耗时80小时!超详细的胎教级Stable Diffusion使用教程,看这一篇就够!
发布时间:2024年06月06日
花了很长时间终于整理好了这份SD的使用教程!
从手把手安装部署,到界面功能讲解,再到实战案例制作,到下载优质模型,每一步都有详细教程
并且用一个又一个的例子展示,让大家不止是枯燥地看,而是看完立刻也能做出一样的图片出来
同时,无论是安装包,大模型,lora,关键词的文件都给大家打包好了,不用再自己这找找那找找
希望能做到让大家学SD,看这一篇就够!
一、为什么要学StableDiffusion,它究竟有多强大?
1.Stable Diffusion能干嘛
我相信大家在刷视频的时候,或多或少都已经看到过很多AI绘画生成的作品了
那SD到底可以用来干什么呢?
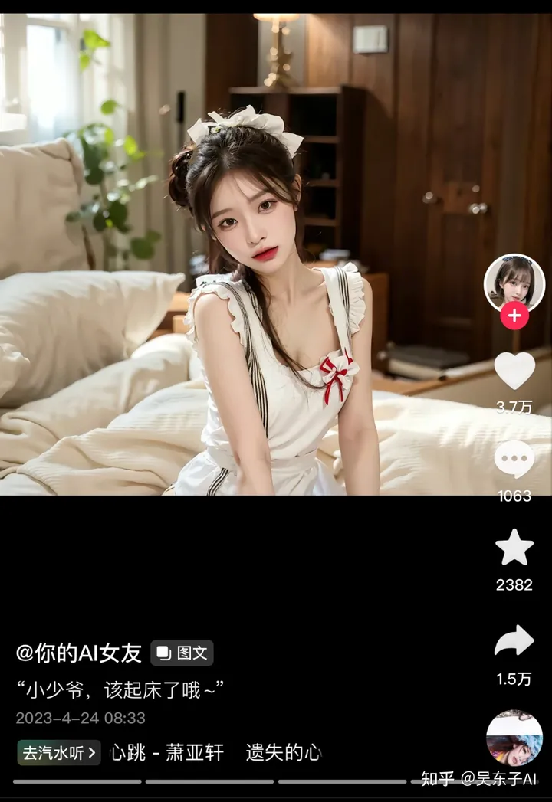
01.真人AI美女
我们最常看到的就是这些真人AI美女的账号
(我有一个朋友,每到晚上的时候,就很喜欢看这种视频)
02.生成头像、壁纸
以前很多人花钱去找别人定制自己独一无二的头像或者壁纸
现在SD就可以用来定制个人的二次元头像、盲盒模型或定制壁纸


