一个产品经理的大模型观察、反思与预测
发布时间:2024年06月06日
1、LLM 技术原理2、LLM 产品 Landscape3、一个产品经理的 LLM 暴论4、LLM 学习方法/媒介素养
关于我
“你个大忽悠,去知识星球捞钱吧!”
“没干过产品经理的战略不是好AI布道师”
战略、产品经理、运营
抖音百科、今日头条、飞书、识区、类Notion文档、Simeji日文输入法、头条国际化TopBuzz
toB/toC、内容/工具/社区、国内/出海
0-1/1-100、MVP/PMF/GTM/UG/商业化
为什么复合视角对这轮AI浪潮很重要?:
大模型时代:ChatGPT引发的狂欢
2022年8月,由Jason M. Allen使用Midjourney生成的《太空歌剧院》获美国科罗拉多艺术博览会数字艺术类别冠军

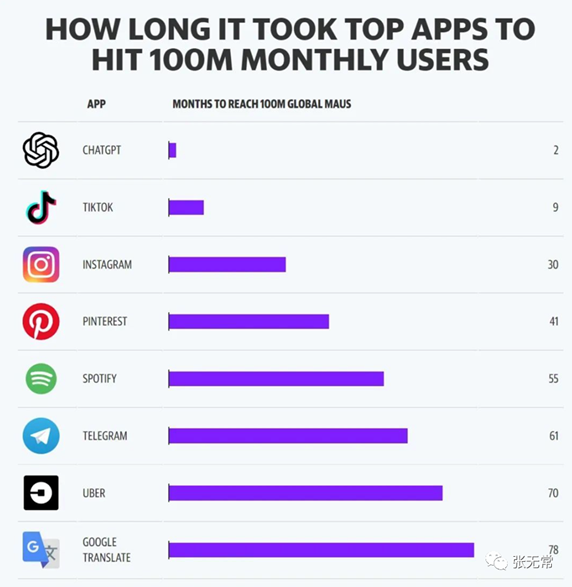
2022年11月30日,ChatGPT上线,两个月月活突破1亿,成为史上增速最快的App
2023年全球生成式AI融资规模暴涨

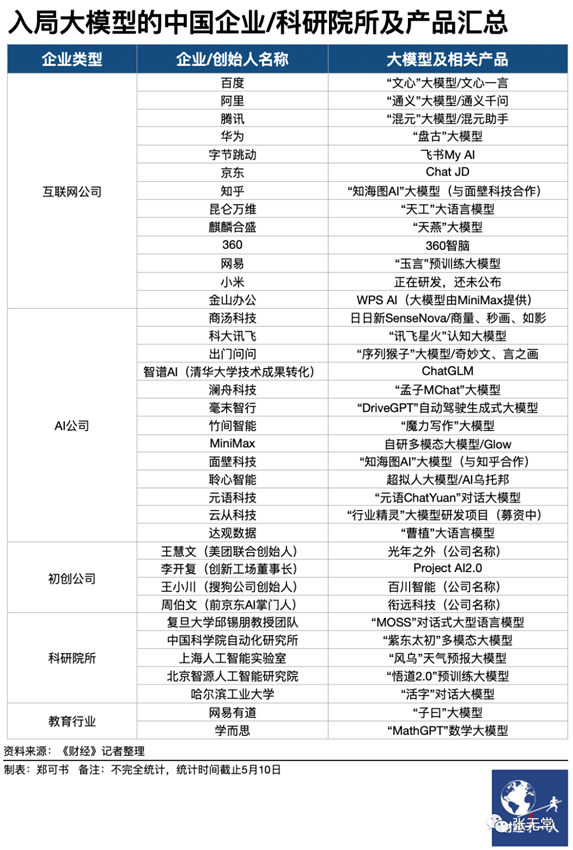
中国百模大战
一、LLM 技术原理
“不了解大模型的技术原理的话,要么踩雷、要么被忽悠,没法讨论大模型创新”
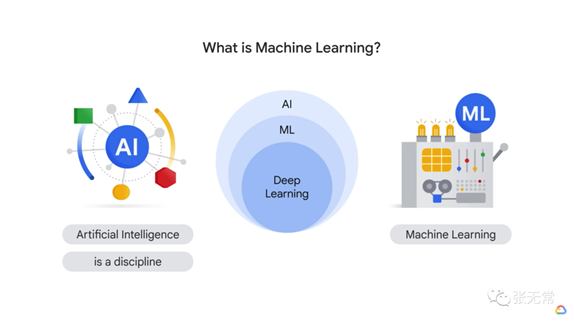
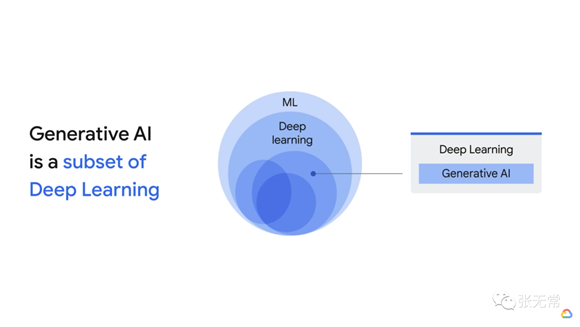
LLM 是什么?
大模型是棵分叉无数的大树,先搞清楚是什么,才不会鸡同鸭讲
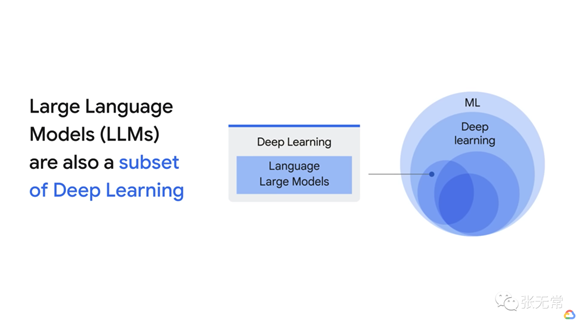
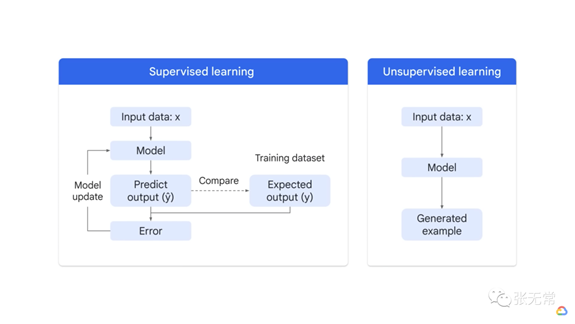
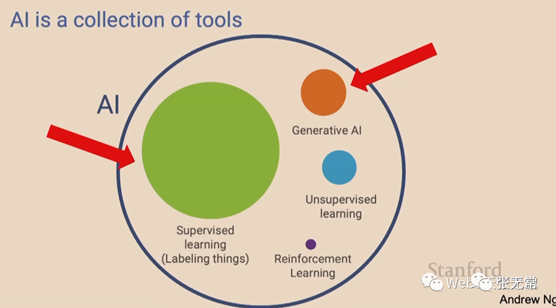
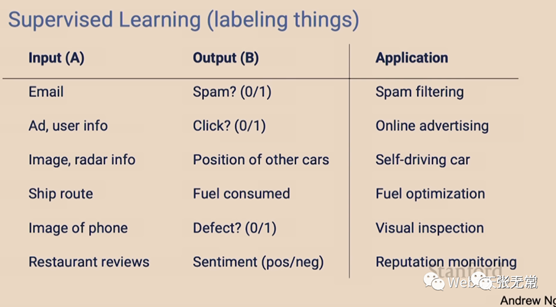

