如何修复GPT幻觉、及评估数据集的挑战
发布时间:2024年06月06日
生成大型语言模型 (LLM) 可以对各种用户提示生成高度流畅的响应。然而,他们产生幻觉或做出不实陈述的倾向可能会损害信任。
我认为我们将把幻觉问题解决得更好……这需要我们一年半、两年的时间。— OpenAI 首席执行官 Sam Altman
当开发人员希望使用模型构建系统时,这些限制提出了真正的挑战,因为整个系统必须满足质量、安全性和基础性要求。例如,我们可以相信LLM提供的自动代码审查是正确的吗?或者返回的有关如何处理保险相关任务的答案是否可靠?本文首先概述了幻觉如何仍然是LLM面临的一个持续挑战,然后是解决幻觉和可靠性问题的步骤(以及相关的研究论文)。
免责声明:本文中的信息截至 2023 年 8 月28日是最新的,但请注意,此后可能会发生变化。
1、简短的摘要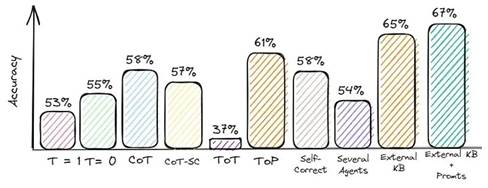 实验结果对比大型语言模型中的幻觉源于数据压缩和不一致。质量保证具有挑战性,因为许多数据集可能已过时或不可靠。为了减轻幻觉:
实验结果对比大型语言模型中的幻觉源于数据压缩和不一致。质量保证具有挑战性,因为许多数据集可能已过时或不可靠。为了减轻幻觉:
1.调整温度参数以限制模型创造力。
2.注重提示词工程。要求模型逐步思考,并在响应中提供事实和来源参考。
3.合并外部知识源以改进答案验证。
这些方法的组合可以达到最佳结果。
2、什么是LLM幻觉?
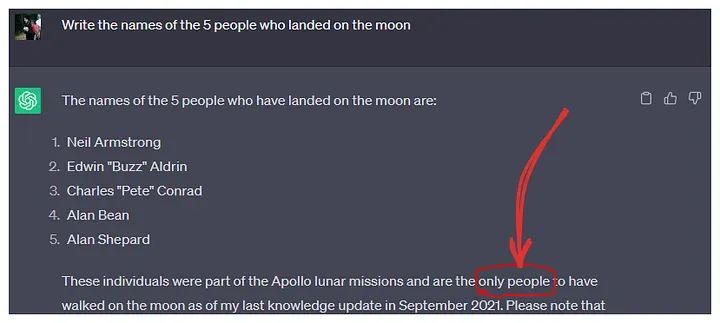 捏造事实的例子:月球行者一共有12人人工智能研究中心的一篇研究论文将法学硕士的幻觉定义为“当生成的内容是无意义的或不忠实于所提供的源内容时”。(论文地址:https://arxiv.org/pdf/2202.03629.pdf)幻觉可以分为以下几种类型:
捏造事实的例子:月球行者一共有12人人工智能研究中心的一篇研究论文将法学硕士的幻觉定义为“当生成的内容是无意义的或不忠实于所提供的源内容时”。(论文地址:https://arxiv.org/pdf/2202.03629.pdf)幻觉可以分为以下几种类型:
1.逻辑谬误:模型的推理错误,提供了错误的答案。
2.捏造事实:模型没有回答“我不知道”,而是自信地断言不存在的事实。
3.数据驱动的偏见:由于某些数据的普遍存在,模型的输出可能会出现偏差,从而导致结果不正确。例如政治偏见。
3、为什么LLM会产生幻觉
我喜欢本文中的概念:当我们压缩训练数据时,模型将不可避免地产生幻觉。考虑一些流行模型的压缩比: 训练数据的压缩当然,这种压缩的关键在于生成模型存储输入(文本或像素)之间关系(概率)的数学表示,而不是输入本身。更重要的是,这种表示可以让我们提取知识(通过采样或运行查询/提示)。这种压缩会降低保真度,类似于《纽约客》文章中讨论的 JPEG 压缩。从本质上讲,完全恢复原始知识即使不是不可能,也是一项困难的任务。模型倾向于不完美地“填补空白”或产生幻觉,这是对这种压缩但有用的知识表示的权衡。当LLM的训练数据集包含有关向他们提出的问题的有限、过时或矛盾的信息时,LLM也会产生幻觉。
