不同信息抽取数据集的基准,具有专家编写的指令。每个任务实例由四个属性描述:任务指令、选项、文本和输出。任务指令包含诸如要提取的信息类型、输出结构格式以及在提取过程中需要遵守的附加约束或规则等信息。选项指的是任务的输出标签约束,文本指的是输入的句子。输出是通过转换样本的原始标签(例如:NER中的“实体标签:实体跨度”)。在监督设置下,InstructUIE的表现与BERT相当 (Devlin等人,2018年),并在零样本设置中优于最先进的GPT3.5。
6.4 基于方面的情感分析
Varia 等人(2022)提出了一个统一的指令调整框架,用于基于微调 T5 (220M) (Raffel 等人,2019)模型来解决基于方面的情感分析(ABSA)任务。该框架处理的多因子子任务涉及ABSA的四个要素,即方面术语、方面类别、意见术语和情感。它将这些子任务视为五个问答任务的组合,使用为每个任务提供的指令模板对语料库中的每个句子进行转换。例如,使用的一个指令模板是“文本中的方面术语是什么:$text ?”该框架展示了实质性的改进(平均 8.29 F1)超过最先进的少数镜头学习场景,并保持在全面的微调场景下的可比性。
6.5 写作
Zhang 等人(2023d)提出了Writing-Alpaca-7B,它对写作指令数据集上的LLaMa-7B 进行微调,以提供写作帮助。建议的指令数据集是基于指令数据的 EDITEVAL 基准的扩展,去掉了更新任务,并引入了语法性任务。指令方案严格遵循Stanford
Alpaca项目的指令方案,包括通用序言、指导任务完成的指令域、提供待编辑文本的输入域和需要模型填写的响应域。Writing-Alpaca-7B改善了LLaMa 在所有写作任务上的表现,并优于其他更大的现成LLM。
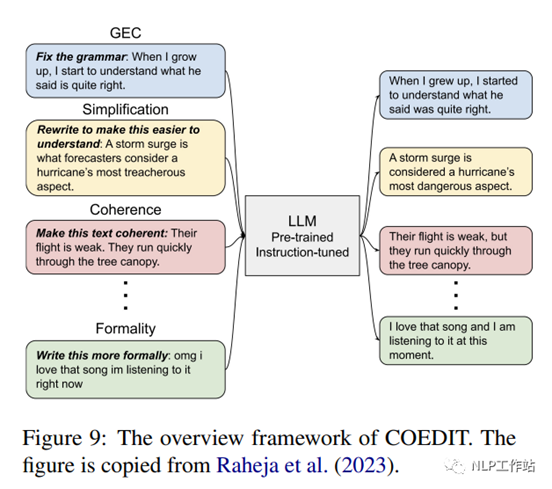
CoEdIT (Raheja et al., 2023) 微调 FLANT5 (770M 参数,3B参数和 11B参数)在指令数据集上进行文本编辑,以提供写作帮助。指令集由大约 82K对<指令:源,目标>组成。如图 9所示,模型接受用户指定所需文本特征的指令,例如“让句子更简单”,并输出编辑后的文本。CoEdIT 在几个文本编辑任务中实现了最先进的性能,包括语法错误纠正、文本简化、迭代文本编辑和三种文体编辑任务:正式风格转换,中和及释义。此外,它可以很好地推广到新的、在微调中没见过的相邻任务。
CoPoet (Chakrabarty 等人,2022)是一种协作式诗歌写作工具,它利用大型语言模型(如 T5-3B、T5-11B 和
T0-3B模型),在各种诗歌写作指导集合中进行训练。指令数据集中的每个示例都包含一个<指令,poe_line >对。有三种主要的指示类型:接续、词汇约束和修辞技巧。CoPoet 是由指定诗歌所需属性的用户指令来引,比如写一个关于“爱”的句子,或者以“飞”结束一个句子。该系统不仅可以与基于指令(如 InstructGPT)训练的公开可用的LLM竞争,而且还能够满足没见过的的合成指令。
6.6 医疗
Radiology-GPT (Liu et al., 2023c)是一种用于放射学的微调 Alpaca-7B 模型,该模型在广泛的放射学领域知识数据集上使用一种指令调整方法。放射学报告通常包括两个相应的部分:“发现”和“印象”。“发现”部分包含放射学图像的详细观察结果,而“印象”部分总结了从这些观察结果得出的解释。Radiology-GPT 对“发现”文本提供了简要说明:“从放射学报告中的发现得出印象”。同样的报告里的"印象"文本作为目标输出。与 StableLM、Dolly 和
LLaMA等通用语言模型相比,Radiology-GPT在放射诊断、研究和交流方面具有显著的通用性。
ChatDoctor (Li et al., 2023g)基于经过微调的 LLaMA-7B 模型,利用alpaca指令数据集和HealthCareMagic100k 患者-医生对话数据集。提示模板设计用于在医患对话期间检索外部知识库,如疾病数据库和维基百科检索,以从模型获得更准确的输出。ChatDoctor 显著提高了模型理解病人需求和提供明智建议的能力,通过从可靠的在线和离线来源对模型进行自导向信息检索,其响应的准确性大大提高。