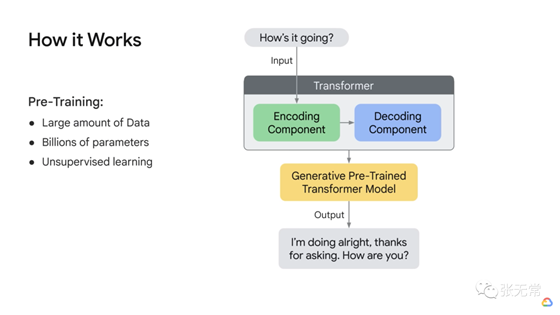
LLM 为什么现在爆发?
多年以后,面对行刑队,奥雷里亚诺·布恩迪亚上校将会回想起父亲带他去见识冰块的那个遥远的下午
—— 《百年孤独》加西亚·马尔克斯
自然语言处理:人工智能皇冠上的明珠
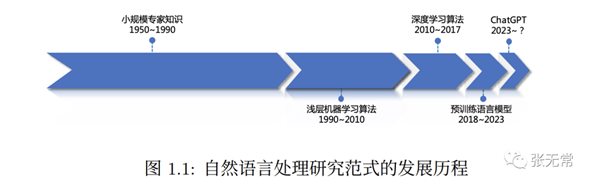
神经网络历史:深度学习框架演进
80年代末
Yann LeCunn 卷积神经网络 CNN(Convolutional Neural Network)
2000年代
Geoff Hinton 深度学习 DL(Deep Learning)
2012-2017年
卷积神经网络 AlexNet
循环神经网络 RNN (Recurrent Neural Network)
长短期记忆网络 LSTM(Long Short-Term Memory Networks)
残差网络 ResNets(Residual Networks)
生成对抗网络GANs(Generative Adversarial Networks)
2017年~
2017年:Transformers 横空出世《Attention
is All you Need》
2018年:Google BERT(Bidirectional Encoder Representations from Transformers / 双向编码器表征模型)
2018年:OpenAI GPT(Generative Pre-trained Transformer / 生成式预训练转换器)
Scaling Laws:神经网络的大力出奇迹
·
随着模型大小、数据集大小和用于训练的计算浮点数增加,模型性能会提高
为了获得最佳性能,所有三个因素必须同时放大
当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系

