大模型LLM基础|分词
发布时间:2024年06月06日
分词是NLP中的关键预处理步骤之一,用于将文本分解为词或子词的组合,使机器更好地理解和分析文本。
1. 规则分词
基于预定义的规则,如空格和标点符号进行文本分割。
例子:
text = "我喜欢学习自然语言处理。"
tokens = text.split()
2. 统计分词
通过分析语料库中的统计信息来发现最有可能的分词方式。常用方法包括n-gram模型和隐马尔可夫模型(HMM)。
例子:
from jieba import cut
tokens = cut("我喜欢学习自然语言处理。")
3. 基于词典的分词
基于词典的分词使用一个预定义的词汇集进行分词,通常涉及最大匹配算法。
例子:
from jieba import cut
tokens = cut("我喜欢学习自然语言处理。", cut_all=False)
4. 基于机器学习的分词
基于机器学习的分词方法通常使用诸如条件随机场(CRF)、长短时记忆(LSTM)等算法,学习从标注的语料库中推断分词的模式。
例子:
from pkuseg import pkuseg
seg = pkuseg()
tokens = seg.cut("我喜欢学习自然语言处理。")
5. 子词分词
Byte Pair Encoding (BPE)
BPE是一种贪婪算法,通过迭代地合并最常见的字符对来学习词汇表。
工作原理:
· 从字符级别开始构建词汇表。
· 在语料库中查找最常见的字符对并合并,添加到词汇表中。
· 重复该过程直到达到预定义的词汇大小或无法合并为止。
优点:BPE的优点是能够灵活地处理未知词汇,并可缩小词汇表的大小。
Python代码示例:
from tokenizers import ByteLevelBPETokenizer
tokenizer = ByteLevelBPETokenizer()
tokenizer.train(["./dataset.txt"], vocab_size=5000)
WordPiece
WordPiece与BPE类似,但在选择合并时引入了概率模型,根据合并的似然来确定是否合并字符。
工作原理:
· 与BPE类似地开始从字符级别构建。
· 使用最大似然估计确定合并字符的顺序。
· 重复该过程直到达到预定义的词汇大小或无法合并为止。
优点:WordPiece维持了BPE的优点,但通过考虑合并的似然,可能提供了更合适的子词划分。
Python代码示例:
from tokenizers import BertWordPieceTokenizer
tokenizer = BertWordPieceTokenizer()
tokenizer.train(["./dataset.txt"], vocab_size=5000)
SentencePiece
SentencePiece是一个无监督文本编码器,提供了一个单一的、一致的接口,可实现BPE、WordPiece和Unigram等多种分词算法。
工作原理:
· 不依赖空格和预处理,直接在原始文本上工作。
· 支持多种分词算法,为不同的应用提供灵活性。
优点:与其他子词分词方法相比,SentencePiece的主要优点是其灵活性和一致性。
Python代码示例:
import sentencepiece as spm
spm.SentencePieceTrainer.Train('--input=./dataset.txt --model_prefix=m --vocab_size=5000')
参考一下LLaMA和ChatGLM等大模型用的分词算法就知道目前LLM首选分词算法就是基于SentencePiece的BBPE了。
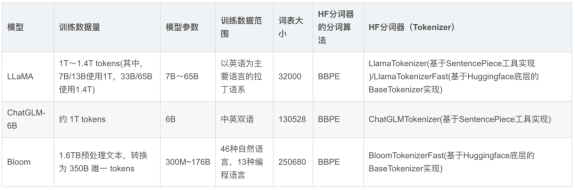
由于LLaMa原声词表对中文的支持并不好,所以通常会训练个中文分词模型,再来扩充LLaMa的词表。代码主要执行以下步骤:
· 加载分词器:加载Llama分词器和中文SentencePiece分词器。
· 合并分词器:将中文tokens添加到Llama分词器,创建一个合并后的分词器。
· 保存合并后的分词器:将合并后的分词器保存到指定目录。
· 测试分词器:使用原始和合并后的分词器对示例文本进行分词,并打印结果。
import os
from transformers import LlamaTokenizer
from sentencepiece import sentencepiece_model_pb2 as sp_pb2_model
import sentencepiece as spm
import argparse
# 设置环境变量以使用Python的Protocol Buffers实现
os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "python"
# 命令行参数解析
parser = argparse.ArgumentParser()
parser.add_argument('--llama_tokenizer_dir', default=None, type=str, required=True)
parser.add_argument('--chinese_sp_model_file', default='./chinese_sp.model', type=str)
args = parser.parse_args()
llama_tokenizer_dir = args.llama_tokenizer_dir
chinese_sp_model_file = args.chinese_sp_model_file
# 加载Llama分词器和中文SentencePiece分词模型
llama_tokenizer = LlamaTokenizer.from_pretrained(llama_tokenizer_dir)
chinese_sp_model = spm.SentencePieceProcessor()
chinese_sp_model.Load(chinese_sp_model_file)
# 解析protobuf格式的分词模型
llama_spm = sp_pb2_model.ModelProto()
llama_spm.ParseFromString(llama_tokenizer.sp_model.serialized_model_proto())
chinese_spm = sp_pb2_model.ModelProto()
chinese_spm.ParseFromString(chinese_sp_model.serialized_model_proto())
# 打印分词器信息
print(len(llama_tokenizer), len(chinese_sp_model))
print(llama_tokenizer.all_special_tokens)
print(llama_tokenizer.all_special_ids)
print(llama_tokenizer.special_tokens_map)
# 将中文tokens添加到Llama分词器
llama_spm_tokens_set = set(p.piece for p in llama_spm.pieces)
print(f"Before: {len(llama_spm_tokens_set)}")
for p in chinese_spm.pieces:
piece = p.piece
if piece not in llama_spm_tokens_set:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
new_p.score = 0
llama_spm.pieces.append(new_p)
print(f"New model pieces: {len(llama_spm.pieces)}")
# 保存合并后的分词模型
output_sp_dir = 'merged_tokenizer_sp'
output_hf_dir = 'merged_tokenizer_hf' # 保存中文-LLaMA分词器的路径
os.makedirs(output_sp_dir, exist_ok=True)
with open(output_sp_dir + '/chinese_llama.model', 'wb') as f:
f.write(llama_spm.SerializeToString())
tokenizer = LlamaTokenizer(vocab_file=output_sp_dir + '/chinese_llama.model')
tokenizer.save_pretrained(output_hf_dir)
print(f"Chinese-LLaMA tokenizer has been saved to {output_hf_dir}")
# 测试新的分词器
llama_tokenizer = LlamaTokenizer.from_pretrained(llama_tokenizer_dir)
chinese_llama_tokenizer = LlamaTokenizer.from_pretrained(output_hf_dir)
print(tokenizer.all_special_tokens)
print(tokenizer.all_special_ids)
print(tokenizer.special_tokens_map)
text = '''白日依山尽,黄河入海流。欲穷千里目,更上一层楼。
The primary use of LLaMA is research on large language models, including'''
print("Test text:\n", text)
print(f"Tokenized by LLaMA tokenizer: {llama_tokenizer.tokenize(text)}")
print(f"Tokenized by Chinese-LLaMA tokenizer: {chinese_llama_tokenizer.tokenize(text)}")
出自:https://mp.weixin.qq.com/s/jYlWTW2SjLqO7k7OBMncNg
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
专注于论文写作的网站、仅需要输入标题,就能生成一篇两万字的完整论文,瑞达写作还可以在线改稿,根据指导老师的修改意见在线进行内容修改。