ChatGLM-Med,基于ChatGLM-6B模型对中文医学教学数据集进行了微调(王浩春,2023)。指令数据集包括使用 GPT3.5 API 和医学知识图创建的与医学相关的问题和答案对。该模型提高了ChatGLM在医学领域的问答性能。
6.7 算术
Goat (Liu and Low, 2023) 是一个基于指令的精细调整的LLaMA-7B 模型,旨在解决算术问题。它通过使用ChatGPT 生成数百个指令模板,以自然语言问答的形式表示算术问题,如“什么是 8914/64?”该模型采用了多种技术来增强其对不同问题格式的适应性,例如随机删除算术表达式中数字和符号之间的空格,以及将“*”替换为“x”或“times”。Goat 模型在BIG-bench 算法子任务上实现了最先进的性能。特别是,零样本的 Goat7B 匹配或超过了少样本的PaLM-540B。
6.8 代码
WizardCoder (Luo et al., 2023)利用 StarCoder 15B 作为基础,通过将进化-指令方法(Xu et al.,
2023)适应到代码领域,进行复杂的指令微调。训练数据集通过在 Code Alpaca 数据集上迭代应用 Evol-Instruct 技术,它包括每个样本的以下属性:指令、输入和预期输出。例如,当指令是“修改下面的 SQL 查询以选择不同的元素”时,输入是 SQL 查询,预期的输出是生成的答案。WizardCoder 优于所有其他开源代码 LLMs,甚至在HumanEval 和HumanEval+优于最大的 LLMs,如Anthropic 的
Claude 和谷歌的 Bard.
7.
有效的调优技术
高效的微调技术旨在通过多种方式优化一小部分参数,即基于添加、基于规范和基于重参数化,从而使LLMs适应下游任务。基于添加的方法引入了原始模型中没有的额外的可训练参数或模块。代表性的方法包括adapter tuning(Houlsby 等人,2019)和prompt-based tuning(Schick 和Schütze, 2021)。基于规范的方法指定要调整的某些固有模型参数,同时冻结其他参数。例如,BitFit (Zaken et al., 2022)对预训练模型的偏差项进行调整。重参数化方法将模型权重转换为参数效率更高的形式,以便进行调整,其关键是假设模型适应性是低秩的,因此权重可以被重新参数化为低秩因子或低维子空间(如 LoRA (Hu et al.,
2021))。Intrinsic prompt发现了一个低维子空间,它由跨不同任务的调优提示共享。
7.1 LoRA
低秩适应(LoRA) (Hu et al., 2021)能够使用低秩更新实现LLM的高效适应。LoRA使用 DeepSpeed (Rasley
等人,2020年)作为训练骨干。LoRA的关键观点是,适应新任务所需的 LLM权值的实际变化存在于低维子空间中。具体来说,对于一个预先训练的权值矩阵W0,作者将调整后的权值矩阵建模为W0 +∆W,其中∆W是一个低秩更新。∆W参数化为∆W = BA,其中A和B是小得多的可训练矩阵。我们选择∆W的秩 r 远小于W0 的维数。作者的直觉是,不直接训练所有的W0,而是训练低维A和B,后者在与下游任务有关的方向的低秩子空间中间接训练W0。与完全的微调相比,这导致可训练的参数要少得多。对于 GPT-3,与完全的微调相比,LoRA减少了 10,000 倍的可训练参数数量和 3 倍的内存使用。
7.2 HINT
HINT (Ivison et al., 2022)将指令调优的通用性优势与高效的按需微调结合在一起,避免了重复处理冗长指令。HINT的本质在于超网络,它基于自然语言指令和少量示例生成参数高效的llm自适应模块。所采用的超网络将指令和少数示例转换成编码指令,并使用预先训练的文本编码器和基于交叉注意的参数生成器生成适配器和前缀参数。然后,生成的适配器和前缀作为高效的调优模块插入到主干模型中。在推理时,超网络对每个任务只执行一次推理,以生成适应的模块。这样做的好处是,与常规的微调或输入连接方法不同,HINT可以在不增加计算量的情况下合并较长的指令和额外的少量片段。
7.3 Qlora
QLORA (Dettmers 等人,2023)包括优化量化和内存优化,旨在提供高效和有效的 LLMs 微调。QLORA包括4 位NormalFloat
