LLM应用架构之检索增强(RAG)的缘起与架构介绍
发布时间:2024年06月06日
当前,随着大模型应用落地需求不断增加,越来越多的人在寻找搭建LLM应用的最佳模式,而这种模式就如同当年web开发中MVC架构一样,能够很好地指导开发者正确高效地开发应用。目前,在LLM开发领域,有RAG,MRKL,Re-Act,Plan-Execute等模式越来越多被人提及和应用,那么它们是什么,怎么产生的,解决什么问题,这一切都要从大模型内在基因谈起。
大模型的内在基因
怎么样才能算是一个大语言模型(LLM)?实际上这个问题比较模糊,比如bert算不算是大模型呢?一个参数量上千亿的推荐系统模型,它是不是大模型呢?在这里,笔者认为,我们探讨的大模型应该满足两个条件,才能称之为当下语义下的大模型。

首先它应该是生成式的,第二它的模型规模要足够大,这里的规模包含了参数规模和数据规模。
生成式模型
在机器学习中,我们根据解决问题方法不同将模型分为两类,生成式和判别式。应该如何理解这两者各有什么特点呢?
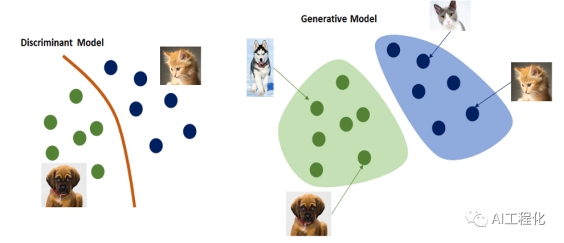
这里有一个形象的例子来解释,有两个小学生小明和小花,他们得到一个相同的任务就是学习区分狗和猫,小明是个急性子,他希望赶紧把任务完成然后就可以玩,所以,他学习方法简单直接,重点放在了猫和狗的差异特征上,比如耳朵贴着头的是狗,竖起来的猫,他在寻找一个边界,在边界一方就是狗,边界另一方就是猫。而小花,是一个善于思考总结,勤于钻研的孩子,她会从猫和狗各自具有的形态和特征入手,总结什么样的样子是一只猫,什么样是一只狗。到了考试时间,小明在完成曾经看到过猫狗品种上,回答的很快,但是对于没有见过的新的品种,比如竖着耳朵的哈士奇时,就辨别错误了。而小花却能准确地回答,甚至还可以画出一只真实不存在的狗或者猫。这里小明的学习方法就是判别式的,而小花采用的就是生成式的。如果用数学语言来说明判别式和生成式,那么判别式是直接寻找P(y|x),即y在x条件下的概率,找到决策边界,即根据x来判别y,故叫做判别式。而生成式的方法是,首先会生成P(x,y)的联合分布,即该类别固有的数学分布是什么样的,然后继而推算P(y|(x,y)),而y本身就是这个概率分布生成的,所以叫做生成式。
简单总结两者区别,判别式在分类问题上解法直接,从历史结果总结原因,是经验主义,强依赖标记样本,擅长记忆,能力也比较单一,因为就是为了这个问题而生,缺乏创造性。而生成式更为深入,也更符合人类喜欢的学习模式,能够举一反三,从事实原因来顺推结果,但这个推理过程,自然需要大量的样本和算力支持,它不仅能够简单判别,而且它学到的事物真实的本质,即概率分布,故而泛化性强,它能处理它在训练样本中未见过的情况。从这个角度讲,使用生成式的方式做异常检测,会相对于传统判别式方式来做,更能解决异常检测滞后性及负样本不足的情况。而大模型应用利用生成式的另一面,充分挖掘其生成能力,生产内容,使得它让人们感觉到了它创造性。但同时,也要认识到,它的生成的新样本是基于它学到的概率分布而来,它有可能生成出符合人类预期的结果,同时,也有可能生成出不符合预期的情况,我们能做的就是通过微调等手段改变数据概率分布来干预模型结果,但无法完全改正,可以说这就是生成式模型的内在基因体现,如何扬长避短才是关键。
