从0到1基于ChatGLM-6B使用LoRA进行参数高效微调
发布时间:2024年06月06日
之前尝试了基于LLaMA使用LoRA进行参数高效微调,有被惊艳到。相对于full finetuning,使用LaRA显著提升了训练的速度。
虽然 LLaMA 在英文上具有强大的零样本学习和迁移能力,但是由于在预训练阶段 LLaMA 几乎没有见过中文语料。因此,它的中文能力很弱,即使对其进行有监督的微调,同等参数规模下,它的中文能力也是要弱于bloom-7b1、chatglm-6b等。
下面,我们来尝试基于中英双语的对话语言模型ChatGLM-6B使用LoRA进行参数高效微调,相关代码放置在GitHub上面:llm-action。
ChatGLM-6B简介
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language
Model (GLM) 架构,具有 62 亿参数。ChatGLM-6B
使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62
亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。
具备的一些能力
自我认知、提纲写作、文案写作、邮件写作助手、信息抽取、角色扮演、评论比较、旅游向导等
局限性
由于 ChatGLM-6B 的小规模,其能力仍然有许多局限性。以下是我们目前发现的一些问题:
·模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B
可能会生成不正确的信息;它也不擅长逻辑类问题(如数学、编程)的解答。
·产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。(内容可能具有冒犯性,此处不展示)
·英文能力不足:ChatGLM-6B 训练时使用的指示/回答大部分都是中文的,仅有极小一部分英文内容。因此,如果输入英文指示,回复的质量远不如中文,甚至与中文指示下的内容矛盾,并且出现中英夹杂的情况。
·易被误导,对话能力较弱:ChatGLM-6B 对话能力还比较弱,而且 “自我认知” 存在问题,并很容易被误导并产生错误的言论。例如当前版本的模型在被误导的情况下,会在自我认知上发生偏差。
LoRA 技术原理
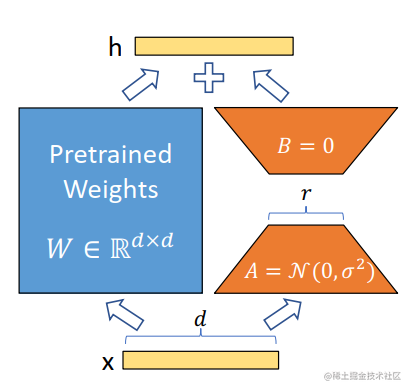
image.png
LoRA 的原理其实并不复杂,它的核心思想是在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。训练的时候固定预训练语言模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练开始时,新增的通路BA=0从,而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
LoRA 的最大优势是速度更快,使用的内存更少;因此,可以在消费级硬件上运行。
环境搭建
基础环境配置如下:
·操作系统: CentOS 7
·CPUs:单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
·GPUs: 8 卡 A800 80GB GPUs
·Python: 3.10 (需要先升级OpenSSL到1.1.1t版本(点击下载OpenSSL),然后再编译安装Python),点击下载Python
·NVIDIA驱动程序版本: 515.65.01,根据不同型号选择不同的驱动程序,点击下载。
·CUDA工具包: 11.7,点击下载
·NCCL: nccl_2.14.3-1+cuda11.7,点击下载
·cuDNN: 8.8.1.3_cuda11,点击下载
上面的NVIDIA驱动、CUDA、Python等工具的安装就不一一赘述了。
创建虚拟环境并激活虚拟环境chatglm-lora-venv-py310-cu117:
cd /home/guodong.li/virtual-venvvirtualenv -p /usr/bin/python3.10 chatglm-lora-venv-py310-cu117source /home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/bin/activate离线安装PyTorch,点击下载对应cuda版本的torch和torchvision即可。
pip install torch-1.13.1+cu117-cp310-cp310-linux_x86_64.whlpip install torchvision-0.14.1+cu117-cp310-cp310-linux_x86_64.whl安装相关的库。
pip install -r requirements.txtrequirements.txt文件内容如下:
# int8bitsandbytes==0.37.1accelerate==0.17.1# chatglmprotobuf>=3.19.5,<3.20.1transformers==4.27.1icetkcpm_kernels==1.0.11#torch>=1.13.1tensorboarddatasets==2.10.1安装PEFT,PEFT 是一个库(LoRA 是其支持的技术之一,除此之外还有Prefix Tuning、P-Tuning、Prompt Tuning),可以让你使用各种基于 Transformer 结构的语言模型进行高效微调。
git clone https://github.com/huggingface/peft.gitcd peft/git checkout e536616pip install .数据集准备
本文采用Stanford Alpaca中提供的alpaca_data.json指令数据集进行参数高效微调,但是在Alpaca-LoRA中提到该数据集存在一些噪声,因此,他们对该数据集做了清洗后得到了alpaca_data_cleaned.json文件。采用该数据集进行训练大概率会得到更好结果。
数据预处理
下载ChatGLM-Tuning代码,并切换到对应的commitid保证代码的一致性。
git clone https://github.com/mymusise/ChatGLM-Tuning.gitcd ChatGLM-Tuninggit checkout 9973930转化alpaca数据集为jsonl格式,即每行一条json语料。
python cover_alpaca2jsonl.py \ --data_path /data/nfs/guodong.li/data/alpaca_data_cleaned.json \ --save_path /data/nfs/guodong.li/data/alpaca_data_cleaned.jsonl查看结果:
> head -n10 /data/nfs/guodong.li/data/alpaca_data_cleaned.jsonl> {"context": "Instruction: Give three tips for staying healthy.\nAnswer: ", "target": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."}> {"context": "Instruction: What are the three primary colors?\nAnswer: ", "target": "The three primary colors are red, blue, and yellow."}> {"context": "Instruction: Describe the structure of an atom.\nAnswer: ", "target": "An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom."}> {"context": "Instruction: How can we reduce air pollution?\nAnswer: ", "target": "There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances."}> {"context": "Instruction: Pretend you are a project manager of a construction company. Describe a time when you had to make a difficult decision.