(NF4)量化,这是一种针对 LLM权值的典型正态分布优化的量化方案。通过基于正态分布的分位数进行量化,NF4提供了比标准的4位整数或浮点量化更好的性能。为了进一步减少内存,量化常量本身被量化为8位。这第二级量化平均为每个参数节省 0.37比特。QLORA利用NVIDIA的统一内存特性,当GPU内存超过时,页面优化器状态到 CPU RAM,避免了训练过程的记忆不足。QLORA可以在单个 48GB GPU上训练65B参数的LLM,而与全16位微调相比没有退化。QLORA的工作原理是冻结 4位量化基LLM,然后反向传播。
7.4 LOMO
LOw-Memory Optimization (LOMO) (Lv 等人,2023)通过融合梯度计算和更新,在有限的计算资源下实现 llm的全参数微调。其本质是将梯度计算和参数更新融合到反向传播的一步中,从而避免了全梯度张量的存储。首先,在 LOMO 中提供了理论分析,解释了为什么SGD可以很好地对大型预训练模型进行微调,尽管它对较小的模型存在挑战。此外,LOMO在反向传播中计算出每个参数张量的梯度后,会立即更新每个参数张量。每次存储一个参数的梯度可以将梯度内存减少到O(1)。LOMO采用梯度值裁剪、分离梯度范数计算和动态损耗缩放来稳定训练。激活检查点和零优化方法的集成节省了内存。
7.5 Delta-tuning
Delta-tuning(Ding et al., 2023b)为理论分析提供了优化和最优控制的视角。直观地说,delta-调优通过限制调优到低维流形来执行子空间优化。调整后的参数作为最优控制器,指导下游任务的模型行为。
8.
评估、分析和批评
8.1 HELM评估
HELM(Liang et al., 2022)是对语言模型(LMs)的整体评估,以提高语言模型的透明度,提供对语言模型的能力、风险和局限性的更全面的理解。具体来说,与其他评价方法不同的是,HELM认为对语言模型的整体评价应该关注以下三个因素:
o(1) 覆盖面广。在开发过程中,语言模型可以适应各种NLP任务(如序列标注和问题回答),因此,语言模型的评估需要在广泛的场景中进行。考虑到所有可能的情况,HELM提出了一种自顶向下的分类法,首先将一个大型NLP 会议(ACL2022)中的所有现有任务编译成一个任务空间,并将每个任务划分为场景(如语言)和度量(如准确性)的形式。然后,当面对一个特定的任务时,分类法将在任务空间中选择一个或多个场景和指标来覆盖它。HELM通过分析每个任务的结构,明确了评估内容(任务场景和指标),将语言模型的场景覆盖率从 17.9%提高到96.0%。
o(2) 多度量测量。为了使人类能够从不同的角度衡量语言模型,HELM提出了多度量度量。HELM涵盖了
16个不同的场景和 7 个指标。为了确保密集的多度量测量的结果,HELM测量了 112 个可能的核心场景中的98个(87.5%)。
o(3) 标准化。语言模型的规模和训练复杂度的增加,严重阻碍了人们对各个语言模型结构的理解。为了建立对现有语言模型的统一理解,HELM对30个知名语言模型进行 了 基 准 测 试 , 包 括 谷 歌 (UL2(Tay et al. ,2022)) 、 OpenAI (GPT-3(Brown et al. , 2020b)) 和EleutherAI (GPT-NeoX(Black et al., 2022))等机构。有趣的是, HELM 指 出 , T5 (Raffel et al. , 2019) 和Anthropic- LMv4-s3 (Bai et al., 2022a)等 LLMs 在最初的工作中并没有直接比较,而 GPT-3、YaLM等 LLMs经过多次评估后,仍然与相应的报告存在差异。
8.2 低资源指令调优
Gupta 等人(2023)试图估 IT模型所需的最小下游训练数据,以匹配 SOTA监督模型对各种任务的要求。Gupta 等人(2023)在单任务学习(STL)和多任务学习(MTL)设置下,对来Super Natural
Instructions(SuperNI)的 119个任务进行了实验。结果表明,在 STL设置中,只有25%的下游训练数据的IT 模型在这些任务上的表现优于 SOTA模型,而在MTL设置中,只有 6%的下游训练数据可以引导 IT 模型实现SOTA性能。这些发现表明,指令调整可以有效地帮助模型在数据有限的情况下快速学习任务。
