Giraffe:世界上第一个商业可用的32K长上下文开源LLM(基于Llama-2)
发布时间:2024年06月06日
项目简介
选择如何对 Transformer 的位置信息进行编码一直是 LLM 架构的关键组成部分之一。
最近我们和社区其他人感兴趣的一个领域是法学硕士是否可以扩展到更长的背景。
我们使用不同的方案进行了一系列实验,以扩展 Llama 的上下文长度功能,Llama 已使用 RoPE(旋转位置嵌入)编码在 2048 上下文长度上进行了预训练。在这里,我们分享一些结果以及培训和评估脚本,希望对社区有用。对于我们性能最佳的模型(在尺度 4 和 16 处使用 IFT 进行线性缩放),我们还共享权重,以防其他人希望使用它们或进行自己的测试。我们认为,规模 16 模型应该在高达 16k 上下文长度、甚至可能高达约 20-24k 上下文长度的现实任务中表现良好。
概述
我们进行了各种各样的实验,试图延长模型的上下文长度。首先,我们尝试简单地使用基本 Llama 模型零样本。正如预期的那样,它在 2048 上下文长度之前表现良好,但随后迅速恶化。
接下来,我们研究了微调方法,在 RedPajama 数据集上以 4096 个上下文长度训练模型。这导致预期的性能改进高达 4096 个上下文,但同样,不会再进一步。
扩展上下文长度的另一种方法是以某种方式修改 RoPE 编码。在这里,我们尝试了许多不同的想法:
·
线性缩放,如 kaiokendev.github.io 所描述。
·
·
通过幂缩放 RoPE 的傅立叶基,使得低频比高频拉伸得更多。
·
·
对傅立叶基应用截断。我们的想法是,我们希望模型只看到足够快的频率,以便在训练期间至少获得一个完整的周期;任何较慢的频率都设置为 0(相当于根本不旋转,即在所有上下文长度上同样重要)。
·
·
随机化位置向量。
·
特别是,我们将 RedPajama 数据集的微调和 Vicuna 数据集的指令微调与上述方法结合起来。这就是取得最丰硕成果的原因。
最后,我们实现并尝试了 xPos 论文中描述的方法。这种方法增加了衰减幅度惩罚项,导致快速频率在长距离上的影响比傅立叶基中的慢频率的影响更小(请参阅我们的博客文章,了解显示这一点的相似性热图)。
突出的结果
也许我们最尖锐的观察是,不同的评估方法/任务会导致上述方法的不同排名。这将在下面进一步详细描述。
也就是说,我们提出了以下一般性观察:
·
线性插值/缩放似乎是增加模型上下文长度的最稳健的方法。
·
·
使用 N 的线性尺度并不一定会导致模型上下文长度增加 N 倍。例如,我们的尺度 16 实验通常在上下文长度为 16000 而不是 32000(~2048 * 16)后停止表现良好。我们对如何改善这种影响有一些想法,并计划在未来的工作中进行。
·
·
截断和随机化似乎都具有很高的困惑度分数,但在检索任务上表现不佳。
·
·
使用 Vicuna 数据集进行指令微调可在基本模型能够处理的长度上显着提高检索上下文的准确性,但无法在基本模型失败的长度上“修复”基本模型。
·
评估任务
为了进行评估,我们使用了两个不同的数据集:
·
用于在上下文中定位子字符串的 LMSys 数据集(“行”任务)
·
·
我们自己的开放书问答数据集 WikiQA,它基于其他开源基础 QA 数据集
·
此外,我们还研究了训练集和评估集的对数损失
对于 LMSys 任务,我们生成了新的更长的测试用例,上下文长度高达约 25000,超出了原始数据集中的 16000 个上下文测试用例。
WikiQA 任务是根据维基百科文档中给出的信息回答问题的任务。我们基于 Google Natural Questions 中的简答格式数据来构建我们的 QA 任务。它的格式为文档和问题。我们确保问题的答案是简短的答案,可以是单个单词,也可以是直接从文档中剪切粘贴的小句子。有了这样的任务结构,我们就可以准确地确定法学硕士应该在上下文中“寻找”答案的位置,从而通过仔细地将答案放置在不同的位置来有效地评估扩展上下文长度的每个部分。