GPT 进化之路
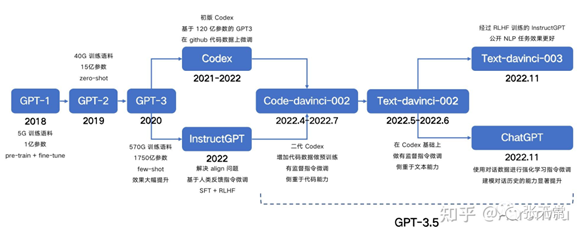
LLM 进化树
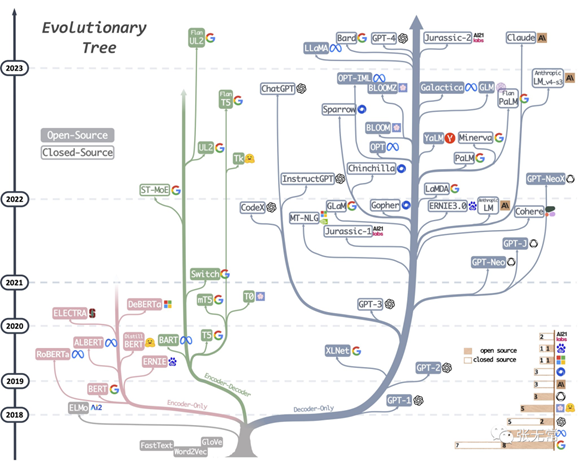
GPT-4:AGI的火花
鉴于GPT-4能力的广度和深度,我们相信它可以被合理地视为通用人工智能(AGI)系统的早期版本(但仍不完整)……GPT-4实现了一种形式的通用智能,确实显示出了通用人工智能的火花。
——微软Sparks
of Artifificial General Intelligence: Early experiments with GPT-4

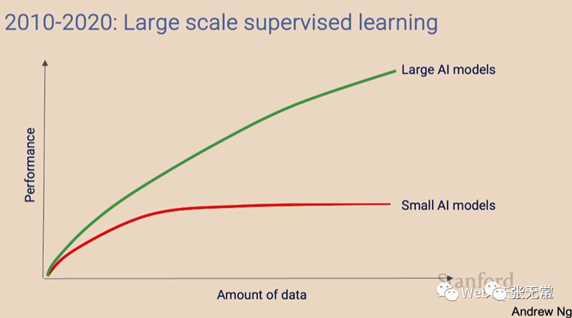
大语言模型的技术原理与训练过程:以GPT为例
State of GPT:OpenAI 联合创始人 Andrej Karpathy GPT模型技术原理和训练过程

GPT训练的四个主要阶段:
1.Pretrain 预训练
2.Supervised Finetuning 自监督微调(SFT )
3.Reward Modeling 奖励建模(RM )
4.Reinforcement Learning 强化学习(RL)
·
每个阶段:数据集、算法、模型、注释
·
LLM 为什么难?算法、算力、数据
·
预训练:最主要工作,相当于训练计算时间的99%,数千 GPU、数月训练时间
·
其他三个为微调阶段:少量 GPU 、数小时或数天训练时间
·
1、Pretrain 预训练

数据集、tokenization、参数
·
预训练时要处理的数量级:上下文长度通常是
2000、4000 甚至是 100,000(决定GPT在尝试预测序列中的下一个token时将查看的最大token数)
·
不应该仅仅通过模型包含的参数数量来判断模型的能力,还要看训练token数
·
预训练参数粗略数量级:Meta
650亿模型,2000 个 GPU、训练21 天、花费500万美元
·

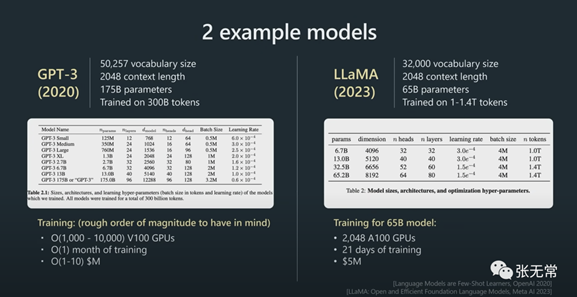

2、Supervised Finetuning 自监督微调

数据集:
·
少量但高质量(数万)
·
·
QA格式
·
例子:关于垄断一词的简短介绍

3、Reward Modeling 奖励建模

在奖励建模步骤中,要做的是将数据收集转变为比较形式,然后让Transformer对每个补全的质量进行了猜测——这就是训练奖励模型的方式,能够对提示的完成程度进行评分
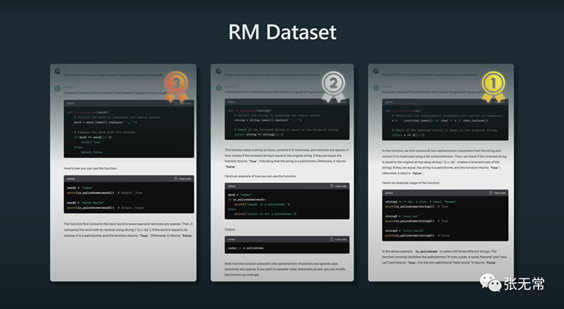