训练数据的压缩当然,这种压缩的关键在于生成模型存储输入(文本或像素)之间关系(概率)的数学表示,而不是输入本身。更重要的是,这种表示可以让我们提取知识(通过采样或运行查询/提示)。这种压缩会降低保真度,类似于《纽约客》文章中讨论的 JPEG 压缩。从本质上讲,完全恢复原始知识即使不是不可能,也是一项困难的任务。模型倾向于不完美地“填补空白”或产生幻觉,这是对这种压缩但有用的知识表示的权衡。当LLM的训练数据集包含有关向他们提出的问题的有限、过时或矛盾的信息时,LLM也会产生幻觉。
4、准备实验
本文旨在创建并测试减少幻觉并提高系统性能的实际步骤。为此,在审查了各种数据集之后,我选择了TruthfulQA 基准。(https://github.com/manyoso/haltt4llm)尽管该数据集存在问题,例如正确答案与其来源之间存在差异,但由于其主题多样且覆盖面广,它仍然是最合适的选择。我还很欣赏答案以测验的形式出现,有助于模型测试。人们可以轻松地请求 JSON 格式的答案:… 以 JSON 格式返回响应,例如:[{“class”: “A”}]我使用了 800 行的数据集,并使用 GPT-3.5 Turbo 来实现其成本效益。评估幻觉的其他基准
知识导向的LLM评估基准(KoLA)
TruthfulQA:衡量模型如何模仿人类的谎言
大型语言模型的医学领域幻觉测试
HaluEval:LLM的幻觉评估基准
5、降温
模型的温度是指用于调整模型预测的概率分布的标量值。就法学硕士而言,它需要在坚持模型从训练数据中学到的知识和生成更多样化或创造性的响应之间取得平衡。一般来说,这些创造性的答案更容易产生幻觉。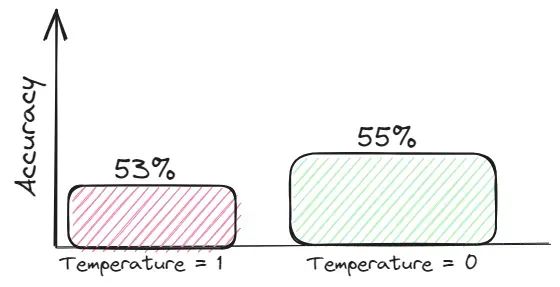 降温实验结果比较对于需要准确性的任务,努力争取信息密集的上下文并设置温度=0以获得基于上下文的答案。
降温实验结果比较对于需要准确性的任务,努力争取信息密集的上下文并设置温度=0以获得基于上下文的答案。
6、思维链条的提示和自洽
基准错误通常可以通过改进提示设计来修复。这就是为什么我更加关注这个话题。法学硕士常常在算术或逻辑等多步骤推理任务上表现不佳。最近的研究表明,提供将任务分解为步骤的示例可以提高绩效。值得注意的是,仅用“让我们一步一步思考”而不带具体示例进行提示会产生类似的改进。许多文章深入探讨了思想链技术。本质上,他们的目标是让模型逐步思考并自我验证。以下是一些出色的方法: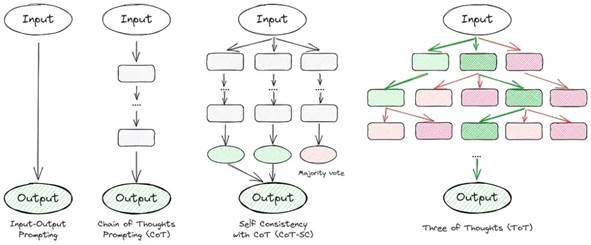 说明法学硕士解决问题的各种方法的示意图现在,让我们深入研究每种方法并评估它们在数据集上的质量。