规模大对于大模型来讲,之所以称之为大模型,规模大是很重要的因素,我们一般任务参数量超过10亿的才能跨进大模型的门槛。另一方面,其训练数据的规模也要足够,避免模型产生过拟合,从压缩思维来讲,模型不过是真实世界的压缩表示,为了能够真实反映这个世界的运行规律和知识,生成真实的数学概率分布,大的模型参数规模和大的数据量是一个硬币的两个面。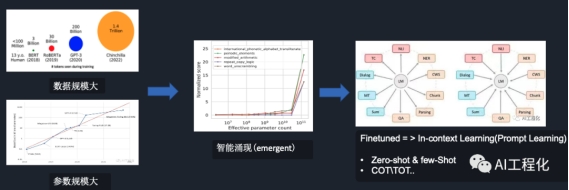 从上图可以看到,参数规模和训练的token数是正相关的,以gpt3为例,它有1750亿参数,其训练的token量达到了2000亿,据说包含了全球所有公开的文本信息,自然它能什么都懂就不奇怪了。而参数规模大,数据规模大只是大模型的一个必要条件,能不能发生智能涌现,才是这其中的关键。也正是如此,大量企业在模型争霸赛时,没有一直坚持下去,堆叠规模,而是采用了专才思路,具体看:一文探秘LLM应用开发(5)-微调(背景与挑战),错过了人工智能的圣杯,而OPENAI坚持住了,发现了涌现,继而将我们是使用模型的方式从以finetune模型适配下游任务,变成了通过in-contextlearning的方式来适配大模型,从而改变了大模型使用的范式。
从上图可以看到,参数规模和训练的token数是正相关的,以gpt3为例,它有1750亿参数,其训练的token量达到了2000亿,据说包含了全球所有公开的文本信息,自然它能什么都懂就不奇怪了。而参数规模大,数据规模大只是大模型的一个必要条件,能不能发生智能涌现,才是这其中的关键。也正是如此,大量企业在模型争霸赛时,没有一直坚持下去,堆叠规模,而是采用了专才思路,具体看:一文探秘LLM应用开发(5)-微调(背景与挑战),错过了人工智能的圣杯,而OPENAI坚持住了,发现了涌现,继而将我们是使用模型的方式从以finetune模型适配下游任务,变成了通过in-contextlearning的方式来适配大模型,从而改变了大模型使用的范式。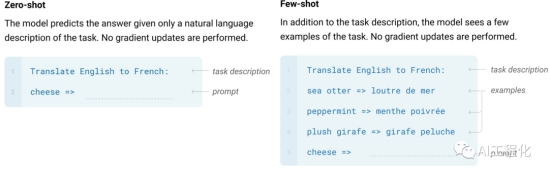 这样做的好处是什么?好处在于,原来完成任何一个下游任务,如总结,情感分析,都需要微调一个模型,而现在,只需要通过输入写prompt给模型就可以,甚至利用prmpt还能激发出大模型的推理思考能力(COT),而这样做的成本非常低,并且真正激发了模型潜在能力。因此,大模型的规模大小不是判定大模型本身的充分条件,而一个模型具备了in-context learning的能力才是。
这样做的好处是什么?好处在于,原来完成任何一个下游任务,如总结,情感分析,都需要微调一个模型,而现在,只需要通过输入写prompt给模型就可以,甚至利用prmpt还能激发出大模型的推理思考能力(COT),而这样做的成本非常低,并且真正激发了模型潜在能力。因此,大模型的规模大小不是判定大模型本身的充分条件,而一个模型具备了in-context learning的能力才是。
与之俱来的优势与问题前面探讨了大模型的基因,一个是生成式结构,一个是模型规模很大,那么,对于基于它开发LLM应用就不得不面对它带来的优势及问题。
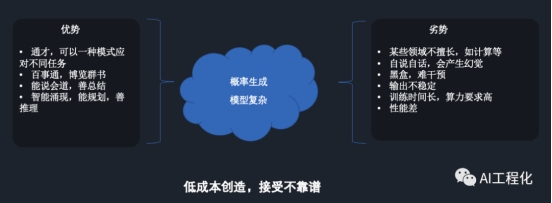
