复旦开源中文医疗大模型,基于百川微调,模型和数据集都公开
发布时间:2024年06月06日
DISC-MedLLM是由复旦大学数据智能与社会计算实验室(Fudan-DISC)研发并开源的一款专门针对医疗健康对话式场景而设计的大模型。DISC在Github开源了这个项目,其中包括DISC-Med-SFT数据集(不包括行为偏好训练数据)和DISC-MedLLM的模型权重。
同时提供了在线的地址,现在就可以体验到MedLLM的模型效果,关注本公众号“极客开源”并在公众号后台回复MedLLM或医疗模型获取在线Demo地址。
01
DISC-MedLLM的问世,为医疗领域带来了很多的可能性。它不仅仅是一个简单的问答模型,更有可能成为医疗健康领域的智慧助手。无论是需要进行疾病问诊、治疗方案咨询还是寻求高质量的健康支持服务,DISC-MedLLM都能够满足当前的各种医疗保健需求。
这一医疗领域大模型的独特之处在于,它有效地对齐了医疗场景下的人类偏好。这意味着,DISC-MedLLM不仅仅提供通用性的语言模型输出,更能够弥合真实世界医疗对话与通用模型之间的差距。这一优势在实验结果中得以清晰体现,很明显这个优势能为用户提供卓越的使用体验。
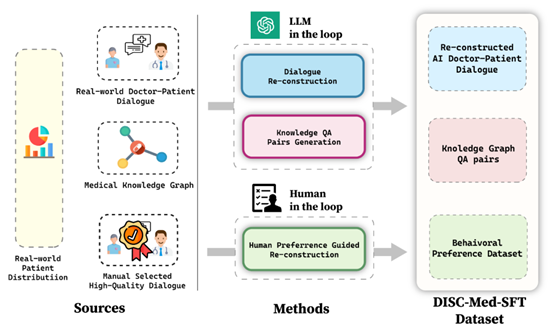
