深入探秘:百川7B大模型的训练代码解析,揭秘巨无霸语言模型背后的奥秘
发布时间:2024年06月06日
之前几期讲了大模型的一些部署相关,非常基础,感兴趣的同学可以参考下:
手把手教你部署和理解大模型,超详细步骤,包教包会!(一、环境准备篇)
手把手教你部署和理解大模型,超详细步骤,包教包会!(二、软件和部署)
本期开始,为大家讲下这些大模型是怎么训练生成的
首先,为了确保本系列的讲解流畅,我将直接深入讲解大型语言模型的代码。尽管大型模型的训练和微调涉及众多背景知识,但本系列将不会过多展开这些知识。这样做的好处是我们可以聚焦于核心内容,因为在学习过程中,一个重要的原则就是不要试图一次性理解所有内容,否则很容易忘记最初的目标。
废话不多说,让我们直接开始,全速前进!先说下大模型的理论:大模型的底座模型就是多层的transformer,由于是因果语言建模,它只用了transformer的decoder模块。以百川7B模型为例,讲解大模型训练的代码和方法:一、整体代码结构: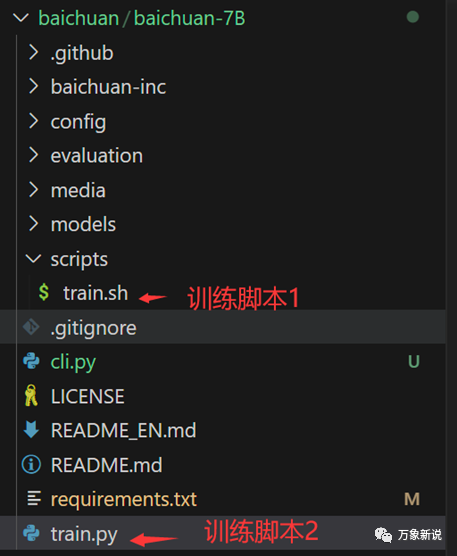
可以看到,我们训练时用到的就是train.sh,train.sh里也调用了train.py,追进去后,可以看到step2中真正用到了BaiChuanForCausalLM这个类,我们知道 ,在自然语言处理里面,有两种模型,一种是causal language modeling,它的输出是依赖过去和现在的输入;同时,还有一种是masked language modeling,它是把句子中的一个词盖住,然后通过这个词的上下文去预测这个词,具体大家可以看huggingface里的NLP课程:Hugging
Face - Learn所以,百川模型从名字上看,也是这种causal language modeling;是用之前的词预测下一词的方法。