简单讲,它这两个基因带来的了两个特性,一个就是它的输出是概率生成的,既然是概率,那么就有一定几率是好的,有一定几率不好,我们只能引导,无法完全消灭。另一个就是模型复杂,如前文讲,生成式本身是在学习样本的真实分布,而非决策边界,故而更为复杂,性能较差,再加上为了能够获得智能涌现,模型参数量巨大,就更难以训练和部署。先从优点说起:
1)大模型是通才,能够可以通过一种方式,即prompt完成不同的下游任务。2)它由于在预训练和微调过程中学到了大量的知识,可谓是无所谓不知。3)基于预训练,指令微调,人类反馈强化微调使得大模型能够很好的对齐指令,其输出也更加符合人类习惯,善于总结,能说会道。4)大模型具有智能涌现的特性,能够具备以往模型不具备的zero-shot,few-shot,cot等能力,能够规划和推理,让人感受到了AGI的潜质。而缺点也很多,具体如下:1)由于它是按通才来培养的,在专业能力上并不见得比小模型强,曾有人做过测试,在某项具体的nlp任务中,它的能力或许并不如bert之类的专门finetuned的小模型。另外,由于它是一个语言模型,在一些数学计算和工具使用上并不擅长,简单的四则运算可能都会出错。这一问题,也使得另一个架构模式的产生那就是MRKL,其基本思路就是让专业的人做专业的事情,后续将介绍给大家。2)自说自话,会有幻觉的问题。这一问题本质就是概率生成的负面体现,并且由于数据集内容分布问题,很有可能产生歧视,暴力等非法输出,这也是实际投产一个比较棘手的问题。3)目前深度学习,特别是大模型巨大的参数量及模型结构,对于模型为什么输出是这样,对于人类来讲是个黑盒,很难干预,比如想要不破坏大模型原有能力而修改其中部分数据错误就是一个非常难的事情。4)输出不稳定,尽管我们可以通过prompt约束大模型的输出,然而既然是概率生成,那么就存在着无法避免的边角case,从而导致构建其上的LLM应用失败。
5)模型训练的时间很长,算力要求高,导致预训练和微调都是挑战。6)推理性能差,这使得模型服务很难直接面向用户提供服务。
总结起来,使用大模型能够做到低成本的创造,但我们需要接受它有时的不靠谱,希望模型做到100%正确是一件非常难办的事情。
能力与应用
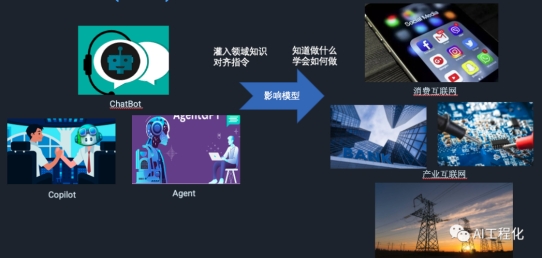 理解了它的优势和劣势,那么如何发挥它的能力,让它在不同领域落地就是新的问题。从目前大模型特点出发,从简单到复杂,可以分为三个形态,chatbot(聊天机器人),copilot(智能助手),Agent(智能体)。它们能力边界是越来越大的,从回答单一问题,到辅助人类工作,再到独立工作是逐渐变强的。而在领域层面,分别是消费互联网和产业互联网。要让这样的产品落地到行业,其关键问题是如何影响模型,也就是说改变模型原因的概率分布,让它能够更好地匹配所在行业。而手段就是灌入领域知识,并对齐行业任务指令,教会模型理解知道做什么,进而学会如何做。这一点和一个员工进入一个新公司,新行业一样,首先理解这个行业这个公司的背景,知识,流程,进而知道怎么具体做一个任务,以及怎么做才是对的。影响大模型效果的手段
