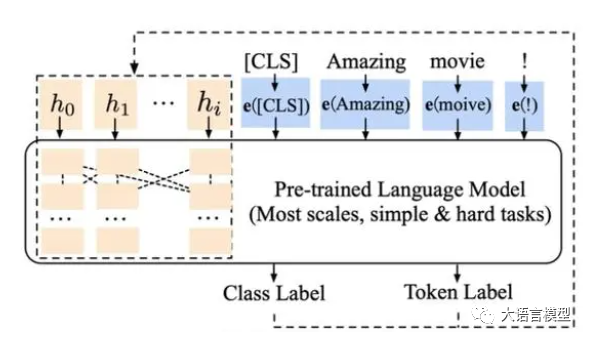
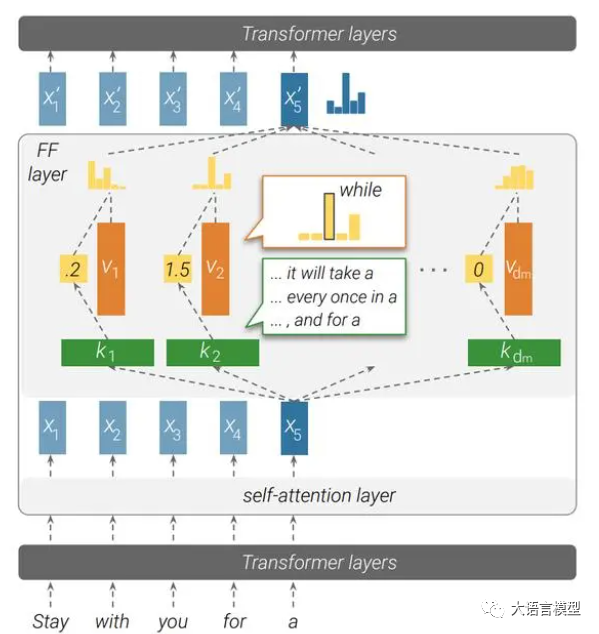
四种微调技术详解:SFT 监督微调、LoRA 微调、P-tuning v2、Freeze 监督微调方法
发布时间:2024年06月06日
当谈到人工智能大语言模型的微调技术时,我们进入了一个令人兴奋的领域。这些大型预训练模型,如GPT-3、BERT和T5,拥有卓越的自然语言处理能力,但要使它们在特定任务上表现出色,就需要进行微调,以使其适应特定的数据和任务需求。在这篇文章中,我们将深入探讨四种不同的人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning
v2 微调方法和Freeze 监督微调方法。
第一部分:SFT 监督微调
简介
SFT(Self-training Fine-tuning)是一项引人注目的微调方法,特别适用于解决低资源语言或领域的挑战。它采用了自监督学习的思想,可以显著减少对大量标记数据的依赖。
SFT 的步骤
1. 预训练
SFT的旅程始于对大型语言模型进行预训练,这通常在大规模未标记的文本数据上进行。这一阶段的目标是使模型获取通用的语言理解和推理能力。
2. 生成伪标签
接下来,SFT将模型应用于目标任务的未标记数据,以生成所谓的伪标签。这是通过利用模型的预测结果来为未标记数据自动生成标签,而不必进行人工标注。例如,在文本分类任务中,SFT可以利用模型的预测结果为文本分配类别标签。
3. 有监督微调
一旦生成了伪标签,SFT将这些伪标签与少量真实标记数据一起用于有监督微调。这是微调的传统阶段,模型通过在包含真实标签的数据上进行训练来微调权重。
4. 微调结果
通过有监督微调,模型应该在目标任务上表现出更好的性能。由于引入了伪标签,模型能够更好地适应任务的特定要求和特征。
优势和应用
SFT的最大优势在于它能够在低资源环境中获得出色的性能。这对于处理少见语言或领域的任务非常有用。
SFT的应用领域包括文本分类、命名实体识别、情感分析等自然语言处理任务。尤其是在标记数据有限的情况下,SFT成为了一个强大的工具。
第二部分:LoRA 微调方法
简介
LoRA(Language-oriented Data Augmentation)是一种针对自然语言处理任务的微调方法,它引入了一种语言导向的数据增强技术,以改进模型的性能。
LoRA 的步骤
1. 预训练
与其他微调方法一样,LoRA的第一步是在大规模未标记的文本数据上对模型进行预训练。这使得模型能够学习通用的语言表示。
2. 数据增强
LoRA中的关键步骤是数据增强。这个方法通过在文本数据上引入语言相关的扰动来提高模型的性能。这可能包括以下操作:
·
同义词替换:将文本中的一些词汇替换为它们的同义词,以生成变种数据。
·
·
句子重排:重新排列句子的顺序,生成不同结构的句子。
·
·
语法扰动:修改句子的语法结构,例如重新排列短语或子句。
·
·
3. 微调
在数据增强之后,模型通过在任务特定的标记数据上进行微调来适应特定任务。这个微调阶段使模型更能够理解和生成与任务相关的文本。
优势和应用
LoRA的优势在于它通过数据增强提高了模型的性能,使其更适合特定领域或任务。这种方法特别适用于需要大量领域特定数据的任务,但实际可用的标记数据有限的情况。