直接跳到定义的大模型类的地方:train.py中要关注的是在哪里定义模型结构,可以看到是从BaiChuanForCausalLM中调用的,同时定义模型的还有一个配置文件,可以看到隐层的大小,decoder的层数等信息。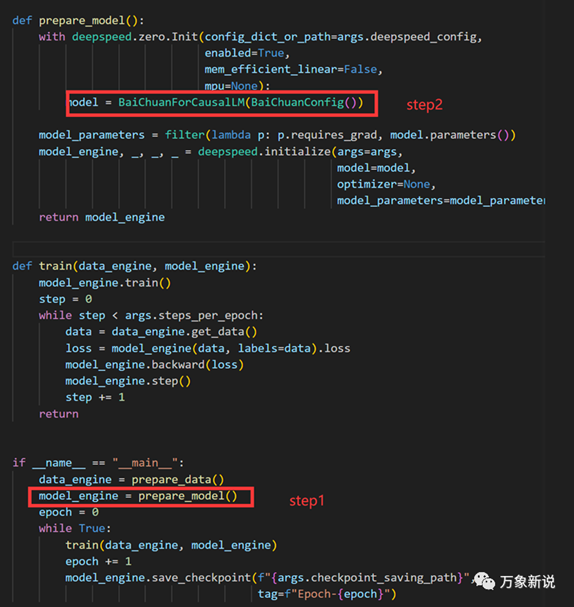 二、CML模型类:BaiChuanForCausalLM这个类主要做的就是调用多层的decoder结构,拿到最后一层的输出,然后自监督地预测下一个词,完成了训练目的,具体的是下面的步骤:1、 将上面的logits变成
二、CML模型类:BaiChuanForCausalLM这个类主要做的就是调用多层的decoder结构,拿到最后一层的输出,然后自监督地预测下一个词,完成了训练目的,具体的是下面的步骤:1、 将上面的logits变成
(bsz, seq_len-1, vocab_size), 之所以-1是因为要用之前的输入预测下一个单词2、 同样的,labels也做一个调整,整体左移一位,以与上面的logits对齐长度用一句话举例:我爱大模型,经过处理后,logits保留"我爱大模",labels保留"爱大模型" "我" ---> "爱","我爱" ---> "大","我爱大"
---> "模","我爱大模" ---> "型"代码如下: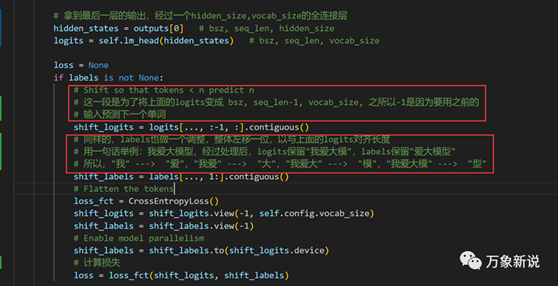
三、Model类,多层decoder结构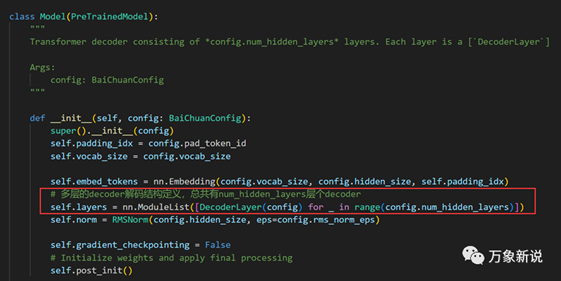
同时,对每一层输入相应的参数,并处理得到最后一层的输出
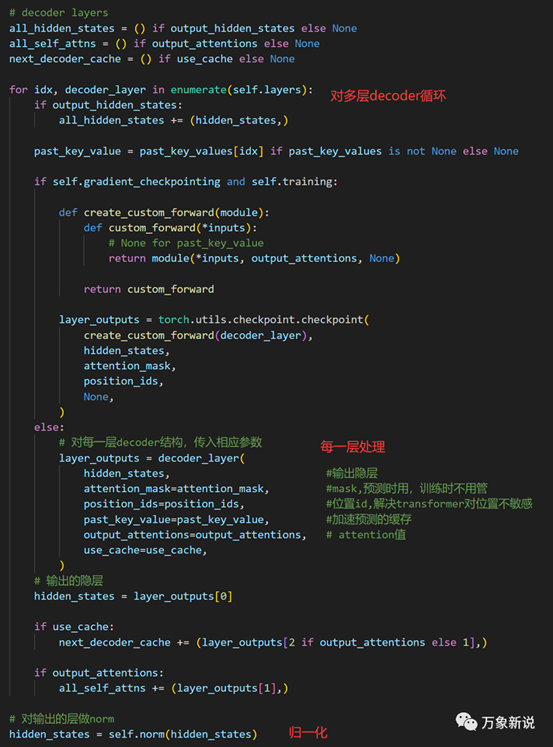
