大模型再发展5年,搜索引擎还在么?
发布时间:2024年06月06日
大模型既是内容的生成器也是信息的过滤器,而搜索只是信息的过滤器,那发展下去搜索引擎这个自互联网发生以来就存在的产品会受到什么影响?
被动摇的搜索根基
想象一个中期场景:假如一半以上的内容是人工智能体在生产和消费,那搜索引擎会怎么样?
原始意义的搜索引擎会消失,名实具亡。
因为搜索最基础的机制会被动摇,并逐渐失效。
搜索引擎从产品上看并不复杂,就是要在海量信息中快速找到你需要信息的工具。而判断是不是你需要的信息就在于PageRank等算法,这些算法依赖链接数和质量等判断内容的权重,再依赖关键字来判断匹配度。
现在这两点正好都会出问题。
链接可能不是真的链接,而关键字对应的内容可能是人工智能生成的内容。人工智能生成的内容增长速度一定远大于人生成的内容,而这部分内容并没谱,是带着我们经常说的幻觉所生成的内容。假如互联网上的内容一共是十,如果这部分内容的比例超过五,那搜索要面对的就是概率在50%以上的一个虚拟世界反馈出的结果。不管你怎么用算法来排序,也规避不了这种失真和不准的问题。可以想象一个极端情况,就是全网50%的内容都和一个人工智能生成的内容发生链接,那按照搜索的机制,无疑的这是应该被排到前面的,而则可能是不对的,它不一定质量很好,而只可能是被用其它模型生成内容用的多。
这进一步意味着信息精度的责任方在转移,过去是搜索引擎负责从已有内容中尽可能过滤出有价值的信息,而如果这套机制失灵,那就变成大模型在信息生成的同时需要扮演信息质量保证者的角色。模型自身决定了信息的精度。
不局限于搜索引擎
这显然不局限于搜索引擎,过去我们一共有两种主要信息集散方法:
一种就是上面说的搜索引擎,一种则是在头条和抖音上广泛被应用的个性化推荐。
而如果大模型在内容源上占据统治性,超过50%,那依赖于个性化推荐的产品同样会受到冲击。不过冲击的表现形式会有所不同。
国内几个个性化推荐平台,通常和UGC相关,这样一来,首先冲击的是内容生成端。
如果把大模型的内容生产水平画一条线,那这条线以下的生产能力,没有存在的基础,会很快的被淹没。而在这条线上面的除非有明确的标识度,比如你在社会上是个名人,否则也会被淹没。
而如果是大模型对大模型(都基于大模型进行生产),那数据量则会飞涨。
内容膨胀之后,很可能流量分布上会两个趋势同时发生:一个是中心节点会有更大的增长量,一个则是一般的流量会被摊的更加稀薄,也就是上面说的一般人会更容易被淹没。
像更加靠谱的中心节点集中是因为不知道别的信息是对是错,只能借助于传统的社会体系的筛选,一般的流量更加分散则是因为内容过多,流量还是那么多,内容变多,那平均下来肯定更加稀薄。
这就会产生一个流量的鸿沟。

跨越流量鸿沟可能比现在更为困难,而在此之前拿到的流量可能会变的更加值钱。
与此同时,另一个附带效果可能是UGC平台利润空间会下降,因为信息的总价值并不会因为因为量的增加而增加,但它的处理成本却会因此而上升。信息量增加后,不管存储还是计算成本都会增加。
怎么办?
怎么办里面最原点的选择是不用(比如禁止大模型使用),但这显然不靠谱。
不同的学校对此也采取过不同的态度,有的学校是完全禁绝大模型在做作业等环节的应用;有的学校则非常开放,全面接受。
但这事其实不难选择,因为我们好像又回到了大禹和他爹的选择
未来的现实是大模型会成为工作生活的底座和外壳,在它之上每个人都会变成现实版的钢铁侠。
你可以选择不穿,那你力量就弱。既然如此,那显然不能禁止,只能比谁用的更好,否则就和清朝禁海差不多。
关键是要在面对的同时处理它潜在的负向结果。
最典型办法就是唯一性身份认证。唯一性身份认证能够降低一部分纯粹机器人的内容生产,但没办法避免每个内容生产者都变成超级英雄一样超高速进行内容生产。
次一级的方法则是模型对模型。我们确实需要清楚的认识到因为信息的暴涨,最终只有模型才可能处理模型相关的事务。但即使把模型渗透到审核等环节,模型对模型也只能降低的太差的水货,或者说明显在认知错误。模型生产出来的真的质量上乘的作品是没办法的,也不应该被禁止。但不管结果如何,模型要肩负起信息生成和分发的责任是确定的。
从这个角度再递进一步,到每个人具体的生活体验,也会发生变化。因为信息的膨胀个人已经失去了自我筛选信息的能力(看报纸的时候基本是自我进行信息筛选),所以这时候助理会履行这个职责,别看过去的小爱同学等又呆又傻,但到后面它还是会变得越来越不可或缺。助理首先冲击搜索,相当于在搜索上又套了个壳,推荐由于本质上相当于是助理在后台进行推送,影响还在搜索之后,比如个人助理怎么和推荐进行交互一样是需要解决的问题。
但影响还不止于此。
奇点曲线的新解
全面拥抱大模型等马上就带来一个新的后果。
我们都知道当年奇点临近里画了一条指数曲线,但这条曲线的含义却很少被进一步解读。
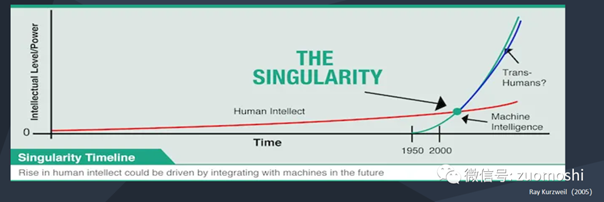
当社会的变化和智能是指数型向上的时候,比如GDP增长,那意味着企业或者个人的事业必须是指数向上,否则就会被甩下来。道理很简单,如果平均GDP增长是10%,一个企业的增长则是5%,那大概率它会破产,而一个人的收入增长如果是5%,那很可能他会变的相对贫困。
而人的部分是不可能做出指数型增长的,所以能够匹配高速增长且不掉落,就只可能是基于大模型等技术的组织和个人。这是一种碳基智能和硅基智能找到合适边界的复合体。从这个角度看大模型确实也只能被拥抱,而不可能被规避。
回到我们文章题目的设问,从这个角度看,现在形态的搜索可能五年到十年后就真的不在了。因为当下搜索这种信息分发方式太不智能了,智能越翻倍,这种初级的信息分发方式就显的越落后和不精准。
小结
在寻找智能飞轮:从数据枯竭到多模态再到自生成里,我们提到过这样一个观点:企业里的场景和任务,其实是在封闭和开放之间连续的,比如总是既有外卖小哥这类工作,也有CEO的工作,前者就封闭后者就开放。然后不同的企业里不同类型的工作配比不一样,比如工厂里或者清洁公司就封闭度高,大学可能就开放度高。如果面向未来的话,那显然要加一点,硅基的人工智能和碳基的人类所对应的整体智能配比也不同,这会变成未来组织的一个关键特征。
一个由AI驱动提供在线和本地音频内容的转录、摘要和问答服务的平台,包括YouTube视频。Alphy帮助用户快速高效地从音频和音频视听媒体中提取有价值的信息。