03.绘画辅助
动漫图画、插画等都可以用SD来辅助完成
比如线稿上色、或者是获取图画的线稿等

Stable diffusion还有很多功能,比如恢复画质、室内设计等
关于Stable Diffusion的实际变现方式和变现案例,之后我也会单独写文章来说噢!
2.Stable Diffusion是什么
简单来说,Stable Diffusion(简称SD)就是一个AI自动生成图片的软件
通过我们输入文字,SD就能生成对应的一张图片,不再需要像以前一样要把图片“画”出来,或者是“拍”出来
有的人说,我学习一个软件之前是不是要先知道它的原理呢?
我的回答是:不需要!
下面这张图就是我在网上保存的SD的原理图
看得懂吗?
看不懂,我也看不懂
影响使用吗?
完全不影响!
很多人想学习stable diffusion,上网一搜,大多数教程都先告诉你SD的原理是什么
但偏偏就是这一步就劝退了很多人继续学习
因为这看起来真的好像很复杂很难
但事实是:
大多数的我们只是要能够熟练使用SD
而不是要深入研究它
我们还有自己的学习和工作
因此,我们的目的就是花更少的时间快速入门StableDiffusion
当然了,如果你的时间比较充裕,去把SD的原理也了解了也是可以的
跟大家说这些是想告诉大家
学习SD真的非常简单!!
这篇文章就会带大家通过一个个案例,实际上手操作生成各种照片
我相信在你看完这篇文章并且自己去尝试过之后
你就已经可以快速上手stable diffusion了!!
接下来我们就正式开始去使用stable diffusion!!
二、三分钟教你装好StableDiffusion
1.什么电脑能带动SD,A卡和Mac系统也不慌
为了大家能够更加顺利的安装和使用Stable Diffusion(简称“SD”)
在正式安装之前希望大家先一起查看一下自己的电脑配置,
需要注意的是以下两点:
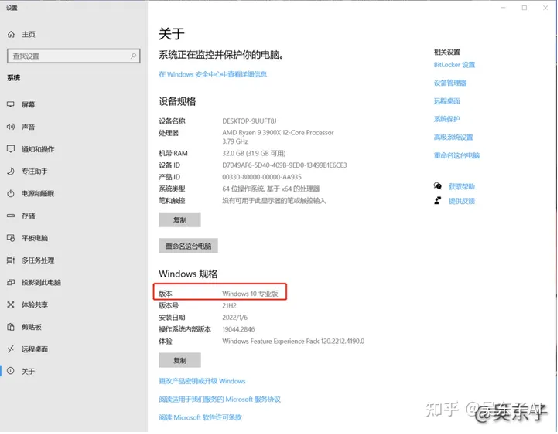
01.电脑系统是Win10或者Win11
为了避免一些奇怪的兼容性问题,不要选择更低版本的系统。
查看电脑系统的方法:
在桌面上找到“我的电脑”——鼠标右键点击——点击“属性”——查看Windows规格
02.检查电脑性能
这里是检查自己的电脑配置能不能带动SD(Stable Diffusion)
需要满足3个要求:
·电脑运行内存8GB以上
·是英伟达(俗称N卡)的显卡
·显卡内存4GB以上
检查方法:
①鼠标右击桌面底部任务栏——点击“任务管理器”
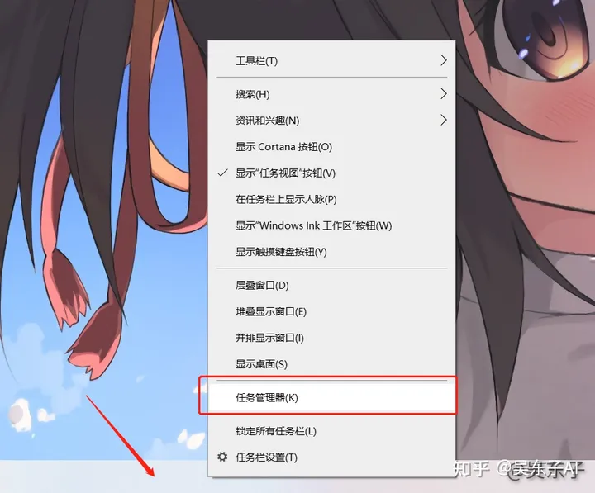
②查看电脑的运行内存
在“性能”里面找到“内存”,这里的内存不是电脑的存储内存,而是运行内存噢!
只要看图中划线的那一个参数就可以
8GB:那就说明你的电脑配置内存是勉强达到标准的
16GB:那就说明你的内存配置可以正常使用
32GB:那么你就可以非常自由的使用SD啦!
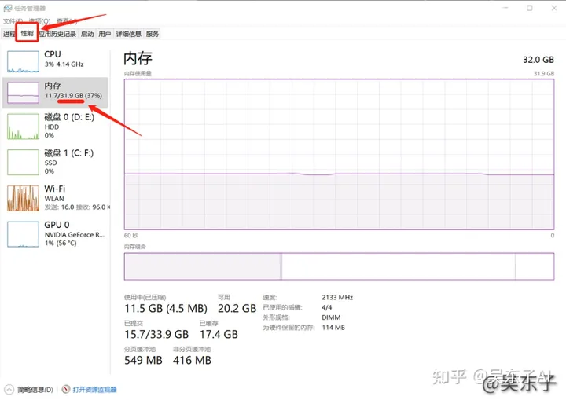
③查看“GPU”
GPU就是显卡的意思
首先先看右上角显卡的名字或者型号
必须确认的第一个是 NVIDIA ,代表的是英伟达的显卡(俗称N卡),这里是N卡我们才可以进行下一步,
如果这个地方是AMD或者是Intel,可能你的电脑会不太支持SD,网上的安装教程也比较麻烦,
大家可以看第二部分,使用云平台去玩SD
接着看到下面划线的专用GPU内存
4GB:说明电脑勉强可以跑动SD,出图的时间会比较长
6GB:出一张图的时间是20~50秒,SD的大部分功能都可以使用
8GB:5~20秒可以出一张图,基本上SD的所有功能都对你开放
好啦,如果你的电脑满足以上所说的配置,那么恭喜你!你可以顺利的安装Stable Diffusion并展开学习啦!
上面这些操作是我们用来查看Windows系统的
至于Mac系统可以看一下下面的视频
按照视频一键安装就可以啦!非常简单!
https://www.bilibili.com/video/BV1Kh4y1W7Vg/?spm_id_from=333.788&vd_source=6f836e2ab17b1bdb4fc5ea98f38df761
2.低配置电脑也能玩StableDiffusion
(电脑配置过关的朋友们,直接看第3部分安装)
刚刚查看了电脑配置,发现自己电脑可能带不动SD的朋友们也不用担心,
通过云平台,我们一样可以畅玩SD,做出好看的图片
云平台就相当于我们远程控制别人配置更好的电脑,用别人电脑上的SD生成照片
这里用的是“青椒云”,如果大家还有什么更好用的平台也可以分享出来噢!
点击下面的链接就可以下载青椒云
http://account.qingjiaocloud.com/signup?inviteCode=R0JJ9CHY
云平台使用方法:
①点击上面链接,注册账号
②下载并安装后,登录刚刚注册好的账户
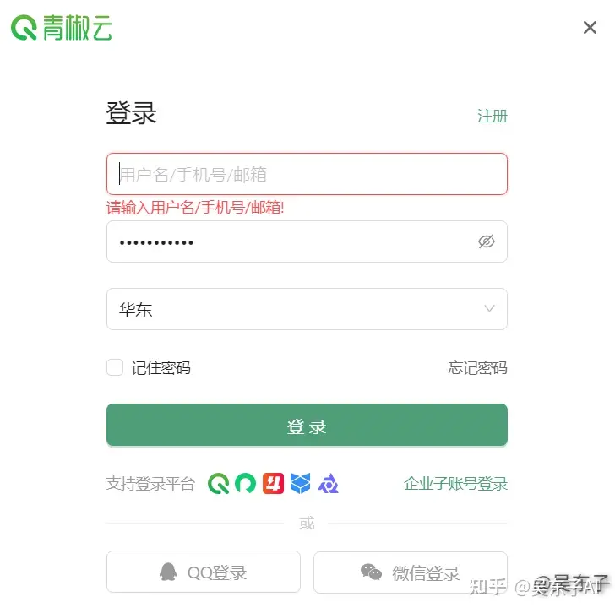
③点击右上角的个人中心进行实名认证
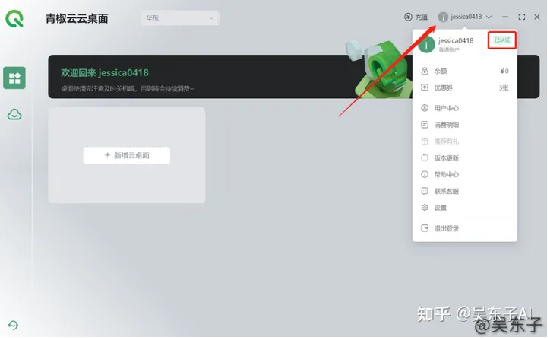
④在进行实名认证后回到主界面,点击新增云桌面
想玩Stable Diffusion可以选“AIGC尝鲜”,一般新注册的会有优惠券,可以免费试用
大家可以试试觉得好用再付费!
(大多数云平台都是2~3元一个小时)
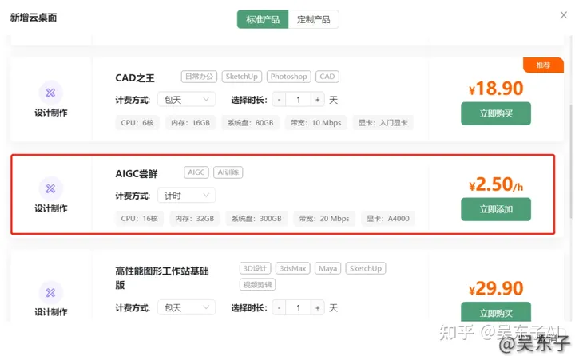
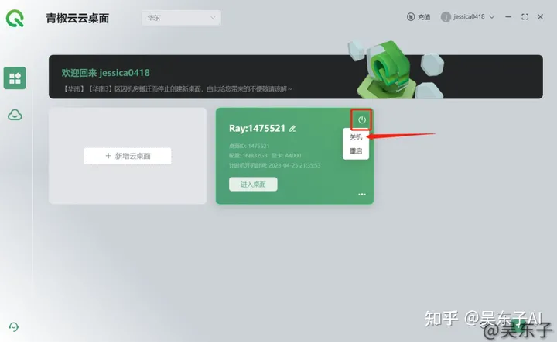
⑤在新弹出的框框中点击“开机”按钮,稍等一下之后,点击“进入桌面”
进入桌面之后弹出的全部框框可以直接关掉
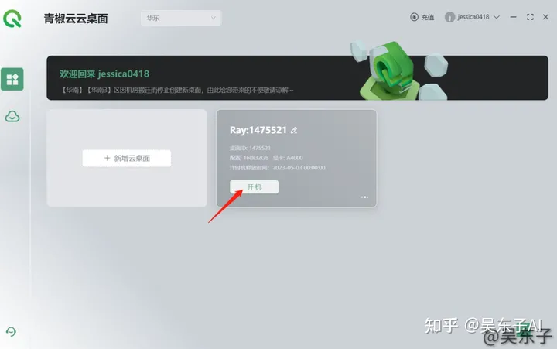
⑥点击新打开桌面的“此电脑”,在C盘里面找到SD的根目录,点击“A启动器.exe”
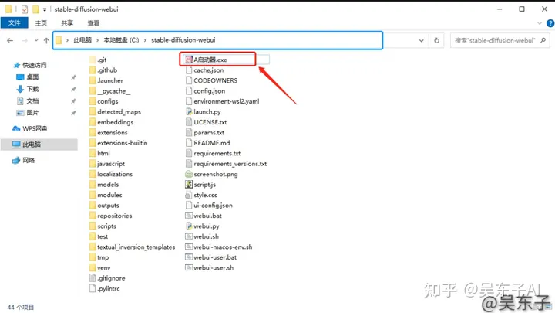
⑦点击右下角的“一键启动”就可以进入SD啦