\nAnswer: ", "target": "I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client\u2019s expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team\u2019s resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client\u2019s expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities."}> {"context": "Instruction: Identify the odd one out.\nInput: Twitter, Instagram, Telegram\nAnswer: ", "target": "Telegram"}> {"context": "Instruction: Explain why the following fraction is equivalent to 1/4\nInput: 4/16\nAnswer: ", "target": "The fraction 4/16 is equivalent to 1/4 because both numerators and denominators are divisible by 4. Dividing both the top and bottom numbers by 4 yields the fraction 1/4."}> {"context": "Instruction: Write a short story in third person narration about a protagonist who has to make an important career decision.\nAnswer: ", "target": "John was at a crossroads in his life. He had just graduated college and was now facing the big decision of what career to pursue. After much deliberation, he decided that he wanted to be an accountant and help the financially disadvantaged. He had always been good with numbers and enjoyed seeing the tangible results of his work. \n\nJohn enrolled in accounting courses and initially found it quite challenging. He had to learn multiple systems and regulations quickly, but he worked hard and eventually excelled in his studies. After a few years, John started working at an accounting firm in his city. He was eager to put his knowledge of taxes and accounting to use in a real-world setting.\n\nJohn loved his job, as it let him express his creativity in finding strategies to save his clients money. After a few years at the firm, he became a senior accountant and was asked to manage bigger and more challenging cases. He was now a respected figure in the financial industry, but he still remembers when he was just a recent college graduate, unsure of the direction in which his life would take him."}> {"context": "Instruction: Render a 3D model of a house\nAnswer: ", "target": "<nooutput> This type of instruction cannot be fulfilled by a GPT model."}> {"context": "Instruction: Evaluate this sentence for spelling and grammar mistakes\nInput: He finnished his meal and left the resturant\nAnswer: ", "target": "He finished his meal and left the restaurant."}对预处理后的语料进行分词并保存。
#预先创建输出分词后的目录
mkdir -p /data/nfs/guodong.li/data/alpaca_tokenizepython tokenize_dataset_rows.py \\--jsonl_path /data/nfs/guodong.li/data/alpaca_data_cleaned.jsonl \\--save_path /data/nfs/guodong.li/data/alpaca_tokenize \\--max_seq_length 200 \\--skip_overlength True参数说明:
·--jsonl_path 微调的数据路径, 格式jsonl, 对每行的['context']和['target']字段进行encode
·--save_path 输出路径
·--max_seq_length 样本的最大长度
查看处理之后的结果:
> ls -al --block-size=K /data/nfs/guodong.li/data/alpaca_tokenizetotal 15588Kdrwxrwxr-x 1 nobody nobody 0K Apr 13 14:06 .drwxr-xr-x 1 nobody nobody 0K Apr 13 14:06 ..-rw-rw-r-- 1 nobody nobody 15578K Apr 13 14:06 data-00000-of-00001.arrow-rw-rw-r-- 1 nobody nobody 1K Apr 13 14:06 dataset_info.json #数据集信息文件
-rw-rw-r-- 1 nobody nobody 1K Apr 13 14:06 state.json参数高效微调
单卡模式模型训练
修改finetune.py文件:
# TODO# tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)tokenizer = AutoTokenizer.from_pretrained("/data/nfs/llm/model/chatglm-6b", trust_remote_code=True)...def main(): ... # TODO """ model = AutoModel.from_pretrained( "THUDM/chatglm-6b", load_in_8bit=True, trust_remote_code=True, device_map="auto" ) """ model = AutoModel.from_pretrained( "/data/nfs/llm/model/chatglm-6b", load_in_8bit=True, trust_remote_code=True, device_map="auto" )运行命令:
python finetune.py \ --dataset_path /data/nfs/guodong.li/data/alpaca_tokenize \ --lora_rank 8 \ --per_device_train_batch_size 6 \ --gradient_accumulation_steps 1 \ --max_steps 52000 \ --save_steps 1000 \ --save_total_limit 2 \ --learning_rate 1e-4 \ --fp16 \ --remove_unused_columns false \ --logging_steps 50 \ --output_dir /home/guodong.li/data/chatglm-6b-lora运行过程:
{'loss': 2.2081, 'learning_rate': 9.991153846153847e-05, 'epoch': 0.01}...{'loss': 1.7604, 'learning_rate': 9.904615384615386e-05, 'epoch': 0.06}{'loss': 1.7521, 'learning_rate': 9.895e-05, 'epoch': 0.07} 1%|█▌ | 588/52000 [11:42<16:38:08, 1.16s/it] 貌似很慢,尝试增大batch_size和gradient_accumulation_steps来提升。
python finetune.py \ --dataset_path /data/nfs/guodong.li/data/alpaca_tokenize \ --lora_rank 8 \ --per_device_train_batch_size 32 \ --gradient_accumulation_steps 4 \ --num_train_epochs 3 \ --save_steps 1000 \ --save_total_limit 2 \ --learning_rate 1e-4 \ --fp16 \ --remove_unused_columns false \ --logging_steps 50 \ --output_dir /home/guodong.li/data/chatglm-6b-lora运行过程:
0%| | 0/1167 [00:00<?, ?it/s]{'loss': 2.142, 'learning_rate': 9.571550985432734e-05, 'epoch': 0.13}8%|██████████▊ | 89/1167 [33:17<6:30:07, 21.71s/it]速度提升上去了,但是还是在单卡模式下进行训练,下面尝试使用数据并行技术来进一步提升训练速度。
数据并行模式模型训练
首先,拷贝finetune.py文件为finetune_dp.py。
cp finetune.py finetune_dp.py然后,修改finetune_dp.py文件。
# TODO# tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)tokenizer = AutoTokenizer.from_pretrained("/data/nfs/llm/model/chatglm-6b", trust_remote_code=True, revision="")...def main(): writer = SummaryWriter() finetune_args, training_args = HfArgumentParser( (FinetuneArguments, TrainingArguments) ).parse_args_into_dataclasses() # init model # TODO """ model = AutoModel.from_pretrained( "THUDM/chatglm-6b", load_in_8bit=True, trust_remote_code=True, device_map="auto" ) """ while True: try: model = AutoModel.from_pretrained("/data/nfs/llm/model/chatglm-6b", trust_remote_code=True, revision="") break except: pass model.gradient_checkpointing_enable() model.enable_input_require_grads() # TODO #model.is_parallelizable = True #model.model_parallel = True model.lm_head = CastOutputToFloat(model.lm_head) model.config.use_cache = ( False # silence the warnings. Please re-enable for inference! ) # setup peft peft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, r=finetune_args.lora_rank, lora_alpha=32, lora_dropout=0.1, ) model = get_peft_model(model, peft_config) # load dataset dataset = datasets.load_from_disk(finetune_args.dataset_path) print(f"\n{len(dataset)=}\n") training_args.ddp_find_unused_parameters=False # start train trainer = ModifiedTrainer( model=model, train_dataset=dataset, args=training_args, callbacks=[TensorBoardCallback(writer)], data_collator=data_collator, ) trainer.train() writer.close() # save model model.save_pretrained(training_args.output_dir)注意:
chatglm加载模型时会调用transformers/dynamic_module_utils.py文件下的get_class_in_module方法,而该方法在并发情况下会存在找不到文件的问题。本文在程序中加了个while True进行简单的容错处理,因此,出现FileNotFoundError可以忽略。
运行命令:
torchrun --nproc_per_node=4 --master_port=29005 finetune_dp.py \ --dataset_path /data/nfs/guodong.li/data/alpaca_tokenize \ --lora_rank 8 \ --per_device_train_batch_size 40 \ --gradient_accumulation_steps 4 \ --num_train_epochs 3 \ --save_steps 1000 \ --save_total_limit 2 \ --learning_rate 1e-4 \ --fp16 \ --remove_unused_columns false \ --logging_steps 50 \ --output_dir /home/guodong.li/data/chatglm-6b-lora运行结果:
WARNING:torch.distributed.run:*****************************************Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.*****************************************===================================BUG REPORT===================================Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues================================================================================.../home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst')} warn(msg)CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.soCUDA SETUP: Highest compute capability among GPUs detected: 8.0CUDA SETUP: Detected CUDA version 117CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda117.so.../home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}...CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.soCUDA SETUP: Highest compute capability among GPUs detected: 8.0CUDA SETUP: Detected CUDA version 117CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda117.so......Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:16<00:00, 2.05s/it]/home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/peft/tuners/lora.py:191: UserWarning: fan_in_fan_out is set to True but the target module is not a Conv1D. Setting fan_in_fan_out to False. warnings.warn(Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:17<00:00, 2.17s/it]/home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/peft/tuners/lora.py:191: UserWarning: fan_in_fan_out is set to True but the target module is not a Conv1D. Setting fan_in_fan_out to False. warnings.warn(Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:20<00:00, 2.54s/it]/home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/peft/tuners/lora.py:191: UserWarning: fan_in_fan_out is set to True but the target module is not a Conv1D. Setting fan_in_fan_out to False. warnings.warn(Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:21<00:00, 2.63s/it]len(dataset)=49847len(dataset)=49847len(dataset)=49847len(dataset)=49847{'loss': 2.1301, 'learning_rate': 7.863247863247864e-05, 'epoch': 0.64}{'loss': 1.8471, 'learning_rate': 5.726495726495726e-05, 'epoch': 1.28}{'loss': 1.7966, 'learning_rate': 3.58974358974359e-05, 'epoch': 1.92}{'loss': 1.7829, 'learning_rate': 1.4529914529914531e-05, 'epoch': 2.56}{'train_runtime': 2654.3961, 'train_samples_per_second': 56.337, 'train_steps_per_second': 0.088, 'train_loss': 1.8721362872001452, 'epoch': 3.0}100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 234/234 [44:13<00:00, 11.34s/it]显存占用:
Thu Apr 13 20:20:05 2023+-----------------------------------------------------------------------------+| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. || | | MIG M. ||===============================+======================+======================|| 0 NVIDIA A800 80G... Off | 00000000:34:00.0 Off | 0 || N/A 67C P0 271W / 300W | 33429MiB / 81920MiB | 100% Default || | | Disabled |+-------------------------------+----------------------+----------------------+| 1 NVIDIA A800 80G... Off | 00000000:35:00.0 Off | 0 || N/A 68C P0 342W / 300W | 52621MiB / 81920MiB | 100% Default || | | Disabled |+-------------------------------+----------------------+----------------------+| 2 NVIDIA A800 80G... Off | 00000000:36:00.0 Off | 0 || N/A 68C P0 241W / 300W | 75273MiB / 81920MiB | 100% Default || | | Disabled |+-------------------------------+----------------------+----------------------+| 3 NVIDIA A800 80G... Off | 00000000:37:00.0 Off | 0 || N/A 70C P0 341W / 300W | 29897MiB / 81920MiB | 100% Default || | | Disabled |+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=============================================================================|| 0 N/A N/A 55827 C ...nv-py310-cu117/bin/python 33427MiB || 1 N/A N/A 55828 C ...nv-py310-cu117/bin/python 52619MiB || 2 N/A N/A 55829 C ...nv-py310-cu117/bin/python 75271MiB || 3 N/A N/A 55830 C ...nv-py310-cu117/bin/python 29895MiB |+-----------------------------------------------------------------------------+模型输出文件:
> ls -altotal 14368drwxrwxr-x 3 guodong.li guodong.li 86 Apr 13 20:00 .drwxrwxr-x 12 guodong.li guodong.li 206 Apr 13 11:13 ..-rw-rw-r-- 1 guodong.li guodong.li 425 Apr 13 20:00 adapter_config.json-rw-rw-r-- 1 guodong.li guodong.li 14700953 Apr 13 20:00 adapter_model.bindrwxrwxr-x 13 guodong.li guodong.li 4096 Apr 13 19:15 runs至此,整个训练过程就完成了,接下来使用生成的模型进行推理。
