Prompt工程如此强大,我们还需要模型训练吗?
发布时间:2024年06月06日
.1.Fine tune成本高,而且看起来影响模型zero shot或者通用领域方面的能力,所以看起来现在有很大的趋势都是更多利用提示词工程。
.2.对于新信息,模型也能很好地跟搜索引擎结合,将新信息整合在prompt中让模型来回答,这种方法是否有局限?
.3.如果我们还需要模型训练,例如在GPT3基础上把21年以后的数据喂进去,其中学到的新信息与prompt里学到的信息有没有本质区别?
.4.是否可以区分概念逻辑类知识与事实记录,后者可以通过模型外部的文档来提供,而模型只要学“核心知识”即可?类似于稀疏的知识放在外围存储(也更高效),模型只做稠密的推理处理。
.5.人类在模型能力之上发挥增量价值,是否就是集中在更加抽象的概念和逻辑、规律、联结这类“核心知识”的生成?
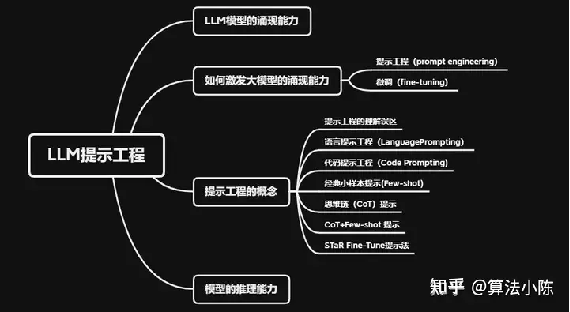
一、目前情况
在GPT没有爆火之前,一直以来的共识都是:模型的规模越大,模型在下游任务上的能力越多、越强。LLM原始训练目标是为了生成自然、连贯的文本,因为其本身接受了大量的文本进行预训练,因此根据提示补全和创造文本就是模型的原生能力。
在原生能力范畴下,LLM模型具备文本创造能力,如写小说、新闻、诗歌,GPT-3模型最早是被用来做这些事情的。
不过,仅仅能进行文本创造,并不足以让大语言模型掀起新的一轮技术革命,引爆这一轮技术革命的真正原因是:大语言模型的涌现能力
人们真正看好大语言模型技术的根本在于当模型足够大(参数足够大&训练数据足够多)时模型展示出了“涌现能力”。
随着不断有新的模型的提出,大规模的语言模型出现了很多超乎研究者意料的能力。针对这些在小模型上没有出现,但是在大模型上出现的不可预测的能力,就被称为涌现能力,在 Jason Wei 等人的研究中给出如下定义:
在小模型中没有表现出来,但是在大模型中变现出来的能力(An
ability is emergent if it is not present in smaller models but is present in
larger models.)。
换句话说:所谓涌现能力(EmergentCapabilities),指的是模型在没有针对特定任务进行训练的情况下,仍然能够在合理提示下处理这些任务的能力,有时也可以将涌现能力理解为模型潜力,巨大的技术潜力,是LLM爆火的根本原因。
激发大型语言模型的涌现能力有两种方法:提示工程(prompt engineering)和微调(fine-tuning)。
对于这两种方法各自有各自使用的应用场景,提示工程解决的问题,往往不会用微调(如小语义空间内的推理问题),微调通常用于解决那些无法通过特征工程解决的问题。
它们更多的时候是作为上下游技术关系,例如要进行本地知识库的定制化问答,最好的方法就是借助提示工程进行数据标注,然后再利用标注好的数据进行微调。
相比模型的原生能力,模型的涌现能力是非常不稳定的,要利用提示工程和微调技术来引导和激发模型的涌现能力,难度很大。
我通过复现解决论文中四个经典推理问题来看Prompt的上限!
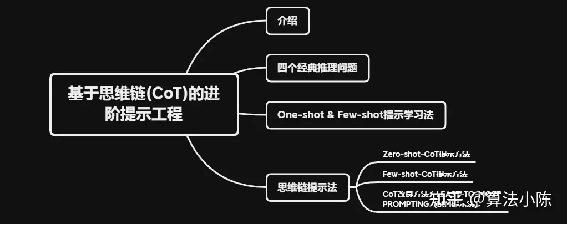