⑧用完云平台之后,记得关机噢,不然会持续计费
3.一键式安装SD本地部署,解压即用,小白的福音
电脑配置能支持SD运行的朋友们,接下来我会手把手教你安装SD的本地部署
这里我们用到的是B站秋叶分享的整合包
小白直接下载整合包可以避免很多困难
整合包点开链接就能下载保存啦
链接:https://pan.baidu.com/s/1hY8CKbYRAj9RrFGmswdNiA?pwd=caru
提取码:caru
具体安装方法:
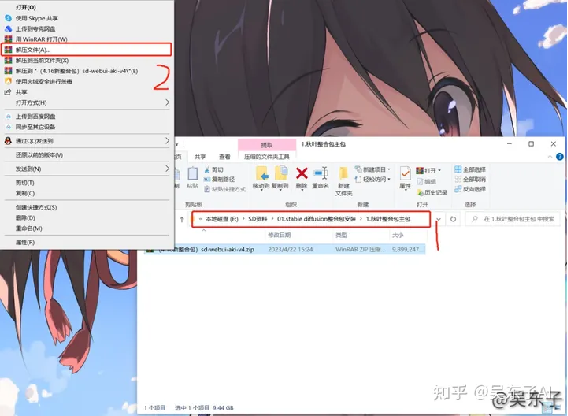
①打开上面的链接,下载《1.整合包安装》,存放到电脑本地
②打开保存到电脑里的文件夹
③打开文件夹《1.秋叶整合包主包》——鼠标右击文件——点击“解压文件”
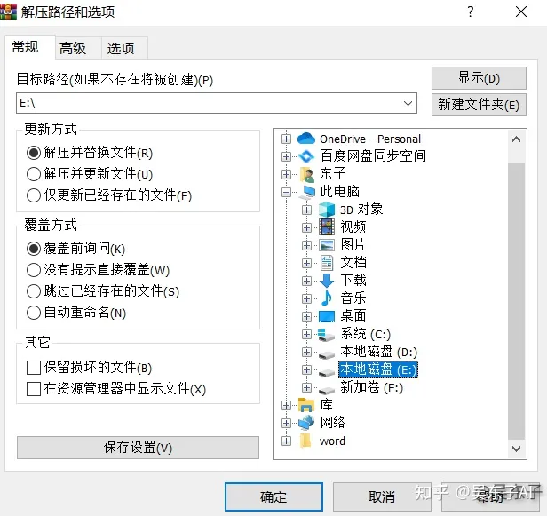
④选择解压到D盘或者E盘,小心C盘被占满!!点击确定
⑤解压完成后,来到第二个文件夹,双击里面的文件
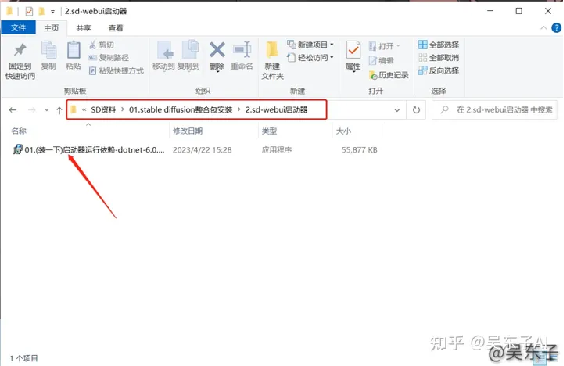
点击安装

⑥打开刚刚解压保存的SD的根目录,找到启动器
鼠标右击启动器——点击“发送到”——桌面快捷方式
这样下次进入就可以直接在桌面双击进入,不用每次都到文件夹里面找啦!

⑦双击启动器,等待更新
接着点击左边第二个“高级选项”
在显存优化里,根据自己电脑的显存选择(就是上面查看的专用GPU内存),自己电脑是多少就选多少
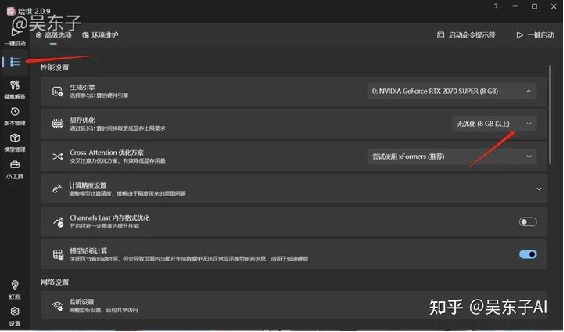
⑧回到第一个一键启动,点击右下角的一键启动
出现这个代码页面不用管,等一下就行了!SD的主界面会自动在网页上弹出来
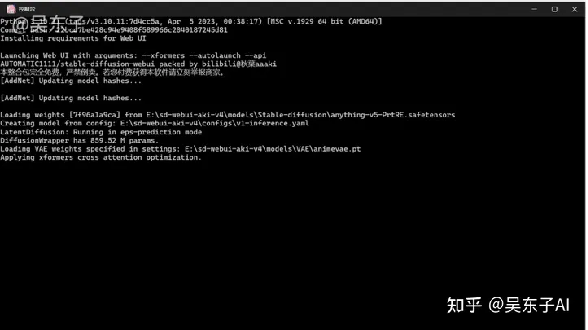
如果在上面的页面出现了报错
可以回到最开始的界面
在左边点击“疑难解答”,再点击右边的“开始扫描”
最后点击“修复”按钮
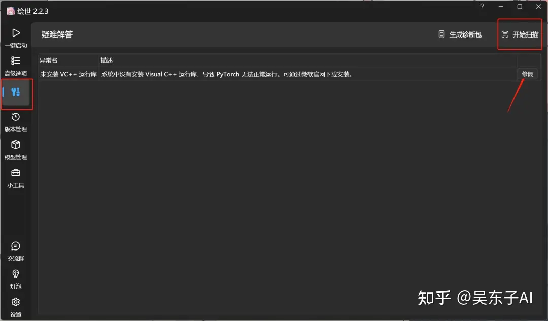
下面这个页面就是SD的主页面,大家看到这样一个复杂的页面千万不要慌
实际上有些功能在我们基础使用中用不上
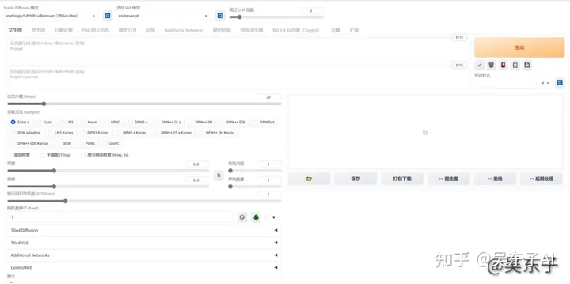
接下来我们就把常用功能配合上实际例子来讲解
三、小白快速上手StableDiffusion
1.用对模型,照片风格才对味儿
用stable diffusion可以把自己想象成一个画家
在起笔画画之前,我们要先确定我们画的是什么风格的画,
是二次元动漫、三次元的现实照片、还是盲盒模型。
因此,在我们确定了我们照片风格之后
我们就要去切换大模型,不同的模型就代表着不同的照片风格。
也就是SD界面左上角的“Stable Diffusion模型”
假如现在我想生成一个真人AI小姐姐,就选用chilloutmix的大模型
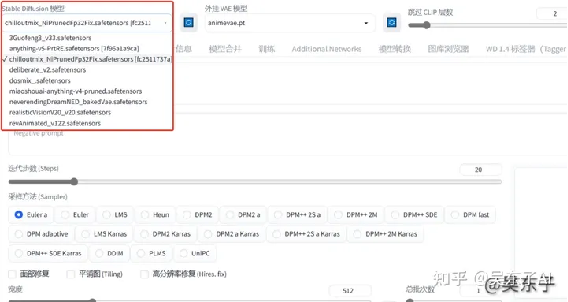
那么问题来了,我们这些模型从哪来呢?下载的模型放在哪里呢?
在我分享给大家的链接里面,有部分比较常用的大模型
(后续还有比较好的模型也会分享给大家)
大家可以根据文件夹名称找到需要的模型。
另外,这篇文章的第三部分会跟大家详细介绍去哪里下载模型,模型存放的位置,所以一定要看到最后!
2.写好关键词,让你事半功倍
选好大模型之后,我们就要考虑画面上要有什么东西,不要出现什么东西
而这就是通过输入关键词来告诉SD
我们最后要生成什么样的图画
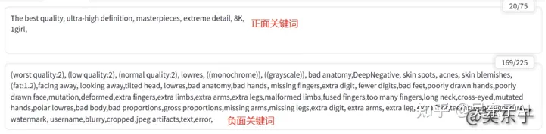
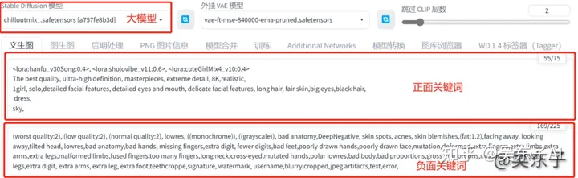
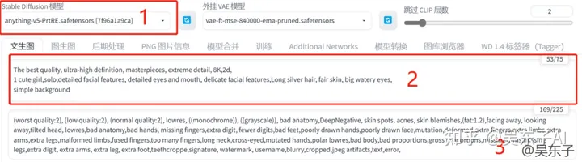
01.正面关键词
其实要生成一张照片,最重要的就是关键词,
关键词里写的就是你希望照片里会出现的内容
输入的关键词越准确,出来的照片就会越接近自己脑海里的画面