四:DecoderLayer类
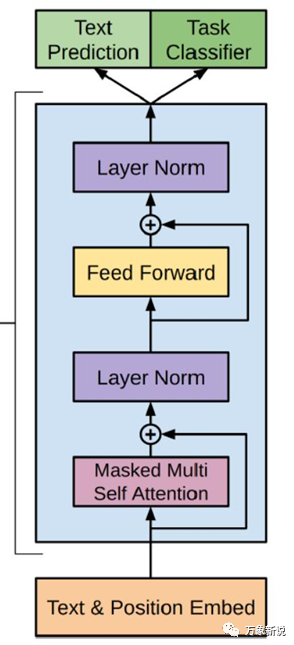
下面看一下每一层的decoder的结构是什么:
这个结构可以参考经典的tansformer
decoder结构,这个也是GPT所用的结构,代码步骤的残差,attention等都可以和这个对应上;
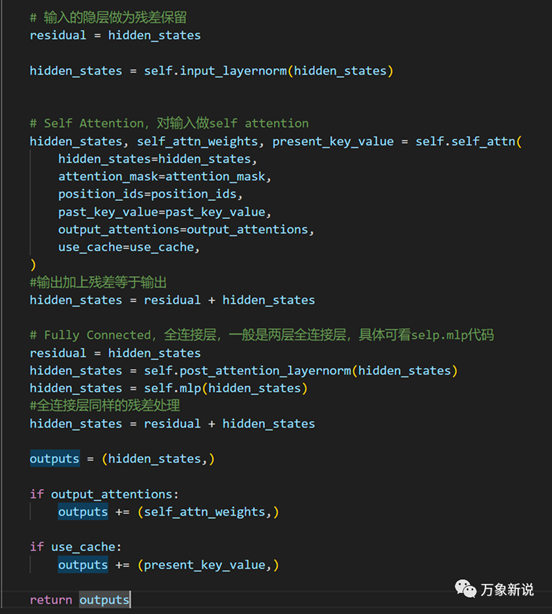
五、attention结构
最后,就是attention结构了,这部分太多文章在讲,基本就是把输入的向量通过Q,K 先变换,得到每个词对其它词的注意力,然后用注意力权重与原始的向量相乘,得到最终的输出
值得注意的点是以下几个点:
1、causal mask要体现在训练里,实现训练与推理的统一,这句代码很容易忽略
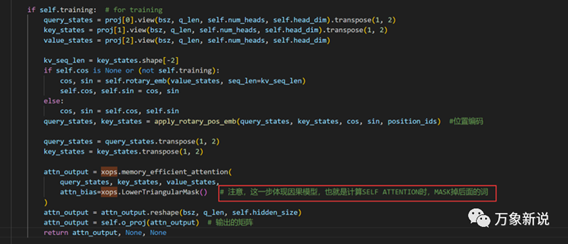
2、多头的注意力并不会增加参数量,只是把hidden_size
拆开成了head_dim 和 num_head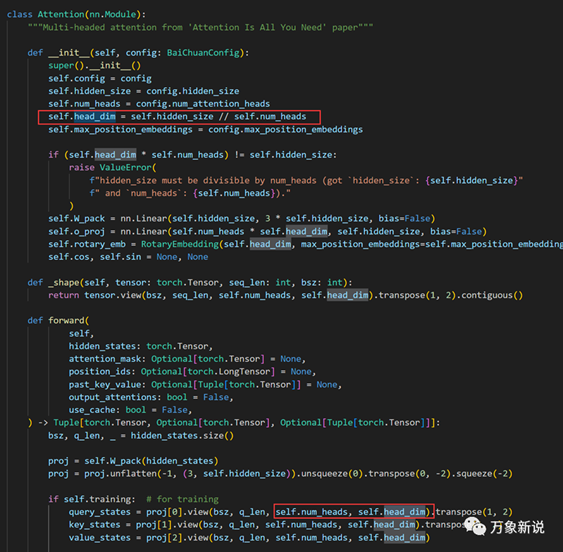
结语:
本次梳理了百川-7B的模型代码,里面还有些细节,每一个小细节都比较复杂,比如位置embedding怎么做,layer_norm是什么意思,参数量的计算,如何微调等
出自:https://mp.weixin.qq.com/s/rSEXsJxIqj9PZkw4LD6ntA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Motion Array提供了大量优质的AE、PR、DaVinci、FCPX的模板、预设、音频、视频、照片、PR插件、工具和教程等资源。是一个提供视频制作需要的免费可商用下载网站。