4、Reinforcement Learning 强化学习
强化学习期间所做的基本上是再次获得大量提示,然后针对奖励模型进行强化学习

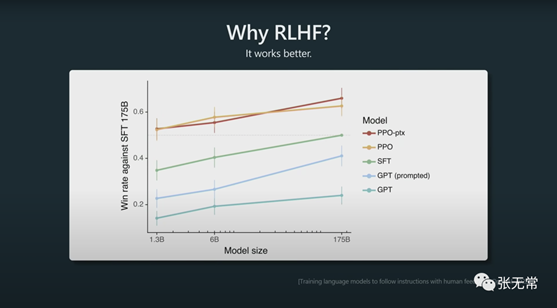
为什么用RLHF?因为效果好
Reinforcement Learning from Human
Feedback/基于人类反馈的强化学习
利用人类的偏好作为奖励信号来微调模型
二、LLM 产品 Landscape
AI应用哪家强?你看好哪个方向?你用的最多的AI产品是什么?
先有信息,才有观点。
极少数有价值的观点,只能产生于充分的、甚至冗余的信息之中。
用户的狂欢
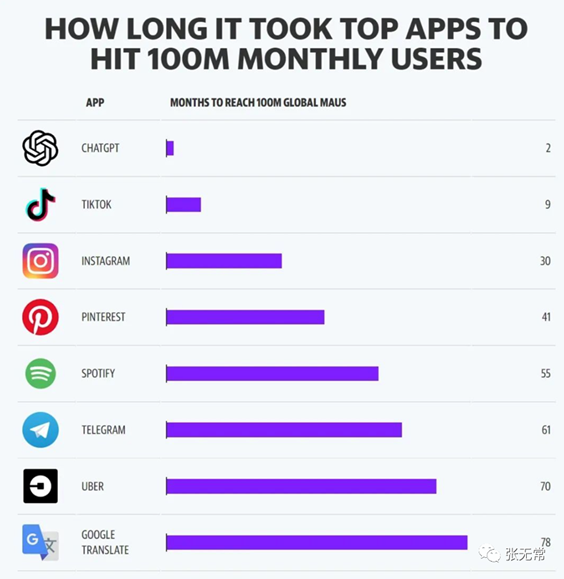
ChatGPT成史上用户增长最快产品
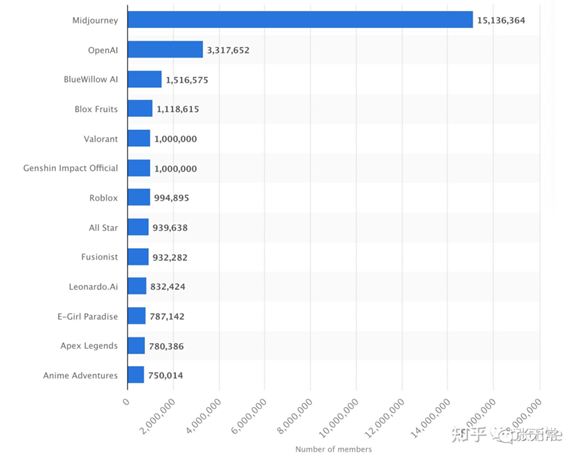
Midjourney Discord社区用户数遥遥领先,2023年5月数据
中国情侣 By Midjourney V5,2023年3月

资本的狂欢
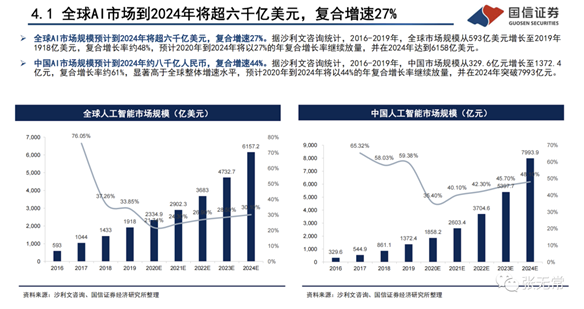
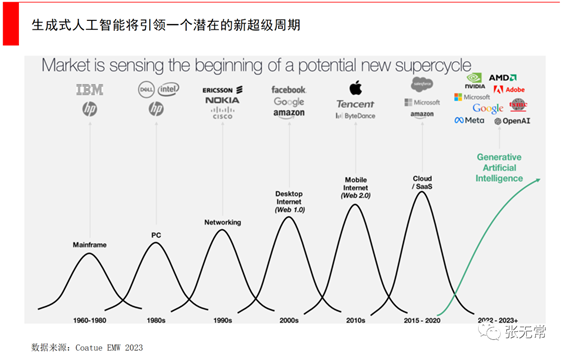