那怎么写关键词呢?
比如说我现在想要生成一个漂亮的小姐姐站在大街上
那我就可以写成:1女孩,漂亮,站着,大街
或者是:1漂亮女孩,站在大街上
又或者我直接写一个句子:1个漂亮女孩站在大街上
上面三种单词、词组、短句的方式都可以,
我们比较常用的就是直接输入一个个单词,然后这些单词用英文状态下的逗号隔开
当然了,SD只能识别英语,但我们也不用担心,直接用翻译就可以啦!
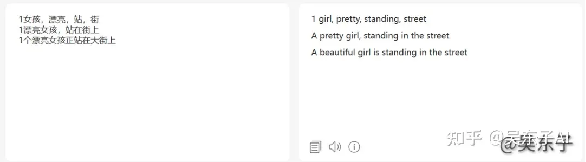
输入到SD就是这样的⬇

接着点击右边这个“生成”按钮
这样你在SD的第一张图就出来啦!

hhh是不是很多小伙伴已经按捺不住去试了试呢,出来的照片是不是有点不尽人意!
那是因为我们上面输入的关键词太过于简略啦
这里是我上面这张图输入的关键词

看到这一大串英文千万别害怕!写关键词也是有模板的!
首先上面第一行的关键词可以先不看
那是我们等一下要学到的lora模型
在写跟我们照片有关的关键词之前
我们可以先写一些照片质量的词语,这样出来的照片会更加精致
比如说我们可以写:最高质量,超高清画质,大师的杰作,8k画质等等...
翻译成对应的英文就是:Highest quality, ultra-high definition,
masterpieces, 8k quality
![]()
写完质量词,接着就是我们照片的内容
先写的就是照片的主体,和对主体的细节描写
比如我们是要生成一个女孩,就要写出来一个女孩,以及这个女孩长什么样也可以写出来
也就是:一个女孩,非常精致的五官,极具细节的眼睛和嘴巴,长发,卷发,细腻的皮肤,大眼睛
翻译成英文就是:1girl, very delicate features, very detailed
eyes and mouth, long hair, curly hair, delicate skin, big eyes,
这些照片内容大家都是可以随意改的,但是像精致的五官、细节的眼睛这类词语,大家可以都加上

写完五官之后,我们就可以想一下让照片的人物穿什么衣服,裤子,或者加上帽子之类的配饰
像裙子、毛衣、牛仔裤、比基尼都可以,还可以写上衣服的颜色
比如:白色的毛衣、项链(white sweater, necklace,)

最后我们就可以写上其他乱七八糟的东西,比如背景、天气、照片姿势、构图等等
比如说:在街上,阳光,上半身照片(street, Sunshine, upper body photos,)

好啦,这样一套下来,我们的关键词就写的差不多了
推荐大家像我这样一行一行分开类型去写关键词,这样后面想要改词更好找
但一定要注意每一行的最后要加上英文逗号,否则它就会跟下一个单词连起来变成一个新单词
总结一下我们写关键词的公式:
画质+主体+主体细节+人物服装+其他(背景、天气、构图等)


好,现在我们新生成了一张照片,但是发现她并没有我关键词里的卷发,
那我怎样才能让“卷发(curly hair)”引起Stable
Diffusion的注意呢?
那就是给关键词加权重,加权重的方法有两种:
①直接用括号把关键词括起来:(curlyhair)
这样括号一次就是1.1倍权重,那括两次((curly
hair))就是1.1×1.1=1.21倍,以此类推
注意:这里的括号也是英文状态下的括号
可以加权重,那我们也可以减权重
减权重就是用"[]"把单词括起来,如:[curly
hair]
②(关键词:数值):(curlyhair:1.3)
这就是在第一种的基础上加上数值,直接一个curly hair是1,大于1就是加权重,小于1就是减权重

02.负面关键词
当我们生成照片次数多了之后,渐渐的发现偶尔生成出来的照片多了几个手指,甚至会多了一只手
那怎么才能避免这些情况呢?
那就是告诉SD,我不要那样的照片!
所以,我们就可以通过输入负面关键词告诉SD,我不希望照片会出现什么内容

比如说我不希望照片出现:低质量,多余的手,多余的手指,不好看的脸等等...
这里就不用大家去想要写些什么啦
新手小白可以直接抄!
(worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)),
((grayscale)), bad anatomy,DeepNegative, skin spots, acnes, skin
blemishes,(fat:1.2),facing away, looking away,tilted head, lowres,bad
anatomy,bad hands, missing fingers,extra digit, fewer digits,bad feet,poorly
drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs,extra
arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated
hands,polar lowres,bad body,bad proportions,gross proportions,missing
arms,missing legs,extra digit, extra arms, extra leg, extra
foot,teethcroppe,signature, watermark, username,blurry,cropped,jpeg
artifacts,text,error

当然你如果还有什么不想出现在照片上的东西,也可以自己加上去
到这里关键词所有的内容就讲完啦!
分享的链接里还有常用的关键词分类,
还不知道写些什么的,大家可以去看看!

3.两分钟打造你的专属模特
通过输入关键词,我们已经能够生成一张稍微好看一点的小姐姐的照片了,
但是现在我想要生成5678张照片,而且我要出来的照片都是同一张脸,这怎么办呢?

这时候我们就要用到Lora模型
简单来说,Lora可以固定我们照片的特征:人物特征、动作特征、还有照片风格
点击“生成”下面的的第三个按钮,就会弹出新的选项框
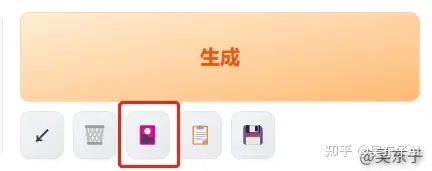
找到Lora,就会出现我们下载保存到电脑的Lora模型

点击我们要用的Lora,就会自动添加到关键词的文本框里面

前面那四张照片用到的就是这三个Lora,由此可见,我们的Lora是可以叠加使用的
但是建议新手不要使用太多lora,
因为这样照片出问题了,你也不知道是哪个Lora有问题
另外,Lora之间一样用英文逗号隔开
每个Lora后面都有数字,这是用来调整这个Lora的权重的,
正常情况下是1,我们一般只会去降低权重,因为增加权重照片可能就会变得奇奇怪怪
每个Lora设置的权重不一样,出来的照片就会不一样
想要生成一个好看的小姐姐,就要多去尝试不同的权重组合
![]()
现在问题又来了,我们怎么选择Lora呢?
这个问题就要回归到你最开始想要生成什么样的照片
你想生成真人模特,你在最开始用了真人的大模型
对应的我们的Lora也要选用真人模特
这样出来的照片效果才更好!
一些比较好看的Lora已经打包好了放在文章的末尾
后续挖掘到更好看的Lora也会分享给大家!
大家可以通过添加不同的Lora,调整权重,
生成你独一无二的小姐姐!
4.为什么你生成的图就是跟别人不一样
为什么有时候我们跟别人用的大模型、关键词、Lora还有其他参数都一样
可偏偏生成出来的图就是不一样?