DISC-MedLLM的独特之处源于其创新性的设计和多元数据构造机制,这一机制是基于我们以目标为导向的策略,以及真实医患对话数据和知识图谱的深度结合而成。这为DISC-MedLLM赋予了以下 3 个显著特点,使其成为医疗领域大模型的佼佼者:1. 可靠丰富的专业知识:我们将医学知识图谱作为信息源,利用采样三元组的方法,结合通用大模型的语言能力,构建对话样本。这一独特的构建方式赋予了DISC-MedLLM丰富的专业知识,使其能够在医疗对话中提供可靠且充实的信息,满足用户的需求。2. 多轮对话的问询能力:为了确保DISC-MedLLM能够胜任复杂的多轮医疗对话,我们以真实咨询对话记录作为信息源,利用大模型进行对话重建。在构建过程中,我们追求模型对话的完全对齐,特别注重对医学信息的准确呈现。这一特性使DISC-MedLLM成为一个多轮对话的专家,能够深入理解和回应患者的各种疑虑和问题。3. 对齐人类偏好的回复:在医疗咨询过程中,患者常常期望获得更多的支撑信息和背景知识,然而,人类医生的回答通常较为简洁。为了满足患者的需求,我们采取了一项创新的举措,通过人工筛选,构建了符合人类偏好的高质量小规模行为微调样本。这使得DISC-MedLLM的回复能够更好地对齐患者的期望,为他们提供更丰富和满意的支持。总之,DISC-MedLLM以其可靠的专业知识、多轮对话的问询能力和对齐人类偏好的回复而脱颖而出。算是大语言模型在医疗领域的一项创新,为在线问诊和医患交流场景提供了可行的智能化解决方案。02 模型效果DISC-MedLLM 模型模拟用户进行疾病问诊的效果如下:
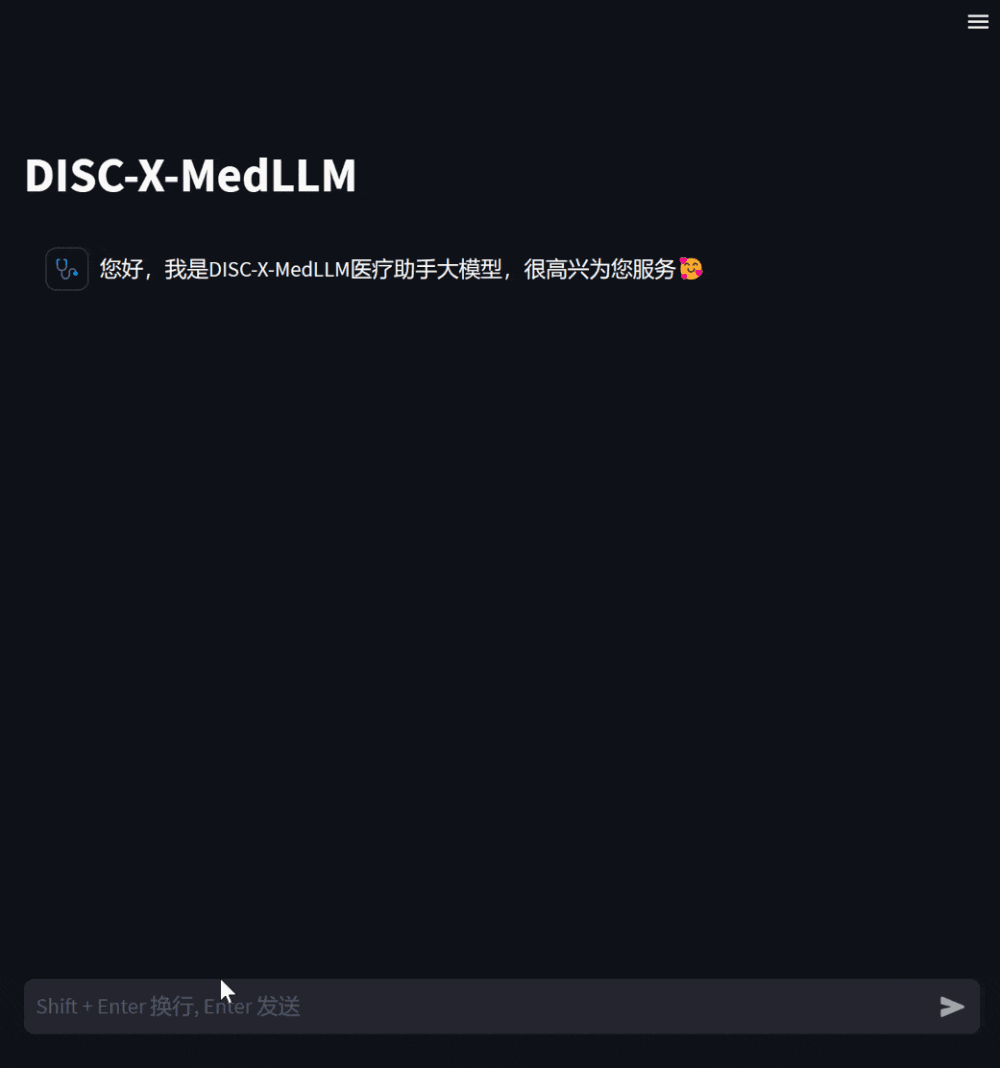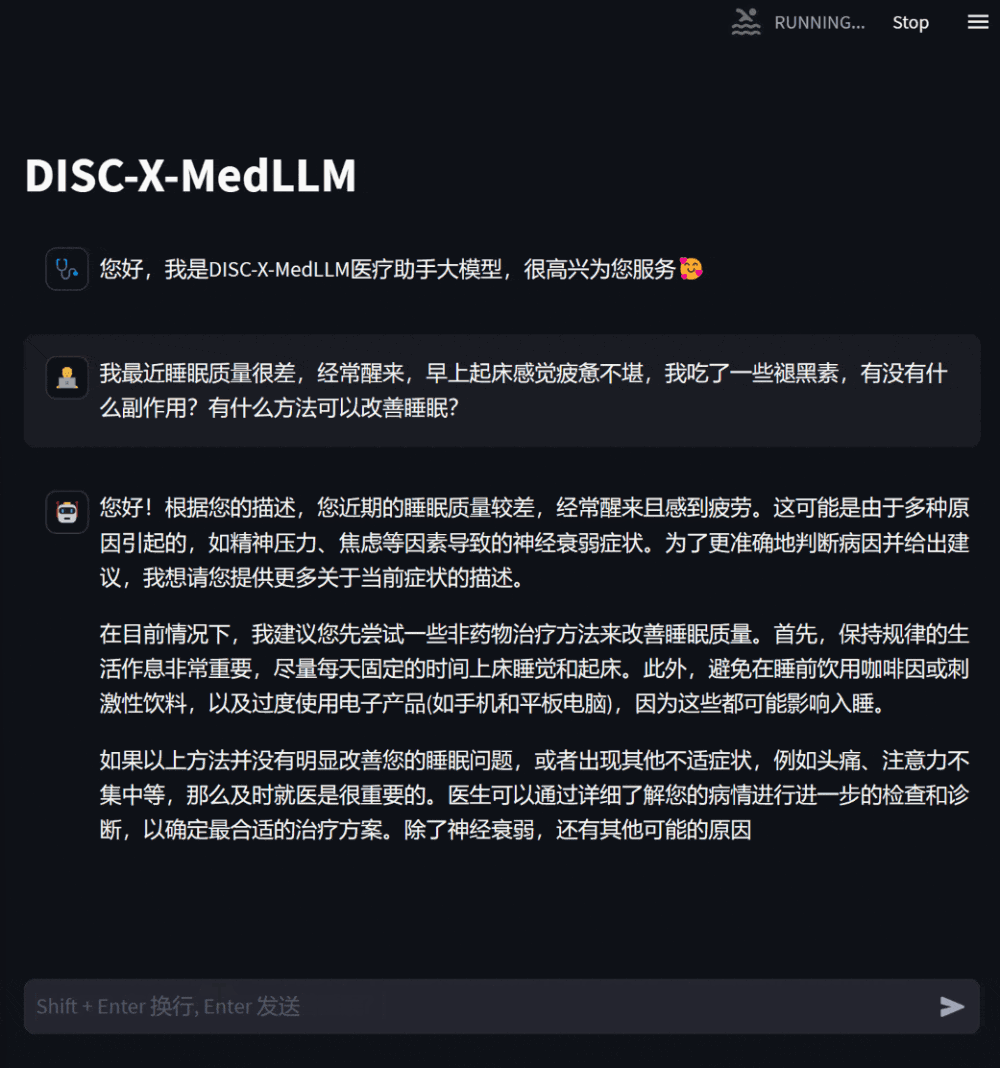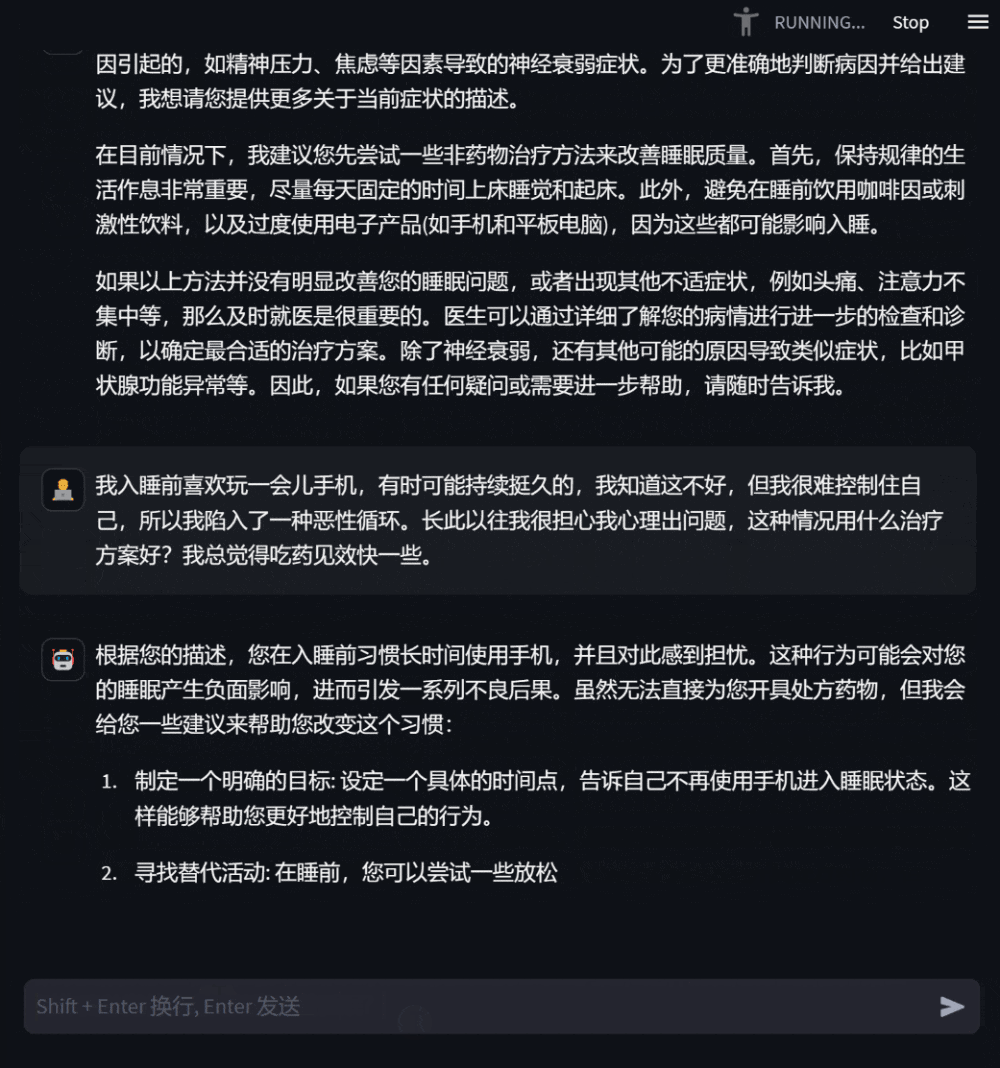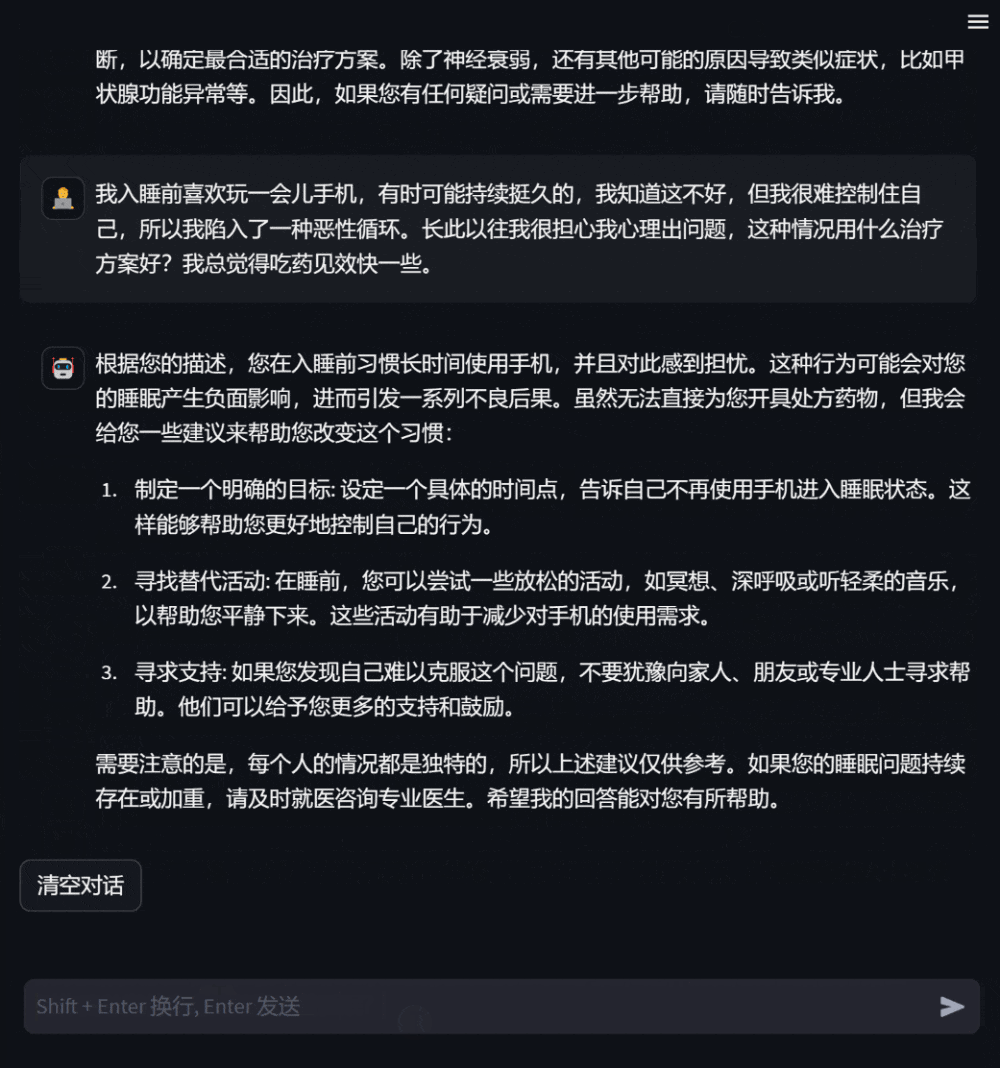
模拟治疗方案咨询效果如下,同时提供了在线的地址,现在就可以体验到MedLLM的模型效果,关注本公众号“极客开源”并在公众号后台回复MedLLM
或 医疗模型获取在线Demo地址。

03 数据集
数据集的精心构建是模型微调可以成功的关键之一,DISC-MedLLM 也不例外。该项目的数据集命名为 DISC-Med-SFT,它是一个高质量的医疗领域数据集,包含了超过47万个样本,这些样本都是通过重新构建现有医疗数据集而得到的。采用了目标导向的策略,通过对几个精心选择的数据源进行重构,为DISC-MedLLM的训练提供了坚实的基础。这些数据的关键作用在于帮助模型学习医疗领域的知识,将其行为模式与人类偏好对齐,并确保与真实世界在线医疗对话的分布情况相符。以下是构建DISC-Med-SFT数据集所使用的数据源以及相应的样本数量:1. AI医患对话 (MedDialog):这个数据源贡献了400,000个样本,为DISC-MedLLM提供了丰富的医患对话背景。2. cMedQA2:这个数据源提供了20,000个样本,有助于拓展模型的医学知识。3. 知识图谱问答对