我们选择了大型维基百科文档并对其进行了截断,以获得同一文档的多个版本,其大小在 2000 到 16000 个标记之间变化。对于每种尺寸的文档,我们还有多个版本,将问题和答案文本放置在不同的位置,即是否出现在文档的前 10%、大部分或最后 10%。拥有同一文档的多个版本使我们能够在模型大小和一个模型的上下文位置内获得详尽且公平的评估,因为我们本质上要求的是相同的信息。
基于维基百科的数据集的一个潜在问题是,该模型也许可以从其预训练的语料库而不是上下文中正确回答。为了解决这个问题,我们创建了另一个“更改的”数据集。该数据仅包含具有数字答案的问题。在这里,我们将答案以及文档中每次出现的答案更改为不同的数字。本质上是确保如果法学硕士从其预训练的语料库中收集数据,它会给出错误的答案。修改如下:
·
如果答案是一年,这是相当频繁的(即在 1000-2100 之间),我们将其更改为原始值 +/- 10 范围内的不同随机值。我们将年份视为特殊情况,以免因弄乱年代信息而使文件的解释变得荒谬
·
·
如果答案是任何其他数字,我们将其更改为具有相同位数的不同随机数
·
结果
LM系统评估
作为关于以下结果的一般观点,作者认为此任务的准确性的微小差异并不能特别表明模型排名质量。在解释结果时,我们通常会关注最广泛的趋势。
此外,作为基线,标准 Llama-13b 仅具有最多 2048 个上下文长度的非零精度(其 Vicuna 指令微调版本也是如此)。
不同缩放方法的比较
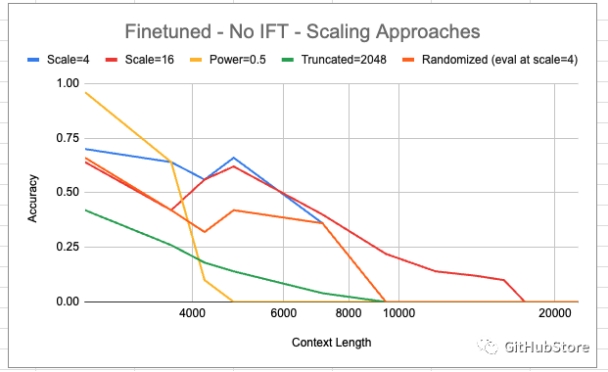
在上面我们比较了不同的缩放方法。“缩放”是指使用指定缩放值进行线性插值。我们看到,尺度为 16 的线性插值是唯一一种在上下文长度大于 9000 时实现非零精度的插值方法。然而,这似乎会牺牲一些较短上下文的精度。
在较短的上下文中,幂 = 0.5 的基础似乎特别适合这项任务,但随着上下文长度的增加,准确性会急剧下降。
有趣的是,scale=16 并没有像人们希望的那样具有普遍性。天真地,人们期望遵循scale=4的趋势——直到8192为止都是非零的(这是合理的,因为原始上下文长度是2048,并且8192 = 2048 * 4;除此之外,模型看到的是相对距离在以前从未遇到过的键和查询之间),scale=16 应该一直非零,直到 2048 * 16 = 32768。
IFT(指令微调)的影响
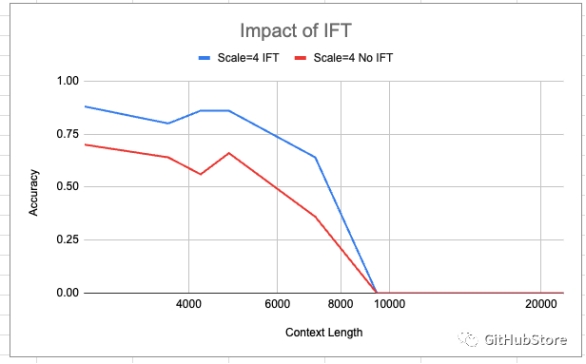
在上面,我们通过使用 LoRA 使用 Vicuna 指令集进行训练展示了 IFT 的影响。我们看到 IFT 确实以微小但不可忽略的幅度提高了准确性。然而,改变准确度曲线的整体形状是不够的——并且它不会对模型可以在此任务上实现非零准确度的上下文长度范围进行任何扩展。
在与训练不同的尺度上评估零射击
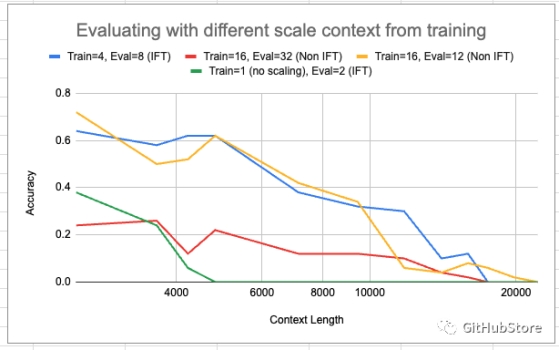
在上面,我们展示了在评估时尝试与模型训练时不同的比例值(用于线性插值)的各种实验。绿色曲线表示采用基本模型(在 2048 上下文中训练)并向其应用比例值。它确实将非零范围从 2048 扩展到 4096,但整个精度较低。然而,一般来说,一旦模型经过规模 > 0 的训练,似乎该模型就可以在评估时很好地从零射击到更大的规模——极大地增加了连贯上下文长度的范围(例如,比较训练=4,Eval=8 在上下文长度为 16k 时为非零,而对于上面两张图的 8k 以上,Eval=8 为 0)。然而,这确实是以精度下降为代价的,特别是对于 Train=16、Eval=32 的情况。
Train=16, Eval=12 运行具有我们见过的最长的非零精度上下文长度。它在上下文长度约为 20000 时获得非零分数。
项目链接
https://github.com/abacusai/long-context
出自:https://mp.weixin.qq.com/s/pSmT3uZOJAw7ClSz0gcJyA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
基于gpt模型 AI智能生成亚马逊产品listing