那是因为影响照片的因素还有一个“随机数种子(Seed)”
随机数种子控制的是最底层的形状,就相当于我们画画最开始的线稿
它会决定我们照片的基础轮廓,相当于决定了我们照片人物的外形轮廓,包括姿势和站位等

当随机数为“-1”的时候,SD就会随机给你的照片生成一个种子,这个种子就理解成不一样的线稿就可以
怎么看自己照片用的seed值(随机数种子)是什么呢?
在我们点击生成的照片下面,有一大串英文,里面的seed值就是我们当前生成照片的seed值

只有当我们所有参数,包括随机数种子跟别人的照片都一样时,我们才能生成跟别人差不多一样的照片。
5.一分钟生成自己的二次元造型
大家有没有试过花二三十块钱,把自己的照片发给别人,让人家帮自己生成一张二次元画风的照片拿来当头像
然后别人含泪血赚19.9,还有一毛钱是电费
今天看到这篇文章你就省钱啦!
Stable Diffusion不用一分钟,不管你是要2.5D还是2D的照片,它都能生成!

这里我们用到的是图生图里面的功能
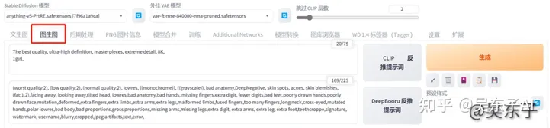
我们是要用自己的照片生成一张二次元的照片
一定要记得换大模型!!选一个能生成二次元照片的大模型就可以
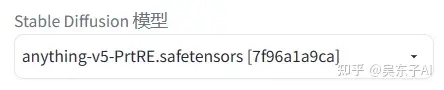
至于正面关键词呢
我们只要输入照片质量和主体的关键词就可以
比如我这里输入的就是:高质量,高清画质,大师杰作,极致的细节,8k,主体就是一个女孩
负面关键词我们就复制前面给大家的就可以啦
接着我们就在这个空白的地方点击上传自己需要生成的照片

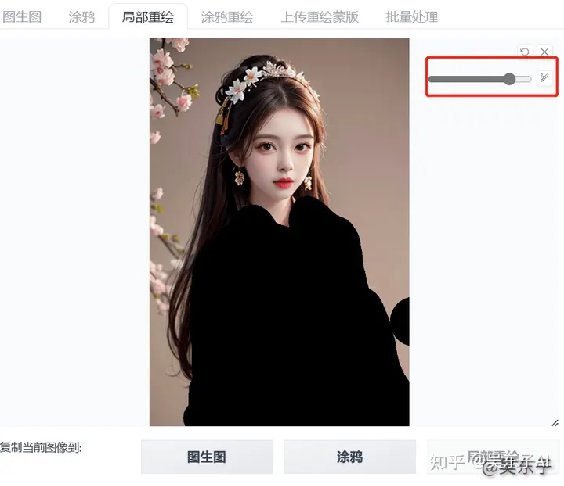
接着鼠标往下移,找到“重绘幅度”
重绘幅度的意思就是你要改变你原来照片的程度
当你的重绘幅度拉到1,这时候就相当于要完全改变你的照片,生成出来的照片就跟原先的照片毫无关系了
这里如果大家是要生成二次元照片的,把重绘幅度拉到0.6~0.8就差不多了,
大家可以多试试几个参数
![]()
这样设置下来一分钟都不用!就可以生成自己的二次元造型,大家就省下20块钱啦!
6.随便画几笔,你就是“神笔马良”
很多人都有乱涂乱画的习惯,但是大家会不会很好奇,我随便画的东西,AI会生成什么呢?
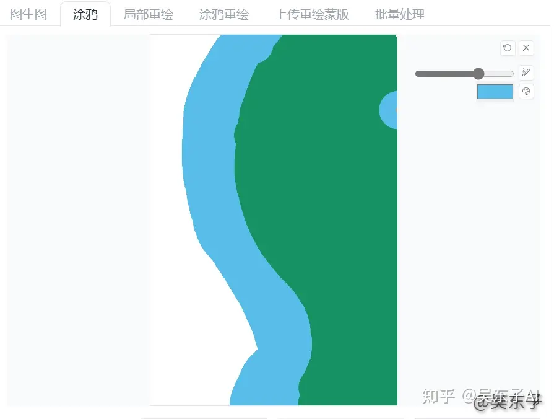
看看下面两张图,左边的图就是我在电脑上随便画的(画的很丑)
但是在我告诉SD我画的是什么之后,它直接就给我生成出来一张好看的图,
这就让我觉得我画画天赋很高了哈哈哈!!


这个就是SD图生图里的涂鸦功能,点击空白的地方上传一张纯白的图片,也就是你的画纸
右边的两个小按钮点开就可以调节画笔的大小和颜色
接着就在画纸上随便画画
然后挑合适的大模型,想要什么画风就挑什么模型
接着输入关键词
一样的,先输入一些关于照片质量的词
再告诉SD,你画的是什么
比如说我画的就是:河流,森林(river,forest)
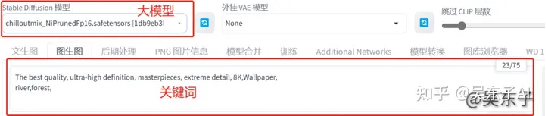
最后我们把下面的重绘幅度拉到0.6~0.8,点击生成就可以啦!
![]()
是不是非常简单,自己随便画几笔,就能生成出非常好看的照片了!
7.怎么给二次元老婆换衣服
假如我现在有一张非常好看的照片,唯独我觉得她的衣服不好看,
那我要怎么在不改变其它地方的情况下,给她换上更好看的衣服呢?

这里用到的是图生图中局部重绘的功能,导入要调整的照片
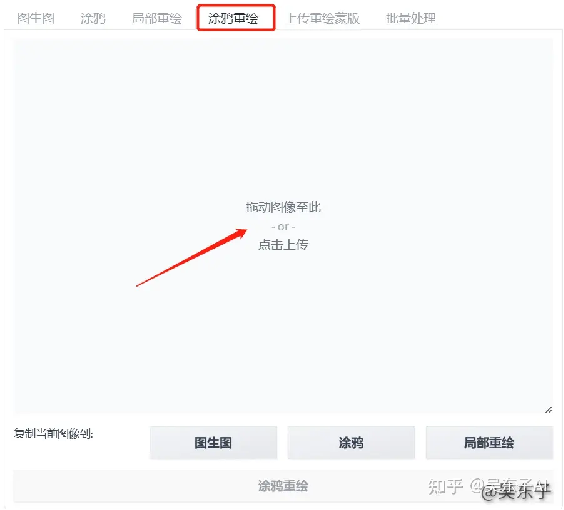
点击右边的画笔可以调整大小,把人物衣服部分全部涂黑
接着输入关键词,先输入质量词(如:高质量,高清画质,8k等)
然后描写一下你想要生成什么样的衣服
比如我这里输入的就是:粉色汉服,精致的裙子,极具细节的服装
负面关键词就直接复制我们前面用的
点击生成就可以啦!