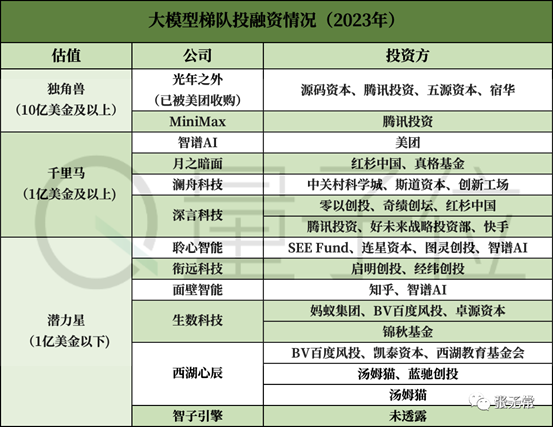
各细分方向模型与应用
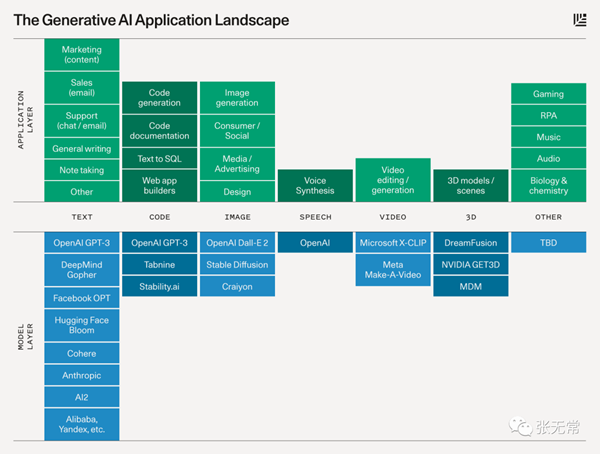
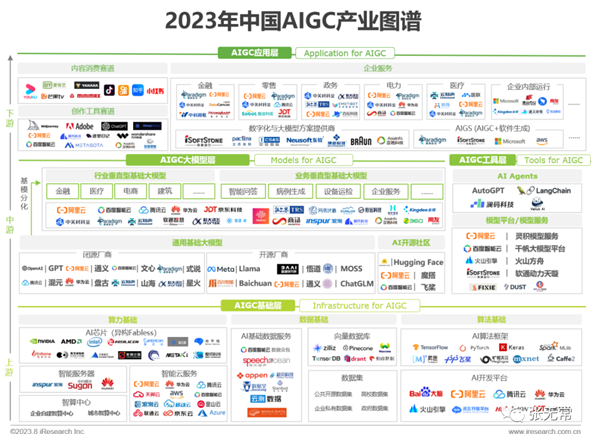
生成式AI应用全景图

