关于大模型驱动的AI智能体Agent的一些思考
发布时间:2024年06月06日
众所周知,大模型可以写好的文案、故事、散文和程序,而随着AutoGPT, GPT-Engineer and BabyAGI等项目的火爆,以LLM(large language model) 作为核心控制器来构建agents,通过集成不同系统、工具自主决策完成各类复杂任务,正在成为自主人工智能新的创新方向。
注意:这里是让LLM去做事,不是去对话。
一、人是如何做事的?
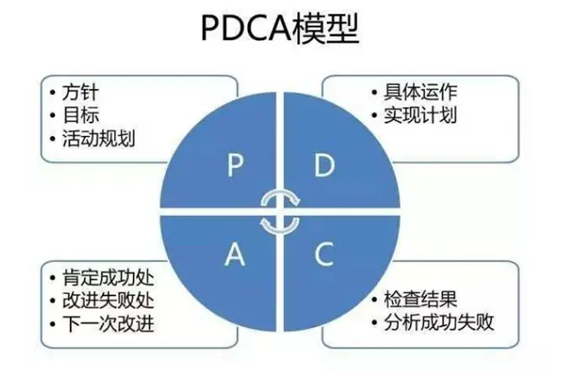
在工作中,我们通常会用到PDCA思维模型。基于PDCA模型,我们可以将完成一项任务进行拆解,按照作出计划、计划实施、检查实施效果,然后将成功的纳入标准,不成功的留待下一循环去解决。目前,这是人们高效完成一项任务非常成功的经验总结。
P (plan) 计划:包括数据收集,方针和目标的确定,以及活动规划的制定。
D (Do) 执行:根据设计和布局,进行具体运作,实现计划中的内容。
C (Check) 检查:总结执行计划的结果,分清哪些对了,哪些错了,明确效果,找出问题。
A (Act)处理:对总结检查的结果进行处理,对成功的经验加以肯定,并予以标准化;对于失败的教训也要总结,引起重视。对于没有解决的问题,应提交给下一个PDCA循环中去解决。
二、如何让LLM替代人去做事
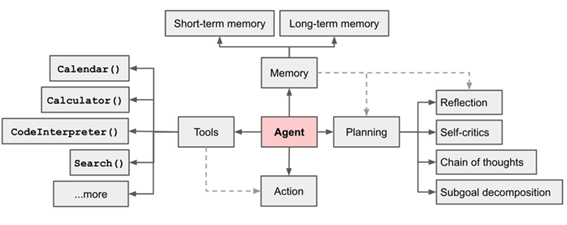
LLM要想作为agent的大脑替代人去自主工作,必须具备以下能力:
规划能力(Plan)
分解任务:
Agent大脑把大的任务拆解为更小的,可管理的子任务,这对有效的、可控的处理好大的复杂的任务效果很好(这个是LLM天然具备的能力)。
思考:
LLM作为大脑我们需要的是全局思维能力;因此,需要通过更多的指令微调来提高LLM的通用推理能力,而不是面向某个领域的专项微调。另外,LLM的能力通常是看的多了就学会了,即一种集众人之力形成的通用能力(行业解决方案),但是缺少个性化。某些时候我们面对的任务往往还会有很多个性化限制条件。例如:某类资源受限,如何在受限条件下进行任务分解可能是我们的一个创新方向。
执行能力(Done)
使用工具:
Agent能学习到在模型内部知识不够时(比如:在pre-train时不存在,且之后没法改变的模型weights)去调用外部API,比如:获取实时的信息、执行代码的能力、访问专有的信息知识库等等。
思考:
这是一个典型的平台+工具的场景,我们要有生态意识,即我们构建平台以及一些必要的工具,然后大力吸引其他厂商提供更多的组件工具,形成生态。
评估能力(Check)
确认执行结果:
Agent要能在任务正常执行后判断产出物是否符合目标,在发生异常时要能对异常进行分类(危害等级),对异常进行定位(那个子任务产生的错误),对异常进行原因分析(什么导致的异常)。
思考:
这个能力是通用大模型不具备的,需要针对不同场景训练独有的小模型。
反思能力(Action)
基于评估结果重新规划:
Agent要能在产出物符合目标时及时结束任务;同时,进行归因分析总结导致成果的主要因素(生成BI报表),另外,Agent要能在发生异常或产出物不符合目标时给出应对措施,并重新进行规划开启再循环过程。
思考:
这个是整个流程最核心的部分,是LLM自主工作(越用越聪明)的核心所在,需要重点创新。
参考:
ReAct (Yao et al. 2023) ,语言模型中推理和动作的协同作用,一种比CoT更好的提升LLM推理能力的prompt 设计方式。参考:REACT:语言模型中推理和动作的协同作用。
ReAct prompt template 一般包含如下的内容:
Thought: ... Action: ... Observation: ... ... (Repeated
many times)
这是一种新型的基于提示的范式,将语言模型中的推理和行为协同起来,我们可以这方式微调LLM(让模型形成反思),最后在推理阶段输入thought,observation,让LLM预测下一步Action。
Reflexion (Shinn & Labash 2023) ,Reflexion 代理通过语言反思任务反馈信号,然后将其自己的反思文本存储在一个情节性记忆缓冲区中,以在后续试验中促进更好的决策。