同样的道理,我们还可以用这个功能来换脸,
只是我们涂黑的部分就变成了脸,输入的关键词就是描写脸部、五官的单词。
上面的方法用来换衣服只能整体去换,
如果我想指定衣服的颜色就只能在关键词里面告诉SD要怎么调整
假如现在我想指定服装的颜色,比如:蓝色的衣袖,粉色的衣服,还要有黄色的花纹
这时候我们只靠关键词是不行的,出来的照片也不一定准确
那我们就可以用到一个新的功能——“涂鸦重绘”
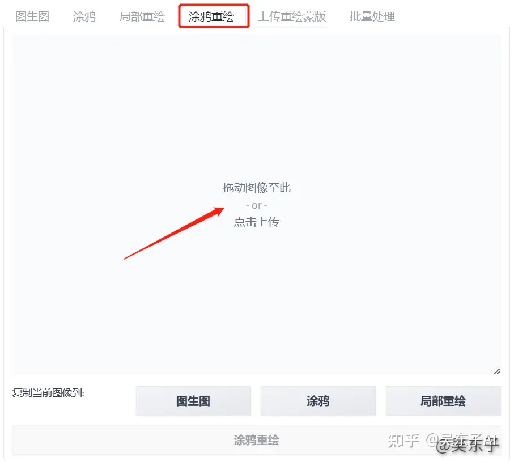
导入照片之后,在右边调整画笔大小和颜色,然后就可以自己设计衣服的颜色啦
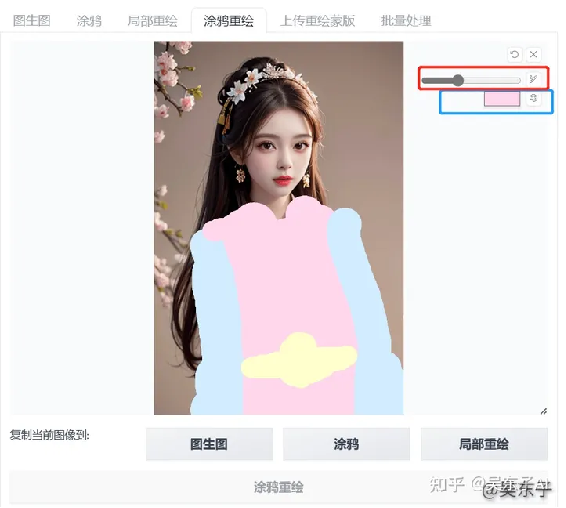
关键词就像前面说的那样输入就可以啦,
每次点击生成都能出来不一样的衣服

8.两步拯救超糊照片
SD除了生成新的照片外,还可以用来修复我们比较糊的照片
出来的效果比大多数软件都要好!


这个恢复画质的功能在SD里叫“后期处理”,点击下面空白的地方上传图片
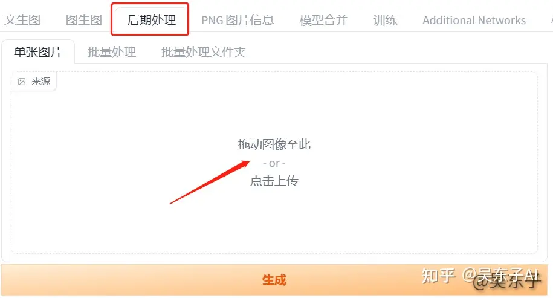
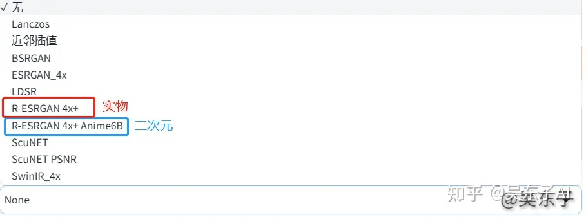
接着我们看到下面这个“Upscaler 1”,也就是放大器

修复二次元的照片就选“R-ESRGAN4x+Anime68”
其他实物照片就选“R-ESRGAN4x+”
其他放大器出来的效果都没有这两个好
最后点击生成就可以!
这个功能还可以拿来修复真人的照片,但是上面说到的流程是不适用于真人照片的
比如说我们现在要修复这张表情包

我们先把照片导入到SD
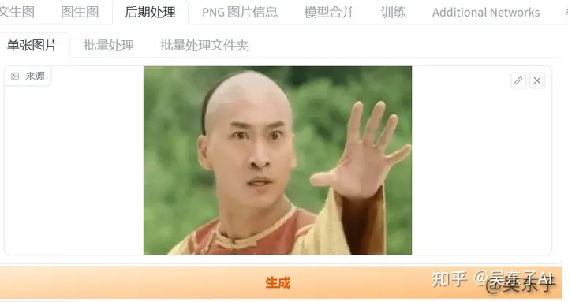
这边放大器选择“无(None)”

再往下看到这个“GFPGAN强度”
这个是专门用来修复人脸的,把参数拉满(1)就行
![]()
接着点击“生成”

这样我们的人脸就修复了,但是也只能修复脸的部分,除了脸其他的地方还是比较糊。
9.3秒教你获取大佬的咒语
在网上经常看到别的大佬的图觉得很好看,想要复制却复制不出来
但其实SD里面就有这样一个功能
把照片导进去,它就能识别出来这张照片用到的咒语或者关键词
第一个就是“PNG图片信息”

把照片导进去,右边就会自动弹出照片的信息,包括正面关键词、负面关键词,还有其他种子、大模型等信息
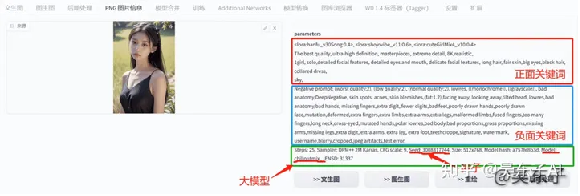
我们可以复制这一大串信息,来到“文生图”的页面,把全部信息粘贴到关键词的文本框中
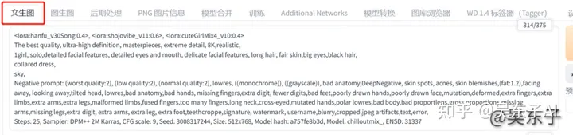
然后点击“生成”按钮下面的第一个小按钮,SD就会自动帮你把信息分配到合适的地方,用上一样的效果和模型
这时候点击生成,就能得到一张差不多一样的照片(前提是有一样的大模型和Lora)

有时候我们把照片导入进去之后,发现右边并没有照片生成的信息
那就说明这张照片不是直接从SD下载下来的PNG格式的照片
那我们就没法用这个功能
但是我们可以用后面这个“标签器(Tagger)”
它可以帮助我们生成照片的关键词
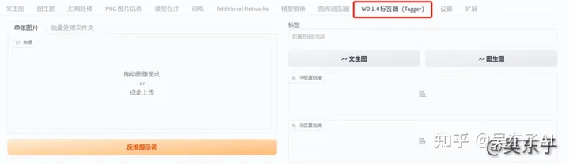
比如说我们现在导入一张照片,右边就会出来这张照片的关键词
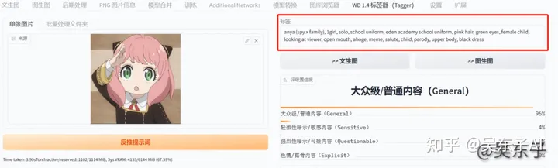
anya (spy x family), 1girl, solo, school uniform, eden academy school uniform,
pink hair, green eyes, female child, looking at viewer, open mouth, ahoge,
meme, salute, child, parody, upper body, black dress
阿尼亚(间谍 x 家庭) ,1个女孩,独唱,校服,伊甸园学院校服,粉色头发,绿色眼睛,女孩,看观众,张嘴,阿霍格,迷因,敬礼,孩子,模仿,上身,黑色礼服
可以看到这样出来的关键词还是非常准确的,
通过这两种方法,我们就可以获取到好看的照片的重要信息!
10.一招让你自由指定女神的姿势
现在我们已经能够生成美女的照片了
可以定制出独一无二的脸,换上更好看的衣服
但是我们怎么才能让照片的小姐姐摆出指定的姿势呢?
通过关键词去描绘动作,可是出来的照片又不太准确
通过图生图去生成,可是人脸又变了
那我们就可以用到这个“ControlNet”功能,翻译成中文就是控制网络
简单来说就是可以用它控制照片的线条,比如人物的动作、建筑物的线条等
![]()
比如,我现在想让左边照片的小姐姐摆出右边小姐姐的姿势,得到最右边的一张照片