LoRA可以应用于各种自然语言处理任务,包括文本生成、机器翻译、情感分析等。它有助于模型更好地适应不同领域或特定领域的数据。
第三部分:P-tuning v2 微调方法
简介
P-tuning是一种适用于多语言和跨语言任务的微调方法,它的目标是使模型能够在不同语言之间进行迁移学习。P-tuning v2是其改进版本,增强了模型的通用性。
P-tuning v2 的步骤
1. 预训练
P-tuning v2的第一步是在大规模未标记的文本数据上对模型进行预训练,这与其他微调方法相似。
2. 适应性层
P-tuning v2引入了适应性层,这是一种特殊的神经网络层,用于根据不同语言和任务的需要自适应模型的表示。适应性层允许模型根据任务和语言的差异进行调整。
3. 跨语言迁移
P-tuning v2的关键是跨语言迁移。在这个过程中,模型首先在一个语言上进行微调,然后通过共享适应性层的参数,轻松地将模型迁移到其他语言上执行相同的任务。
4. 多语言通用性
通过共享适应性层和迁移学习,P-tuning
v2增强了模型的通用性,使其能够处理多种语言和跨语言任务。
优势和应用
P-tuning v2的主要优势在于它使模型能够在不同语言之间共享知识,从而减少了对大规模标记数据的依赖。它可以应用于跨语言文本分类、机器翻译、多语言情感分析等任务。
这种方法尤其适用于全球化和多语言环境下的应用,因为它可以节省大量时间和资源,同时提高模型的性能。
第四部分:Freeze 监督微调方法
简介
Freeze监督微调方法通常用于计算机视觉领域,不同于文本微调方法。这种方法的核心思想是冻结部分模型层,以保留模型在预训练任务中学到的特征。
Freeze 监督微调的步骤
1. 预训练
与其他微调方法一样,Freeze监督微调的第一步是在大规模图像数据上对卷积神经网络(CNN)模型进行预训练。这使模型能够学到通用的视觉特征。
2. 冻结层
在微调时,Freeze方法冻结了模型的一部分层,通常是模型的低级别卷积层。这些层的权重在微调过程中不会被更新。
3. 微调
只有部分模型层被微调,通常是与特定任务相关的高级别层。这些层的权重将根据任务的损失函数进行更新。
4. 微调结果
通过微调,模型应该在特定视觉任务上表现得更好。通过冻结低级别层,有助于保留模型在预训练任务中学到的通用特征。
优势和应用
Freeze监督微调方法适用于计算机视觉任务,特别是在有限的标记数据和计算资源下。它可以用于图像分类、目标检测、图像分割等任务,充分利用了预训练模型的视觉表示能力。
这种方法的优势在于可以减少微调过程中的过度拟合风险,并提高模型的泛化能力。它也是处理小样本视觉任务的有力工具。
总结
人工智能大语言模型微调技术是一项令人兴奋的领域,它有望为自然语言处理和计算机视觉等领域带来重大突破。本文深入探讨了SFT 监督微调、LoRA 微调方法、P-tuning
v2 微调方法和Freeze 监督微调方法,这些技术各具特色,可以根据任务的性质和可用资源来选择。微调方法的不断发展将继续推动人工智能领域的进步,为解决各种现实世界的问题提供有力的工具。
出自:https://mp.weixin.qq.com/s/qvetVJLED4Wow68eRh1ryw
抢先知晓全球最新鲜、最棒的创意资讯,扩充你的灵感库。