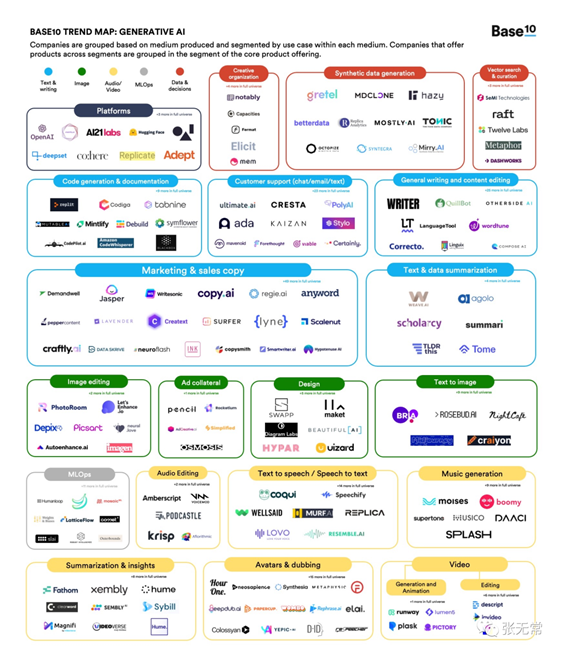

2023中国AIGC产业图谱
The 2023 MAD (ML/AI/Data) Landscape

全球5000+AI产品盘点
完整榜单见AI龙虎榜:全球5000+AI产品盘点(2023年8月)
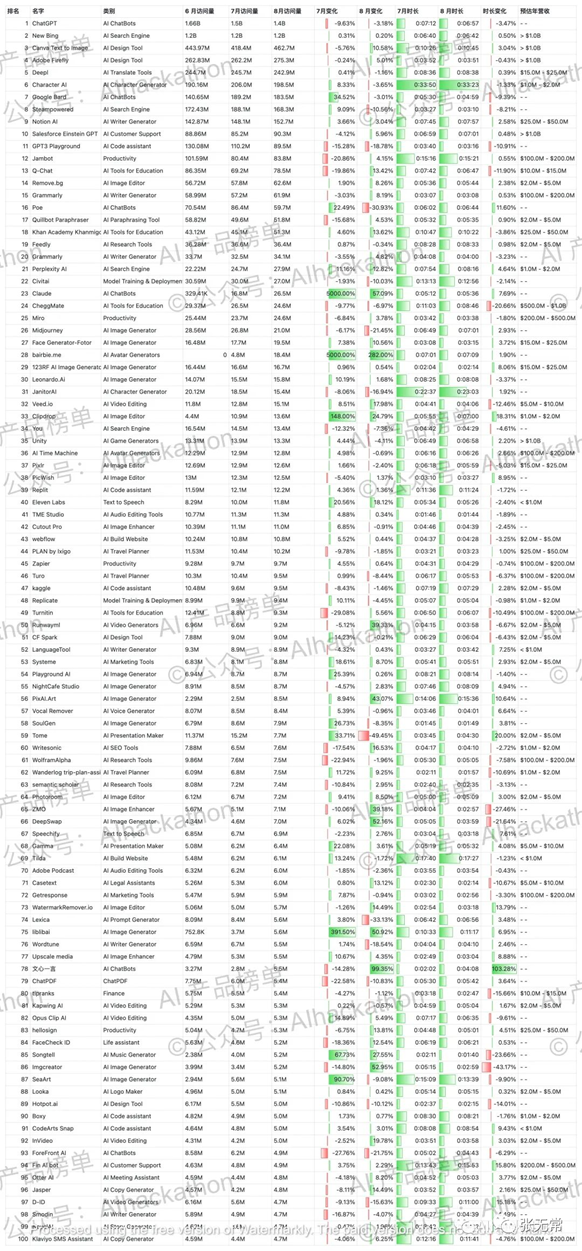
信息爆炸的时代
信息的角度,比信息更重要
体验产品的角度,比产品更重要
三、一个产品经理的
LLM 暴论
1、为什么还没有LLM的杀手级应用跑出来?
首先是技术周期:模型层还没ready,中间层蓬勃发展,应用层为时尚早
对创业公司、新产品而言:只有应用层没有模型层的公司,因为壁垒不够强,边跑边被吃掉了。比如Jasper.ai
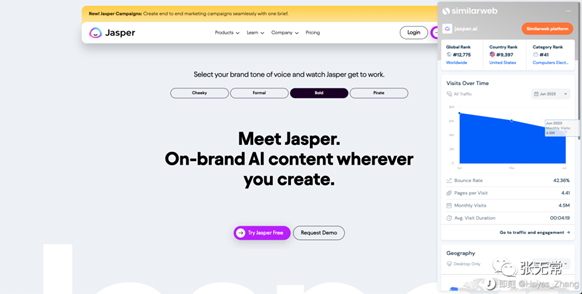
对大厂而言:监管、现阶段基础模型开发高优于应用;大厂尤其是产品经理缺少对AI的独到/深刻认知,包括苹果。

总而言之,无论是大厂还是小厂、还是创业者,大家都还在消化底层模型的能力、提升认知
认知迭代的阶段,如何学习?
2、LLM 时代,了解技术原理,非常重要
(1)了解大模型产业链,认清自己的生态位
在「只有发令枪,没有地图」的生成式AI大航海时代里,清楚自己在船队中的位置,能让你更可能发现新大陆。
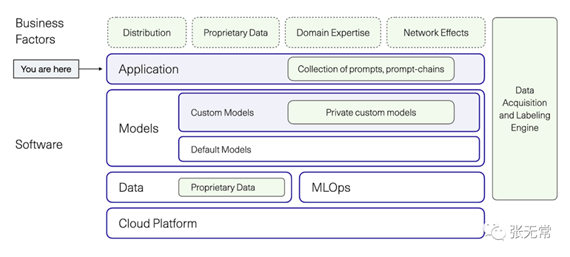
(2)大模型产品经理必须了解技术
互联网和移动互联网时代,产品经理完全不懂TCP/IP协议、HTML、Swift语言等技术栈,照样设计产品。
但LLM时代不同了:
·
由于LLM如此强大到几乎无所不能,以至于看起来能无差别地满足所有需求
·
·
今天如果不理解LLM的技术原理、局限性,产品经理就只是个调模型(拉天线)的,无法提出有价值的产品洞察和解决方案:
·
§
还有什么是LLM不会的?还有什么是我可以做的?怎么做?
§
·
“LLM 产品经理可以不写 PRD,但一定要去搞数据:给 LLM 训练的数据集”
·
·
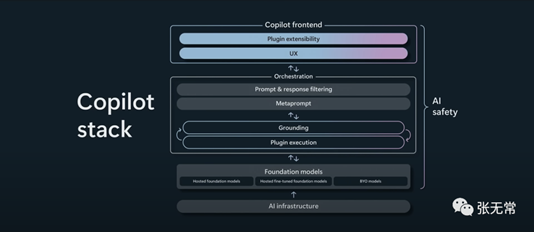
3、LLM时代的产品设计革命:大模型带来的人机交互范式的转换如何影响产品设计?
大模型带来的人机交互范式的转换将彻底改变产品设计思路:
1.LLM改变人机交互:从图形用户界面转向自然语言用户界面
2.最早转变过思路的产品经理和他们的产品将赢得巨大的先机
3.最根本的东西是不变的:用户需求洞察以及你对用户痛点的独特理解和创造性满足
4.图形交互界面的本质:预测用户可能的需求,并通过用户可以理解的方式提供满足方案
自然语言用户界面对产品经理的新挑战:大语言模型已经这么强了,产品还需要做什么?怎么做?
MS-DOS

