RAG——使用检索增强生成构建特定行业的大型语言模型
发布时间:2024年06月06日
在人工智能兴起的当下,AI正在不断地重塑着很多行业。我辈人工智能从业者,在探索AI应用的同时,也在不断地下钻技术本质。由于笔者之前梳理过比较多的AI应用,在查看检索增强生成技术(Retrieval-Augmented Generation)技术论文时,发现了一个事实,那就是几乎各大AI应用都有用到这种检索增强技术。
像之前介绍过的pandasAI、quivr、flowise、localGPT、privateGPT、pdfGPT和一些常见的基于大模型构建的本地知识库等AI应用无一不是建立在检索增强技术之上的,它是向量数据库能够在AI应用中发挥重要作用的根本。
下面放出原来梳理的部分文章链接,需要的自取:
localGPT——一款100%本地布署且支持LangChain的应用
什么是检索增强技术?
下面是检索增强技术论文的摘要部分,从中我们可以看到,检索增强技术是用于知识密集型nlp任务处理文本生成时,先通过信息检索技术来增强信息输入来使生成的内容更具体、更多样化和更真实的技术。

论文与资料
论文地址:[2005.11401]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks[1]
github:transformers/examples/research_projects/rag
at main · huggingface/transformers · GitHub[2]
huggingface:
•facebook/rag-token-nq
· Hugging Face[3]•RAG[4]•huggingface models:[Models - Hugging Face
下文是译自笔者认为比较好地讲述了检索增强在大模型时代应用中发挥的作用的一篇博客,原文地址为:https://towardsdatascience.com/build-industry-specific-llms-using-retrieval-augmented-generation-af9e98bb6f68
使用检索增强生成构建特定行业的大型语言模型
各组织机构正在竞相采用大型语言模型。让我们深入研究如何通过检索增强生成(RAG)构建特定行业的大型语言模型。
现在很多公司都在尝试通过像ChatGPT这样的大型语言模型可以获得大量的生产力提升。但是,如果你问ChatGPT“美国当前的通货膨胀率是多少”,它会给出以下回答:
对不起,我可能让你感到困惑,但作为一个AI语言模型,我没有实时数据或浏览能力。我的回答基于截至2021年9月的信息。因此,我无法提供美国当前的通货膨胀率。
这是一个问题。ChatGPT显然缺乏相关的及时上下文,这在做出明智的决策时可能是必要的。
微软如何解决这个问题
在微软的Build会议中,他们在向量搜索不够用[5]这个主题中,阐述了他们的产品如何将较少的上下文感知的大型语言模型与向量搜索结合起来,以创造更具吸引力的体验。
这个讨论从这篇文章的相反方向开始——从Elastic Search(或向量搜索)的角度出发——并提出搜索本身是有限的,添加大型语言模型的层可以大大提高搜索体验。
基本的想法是,向大型语言模型添加相关的上下文可以大大提高用户体验,特别是在大多数商业案例中,大型语言模型还没有看到这些类型的数据。向量搜索有助于选择什么是相关的上下文,当你有大量的数据,包括数百(或更多)的文档。
向量搜索

向量化是将数据转换为维度。在上面的例子中,你可以看到两个维度:大小和类型。
大小有两个值(小或大),类型有两个值(树或动物)。这只是一个概念性的例子,可以扩展到数百(或更多的值)。
使用单词的向量搜索