理解了它的优势和劣势,那么如何发挥它的能力,让它在不同领域落地就是新的问题。从目前大模型特点出发,从简单到复杂,可以分为三个形态,chatbot(聊天机器人),copilot(智能助手),Agent(智能体)。它们能力边界是越来越大的,从回答单一问题,到辅助人类工作,再到独立工作是逐渐变强的。而在领域层面,分别是消费互联网和产业互联网。要让这样的产品落地到行业,其关键问题是如何影响模型,也就是说改变模型原因的概率分布,让它能够更好地匹配所在行业。而手段就是灌入领域知识,并对齐行业任务指令,教会模型理解知道做什么,进而学会如何做。这一点和一个员工进入一个新公司,新行业一样,首先理解这个行业这个公司的背景,知识,流程,进而知道怎么具体做一个任务,以及怎么做才是对的。影响大模型效果的手段
前面提到了,LLM要真实落地到具体行业发挥价值,其关键在于如何影响大模型,让它能够真正适合行业实际的需求。
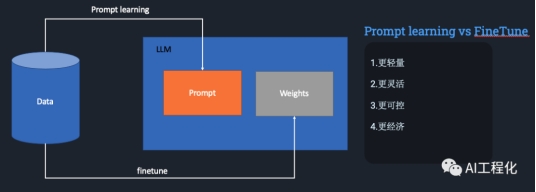 从上图可以看到,影响模型输出莫过于两种方式,一种修改模型本身的参数权重,另一种就是修改它的输入,不改变参数权重,而前者就是微调,而后者就是大模型特有的prompt learning。这里不在详细展开,具体可以看,:一文探秘LLM应用开发(2)-问题定义与基本思路
从上图可以看到,影响模型输出莫过于两种方式,一种修改模型本身的参数权重,另一种就是修改它的输入,不改变参数权重,而前者就是微调,而后者就是大模型特有的prompt learning。这里不在详细展开,具体可以看,:一文探秘LLM应用开发(2)-问题定义与基本思路
而这里重点对于两者做一比较。前面提到了大模型之所以是大模型,prompt learning也就是in-context learning是关键。那么,它相较于finetune有啥优势呢?
1)更轻量,从模型的知识角度讲,一个模型的知识来自于它预训练和微调过程,但是由于这两个训练成本比较大,很难做到实时训练,这样就导致了模型知识的过时,比如ChatGPT只知道2021年9月以前的事实,而对于prompt learning来讲,它可以把知识实时传入给模型,这几乎零成本。另一方面,模型微调是需要大量的标记数据,而这样的标记问答对,本身就是很大的负担,相较于精心构造few-shot来讲,更为笨重。2)更灵活,对于模型应对不同任务来讲,finetune的做法就是每个任务训练一个模型,这就导致了它是否不灵活,虽然从后期改进上有类似adpater机制,但总的来讲,和简单修改prompt来讲,完全不是一个量级。
3)更可控,对于大模型来讲,如何让它理解行业知识,其中做法就是把知识以问答对的方式finetune到模型中,然而这样的做法虽然可以改变模型的概率分布,提升zero-shot的效果,但是并不能直接约束模型是否使用这些知识,也很难很精细的操作。而另一种方式是,将知识以上下文的形式放置到prompt中,只让大模型基于prompt提供的背景发挥,某种意义上它更加可控,也发挥了各自的优势。
4)更经济,这一点很好理解,finetune的成本是远高于推理成本的,加上finetune在流程和技术层面的潜在要求,也更增加了使用的成本。