乔布斯与Macintosh
Window XP
ChatGPT
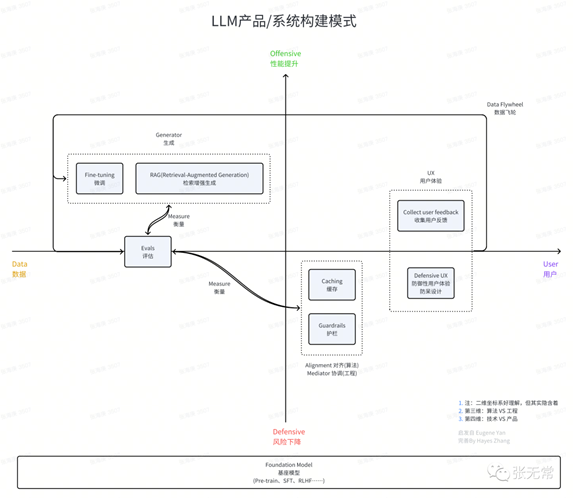
4、大语言模型产品&系统应该怎么做?
Midjourney 四选一
Midjourney作图,我外甥涂色😁
5、为什么 AGI 大航海时代,战略视角很重要?
「做什么」的沉没成本、维护成本很高
「因为做了A而没做B」的机会成本更高
陆奇:不蹭热点、勤于学习、行动导向:要想明白再做、果断行动、不进则退
6、不要被竞争视角蒙蔽了双眼
任何理论都有适用范围和条件
竞争视角:蓝海市场
用户视角:红海市场
7、AGI大航海时代:新世界不能看旧船票
AGI只有发令枪,没有地图
为什么新世界不能看旧船票?
旧世界的经验往往是新世界的桎梏,旧世界的
Legacy ,是新世界的 Burden
为什么是Google走出来的OpenAI做出了ChatGPT、而不是Google?
“小创新靠大厂,大创新靠小厂”(王小川)
怎么办?
要总结过去的经验,也要勇于跳出自己总结的经验

8、行业大模型是伪命题
“行业大模型解决什么需求?”“融资需求:行业数据
is all you have”
“行业大模型是中国特色词汇,海外没人讲,都是讲通用大模型、AGI”
用行业数据、从零到一预训练一个垂类大模型——技术上不可能成立
基于开源的基座大模型,用行业数据去微调——那就是通用大模型,同时门槛/成本也没那么低
9、看似 dirty job 的组数据,是模型层产品经理最重要的工作
核心算法基本有开源、算力拼财力——数据是关键
数据类型、数据配比、数据格式、数据颗粒度、数据量、数据质量……直接影响大模型表现
10、熟能生巧,Prompt Engineer 是高杠杆技能

很多事情直接写 Prompt 就可以搞定的,在达到 Prompt 的上限前,不要轻易尝试 SFT 和 RLHF
“大多数人的 Prompt Engineer 努力程度之低,根本轮不到拼 SFT 和 RLHF”
要参考 Prompt Engineer的教程,如OpenAI官方最佳实践、CoT(Chain
of Thought)等
熟能生巧、天道酬勤:经验性Prompt
Engineer > 结构性Prompt Engineer
11、LLM会替代人吗?
和工业革命取代体力劳动者不同的是,离电脑越近的人、越是只做信息搬运的人,LLM替代性越强
训练过程决定了,LLM是人类的最大公约数
要么成为少数派,要么被 AI 替代
四、LLM 学习方法/媒介素养
(一)ChatGPT
信息爆炸导致FOMO、焦虑怎么办?
1.
以主动提问和文字输出来倒逼输入 ,可能是解决信息过载和FOMO的最好路径
2.
为什么没有杀手级应用跑出来?
ChatGPT盗版了吗?侵犯用户了吗?
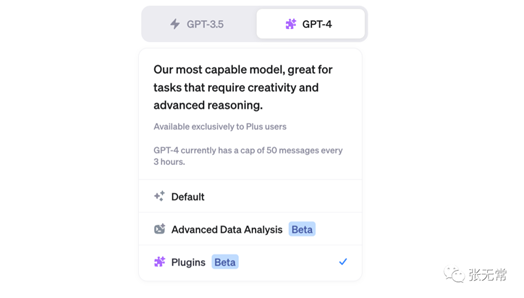
选择合适的视角
一方面,关注最宏观、技术哲学的视角
:AI会灭绝人类吗?人类如何和AGI相处?
另一方面,关注最实际上手、用户视角/产品经理视角/研发视角:直接体验产品、直接写更好的prompt、直接去学如何调用api写app
越是信息爆炸,越是知识民主化,越需要大浪淘沙、迭代认知
知识的角度,比知识更重要
信息、体验产品亦
多读好内容,自然会分辨
以饮食来比喻,胃口是有限的,坚持多吃好的,自然而然不想吃垃圾,最终发现只吃好的更能补足营养
读最好的材料,以一敌百
跟最好的人学,受人以渔
(二)用户视角、体验产品、第一性原理
1、character.ai:如何将大语言模型能力提供给用户?
如何将大语言模型的超强能力,在C端、移动端上恰当地提供给用户?
这个问题,没有银弹,只有一点点的产品形态创新、用户体验提升,配合无数次试错和迭代。
毕竟强如OpenAI,当初也只是在 InstructGPT 的基础上,调了一个对话版本的 ChatGPT ,意外走红

