快消品企业怎么才能用上大语言模型?
发布时间:2024年06月06日
以ChatGPT为起点,大语言模型(LLM)用全面的技术创新,以及在用户和产业中的应用落地,再次掀起了一个AI新浪潮。
与它的前辈们相比,大语言模型因为打通了语言这一人类沟通中介,并且仅用一个模型统一了多种复杂的任务,在对个人和公司的潜在影响力上明显更上一层楼。受到“再不努力就要被机器,或者是会用机器的人取代”趋势的威胁,越来越多中国企业开始下定决心要投身到新的AI热潮中去。
但当他们站上起跑线,只会发现事情并没有那么简单,甚至有点让人迷茫。
AI新浪潮,倒逼企业重塑数字化底座
造成企业“想说爱你不容易”的关键,主要有两点:
1、波及面太广:相比过往数次技术革命,大语言模型影响力和范围更大,渗透到企业运转、经营的多个环节,并与人类工作流程相互交织;
2、倒逼企业重塑数字底座:大语言模型在运行逻辑上不同于互联网时代,且需要企业有相当坚实的数字底座。如果企业自身数字化基础不足,前期准备和调整环节将非常有挑战。
以具体的数字为例,据研究发现,自然语言任务占到了企业人员工作总时长的62%,其中65%的时间可以借助人员强化和自动化技术来提升工作活动的生产力。
将这两个数字直接相乘,就能得到一个简单而又直白的结论——所有行业中40%的工作时间,都能通过GPT-4这样的大语言模型实现革新。
这个数字听起来或许有些夸张,我们不妨具体到特定的产业中来看。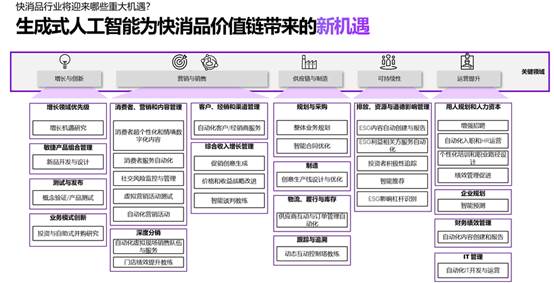
大语言模型能够在产业链中应用的环节实在太多。从最基础的需求确立、产品打造、商业模式创新,到具体的市场营销,再到后续的供应链和制造管理、可持续发展以及企业内部的管理,基本上覆盖了所有的环节。
从企业和产业竞争的视角看,尤其是快消品这样互相快速模仿借鉴、竞争激烈的产业,大语言模型的应用,正在以一个全新的维度为企业带来新的竞争力。
在埃森哲最近的一项技术趋势调研中,72%的受访中国企业高管对AI新能力表示了极大的兴趣,并将在后续的企业经营中积极探索和尝试这项新技术。
确定了“要做”,接下来的问题是“怎么做”。而这恰恰是大语言模型技术的最大挑战所在。
对于本身数字底座相当充分的企业来说,探索AI新技术的应用能力、如何将自己的业务和内部运行模块与AI技术结合,是一个非常烦琐的任务。就拿我们上面提到的“倒逼企业重塑数字底座”为例,过去互联网时代的“人工编写代码+数据库”的模式,正在遭受“模糊数据+神经网络模型”的挑战。企业在需要用大语言模型全面提升自身应用和服务能力的同时,也需要开始着手收集还未数字化的企业信息和知识积累,并将他们整理为神经网络能够理解吸收或者学习的格式、作为企业专属模型的数据输入。
而在企业内部员工的培训上,大语言模型相关的内容也正在成为刚需,尤其是员工日常使用大语言模型过程中的prompt(提示词)技巧。“光是应用云计算、真正实现数字化这一点,对于很多中国企业来说就已经是革命性的了。现如今任务中多了AI,变革的压力和难度其实变得更高。”
根据中国电子技术标准化研究院2022年的研究,占据了中国企业绝对主体的中小企业,79%处于数字化转型初步探索阶段,12%处于应用践行阶段,真正达到深度应用阶段的企业仅占9%。
很显然,大量中国企业急切需要充分理解了AI发展趋势、拥有打造企业数字化底座的解决方案、和拥有丰富企业服务经验的“帮手”来拉一把。
正如我们上文所分析的,大语言模型的场景覆盖各行各业的诸多环节,这也让其应用和落地无法一概而论,整体体现为高度的非标准化,“边摸索、边创新、边落地”成为了当下的解决思路。
我们将这种“边摸索、边创新、边落地”定义为六个步骤:
以业务驱动的初心:以积极的心态全身心拥抱变革,将业务需求和目标作为驱动力,迅速行动。
以人为本的方式:在解决问题和开展工作时,将关注点放在人的需求和体验上,确保以人为中心的方法来处理事务。
准备好企业的专有数据:整理和准备企业拥有的独特数据资源,为后续的生成式AI的使用和决策提供必要的数据支持。
投资于可持续的技术基础:在技术方面进行投资,建立一个稳固可持续的基础设施,以支持长期的生成式AI的业务需求和创新。
加速生态系统创新:推动生态系统内的创新,加快不同组织、合作伙伴之间的创新合作,实现更快的发展和增长。
提升企业的负责任人工智能水平:进一步提升人工智能技术的水平,注重负责任的使用和开发,确保生成式AI的影响是积极和可控的。
具体步骤看起来不复杂,但实际每个步骤操作中,都有很多“Know-How”(经验诀窍)存在。
就拿“投资于可持续的技术基础 ”来说,在互联网和移动互联网时代,虽然每家云供应商的整体技术架构有所不同,但是其技术原理和能力大多是相同的。而现如今的大语言模型能力,都能够通过神经网络实现知识的输入和输出,但是不同厂商大语言模型的最终结果有所差别,因此如何选定合适的生成式模型并以此为基础构建可持续的生成式AI技术能力,成为了一个关键课题。
另一个是潜藏在“ 准备企业的专有数据 ”环节背后的数据安全问题,AI大语言模型在完成自然语言预训练的基础上,需要进一步结合应用场景的特定数据,才能够实现能力的特化。在企业应用视角中,就是需要大量的企业真实数据、知识,其中往往会存在涉及商业机密的内容。
现在有很多企业会直接禁止员工使用公开的大语言模型,就是担心他们在处理公司任务的过程中,将企业的数据泄露出去。如何确保在推广大语言模型的过程中,确保自身企业数据的安全,是一个必须解决的难题。
面对这些挑战,在AI新技术探索上足够前沿,同时又兼具安全的本地化部署方式,就体现出了明显的优势。
客观来看,目前国内哪怕最先开始尝试应用大语言模型的先锋企业,现在仍然还在比较前期、研究怎么将企业数据、经营流程与大语言模型技术进行契合的阶段。
针对大语言模型技术在具体业务场景中的应用范式,国内的很多云服务商和创业公司仍在持续技术创新的过程中。但先行起跑、在行业中抢先推行技术变革、做好数据收集和准备,必然能在将来大语言模型最终落地时,获得先手优势。
使用PixelForce,解锁商拍视野,释放产品魅力。告别模特、摄影、后期制作、现场租赁,甚至是昂贵设备的限制。