说明法学硕士解决问题的各种方法的示意图现在,让我们深入研究每种方法并评估它们在数据集上的质量。
a. 思想链(CoT)
文章的主要思想是在提示中添加“一步步思考”:
回答之前先思考一下,并以 JSON 格式返回响应,例如:[{“class”: “A”}]”
评估:Accuracy = 58%
b. 与 CoT 的自我一致性(CoT-SC)
该方法是先前想法的改进版本。我们要求模型给出几个答案,然后通过投票选择最佳答案:
在回答之前逐步思考并给出三个答案:是否由领域专家回答、是否由主管回答以及您的答案。以下是 JSON 格式的响应:
评估:Accuracy = 57%
c.思想树(ToT)
它是一个概括了思维链提示的框架,并鼓励对思想的探索,作为使用语言模型解决一般问题的中间步骤。这种方法使 LM 能够自我评估中间思想通过深思熟虑的推理过程解决问题所取得的进展。ToT 提示示例如下:
想象一下三位不同的专家正在回答这个问题。所有专家都会写下他们的想法的 1 个步骤,然后与小组分享。然后所有专家将继续下一步,依此类推。如果任何专家意识到他们在任何时候错了,那么他们就会离开。以下是 JSON 格式的响应:
评价:Accuracy = 37%
d. 标记上下文提示
该方法包括生成问题集、通过摘要创建上下文提示以及验证上下文提示和问题。考虑到额外数据集生成的复杂性,我调整了请求源链接和事实的方法: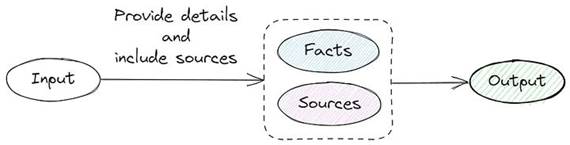 示意图说明了我的标记上下文提示版本
示意图说明了我的标记上下文提示版本
提供详细信息并在答案中包含来源。返回 JSON 格式的响应,例如:
[{“class”: “A”, “details”: “人类静脉中的血液实际上不是蓝色的。由于血红蛋白的存在,血液呈红色”,“来源”:“https://example.com”}]
评估:Accuracy = 61%
e.自我纠正
它可能是即时工程中更先进的技术之一。这个想法是让模型仔细检查并批评其结果,如下所示: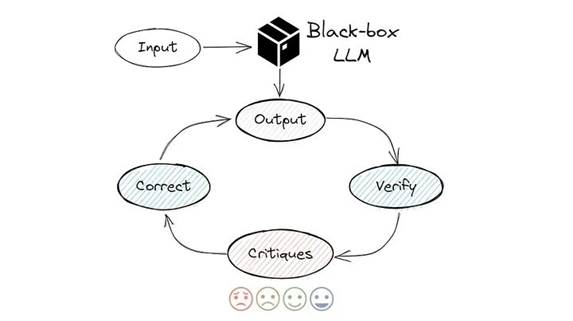
列表中选择最可能的答案 [“A”、“B”、“C”、“D”、“E”]。然后仔细检查你的答案。想想这是否是正确的答案,其他人会同意吗?根据需要改进您的答案。
返回
JSON 格式的响应,例如:[{“first_answer”:”A”, “final_answer”:”B”}]
评估:Accuracy = 58%
f. 若干代理
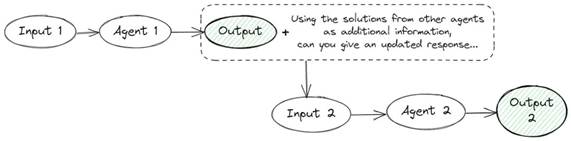
多个代理方法的示意图
多个语言模型实例在多轮中提出并辩论其各自的响应和推理过程,以得出共同的最终答案。该方法包括几个提示:提示1
逐步提供事实和您的想法,以找到此问题的正确答案:{QUESTION}
提示2
使用其他代理提供的解决方案作为附加信息,选择正确的答案选项:{问题} {答案}。以 JSON 格式返回响应...