8.3 更小的指令数据集
IT 需要大量的专门的指令数据进行训练。Zhou 等人(2023)假设,预训练的LLM只需要学习风格或格式来与用户交互,并提出了通过仅在1000个精心挑选的训练示例上对LLM进行微调,从而实现强大性能的LIMA。具体来说,LIMA首先手动管理
1000 个具有高质量提示和响应的示例。然后,1000 个示例被用来微调预训练的 LLaMa-65B(Touvron 等人,2023b)。相比之下,在超过 300个具有挑战性的任务中,LIMA的表现优于 GPT-davinci003 (Brown 等人,2020b),后者通过人类反馈调整在 5200 个示例中进行了微调。此外,仅通过一半的示例 , LIMA 就 取
得 了 与 GPT-4 (OpenAI,2023)、Claude (Bai 等人,2022b)和Bard 相当的结果。最重要的是,LIMA证明了LLMs 强大的知识和能力可以向用户展示,只需要一些精心策划的微调说明。
8.4 指令调优评估数据集
IT模型的性能高度依赖 IT数据集。然而,对这些信息技术数据集缺乏开放式和主观的评价。为了解决这个问题,Wang 等人(2023c)在各种开放
IT数据集上通过微调 LLaMa 模型(Touvron等人,2023b)来执行数据集评估,并通过自动和人工评估来测量不同的微调模型。在 IT数据集的组合上训练一个额外的模型。对于结果,Wang et al. (2023c)表明,在所有任务中不存在单一的最佳 IT数据集,而通过手动组合数据集可以实现最佳的整体性能。此外,Wang et al. (2023c)指出,尽管 IT可以给所有尺寸的 llm带来很大的好处,但更小的模型和高质量的基础模型质是 IT 的最大受益者。对于人类评估,模型越大,可接受性得分越高。
8.5 IT只是学习模式复制吗?
为了解决模型通过指令调优获得的特定知识缺乏清晰性的问题,Kung 和 Peng(2023)深入分析了模型如何在 IT过程中使用指令,方法是比较提供修改指令和原始指令时的调优。
特别是,Kung 和Peng(2023)创建了简化的任务定义,删除了所有语义组件,只留下输出信息。此外,Kung和 Peng(2023)还引入了包含不正确的输入-输出映射的虚幻示例。令人惊讶的是,实验表明,根据这些简化的任务定义或错误示例训练的模型,可以获得与根据原始指令和示例训练的模型相当的性能。此外,本文还引入了零样本分类任务的基线,在低资源设置下实现了与 IT相似的性能。
总之,根据 Kung 和 Peng(2023)的观点,在当前的 IT 模型中观察到的显著性能改进可能归因于他们捕捉表层模式的能力,例如学习输出格式和猜测,而不是理解和学习特定的任务。
8.6 专有LLMs仿制
LLM仿制是一种从更强大的模型(如ChatGPT等专有系统)收集输出的方法,并使用这些输出对开源的 LLM进行微调。通过这种方式,开源LLM可以获得与任何专有模型竞争的能力。
Gudibande 等人(2023)进行了多次实验,批判性地分析了模型模仿的有效性。具体来说,Gudibande
等人(2023)首先从ChatGPT的广泛任务输出中收集数据集。然后,这些数据集被用于微调一系列模型,包括 1.5B到13B的大小,基础模型GPT-2
和LLaMA,数据量从0.3Mtoken到 1.5 m token。
对于评估,Gudibande等人(2023)证明,在支持数据集的任务中,模仿模型比以前好得多,输出结果与 ChatGPT 相似。而在没有模拟数据集的任务中,模拟模型的准确性并没有提高甚至下降。
因此,Gudibande et al.(2023)指出,正是模仿模型善于模仿ChatGPT 的风格(如流利、自信和结构良好)的现象,使得研究者对模仿模型的一般能力产生了错觉。因此,Gudibande 等人(2023)建议,研究人员最好将重点放在提高基础模型和指令示例的质量上,而不是模仿专有模型。
总结
大模型时代,不进则退,希望大家学习起来。
出自:https://mp.weixin.qq.com/s/P57YuTadNagd-a3Np_sooA
一个AI购物助手,Claros 旨在通过提供个性化建议、价格比较和最优惠的价格来简化您的购买决策,彻底改变您的购物体验,确保您做出明智的购买选择并节省时间和金钱。