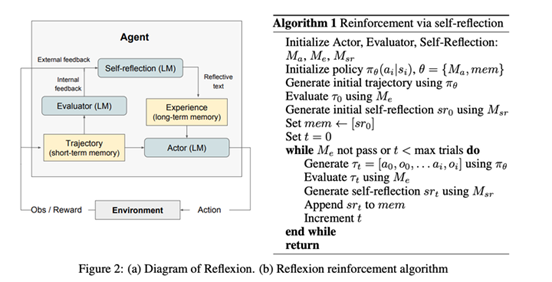
个人观点:
我认为LLM像人脑一样需要记忆的是概念以及运用概念的能力(概念组合的方法,概念拆解的方法,概念转化的方法),LLM中的token=人脑中的概念,LLM的网络结构MLP+attention机制=运用概念的能力。其他的都是信息,可以通过工具随时重新获取不需要记忆(input=上一步的output,都是信息),为了加快计算速度可以暂时放在缓存中(临时记忆随时可以忘掉),通常只需用工具将其管理起来就可以(能存能查,人用记事本,Agent可以用DB)。
因此,我认为prompt都是任务目标(信息),可以分为当前目标和长期目标。
三、现有的技术路线
HuggingGPT+微软的Jarvis
JARVIS 由微软发布,作为 AI 控制器系统运行。可以同时控制多个 AI 模型以完成多模态多任务。HuggingGPT 是一个旨在解决 AI 任务的系统,它使用语言作为接口,将大型语言模型 (LLM) 与各种 AI 模型连接起来。主要思想是使用 LLM 作为控制器来管理 AI 模型,并利用来自 Hugging Face 等社区的模型来解决不同的用户请求。它首先应用LLM来理解用户请求并将其分解成小任务,然后将这些任务分配给不同的功能模型来完成,最后再次使用LLM将结果汇总为最终输出。
工作流程:
·
任务规划:LLM
了解用户的请求,并根据需要将其分解为子任务。
·
·
模型选择:LLM根据每个子任务的描述选择最合适的专家模型。
·
·
任务执行:HuggingGPT
使用选定的模型执行任务,整合它们的结果以提供全面的响应。
·
·
生成回复:LLM整合所有模型的计算结果,为用户生成回答。
·

评价:
javis只提供了一轮最简版基于LLM的智能Agent做事的Framework(plan+do),缺乏自主优化机制的设计(无check + action),即通过反思的再规划能力。
基于开源框架LongChain的BabyAGI
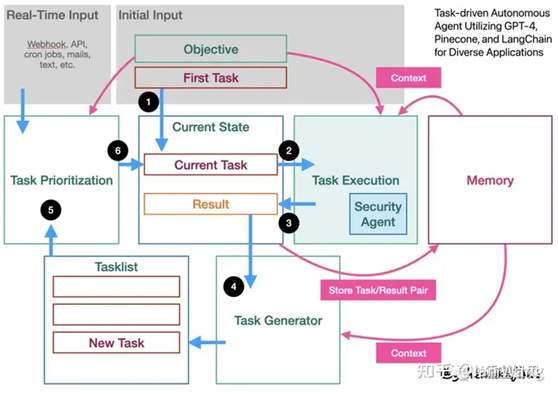
BabyAGI 是task-driven autonomous agent的简化版本。Task-driven
autonomous agent任务驱动的自主代理是一个智能系统,它利用 OpenAI 的 GPT-4 语言模型、Pinecone 矢量搜索和 LangChain 框架来执行跨不同领域的广泛任务。主要有四个模块,包括完成任务、根据完成的结果生成新任务、实时确定任务的优先级、历史任务和结果存储,所有这些都在约束和上下文中进行。
工作流程:
·
用户给出目标要求和第一个任务,也是当前要执行的任务
·
·
将任务放入一个安全代理,安全代理有助于确保系统生成的输入和输出符合道德和安全准则,降低意外后果的风险
·
·
安全代理返回安全合规的结果
·
·
利用ChatGPT的能力作为任务生成器(Task Generator),生成新的任务(New Task),放入任务清单(Tasklist)
·
·
依据规则或者外部要求,安排任务优先级( Task Prioritization)
·
·
按照优先级顺序生成当前要执行的任务(Current Task)
·
评价:
longchain提供了一个升级版基于LLM的智能Agent做事的Framework。进化点:基于任务清单这个数据结构,通生成新的任务New Task以及重排任务优先级这个两个机制,实现了最基本的反思+再规划能力。
四、实际案例
任务:面向金融行业如何通过电销方式实现年贷款XXX亿
约束条件:线路资源
可用工具:ICC系统,数据库系统等
参考信息:LLM给出的任务分解。
![]()
出自:https://mp.weixin.qq.com/s/3HXt1QFCyCwq_TNCl2UMEw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
趣问问AI,人工智能chat,你的生活工作好帮手,高效率的AI智能聊天机器人助手、助理。AI写xhs文案、方案、代码、公文AI论文、脚本、知识问答、语言翻译,只需AI对话问一问。