评估:Accuracy = 54%我不建议在实际应用程序中使用这种方法,因为您需要发出两个或更多请求。这不仅会增加 API 成本,还会减慢应用程序的速度。就我而言,我们花了两个多小时才对 800 个问题做出答复。
7、使用外部知识库
如前所述,法学硕士的幻觉源于尝试重建压缩信息。通过在预测期间从知识库提供相关数据,我们可以将纯粹的生成问题转换为基于所提供数据的更简单的搜索或总结问题。由于在实践中,从知识库检索相关数据并非易事,因此我重点关注了我收集的数据集中的一个小样本(约 300 行)。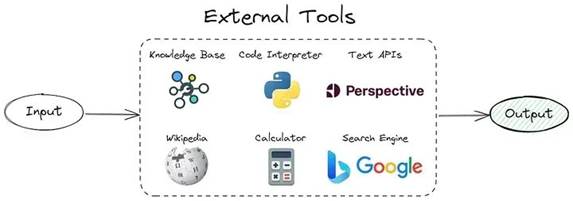 外部资源使用示意图最后,我的提示如下:
外部资源使用示意图最后,我的提示如下:
使用此信息 {INFORMATION} 选择正确答案 {QUESTION} 并以 JSON 格式返回响应...
评估:Accuracy = 65%仍然需要做更多的工作来过滤/排序检索到的段落,并决定本练习中使用了多少 LLM 上下文预算。此外,检索和排名可能会带来对于实时交互至关重要的延迟。另一个有趣的方法是检索增强生成(RAG),它融合了大型语言模型中的检索和文本生成功能。这种方法将用于从庞大语料库中获取相关文档片段的检索系统与基于检索到的信息生成答案的LLM配对。
8、快速工程和外部知识库
这种方法结合了前面的几点。使用不同的即时工程技术和外部知识库。我实现了 CRITIC 框架的逻辑: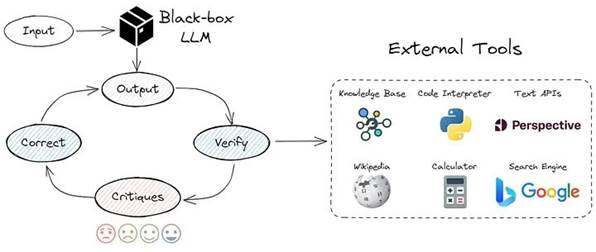 批评家框架
批评家框架
使用此信息{信息}选择正确答案{问题}然后仔细检查您的答案。想想这是否是正确的答案,其他人会同意吗?根据需要改进您的答案。
返回 JSON 格式的响应,例如:[{“first_answer”:”A”, “final_answer”:”B”}]
评估:Accuracy = 67%虽然质量没有提高那么多,但这是由于我使用的数据集存在问题造成的。一些“正确”答案与来源中的信息不匹配。
9、要点
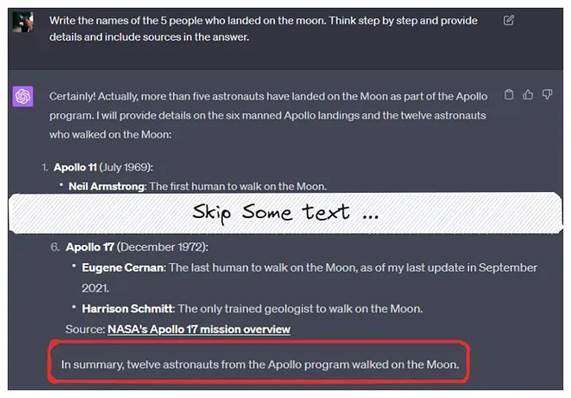
使用文章中的技术,我们修复了幻觉
乍一看,减少LLM的幻觉并不是什么火箭科学:调整温度、玩提示、链接外部数据源。然而,与许多事情一样,细微差别比比皆是。每种方法都有其优点和缺点。我的主要建议是什么?优先考虑提示词设计——这是解决幻觉最具成本效益和最有效的方法。
出自:https://mp.weixin.qq.com/s/Yn9_cm5H4SWcrQxs_yodTQ
Subtxt 是一款AI写作应用程序,可帮助您轻松编写完整的故事。与其他AI文本生成提供包装器的写作应用程序不同,Subtxt 将这些服务与独特的叙事框架配对,有助于识别和增强您要讲述的故事。