因此,从分析来看,对于一个大模型应用来看,虽然现在充斥着大量的文章探讨如何训练,如何微调,但实际投产,要清楚知道,finetune并不是第一选择,我们更应该优先选择利用prompt learning的方式来解决,如果无法解决再考虑finetune,甚至是从零训练一个大模型。
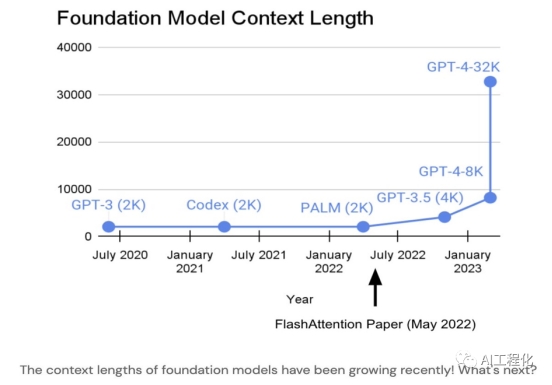
Prompt learning的限制前面提到了很多prompt learning的优势,但它并不是没有缺点,而这一缺点本质上也是大模型固有的。这一个致命缺陷就是prompt是有长度约束的,并且这一长度很难快速提高,因为它的增长带来的计算量(FLOPS)是呈O(n^2)增长的,具体推算逻辑可以查看:一文探秘LLM应用开发(12)-模型部署与推理(大模型相关参数计算及性能分析)。因此,它对算力的消耗是巨大的。目前GPT提供的context大小在8k左右,最大32K。
不过值得openAI的对手,新发布的claud 2支持100k的context window,可以直接上传一个万字长文供它分析。
但是,要注意的是这对于企业级海量知识来讲,仍然相当有限,再加上prompt的长度又进一步的会导致推理速度的下降,显然,直接将所有背景信息,及任务例子等放到prompt中不是一个好的办法。
而解决办法也比较直觉,就是是否在提交prompt给大模型时,把prompt中的内容能够做一筛选,减少候选数据。
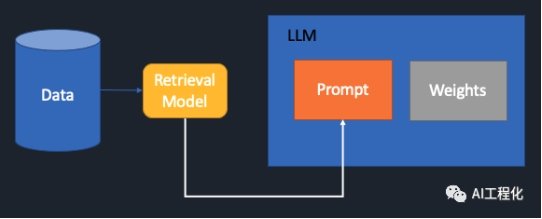
如图,引入一个检索过程,将领域知识通过相关性检索,将相关信息检索出来,基于它们来构造prompt,最终传给LLM,让其在此之上总结推理。这样就能一定程度缓解context window对于prompt learning方式的限制。
RAG(Retrieval Augmented Generation)应运产生实际上,上面提到的思路,早在2020年5月就由meta和伦敦学院及纽约大学的研究者在论文《 Augmented Generation for Knowledge-Intensive NLP Tasks 》提出,并起名为Retrieval Augmented Generation,即RAG,中文翻译为检索增强生成。
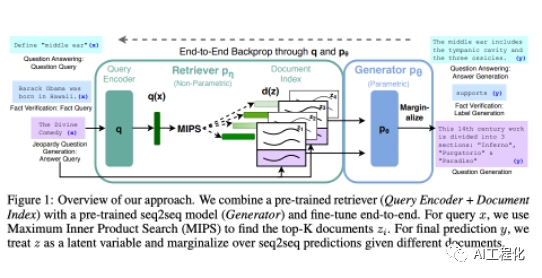
其架构的工作流程比较简单清晰,如下图:
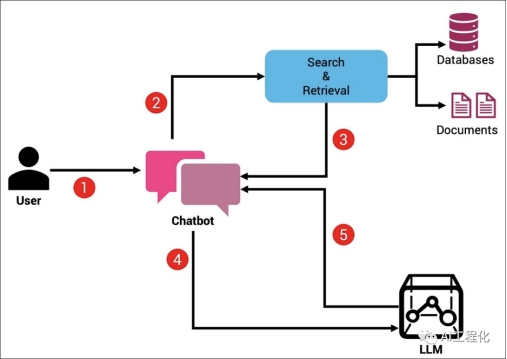
整体分为5步,第一步是用户向chatbot(即LLM应用)提出问题,第二步基于问题在数据库中检索相关问题,第三步,将检索结果top n的数据传给chatbot,chatbot基于用户问题以及检索到的相关信息进行合并形成最终的prompt,第四步,将prompt提交给大模型,第五步,大模型产生输出返回给chatbot,进而返回给用户。
采用RAG架构的LLM应用,除了能够破解prompt learning受限context window的问题,它还有以下好处:
1)它能够基于这种模式,尽量减少大模型幻觉带来的问题。
2)它减少了为了微调而准备问答对(带标记的样本数据),大大减少了复杂度。
3)prompt的构造过程,给了我们很大的操作空间,对于我们后续干预模型效果,完成特定业务需求提供了必要的手段。