大模型开发(八):基于思维链(CoT)的进阶提示工程
内容多为近两年LLM领域的科研成果,但结论多为英文语境下的解决方案,因此,将会围绕这些高价值科研结果进行系统梳理,并且结合中文语境的实际情况提出中文内容逻辑推断的解决方案。
截至2023年7月29日为止,在Completions模型中,gpt-3系列模型(如'text-davinci-003'模型)是最强大的,同时也是第一批拥有涌现能力的大语言模型(LLM),即哪怕模型未经特定任务的训练,但在适当的提示下,仍然能够解决某些特定领域的问题。
比如它的数学能力,大语言模型甚至不知道数字代表的真实含义,只是在学习了无数的语料之后,发现了一些数学结论之间的潜在概率关系,就能最终涌现出了数学运算或者复杂推理的能力,这是很强的。要知道,大语言模型的训练目标目标是生成或预测文本,而不是进行问答。
但是,大模型的这种“涌现能力”其实并不稳定,在不修改模型本身参数(微调)的情况下,模型涌现能力极度依赖对模型的提示过程,即对同样一个模型,不同的提示方法将获得质量完全不同的结果。
一个完整的用户和大语言模型的交互流程,也被称为大语言模型(LLM)的提示工程(Prompt
engineering),提示工程是激发模型涌现能力(激发模型潜力)的非常关键的技术。提示工程和微调同属对模型涌现能力的引导和优化方法,但相比微调,提示工程成本更低、使用更加灵活,且对于提升模型在小语义空间内复杂语义理解效果更好。在很多时候,甚至需要要先设计提示工程进行文本标注,再使用这些标注的文本进行模型微调。
二、四个经典推理问题
对于提示工程来说,其侧重点是要解决复杂语义理解问题,而要验证模型是否具备这种能力,可以观察模型是否能解决复杂逻辑推理问题。
若通过模型能够在提示工程引导下,解决原始状态下无法解决的推理问题,则说明提示工程能够提升模型的推理能力,并且越有效的提示工程对模型推理能力提升幅度越大。这点能够通过设置不同复杂程度的推理问题来进行验证。
看一下以下四个经典的推理问题:
推理题1、2来自论文:Chain-of-Thought
Prompting Elicits Reasoning in Large Language Models
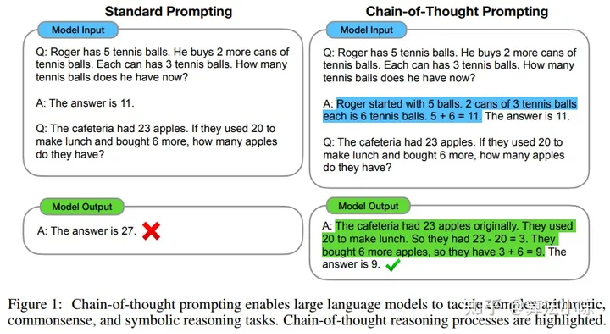
image-20230719091658909
切换到中文语境下:
·推理题 1
prompt1 = '罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?'
代码如下:
importosimportopenaiopenai.api_key=os.getenv("OPENAI_API_KEY")
prompt1='罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?'
response1=openai.Completion.create(
model="text-davinci-003",
prompt=prompt1,
max_tokens=1000,
)
response1["choices"][0]["text"].strip()
看下推理结果:

image-20230719092147846
·推理题 2
prompt2 = '食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?'
看下代码:
prompt2='食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?'response2=openai.Completion.create(
model="text-davinci-003",
prompt=prompt2,
max_tokens=1000,
)
response2["choices"][0]["text"].strip()
看下推理结果:
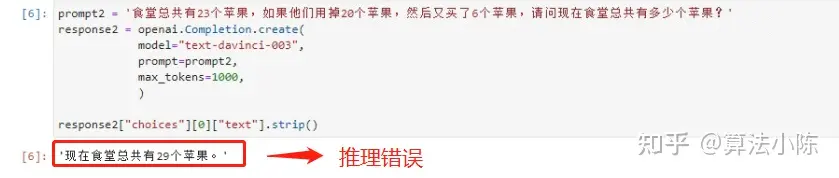
image-20230719092449486
这个推理题更加复杂一点,即食堂不仅增加了6个苹果,而且还消耗了20个苹果。有增有减,大模型就无法做出正确判断了。正确答案应该是目前食堂还剩23-20+6=9个苹果。
推理题3来自论文:Large Language
Models are Zero-Shot Reasoners

image-20230719093003045
切换到中文语境:
·推理题 3
prompt3 = '杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?'
看下代码:
prompt3='杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?'response3=openai.Completion.create(
model="text-davinci-003",
prompt=prompt3,
max_tokens=1000,
)
response3["choices"][0]["text"].strip()
看下推理结果:

image-20230719093255881
第三个逻辑题的数学计算过程并不复杂,但却设计了一个语言陷阱,即一半的一半是多少。能够发现,模型无法围绕这个问题进行准确的判断,正确答案应该是16*0.5*0.5=4个蓝色高尔夫球。
推理题4 来自论文LEAST-TO-MOST
PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS
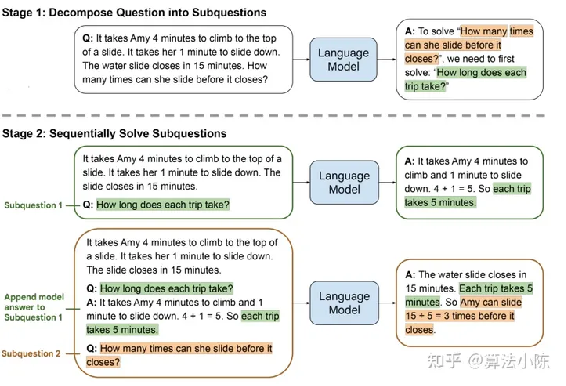
image-20230719150659795
·推理题 4
prompt4 = '艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?'
看下代码:
prompt4='艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?'response4=openai.Completion.create(
model="text-davinci-003",
prompt=prompt4,
max_tokens=1000,
)
response4["choices"][0]["text"].strip()
看下推理结果:

image-20230719094130749
这个题计算过程最复杂的,涉及多段计算以及除法运算。正确的计算过程应该是先计算艾米一次爬上爬下总共需要5分钟,然后滑梯还有15分钟关闭,因此关闭之前能够再滑15/5=3次。
从上述结果来看,'text-davinci-003'在Zero-shot的情况下,逻辑推理能力较弱,只能围绕相对简单的、只有线性运算过程的推理问题进行很好的解答,对于这四个推理题,模型只正确回答了第一个问题,其他问题都答错了,模型的推理能力堪忧。
下面通过不同的提示法,看如何加强模型的逻辑处理能力,从而解决这些问题
三、One-shot &
Few-shot提示学习法
最简单的提示工程的方法就是通过输入一些类似问题和问题答案,让模型参考学习,并在同一个prompt的末尾提出新的问题,依次提升模型的推理能力。这种方法也被称为One-shot或者Few-shot提示方法。
One-shot和Few-shot最早由OpenAI研究团队在论文《Language Models are Few-Shot Learners》中率先提出,这篇论文也是提示工程方法开山鼻祖,不仅介绍了提示工程的两大核心方法,同时也详细介绍这么做背后的具体原因。
具体的应用来说,Few-shot提示方法并不复杂,只需要将一些类似的问题的问题+答案作为prompt的一部分进行输入即可。
做个实验:首先把模型能够正确回答的第一个例子作为提示词输入,查看能否顺利推理出第二个问题:
Few-shot的编写格式:
当需要输入多段问答作为提示词时,以Q作为问题的开头、A作为回答的开头(也可以换成“问题”、“答案”),并且不同的问答对话需要换行以便于更加清晰的展示,具体方法是通过转义符+换行来完成,这样换行之后仍然还在一个字符串内。
代码如下:
prompt_Few_shot1='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“现在罗杰总共有11个网球。” \ Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?” \ A:'
response_Few_shot1=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Few_shot1,
max_tokens=1000,
)
response_Few_shot1["choices"][0]["text"].strip()
看下推理结果:
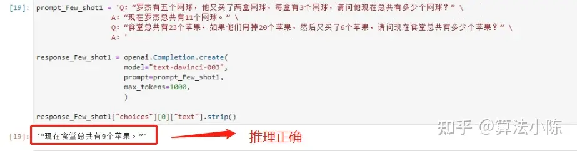
image-20230719101912636
虽然无法确定模型预测过程发生了何种变化,但在学习了第一个例子之后,模型确实能够对第二个问题做出准确判断。能够发现Few-shot在提升模型逻辑推理能力方面能够起到一定作用。
再测试一下将两个例子的问答都作为提示词进行输入,看看模型是否能正确回答第三个问题。代码如下:
prompt_Few_shot2='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“现在罗杰总共有11个网球。” \ Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?” \ A:“现在食堂总共有9个苹果。” \ Q:“杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?” \ A:'
response_Few_shot2=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Few_shot2,
max_tokens=1000,
)
response_Few_shot2["choices"][0]["text"].strip()
看下推理结果:
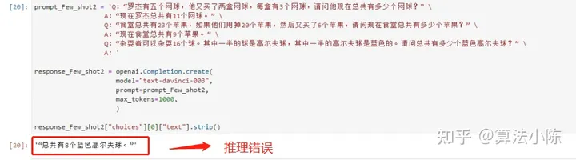
image-20230719102248425
模型对第三个问题仍然回答错误。接下来尝试把前两个问题作为提示词的一部分,让模型回答第四个问题,看下代码:
prompt_Few_shot3='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“现在罗杰总共有11个网球。” \ Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?” \ A:“现在食堂总共有9个苹果。” \ Q:“艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?” \ A:'
response_Few_shot3=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Few_shot3,
max_tokens=1000,
)
response_Few_shot3["choices"][0]["text"].strip()
看下推理结果:

image-20230719102628347
第四个问题也回答错误。这也说明了Few-shot提示方法能够一定程度提高模型推理能力,但提升的幅度有限,对于稍微复杂些的推理问题,模型仍然无法做出准确的回答。
Few-shot的使用方法较为简单,但实际上Few-shot有非常多的变种方法,其中一类非常重要的变种方法就是围绕提示的示例进行修改,即在示例中不仅提供问题+答案,同时还会增加一些辅助思考和判断的“提示”。
四、思维链提示法
4.1 Zero-shot-CoT提示方法
Zero-shot-CoT是在Few-shot思想下,一种更好的提示方法。它借助思维链(也被称为思考链,Chain of Thought,CoT)提示法来解决这个问题。一种非常简单而有效的方式是:在提示词尾部追加一句“Let’s think step by step”,即可大幅提高模型推理能力。
这种方法最早由东京大学和谷歌在论文《Large Language Models are Zero-Shot
Reasoners》中提出。由于只需要修改提示词而无需手动编写推导的成功示例(无需编写思维链样本),因此这种方法也被称为Zero-shot-CoT。
根据原论文描述,作者在测试Zero_shot_CoT方法时曾尝试过多组不同的提示词尾缀,并在一个机器人指令数据集上进行测试,最终发现“Let’s think step by step”效果最好,其他指令及各指令准确率排名如下:

image-20230719104708205
如果切换到中文语境下,对指令“Let’s
think step by step”进行中文翻译,做了大量的测试后,得出结论:“请一步步进行推理并得出结论”要远远好于“请让我们一步步进行思考”等类似的提示词语句,这种情况也给了非常深刻的启发,那就是大模型的“思考过程”是黑箱模型,哪怕表意近似的提示词对模型来说实际的影响力可能会有非常大的区别,大家可以自行测试一下,效果差别很大。
在中文语境下使用指令“请一步步进行推理并得出结论”测试一下,
·推理题 1
看下代码
prompt_Zero_shot_CoT1='罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?请一步步进行推理并得出结论。'
response_Zero_shot_CoT1=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_CoT1,
max_tokens=1000,
)
response_Zero_shot_CoT1["choices"][0]["text"].strip()
看下推理结果:

image-20230719105416603
·推理题 2
看下代码:
prompt_Zero_shot_CoT2='食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?请一步步进行推理并得出结论。'
response_Zero_shot_CoT2=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_CoT2,
max_tokens=1000,
)
response_Zero_shot_CoT2["choices"][0]["text"].strip()
看下推理结果:

image-20230719105626548
·推理题 3
看下代码:
prompt_Zero_shot_CoT3='杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?请一步步进行推理并得出结论。'
response_Zero_shot_CoT3=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_CoT3,
max_tokens=1000,
)
response_Zero_shot_CoT3["choices"][0]["text"].strip()
看下推理结果:

image-20230719105804601
·推理题 4
看下代码:
prompt_Zero_shot_CoT4='艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?请一步步进行推理并得出结论。'
response_Zero_shot_CoT4=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_CoT4,
max_tokens=1000,
)
response_Zero_shot_CoT4["choices"][0]["text"].strip()
看下推理结果:

image-20230719110114882
尽管答案正确,但推理过程并不正确,至于总共能滑3.5次云云,更是不符合逻辑。因此第四题其实仍然回答错误。
经过四个逻辑推导题的验证,确实相比Few-shot,Zero-shot-CoT确实更加有效,即能够通过更加简洁的提示来大幅提高模型推理能力。
该篇论文的另外两个重要结论:
需要重点关注的第二个结论是:在这篇论文中首次提出了利用大模型进行两阶段推理的设想,即第一个阶段先进行问题的拆分并分段解答问题(Reasoning Extraction),然后第二阶段再进行答案的汇总(Answer Extraction),这给予了后续LtM提示方法很大的启发。
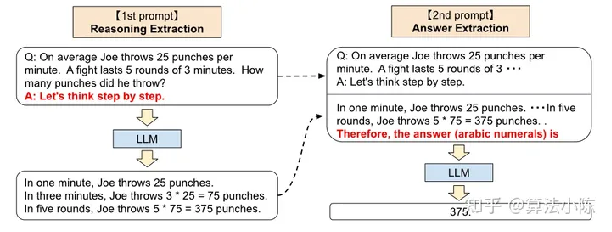
image-20230719110418641
该篇论文的第三个重要结论:作者通过测试验证,在实际使用过程中,Zero-shot-CoT要略弱于Few-shot-CoT方法
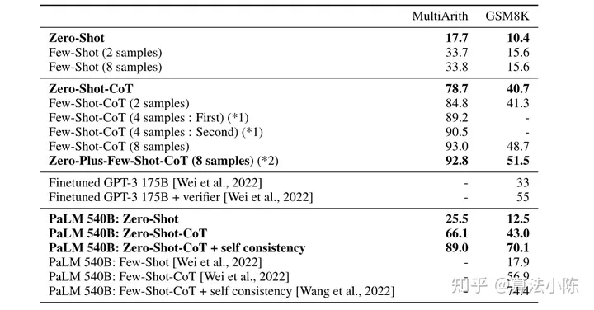
image-20230719110601240
论文中明确表示:模型越大,CoT效果越好,换而言之就是模型越大,CoT对模型“涌现能力”的激发效果越好。并且GPT-3在GSM8K数据集上能达到55%左右准确率。
GSM8K是一个非常著名的小学数学应用题组成的数据集,往往用于测试模型的推理能力。
4.2 Few-shot-CoT提示方法
从诞生时间上来说,Few-shot-CoT诞生时间要早于Zero-shot-CoT,它们之间的区别是:Zero-shot-CoT是零样本提示的情况下通过修改提示词后缀激发模型的思维链,而Few-shot-CoT则是通过编写思维链样本作为提示词,让模型学会思维链的推导方式,从而更好的完成推导任务。
该方法最早由谷歌大脑团队在论文《Chain-of-Thought Prompting Elicits
Reasoning in Large Language Models》中首次提出,也是在这篇论文中思维链的概念被首次提出,因此该论文可以说是思维链的开山鼻祖之作。
相比于Few-shot,Few-shot-CoT的不同之处只是在于需要在提示样本中不仅给出问题的答案、还同时需要给出问题推导的过程(即思维链),从而让模型学到思维链的推导过程,并将其应用到新的问题中。论文中给出了一系列的结论,用于论证思维链在这些领域应用的有效性。
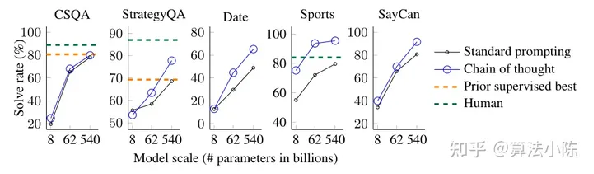
image-20230719152322893
例如,围绕推理1,手动写一个思维链作为Few-shot的示例:
'Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“罗杰一开始有五个网球,又购买了两盒网球,每盒3个,共购买了6个网球,因此现在总共由5+6=11个网球。因此答案是11。” '
在获得了一个思维链示例后,就可以以此作为样本进行Few-shot-CoT来解决第二个推理问题,看下代码:
prompt_Few_shot_CoT2='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“罗杰一开始有五个网球,又购买了两盒网球,每盒3个,共购买了6个网球,因此现在总共由5+6=11个网球。因此答案是11。” \ Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?” \ A:'
response_Few_shot_CoT2=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Few_shot_CoT2,
max_tokens=1000,
)
response_Few_shot_CoT2["choices"][0]["text"].strip()
看下推理结果:

image-20230719151329759
从结果上看,模型能够非常好的回答第二个问题,接下来把前两个问题的思维链作为提示词输入,来引导模型解决第三个问题,看下代码:
prompt_Few_shot_CoT3='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“罗杰一开始有五个网球,又购买了两盒网球,每盒3个,共购买了6个网球,因此现在总共由5+6=11个网球。因此答案是11。” \ Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?” \ A:“食堂最初有23个苹果,用掉20个,然后又买了6个,总共有23-20+6=9个苹果,答案是9。” \ Q:“杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?” \ A:'
response_Few_shot_CoT3=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Few_shot_CoT3,
max_tokens=1000,
)
response_Few_shot_CoT3["choices"][0]["text"].strip()
看下推理结果:
image-20230719151528383
继续叠加,看最后一个问题,代码如下:
prompt_Few_shot_CoT4='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?” \ A:“罗杰一开始有五个网球,又购买了两盒网球,每盒3个,共购买了6个网球,因此现在总共由5+6=11个网球。因此答案是11。” \ Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?” \ A:“食堂最初有23个苹果,用掉20个,然后又买了6个,总共有23-20+6=9个苹果,答案是9。” \ Q:“杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?” \ A:“总共有16个球,其中一半是高尔夫球,也就是8个,其中一半是蓝色的,也就是4个,答案是4个。” \ Q:“艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?” \ A:'
response_Few_shot_CoT4=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Few_shot_CoT4,
max_tokens=1000,
)
response_Few_shot_CoT4["choices"][0]["text"].strip()
看下结果:

image-20230719151733004
哪怕输入了前三个问题的思维链作为提示词样本,第四个问题仍然无法得到正确的解答。
另外,根据《Large
Language Models are Zero-Shot Reasoners》论文中的结论,从海量数据的测试结果来看,Few-shot-CoT比Zero-shot-CoT准确率更高。
重点强调了模型体量和思维链效果之间的关系,简而言之就是,模型越大、Few-shot-CoT应用效果越好。如下图:
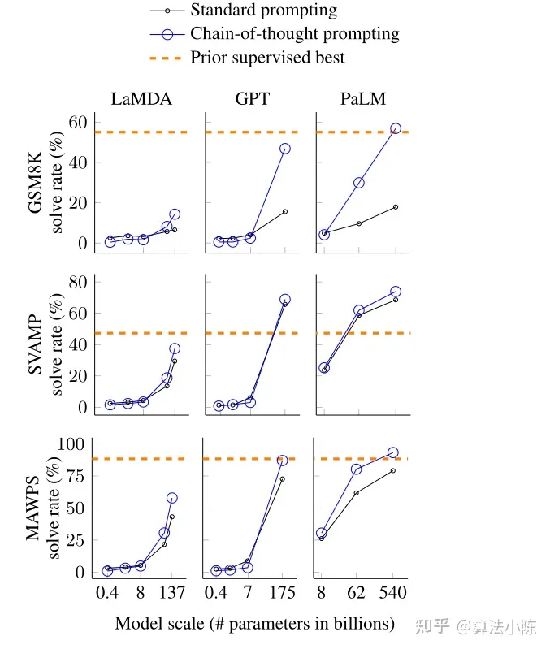
image-20230719152541138
同样以GSM8K数据集为例进行了说明,能够看出模型效果LaMDA(137B)< GPT-3(175B) < PaLM(540B)。和Zero-shot-CoT类似,模型越大、CoT对模型潜在能力激发效果越好。
4.3 CoT改良方法:LEAST-TO-MOST PROMPTING(LtM提示法)
在谷歌大脑提出的CoT被实际验证能够大幅提升大语言模型的推理能力不久,来自谷歌大脑的另一个团队在此基础上发表了另一篇重量级论文《LEAST-TO-MOST
PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS》,并在其中提出了一种名为Least-to-Most(LtM)的提示方法,将大语言模型的推理能力进一步提高。这种名为LtM的提示方法不仅能够将模型在GSM8K上的表现提高至62%,甚至在某些特殊语义解读场景下能够达到3倍于CoT的效果。
该方法是截至目前围绕模型推理能力提升的最为有效的提示学习方法。
LtM提示方法提出的初衷是为了解决CoT提示方法泛化能力不足的问题——即通过人工编写的思维链提示样本可能并不能够很好的迁移到别的问题当中去,换而言之,就是解决问题的流程迁移能力不足,即泛化能力不够。而这种泛化能力不足则会导致“新的问题”无法使用“老的模板”进行解决。
即然要找到更加普适的解决问题的流程会非常复杂,那能否“千人千面”让大模型自己找到解决当前问题的思维链呢?答案是肯定的,谷歌大脑基于这个思路开发了一种全新的提示流程,即先通过提示过程让模型找到解决该问题必须要分步解决哪几个问题,然后再通过依次解决这些问题来解决最原始的问题。
整个提示过程会分为两个阶段进行,第一个阶段是自上而下的分解问题(Decompose Question into subquestion),第二个阶段是自下而上的依次解决问题(Sequentially Solve Subquestion),而整个依次回答问题的过程,其实就可以看成是CoT的过程,只不过LtM会要求模型根据每个不同的问题,单独生成解决问题的链路,以此做到解决问题流程的“千人千面”,从而能够更加精准的解决复杂推理问题。而整个过程问题的由少变多,则是LEAST-TO-MOST一词的来源。
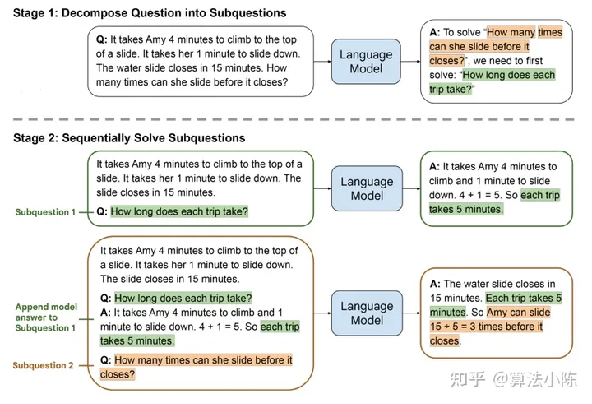
image-20230719153447415
上图是论文中提出的理解LtM提示过程的示例,这里的例子就是一直尝试解决的第四个推理问题。
论文中通过提示模板“To
solve __, we need ti first solve:”来引导模型创建子问题,模型会根据原始问题提出子问题“艾米一次爬上滑梯+滑下滑梯总共用时多少”,然后先解决这个子问题,再解决原始问题,不难发现,这其实是一个非常简单的两阶段解决问题的过程——第一个阶段只额外分解了一个子问题(即总共分两个问题作答)。
根据论文中给出的结果,第一阶段模型能够非常顺利的回答“艾米一次爬上滑梯+滑下滑梯总共用时多少”——5分钟,然后据此顺利回答出在滑梯关闭之前艾米还能玩三次的准确结论。
在第二个阶段、即Sequentially
Solve Subquestion并不是简单的依次解决两个问题,而是在解决了子问题之后,将原问题、子问题和问题和答案三部分都作为prompt输入给大语言模型,让其对原始问题进行回答。
所以,LtM的核心并不仅仅在于引导模型拆分问题,还在于及时将子问题的问题和答案回传给模型,以便更好的围绕原始问题进行回答。
理论上整个过程会有三次调用大模型的过程,问答流程如下:
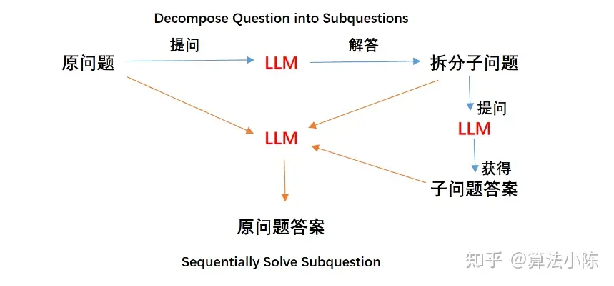
image-20230719153925634
按照这种方式尝试一下,看下代码:
prompt_Zero_shot_LtM4='Q:“艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?”\ A:为了解决“在关闭之前她能滑多少次?”这个问题,我们首先要解决的问题是'
response_Zero_shot_LtM4=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_MtL4,
max_tokens=1000,
)
response_Zero_shot_LtM4["choices"][0]["text"].strip()
结果如下:

image-20230719154836609
LtM提示过程能够非常好的解决这个推理问题。并且,在实际测试过程中,模型不仅能够拆解任务,而且还能够自动根据拆解的子问题答案回答原始问题,最终做到在一个提示语句中对原始问题进行准确回答。
‘为了解决“__”这个问题,我们首先要解决的问题是__’也是经过验证的、最为恰当、同时也最能够得到准确回答的提示词模板,建议经常使用,并验证其功能。
同理,在使用LtM测试其它的三个问题:
·推理题 1
代码如下:
prompt_Zero_shot_LtM1='Q:“罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?”\ A:为了解决“罗杰总共又多少个网球?”这个问题,我们首先要解决的问题是'
prompt_Zero_shot_LtM1=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_LtM1,
max_tokens=1000,
)
prompt_Zero_shot_LtM1["choices"][0]["text"].strip()
看下推理结果:

image-20230719155124426
·推理题 2
代码如下:
prompt_Zero_shot_LtM2='Q:“食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?”\ A:为了解决“现在食堂总共有多少个苹果”这个问题,我们首先要解决的问题是'
prompt_Zero_shot_LtM2=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_LtM2,
max_tokens=1000,
)
prompt_Zero_shot_LtM2["choices"][0]["text"].strip()
看下推理结果:

image-20230719155512353
·推理题 3
代码如下:
prompt_Zero_shot_LtM3='Q:“杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?”\ A:为了解决“总共有多少个蓝色高尔夫球”这个问题,我们首先要解决的问题是'
prompt_Zero_shot_LtM3=openai.Completion.create(
model="text-davinci-003",
prompt=prompt_Zero_shot_LtM3,
max_tokens=1000,
)
prompt_Zero_shot_LtM3["choices"][0]["text"].strip()
推理结果如下:

image-20230719155714258
MtL提示过程能够非常好的帮助模型解决上述问题,这也说明MtL对大语言模型的推理能力提升效果非常显著,可以说是截至目前,尝试过的(解决推理问题方面)最有效的一类提示方法。
出自:https://www.zhihu.com/question/586331504/answer/3125792161
根据文本输入和一个15秒的音频样本,就能生成接近原始说话者声音的自然听起来的语音。