基于LLM+向量库的文档对话痛点及解决方案
发布时间:2024年06月06日
痛点:文档切分粒度不好把控,既担心噪声太多又担心语义信息丢失
笔者之前采用了Longchain的文档切分工具,发现不能问题。笔者做了一些探索,希望与大家共同探讨
问题1:如何让LLM简要、准确回答细粒度知识?
· 举例及标答如下:

https://baijiahao.baidu.com/s?id=1771640093192764694&wfr=spider&for=pc
用户:2023年我国上半年的国内生产总值是多少?
LLM:根据文档,2023年的国民生产总值是593034亿元。
· 需求分析:一是简要,不要有其他废话。二是准确,而不是随意编造。
问题2:如何让LLM回答出全面的粗粒度(跨段落)知识?
· 举例及标答如下

图片来源于网络
用户:根据文档内容,征信中心有几点声明?
LLM:根据文档内容,有三点声明,分别是:一、……;二……;三……。
· 问题解释及需求分析:
要实现语义级别的分割,而不是简单基于html或者pdf的换行符分割。笔者发现目前的痛点是文档分割不够准确,导致模型有可能只回答了两点,而实际上是因为向量相似度召回的结果是残缺的。
有人可能会问,那完全可以把切割粒度大一点,比如每10个段落一分。但这样显然不是最优的,因为召回片段太大,噪声也就越多。LLM本来就有幻觉问题,回答得不会很精准(笔者实测也发现如此)。
所以说,我们的文档切片最好是按照语义切割。
解决方案
思想(原则)
基于LLM的文档对话架构分为两部分,先检索,后推理。重心在检索(推荐系统),推理交给LLM整合即可。而检索部分要满足三点 ①尽可能提高召回率,②尽可能减少无关信息;③速度快。
将所有的文本组织成二级索引,第一级索引是 [关键信息],第二级是 [原始文本],二者一一映射。检索部分只对关键信息做embedding,参与相似度计算,把召回结果映射的 原始文本 交给LLM。
主要架构图如下:
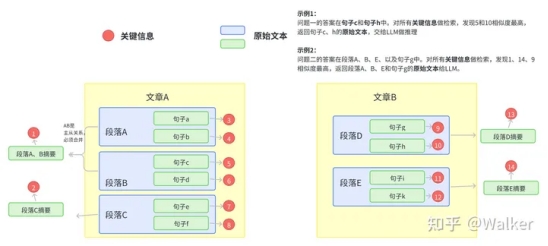
文档切片及检索示意图
如何构建关键信息?
首先从架构图可以看到,句子、段落、文章都要关键信息,如果为了效率考虑,可以不用对句子构建关键信息。
· 文章的切分及关键信息抽取
关键信息: 为各语义段的关键信息集合,或者是各个子标题语义扩充之后的集合(pdf多级标题识别及提取见下一篇文章)
语义切分方法1:利用NLP的篇章分析(discourse parsing)工具,提取出段落之间的主要关系,譬如上述极端情况2展示的段落之间就有从属关系。把所有包含主从关系的段落合并成一段。 这样对文章切分完之后保证每一段在说同一件事情.
语义切分方法2:除了discourse parsing的工具外,还可以写一个简单算法利用BERT等模型来实现语义分割。BERT等模型在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值t,从前往后依次判断相邻两个段落的相似度分数是否大于t,如果大于则合并,否则断开。当然算法为了效率,可以采用二分法并行判定,模型也不用很大,笔者用BERT-base-Chinese在中文场景中就取得了不错的效果。
这部分代码网上似乎没有,那我贴出来吧
def is_nextsent(sent, next_sent):
encoding = tokenizer(sent, next_sent, return_tensors="pt",truncation=True, padding=False)
with torch.no_grad():
outputs = model(**encoding, labels=torch.LongTensor([1]))
logits = outputs.logits
probs = torch.softmax(logits/TEMPERATURE, dim=1)
next_sentence_prob = probs[:, 0].item()
if next_sentence_prob <= MERGE_RATIO:
return False
else:
return True
· 语义段的切分及段落(句子)关键信息抽取
如果向量检索效率很高,获取语义段之后完全可以按照真实段落及句号切分,以缓解细粒度知识点检索时大语块噪声多的场景。当然,关键信息抽取笔者还有其他思路。
方法1:利用NLP中的成分句法分析(constituency parsing)工具和命名实体识别(NER)工具提取,前者可以提取核心部分(名词短语、动词短语……),后者可以提取重要实体(货币名、人名、企业名……)。譬如说:
原始文本:MM团队的成员都是精英,核心成员是前谷歌高级产品经理张三,前meta首席技术官李四……
关键信息:(MM团队,核心成员,张三,李四)
方法2:可以用语义角色标注(Semantic Role Labeling)来分析句子的谓词论元结构,提取“谁对谁做了什么”的信息作为关键信息。
方法3:直接法。其实NLP的研究中本来就有关键词提取工作(Keyphrase Extraction)。也有一个成熟工具可以使用。一个工具是 HanLP ,中文效果好,但是付费,免费版调用次数有限。还有一个开源工具是KeyBERT,英文效果好,但是中文效果差。
方法4:垂直领域建议的方法。以上两个方法在垂直领域都有准确度低的缺陷,垂直领域可以仿照ChatLaw的做法,即:训练一个生成关键词的模型。ChatLaw就是训练了一个KeyLLM。
常见问题
· 句子、语义段、之间召回不会有包含关系吗,是否会造成冗余?
回答:会造成冗余,但是笔者试验之后回答效果很好,无论是细粒度知识还是粗粒度(跨段落)知识准确度都比Longchain粗分效果好很多,对这个问题笔者认为可以优化但没必要
出自:https://zhuanlan.zhihu.com/p/651179780
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Text To Speech,文字转语音,文本朗读,让机器能够说话。构建自然说话的应用和服务,从 147 种语言和变体中选择 456 种语音。借助高表现力和类似人类的神经语音,让你的方案生动起来。