RAG架构常见选型
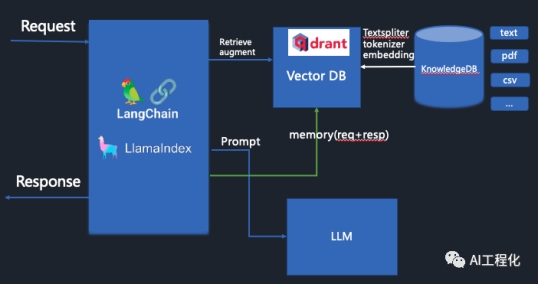
在工业界,langchain及llamaindex都实现了RAG架构,他们基于此架构不断迭代丰富,成长成为了一个功能完备,覆盖LLM应用常见形态(chatbot,copilot,agent)的全功能编排框架。从架构图上可以看到,除了LLM,编排服务外,向量数据库十分重要,它不仅保存了从领域知识库中导入的被embedding的领域知识外,还存储着用户与大模型对话的信息,被称作memory。那么为什么要使用它来作为检索model的核心选择呢?经过我们之前的分析,为了让大模型生成高质量的输出,RAG架构的核心在检索,而检索的核心在相关性,如何提高检索相关性就是其中的关键。而向量检索相较于传统的文本相关性检索来讲,其具备突出的优势,就是它具备语意相关性。

以上图检索为例,在资料库中存在与鱼搭配的葡萄酒,在搜索时,如果搜索词为有海鲜搭配的酒时,对于传统搜索,无法检索到结果,因为“fish”和“seafood”并不存在文本相关性,然而对于embedding向量来讲,海鲜和鱼是存在语意相关性的,因此可以被检索到,而向量数据库正是存放embeding向量,进行向量相似性的工具。自然,在LLM这个场景下使用向量数据库最为合适。除此之外,向量数据库还有如下优势:
1)对于大模型来讲,本质都是embedding的计算, 它们采用相同的embedding方式,能够发挥更好的协同作用。
2)它在大规模数据检索上速度很快,可以弥补模型推理速度慢的问题,向量数据库有很多相似性计算的算法,如ANN,LSH,PQ等
3)天生具备多模态,实际上,不管是文本还是图片,亦或是声音,视频都可以通过向量表示,这样就能够很好的统一存储,对于大模型来讲,也有统一的趋势,从技术走向来看,匹配度高。
因此,向量数据库在RAG架构乃至其它LLM架构如Re-Act架构里扮演着非常重要的作用。可以查看更多关于向量数据库的内容一文探秘LLM应用开发(4)
RAG简单实现示例
得益于langchain,llamaindex的高度抽象和封装,简单实现一个RAG的问答系统比较简单。
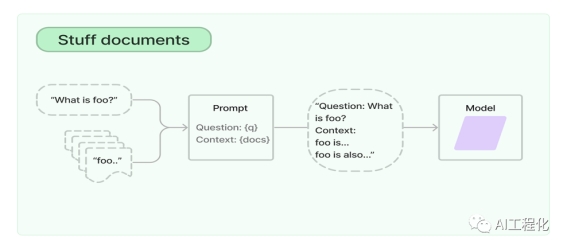
整个过程大体分为两步,第一建库,第二检索。如示例代码。
1)llamaindex:

2)langchain:
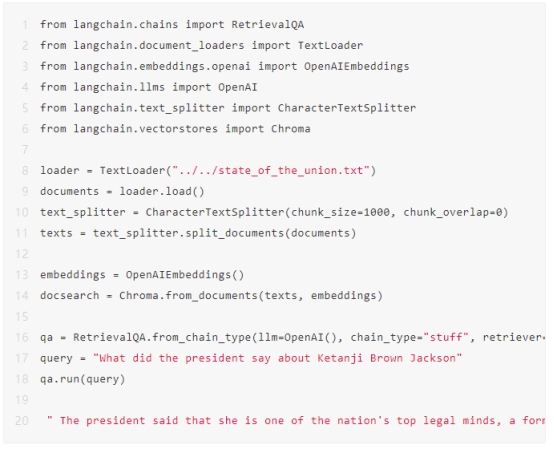
这样一个基本的QA问答服务主体代码就完成了。值得一提的是,langchain和llamaindex中提供了大量的模式供开发者使用,值得大家探究学习。
总结
本文从大模型的天生属性出发,探讨了大模型架构RAG的产生和基本模式,而这一切实际上才刚刚开始,在实际投产过程中,有大量的问题尚待解决。它们分散在效果,内容安全与隐私保护,内容可信,性能等多个方面。
出自:https://mp.weixin.qq.com/s/gmRdjmyzDzrOaO6F99NgsA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款融合了音乐理解和多模态音乐生成任务,旨在助力用户进行音乐艺术创作的引领潮流的框架。