你可以用单词或句子做同样的事情,而不是图片。注意在上面的例子中,向量化能够捕捉到语义表示,即它知道一个句子谈论一只鸟猛扑一只小花栗鼠应该在(小,动物)象限,而谈论昨天的风暴时一棵大树倒在路上的句子应该在(大,树)象限。实际上,有超过2个维度 - 对于句子转换器嵌入(句子或文本块通过BERT转换器,输出对应于384个维度的384个数字)。
向量搜索 + 大型语言模型(RAG)
向量搜索现在在所有搜索中都很常见(Google,Bing,选择你最喜欢的搜索引擎)。想象一下,如果你的整个搜索数据库只有这4个文档。
你可以问一个问题,“告诉我关于一棵大树的事情。”
输出将是:
在昨天的风暴中,一棵大树倒在了路上。
这只是数据库中最相关的文档。但是,如果你问一个大型语言模型同样的问题(并在最后附上4个“文档”),这就是你得到的答案(在这个例子中是ChatGPT):
一棵大树通常是一种高大、耸立的植物,有坚固的树干、树枝和广泛的根系。这些树可以达到令人印象深刻的高度,通常远远超过周围的植被。它们在许多生态系统中起着重要的作用,为各种生物提供阴凉、庇护和食物。
你提到的关于一棵大树在风暴中倒在路上的事件表明了严重天气条件的力量和影响。强风可以将树木连根拔起或折断,导致道路阻塞和对车辆和行人可能的危险。
在你提到的另一个场景中,你在班迪普尔的路上开车时,遇到了一只大象过马路。班迪普尔是位于印度的一个国家公园和野生动物保护区,以其丰富的生物多样性和多样的动物种群而闻名。大象是班迪普尔发现的主要物种之一,它们被知道会穿越该地区,有时会过马路。这样的遭遇突显了野生动物保护的重要性,以及人类与动物在其自然栖息地中共存的需要。
转换话题到盆景,它们是在小盆中种植的微型树,经过精心的塑形和修剪以保持其小尺寸。盆景栽培是源自东亚的古老艺术形式,已在全球范围内赢得了广泛的欢迎。由于其根部空间有限,盆景树需要定期浇水以防止它们干燥。小盆可能会导致土壤快速干燥,所以监控水分水平并相应地浇水是至关重要的。
最后,你提到通过窗户观察到一只鸟猛扑一只小花栗鼠。这个观察反映了自然界的一个瞬间,一只鸟可能在寻找食物。猛禽和某些鸟类,如鹰或猫头鹰,被认为会猛扑小型哺乳动物如花栗鼠,这是它们自然捕猎行为的一部分。见证这样的互动是令人着迷的,因为它们提供了对动物王国动态的洞察。
总的来说,这些自然的片段——无论它们涉及到大树、大象、盆景树还是鸟类捕食——都突显了我们周围自然世界的多样性和奇迹。
这个答案看起来更全面。ChatGPT使用了它从训练了数万亿文档中获得的内部知识,结合了它被给予的上下文。
但是,假设你有超过4个文档——可能有成千上万个,你无法将它们全部放入ChatGPT的提示中。在这种情况下,你可以使用向量搜索来缩小最有可能包含答案的上下文,将其附加到提示中,然后像下面这样提出同样的问题:
这是它现在给出的(被截断的)答案:

你可以有一个数据库,存储文档和嵌入。你可以有另一个数据库,存储查询,并根据查询找到最相关的文档(文档数据库(左)和查询数据库(右)):

一旦你有了最相似的文档(们)通过查询,你可以将其提供给任何大型语言模型,如ChatGPT。通过这个简单的技巧,你已经使用文档检索增强了你的大型语言模型!这也被称为检索增强生成(RAG)。
使用RAG构建特定行业的问答模型
RAG原型
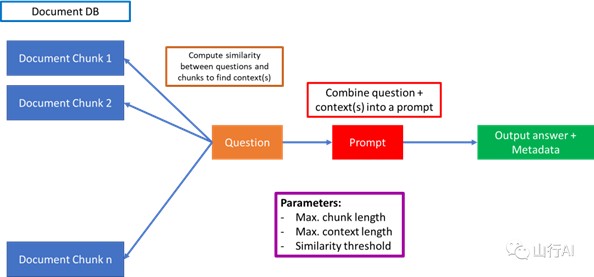
上图概述了如何构建一个基本的RAG,该RAG利用大型语言模型在自定义文档上进行问题回答。第一部分是将多个文档分割成可管理的块,相关的参数是
最大块长度
。这些块应该是包含答案的典型(最小)大小的文本。这是因为你可能会问的问题可能在文档的多个位置有答案。例如,你可能会问“X公司从2015年到2020年的表现如何?”你可能有一个大的文档(或多个文档)包含关于公司在不同部分的文档中的年度表现的具体信息。你理想的目标是捕获所有包含这些信息的文档的不同部分,将它们链接在一起,并将其传递给一个大型语言模型,基于这些过滤和连接的文档块进行回答。
最大上下文长度
基本上是将各种块连接在一起的最大长度——留下一些空间用于问题本身和输出答案(记住,像ChatGPT这样的大型语言模型有一个严格的长度限制,包括所有的内容:问题,上下文和答案。)
相似度阈值
是比较问题与文档块的方式,找到最有可能包含答案的顶部块。余弦相似度是通常使用的度量,但你可能想要权重不同的度量。例如,包括一个关键词度量,以更多地权重包含某些关键词的上下文。例如,当你向大型语言模型提问以总结文档时,你可能希望权重包含“摘要”或“总结”这些词的上下文。
如果你想要一个简单的方式来测试在自定义文档上的生成性问答,可以查看我的API[6]和code[7],它在后端使用ChatGPT。
由RAG提升的ChatGPT原型
让我们通过一个例子来说明RAG的用途。EMAlpha[8]是一家提供新兴市场洞察的公司——基本上是印度、中国、巴西等新兴国家的经济(全面披露——我是EMAlpha的顾问)。该公司正在构建一个由ChatGPT驱动的应用,根据用户输入生成对新兴经济的洞察。仪表板看起来像这样——你可以比较ChatGPT的输出和能够在后端查询IMF金融文档的RAG版本的ChatGPT(EM-GPT)的输出:

(上图来自[EMAlpha](https://www.emalpha.com/)的EM-GPT )
以下是ChatGPT对问题“尼泊尔的GDP是按年计算的吗?”的答案:

ChatGPT只返回了到2019年的GDP,它说如果你想要更多的信息,看看IMF。但是,如果你想找出这些数据在IMF网站的哪个位置,这是很困难的,你需要知道网站上的文档存储在哪里。经过一些搜索,你找到了文档在这里[9]。即使这样,找出GDP信息的确切位置还需要大量的滚动。
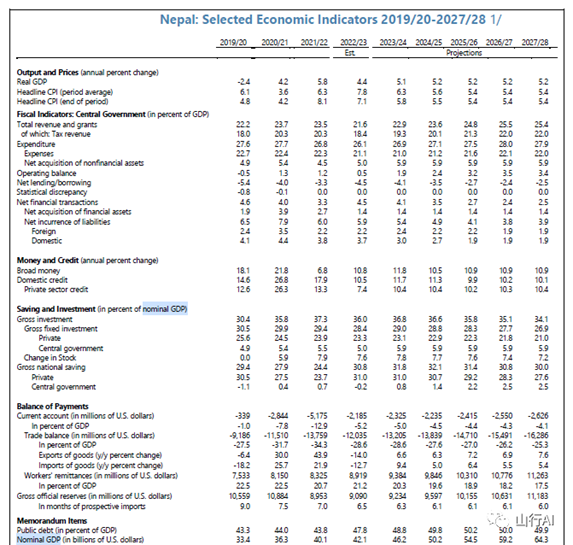
(尼泊尔经济的IMF文档)
如你所见,找到这些数据是相当困难的。但是,当你问EM-GPT同样的问题时,它追踪到相关的上下文,并找到了以下的答案:
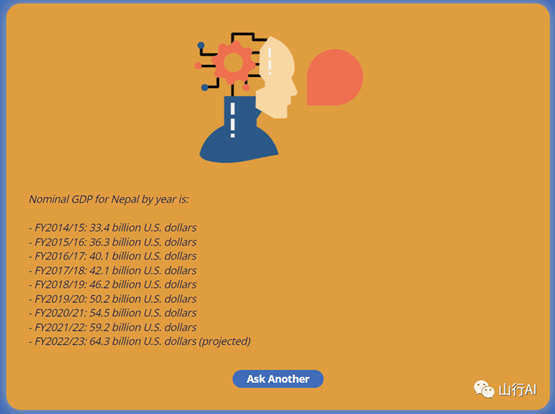
(EM-GPT的答案)
以下是发送给ChatGPT以回答这个问题的确切提示。它能够理解这种格式化的文本,提取正确的信息,并将其格式化成一个很好的人类可读格式,这真是令人印象深刻!