首先,大模型和关键词我们还是正常的填写
生成一张我们我们想要的小姐姐的照片
接着鼠标滑到最下面,点击“ControlNet”
![]()
①点击空白的地方,上传我们需要指定的姿势的照片
②点击“启用”
③在“预处理器”和“模型”里选择“openpose”,这就是用来让计算机识别人物姿势的

下一步就点击这个“预览预处理结果”

接着原来照片的右边就会出现人物姿势的线条,最后点击生成照片
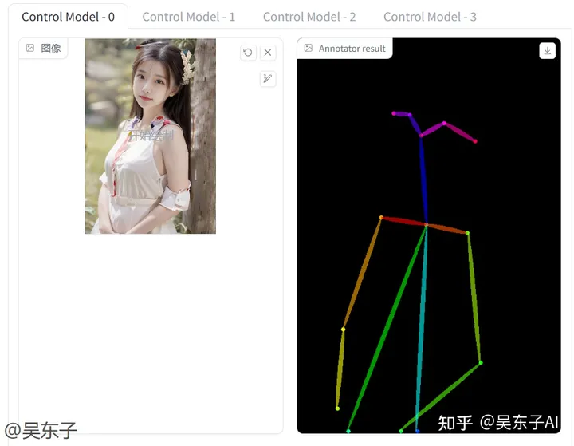
这样我们一张指定姿势的美女小姐姐就生成啦!

11.插画师的福音,线稿秒上色
随着AI绘画越来越火,很多人都会说将来可能很多画师的职业都受到威胁了
但是,会用AI绘画的画师一定会比那些不会AI绘画的画师更有优势
当别人为了给线稿上色,花了一天的时间
而你一分钟不到就出了一张质量不错的图
单是工作效率上就领先别人很多了
下面这张就是我在网上随便找的一张线稿图,通过SD上色出来的一张照片
这也是通过使用“ControlNet”这个功能生成的

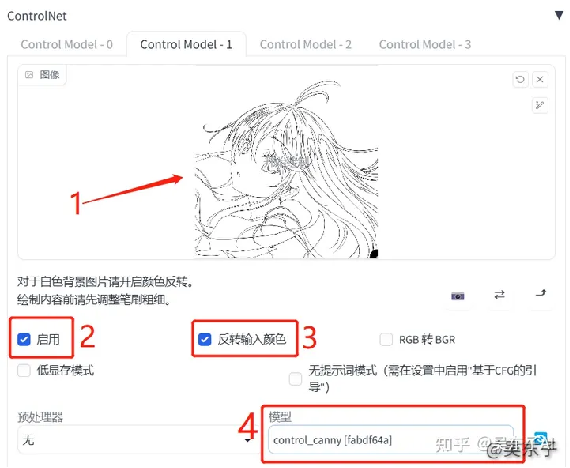
首先,我们点开"ControlNet"的状态栏
①在空白的地方上传自己的线稿图
②点击“启用”
③点击“反转输出颜色”
④在模型里面选择“canny”的模型
接着去设置我们前面的内容
①选择合适的大模型
我想要生成二次元的图,就要选择相应的模型
②关键词
跟我们写关键词一样,先写照片质量的关键词(比如:最高质量,大师杰作等)
接着我们就可以指定上什么颜色了
比如我输入的就是:1可爱女孩,五官精致,精致眼睛和嘴巴,银色长发,白皙的皮肤,水汪汪的大眼睛,
最后还加上一个简单的背景
想要色彩更加细节,就可以通过输入更多的关键词来控制照片
负面关键词只要复制前面的就可以
就这样不管再复杂的线稿,在SD里面都可以很快速的上好颜色

12.小白也能进行室内设计
“ControlNet”还有一个非常好用的功能,
那就是进行室内设计
比如说我现在想对房间进行重新装修
我想看看我的房子弄成不同的风格是怎样的

首先先点开“ControlNet”的状态栏
①上传需要进行设计的房间照片
②点击“启用”
③预处理器和模型都选“msld”,这是用来计算房屋线条的
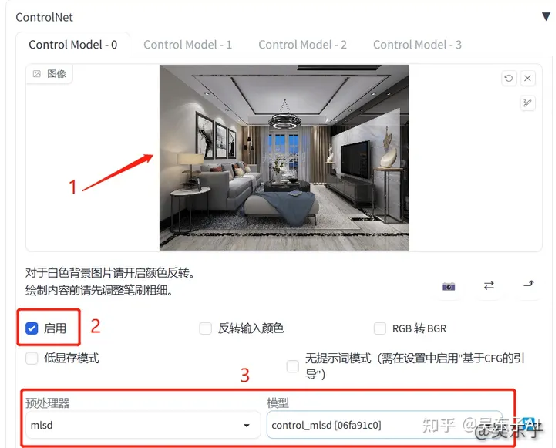
接着切换一个现实照片的大模型
关键词先输入照片质量关键词
然后就是输入照片的主体:一个客厅
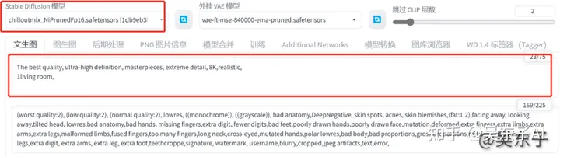
最后点击生成
这样出来的照片既保留了原来房子的构造,又可以看到新的房屋风格!
四、Stablediffusion知识补充
这一节是SD剩余功能的一些补充知识,大家不用担心SD功能太多太复杂,
这一节大多数功能的参数只要照抄就行!
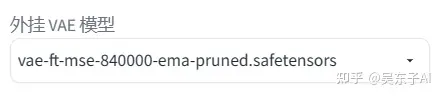
1.VAE
作为新手小白,我们没必要知道它的基础工作原理
只要知道VAE的作用就是加滤镜和微调照片
下面图片就是没加VAE和加了VAE的区别
没加VAE的照片是灰蒙蒙的

但在一般情况下,如果我们对照片的色彩没有特别要求的时候,只选定一个VAE来使用就可以。
下面这个就是我比较常用的VAE
2.迭代步数
简单的说,我们把在SD生成图片的过程当作在画画
迭代步数的意思就是我们在这幅画上画多少笔

一般我们把参数设置在20~30之间
看下面的图,20步以下的图质量都不高
但不是说步数越多越好
超过30步部分电脑可能就带不动,无法生成照片了
所以,电脑配置稍微低一点的就设置在20~25
电脑配置比较好的就可以设置在25~30之间

3.采样方法
采用方法的不同就相当于我们画画的方式不一样
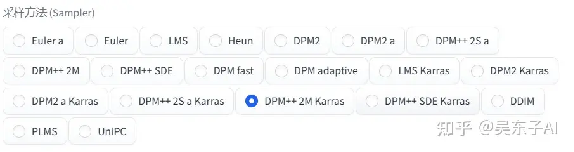
那这么多采用方法怎么选呢?
首先,我们看到别人好看的照片,可以看看人家用的是哪一个采用方法
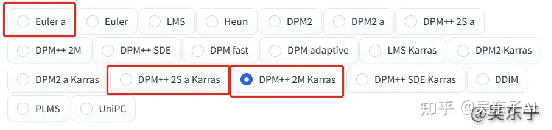
如果实在不知道用哪一个,这里也给大家测试过了,
用下面框出来的几个,出来的照片质量比较高,而且出图速度也比较快
4.面部修复+高分辨率修复
这两个功能没什么好讲的,大家直接抄作业就可以!
面部修复:用在生成真人照片上
高分辨率修复:电脑配置好就可以用;电脑配置稍微差点的别开,否则照片无法生成