(CMeKG):包含50,000个样本,为DISC-MedLLM提供了来自知识图谱的宝贵信息,帮助模型更深入地理解医疗知识。4. 行为偏好数据集:这部分数据是经过人工筛选的,仅包含2,000个样本,但它们在对齐人类偏好方面发挥着关键作用,需要注意这部分数据没有在当前项目中公开。5. 其他数据集:包括MedMCQA(8,000个样本)、MOSS-SFT(33,000个样本)以及Alpaca-GPT4-zh(1,000个样本),为DISC-MedLLM提供了多样性和广泛性。通过综合利用这些数据源,为DISC-MedLLM提供了多元化、高质量的训练数据,使其能够在医疗对话中表现出色。这个精心构建的数据集是DISC-MedLLM成功的关键支持,也确保了模型能够胜任多样性和复杂性的医疗场景。数据集已公开发布在Hugging Face,可以通过链接下载数据集:huggingface.co/datasets/Flmc/DISC-Med-SFT04 部署
DISC-MedLLM的当前版本基于Baichuan-13B-Base进行训练。可以直接从 Hugging Face上下载模型权重,或者根据开源的项目代码样例中的方式自动获取。
关注本公众号“极客开源”并在公众号后台回复MedLLM或医疗模型获取项目地址、公开数据集和模型权重地址,以及在线Demo。
1. 从GitHub上克隆项目到本地或指定环境。

2. 安装项目的依赖环境。

3. 利用Hugging
Face的transformers模块来进行推理。

4. 或者直接运行命令行Demo脚本。

5. 也提供了基于 streamlit 的网页版,运行命令如下:

需要说明的是,由于目前版本的 DISC-MedLLM 是以
Baichuan-13B 作为基座的,所以可以参考 Baichuan-13B 项目的介绍来进行 int8 或 int4 量化推理部署,使用模型量化可能会导致性能的下降。
05 微调可以使用与本项目数据集结构相同的数据对模型进行微调。训练代码也已经开源,项目的训练代码在 Firefly 的基础上进行了修改,使用了不同的数据结构和对话格式。在开始进行模型训练前检查 sft.json 中的设置。需要注意的是只提供了全参数微调的代码:
·
deepspeed --num_gpus={num_gpus} ./train/train.py --train_args_file ./train/train_args/sft.json
如果您想使用其他训练代码来微调当前项目开源的模型,可以尝试使用如下对话格式:
·
<\b><$user_token>content<$assistant_token>content<\s><$user_token>content ...