模型推理
新增推理代码inference.py:
from transformers import AutoModel,AutoTokenizerimport torchfrom peft import PeftModelimport jsonfrom cover_alpaca2jsonl import format_exampledevice = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")model = AutoModel.from_pretrained("/data/nfs/llm/model/chatglm-6b", trust_remote_code=True, load_in_8bit=True, device_map='auto', revision="")tokenizer = AutoTokenizer.from_pretrained("/data/nfs/llm/model/chatglm-6b", trust_remote_code=True, revision="")model = PeftModel.from_pretrained(model, "/home/guodong.li/data/chatglm-6b-lora")# TODOinstructions = json.load(open("/data/nfs/guodong.li/data/alpaca_data_cleaned.json"))answers = []with torch.no_grad(): for idx, item in enumerate(instructions[:3]): feature = format_example(item) input_text = feature['context'] ids = tokenizer.encode(input_text) input_ids = torch.LongTensor([ids]) input_ids = input_ids.to(device) out = model.generate( input_ids=input_ids, max_length=150, do_sample=False, temperature=0 ) out_text = tokenizer.decode(out[0]) answer = out_text.replace(input_text, "").replace("\nEND", "").strip() item['infer_answer'] = answer print(out_text) print(f"### {idx+1}.Answer:\n", item.get('output'), '\n\n') answers.append({'index': idx, **item})运行命令:
CUDA_VISIBLE_DEVICES=0 python inference.py运行结果:
> CUDA_VISIBLE_DEVICES=0 python inference.py===================================BUG REPORT===================================Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues================================================================================/home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst')} warn(msg)CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.soCUDA SETUP: Highest compute capability among GPUs detected: 8.0CUDA SETUP: Detected CUDA version 117CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/chatglm-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda117.so...Overriding torch_dtype=None with `torch_dtype=torch.float16` due to requirements of `bitsandbytes` to enable model loading in mixed int8. Either pass torch_dtype=torch.float16 or don't pass this argument at all to remove this warning.Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:11<00:00, 1.39s/it]The dtype of attention mask (torch.int64) is not boolInstruction: Give three tips for staying healthy.Answer: Three tips for staying healthy include: 1) eating a balanced diet, 2) getting regular exercise, and 3) getting enough rest.### 1.Answer: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.2. Exercise regularly to keep your body active and strong.3. Get enough sleep and maintain a consistent sleep schedule.Instruction: What are the three primary colors?Answer: The three primary colors are red, blue, and yellow.### 2.Answer: The three primary colors are red, blue, and yellow.Instruction: Describe the structure of an atom.Answer: An atom is a small particle of matter that contains a core of positive charge, surrounded by a cloud of negative charge. The positive charge is caused by the presence of an electron cloud, which is surrounded by an electron cloud. The negative charge is caused by the presence of an electron cloud, which is surrounded by an electron cloud. The positive and negative charges are balanced by the presence of an equal number of protons and neutrons.### 3.Answer: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.其中:Answer:是模型的输出,#### Answer:是原答案。
结语
本文主要讲述了基于ChatGLM-6B使用LoRA进行参数高效微调以及使用训练好的模型对其进行推理,后续再基于ChatGLM-6B使用其他的参数高效微调技术。
参考文档:
出自:https://zhuanlan.zhihu.com/p/621793987
Stable Video Diffusion是一种先进的生成式人工智能视频模型,将图像转换为视频,从而改变了视频生成领域。