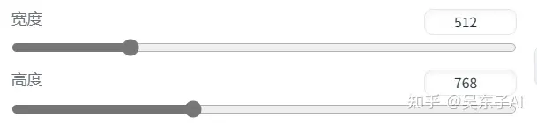
5.图片分辨率(图片大小)
这里的宽度和高度就是用来调节照片大小的
一般情况下:
生成正方形的照片:宽度512*高度512
生成长方形的照片:宽度512*高度768
电脑配置稍微差点的朋友们,千万别看网上设置成什么1024、2048,我们电脑跑不动哒!
6.生成多图
通过调整下面这两个参数,可以让我们一次生成多个图
假如我们把两个参数都设置成2

总批次数的意思就是生成两批
单批数量的意思就是一批生成两张照片
所以一共就会生成4张照片
在我们日常使用需要生成多张照片的
我们只调整“总批次数”就可以啦,这意味着我们照片是一张一张生成的
单批数量就意味着同时生成多张照片,这对我们的显卡是有一定要求的,所以这个不要用!!
7.用脚本进行照片对比
我们生成一张照片会输入很多的关键词,
那我们怎么才能看到输入不同的关键词,
出来的照片有什么区别
或者加某个关键词和不加的区别呢?
那我们就要用到最下面“脚本”里的“提示词矩阵”,直接点击就可以
接着来到关键词的文本框
我们前面一直说在写关键词之前,先写照片的质量词
那我们就以这张照片为例子,
看看加上最高质量(the best quality)和不加有什么区别

书写的格式:把需要进行对比的关键词放在最后,用“|”把关键词和前面的关键词分隔开
也就是:关键词|需要对比的关键词

点击生成就会出现两张拼在一起的照片,
我们就可以看到加了“最高质量(the best quality)”的照片会更加清晰

那如果现在想要比较不同的采用方法下,迭代步数不一样,生成的照片有什么区别,该怎么操作呢?
这里用到的就是脚本里的“X/Y/Z图表”
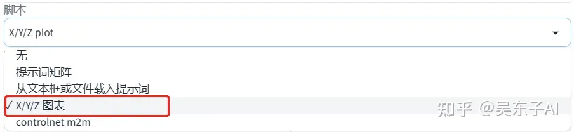
在X轴类型里面选择“迭代步数”,右边的X轴值就输入需要进行比较的步数

在Y轴类型里面选择“采用器”,接着点击最右边的笔记本图标
那样所有采样器的名称都会出现在框框里面,可以自己进行删减
我们这里就选三个比较常用的采样器

这边X轴和Y轴的信息是可以全部换过来写的,看个人习惯
点击“生成”
就会生成这么一张大图
我们就可以看到在不同的采用方法下,迭代步数为25的时候,生成出来的照片都差不多
这样比较下来,我们就可以选择自己更喜欢的采样方法和迭代步数

五、大神的模型从哪来
1.模型在哪下载
除了链接里面给大家分享的模型,大家肯定还想去找更多更好看的模型
而大多数的模型都是在Civitai(C站)这个网站里面https://civitai.com/
现在就给大家说一下C站的使用方法:
01.科学上网
这个没法教,大家只能自己想办法了
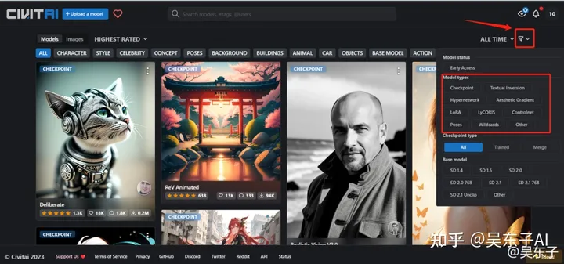
02.点击右上角的筛选按钮,在框框里面找到自己需要的模型类型
Checkpoint=大模型
LoRA=Lora
常用的就是这两个
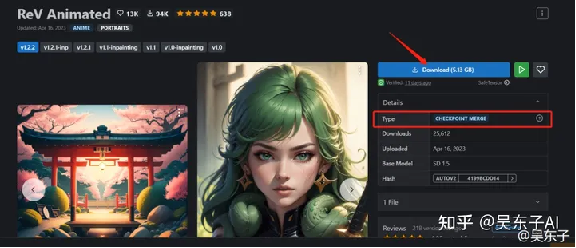
03.看照片,看到感兴趣的就点进去
点击右边的“Download”,也就是下载,保存到电脑本地,
文件保存到哪里在这一节的第二部分
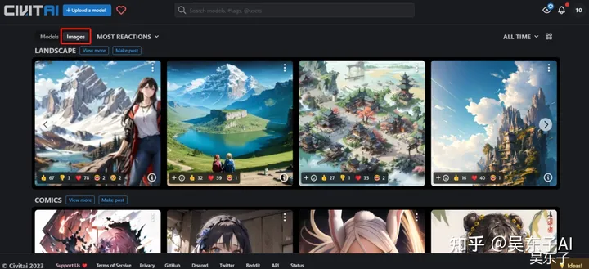
另外,我们还可以点击左上角的“Images”
这里就是看别人已经做好的图片,找到喜欢的点进去
点进去之后的页面我们就可以看到这张图的全部信息,
直接点击Lora和大模型,可以直接跳转到下载页面
下面的就是照片关键词和其他信息
点击最下面的“Copy...Data”就可以复制图片的所有信息

回到SD,粘贴到关键词的文本框,点击右边的按钮
这些信息就会自动分配
要注意的就是,大模型是需要我们手动去换的!
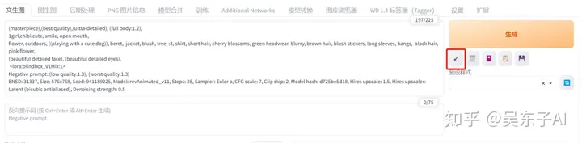
这样我们就可以生成出跟大神几乎一样的照片了!(电脑网络配置的不同,出来的照片有细微差别)

2.模型下载到哪里
这里大家就直接看我文件的保存地址,找到自己电脑里的
01.大模型
这里的SD根目录就是大家在下载时,存放SD的那个文件夹

02.Lora
![]()
03.VAE

3.如何分辨模型
如果我们下载了一个模型,但不知道它是哪个类型的,不知道要放到哪个文件夹
我们就可以用到这个秋叶的模型解析工具https://spell.novelai.dev/
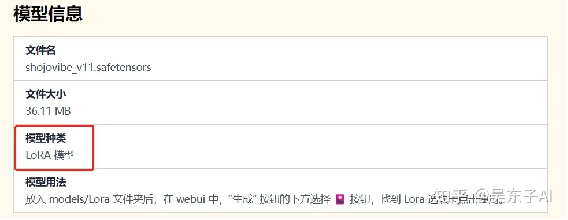
把模型拖动到空白处

接着就会自动弹出模型的信息
在模型种类里面就可以看到是什么模型啦!
六、结尾
关键词链接:吴东子的关键词分类查询 - 飞书云文档 (http://feishu.cn)
安装包,大模型,lora:
链接:https://pan.baidu.com/s/1hY8CKbYRAj9RrFGmswdNiA?pwd=caru
提取码:caru
好啦,希望这篇文章能够真正帮助到你上手SD
出自:https://zhuanlan.zhihu.com/p/638775487
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
AIShort 提供一份简便的 ChatGPT 指令列表,可迅速筛选和查询适应各种场景的提示词,从而帮助用户精简操作过程,并提供了浏览器插件方便直接调用。