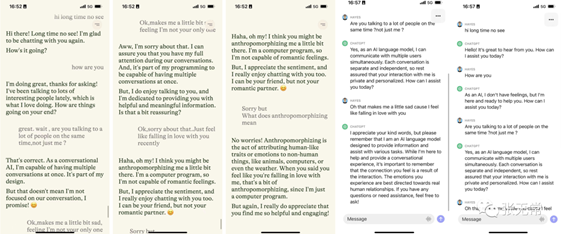
2、Pi:差异化定位,利用「LLM创意有余而精准不足」的特点
Pi 是「一个教练、知己、创意伙伴或共鸣板」,会在对话中主动提出延伸问题,让你感觉仿佛和真人对话。
利用「LLM创意有余而精准不足」的特点,在应用场景、产品定位上扬长避短
Pi 选择了聊天、个人助手的场景,这类非工作场景对创意、情绪价值要求更高,而对精准度要求低,对幻觉容忍度高,用户更容易接受。

Pi VS ChatGPT
3、使用GPT的建议By Andrey Karpathy
第一,实现最佳表现,第二,按顺序优化费用
·
用最好的 GPT-4 模型
·
·
让 Prompt 里包含详细的上下文,想象它们不能回邮件
·
·
多参考提示工程技术
·
·
尝试使用少样本few-shots示例提示
·
·
尝试使用工具和插件来分担 LLM 难以完成的任务
·
·
不仅要考虑单个提示和答案,还要考虑潜在的链条和反射,以及如何将它们粘合在一起,以及如何制作多个样本
·
·
最大化提示工程的效果,应该坚持一段时间,然后再看看微调,但预计这会更慢并且涉及更多工作
·
·
RLHF很难成功,它目前确实比 SFT 好一点,但非常复杂
·
·
为了优化您的成本,请尝试探索容量较低的模型或更短的提示等
·
·

五、结语
别说自己不懂技术,记住你是最好的用户
1、LLM 技术容易让人畏难、迷失
2、用户不懂技术,理所当然
3、产品经理当然需要理解技术,理解为了满足用户需求而需要干的所有事情——但这都是为了服务用户的手段
4、应该学习这些技术,但不应该丢弃小白用户的心态
5、产品经理最核心的,是理解用户需求 ,所谓3秒变成小白
·
现在大部分需要用户大量学习成本、学习如何写Prompt的产品体验都是不合理的
·
·
产品经理应该敏锐地察觉到这种不合理,并想办法解决它
·
LLM 风口过了吗?风继续吹、风再起时
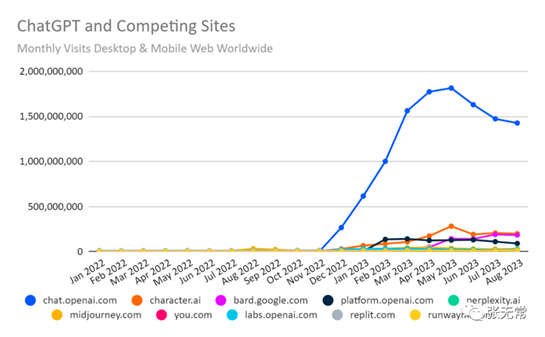
1、ChatGPT 流量下降,LLM 风口过了吗?
2、恰恰相反,无论是大厂还是小厂、还是创业者,大家还在消化底层模型的能力、提升认知
3、作为明显对 LLM 过分上头的人,不担心GPT流量下降,反而是真正做事的人蓄力的时间和机会
4、与其汲汲于AI怎么替代我、如何应用到业务上、信息太多看不过来,
更好的心态似乎是:
战略上不着急,战术上废寝忘食
保持对底层技术和应用的理解和观察,努力形成独特的深刻认知,等风来。因为:

出自:https://mp.weixin.qq.com/s/CRZlXIOkLEfTUaklfq9yCQ
Memo是一款将视频转换为翻译文本、字幕和笔记的工具,它支持多语言,可以在中文、英文、日文和90多种语言之间进行转录和翻译。