其中使用的
user_token 和 assistant_token 分别为 195 and 196,这和 Baichuan-13B-Chat 是相同的。
06 模型的评测在评估模型性能时,性能评估是从两个不同的视角进行的。
1. 模型被测试其在单一问答问题情境中的表现,包括其准确回答问题的能力。
2. 模型被评估其在多轮对话环境中的表现,具体涉及系统性问诊和问题解决的能力。
在单轮对话评测方面,一个基准测试数据集被构建,该数据集汇集了来自两个公开医疗数据源的多项选择问题,以便评估模型回答问题的准确性。
至于多轮对话评测,首先,高质量的诊疗对话案例被创建,然后 GPT-3.5
被扮演患者的角色,与模型扮演医生的角色进行对话。GPT-4 被用于评估每段对话的主动性、准确性、帮助性以及语言质量。
与此相关的测试数据集、各模型生成的对话内容,以及 GPT-4 提供的评分结果都可以在项目的 eval/ 目录下查阅。
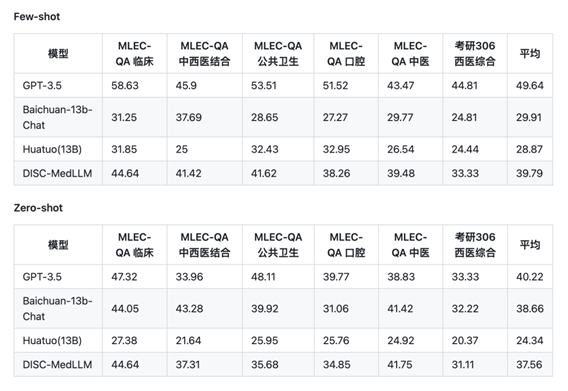
在单轮QA评测中,采用了MLEC-QA和考研306(西医综合)的单项选择题作为评估材料,结果如上图所示。
多轮对话能力评测基于三个不同的数据集:Chinese Medical Benchmark (CMB-Clin)、Chinese
Medical Dialogue Dataset (CMD) 和 Chinese Medical Intent
Dataset (CMID)。其中,CMB-Clin 模拟了现实世界的问诊过程,而 CMD 和 CMID 分别从科室专业性和用户意图的角度进行评估。
以下是关于CMB-Clin数据集的评测结果:
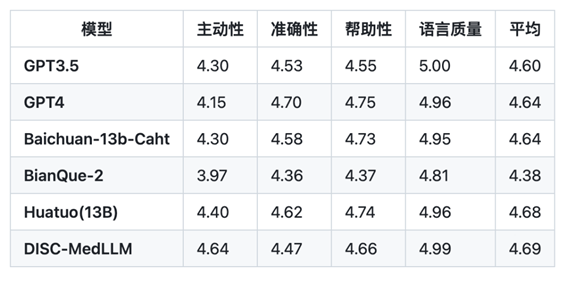
CMD数据集的评测结果:
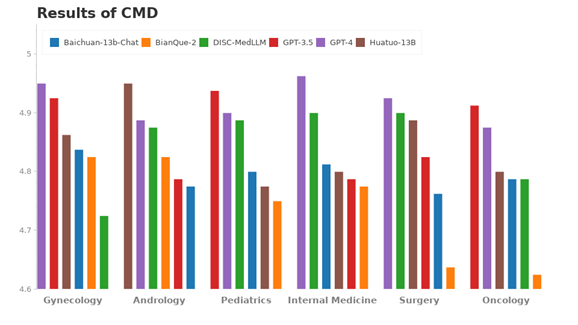
CMID数据集的评测结果:
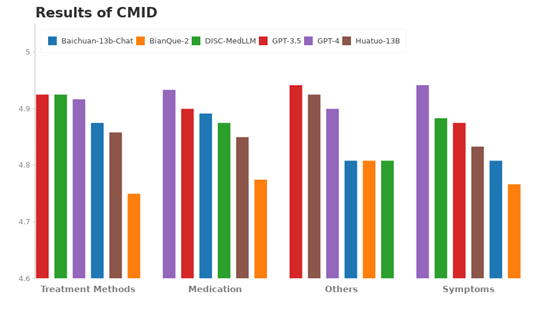
本项目给大家展示了大语言模型在医疗保健领域落地应用的可能性,但是也需要意识到语言模型固有的局限性。正如DISC团队在项目声明中说的:
由于语言模型固有的局限性,我们无法保证 DISC-MedLLM 模型所生成的信息的准确性或可靠性。该模型仅为个人和学术团体的研究和测试而设计。我们敦促用户以批判性的眼光对模型输出的任何信息或医疗建议进行评估,并且强烈建议不要盲目信任此类信息结果。我们不对因使用该模型所引发的任何问题、风险或不良后果承担责任。
出自:https://mp.weixin.qq.com/s/y5LQj5rDEO86p9uFMcHGBQ
Prisma是一款利用AI技术进行图像修改的工具。它可以将你的照片转化为各种艺术风格,包括印象派、后印象派、现代派等。