(基于查询检索的上下文使用ChatGPT提示)
我花了半个小时在IMF网站上找到这个信息,而RAG修改的ChatGPT只用了几秒钟。仅仅使用向量搜索是不够的,因为它可能最多只能找到“名义GDP”的文本,而不能将数字与年份关联起来。ChatGPT在过去接受了多个这样的文档的训练,所以一旦添加了相关的上下文,它就知道文本的哪些部分包含答案,以及如何将这个答案格式化成一个很好的可读格式。
结论
RAG提供了一种在自定义文档上使用大型语言模型的好方法。像Microsoft[10]、Google和Amazon这样的公司正在竞相构建应用,这些应用可以让组织以即插即用的方式使用。然而,这个领域还处于初级阶段,使用向量搜索驱动的大型语言模型在他们的自定义文档上的行业特定应用可以成为先行者,并超越他们的竞争对手。
虽然我有人问我应该使用哪个大型语言模型,是否应该在自定义文档上微调或完全训练模型,但是工程化大型语言模型和向量搜索之间的同步的角色被低估了。这里有一些考虑因素,可以显著提高或降低回应的质量:
1.文档块的长度。如果正确的答案更有可能包含在文本的不同部分,并需要被拼接在一起,文档应该被分割成较小的块,以便可以将多个上下文附加到查询中。2.相似性和检索度量。有时,简单的余弦相似度是不够的。例如,如果许多文档包含关于同一主题的冲突信息,你可能希望根据这些文档中的元数据限制对某些文档的搜索。为此,除了相似性,你可以使用其他过滤度量。3.模型架构:我展示的架构是一个原型。为了效率和可扩展性,必须考虑各种方面,包括向量嵌入模型、文档数据库、提示、大型语言模型的选择等。4.避免幻觉:你可能已经注意到,我上面展示的例子几乎是正确的。增强的ChatGPT得到了尼泊尔GDP的正确金额——但是年份错了。在这种情况下,需要在选择提示、以ChatGPT友好的格式提取数据、评估在何种百分比的情况下存在幻觉,以及哪些解决方案效果好之间进行大量的反馈。
现在你知道如何将大型语言模型应用到你的自定义数据上,去构建出色的基于大型语言模型的产品吧!
声明
本文主要用于知识梳理和技术分享,文中内容部分来自RAG论文和笔者的收集整理,大部分内容译自笔者认为比较有相关性而且写得比较好的一篇博客,原文地址为:https://towardsdatascience.com/build-industry-specific-llms-using-retrieval-augmented-generation-af9e98bb6f68
References
[1] [2005.11401]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: https://arxiv.org/abs/2005.11401[2] transformers/examples/research_projects/rag
at main · huggingface/transformers · GitHub: https://github.com/huggingface/transformers/tree/main/examples/research_projects/rag[3] facebook/rag-token-nq
· Hugging Face: https://huggingface.co/facebook/rag-token-nq[4] RAG: https://huggingface.co/docs/transformers/model_doc/rag[5]向量搜索不够用: https://build.microsoft.com/en-US/sessions/038984b3-7c5d-4cc6-b24e-5d9f62bc2f0e?source=sessions&wt.mc_ID=Build2023_esc_corp_em_oo_mto_Marketo_FPnews_Elastic[6] API: https://rapidapi.com/skandavivek/api/chatgpt-powered-question-answering-over-documents[7] code: https://github.com/skandavivek/web-qa[8] EMAlpha: https://www.emalpha.com/[9]找到了文档在这里: https://www.imf.org/en/Publications/CR/Issues/2023/05/04/Nepal-Staff-Report-for-the-2023-Article-IV-Consultation-First-and-Second-Reviews-Under-the-533075[10] Microsoft: https://www.elastic.co/blog/may-2023-launch-announcement?utm_source=organic-social&utm_medium=twitter&utm_campaign=cee-gc&ultron=t1_launch&blade=twitter&hulk=social&utm_content=10092954746&linkId=215905348
出自:https://mp.weixin.qq.com/s/-0dJ7sPbOD72F8eVR8iUeA
Logo Mockup是一个在线样机生成工具,用户通过上传他们的logo生成高分辨率的样机效果图并可以下载。