研究人员开源中文文本嵌入模型,填补中文向量文本检索领域的空白
发布时间:2024年06月06日
一直以来,基于向量的文本检索是重要的研究议题之一。随着 GPT 的出现,向量检索的意义变得愈发重要。
由于 GPT 使用的 Transformer 模型的自身特性,导致模型只能从固定长度的上下文中生成文本。那么,当我们需要模型感知更广阔的上下文时,应该怎么做呢?
领域内通用的解决方案是,将历史对话或者领域语料中的相关知识通过向量检索,再补充到 GPT 模型的上下文中。
这样,GPT 模型就不需要感知全部文本,而是有重点、有目的地只关心那些相关的部分,这和 Transformer 内部的 Attention 机制原理相似,使得文本嵌入模型变成了 GPT 模型的记忆检索模块。
但是长期以来,领域内一直缺少开源的、可用的中文文本嵌入模型作为文本检索。中文开源文本嵌入模型中最被广泛使用的 text2vec 主要是在中文自然语言推理数据集上进行训练的。
另一方面,OpenAI 出品的 text-embedding-ada-002 模型被广泛使用 ,虽然该模型的效果较好,但此模型不开源、也不免费,同时还有数据隐私和数据出境等问题。
最近,MokaHR 团队开发了一种名为 M3E 的模型,这一模型弥补了中文向量文本检索领域的空白, M3E 模型在中文同质文本 S2S 任务上在 6 个数据集的平均表现好于 text2vec 和 text-embedding-ada-002 ,在中文检索任务上也优于二者。
值得关注的是,目前,M3E 模型中使用的数据集、训练脚本、训练好的模型、评测数据集以及评测脚本都已开源,用户可以自由地访问和使用相关资源。该项目主要作者、MokaHR 自然语言处理工程师王宇昕表示:“我相信 M3E 模型将成为中文文本向量检索中一个重要的里程碑,未来相关领域的工作,都可能从这些开源的资源中收益。”
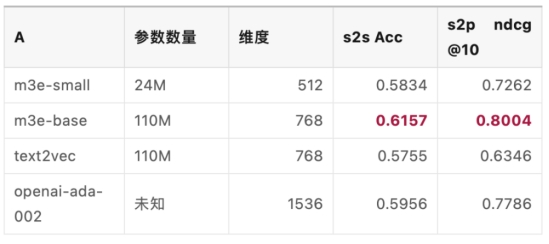 图丨项目中模型的关键数据对比(来源:王宇昕)
图丨项目中模型的关键数据对比(来源:王宇昕)
文本的嵌入式表达本身是一个泛用性特别强的算法。搜索引擎优化方面,M3E 模型对同质和异质文本都有较好的检索能力,这可能使其在搜索引擎的优化中发挥重要作用。例如,它可以帮助改进查询的理解和文档的索引,从而提高搜索的准确性和效率。
NLP 任务方面,M3E 模型在文本分类和情感分类任务上表现都较好,这使其可以在如新闻分类、社交媒体监控、情感分析等领域找到应用。
数据清洗方面,M3E 模型具有出色的向量编码能力,可在此基础上实现一些数据清洗的算法。王宇昕举例说道:“比如通过向量进行聚类,进而筛选出特定类别或特征的语料;或者通过向量进行文本重复检测,将语义重复的文本进行清洗等。”
GPT 记忆模块方面,M3E 模型可以充当 GPT 等类似的大语言模型的记忆模块,可在对话中从历史文本和领域预料中检索出相关知识。“并且,将这些相关知识通过上下文补充给 GPT,从而让 GPT 模型能适应更多的领域,解决更复杂的问题。”他说。
 图丨王宇昕(来源:王宇昕)
图丨王宇昕(来源:王宇昕)
据悉,在项目调研阶段,文本嵌入即 Embedding 模型从 Word2Vec 以来,经历过若干次迭代,已经发展出较成熟的一套解决方案和方法论。但是,最近一系列基于指令和大规模半监督样本的文本嵌入模型,在大规模文本嵌入基准取得了 SOTA 的成绩。
王宇昕指出,在 M3E 项目开始之初,团队就发现了这一趋势,因此 M3E 研究团队对此进行了广泛的调研和实践,最终总结出大规模句对监督数据集 + 指令数据集 + 对比学习的解决方案。
M3E 的研究经历了六个阶段。训练数据准备阶段,M3E 研究团队在 HuggingFace、千言、和鲸等社区收集 30个,包含中文百科、金融、医疗、法律、新闻、学术等多个领域的数据集,共计 2200 万句对样本。这些数据集包括问答、摘要、NLI、NL2SQL 等多种类型的任务。M3E 研究团队将这一数据集进行了收集和整理,并标注了元信息。
训练代码准备阶段,M3E 研究团队提出了 uniem 文本嵌入模型训练框架,对其中重要的组成部分进行了抽象和接口设计,目前 uniem 支持三种样本结构,包括句子对、句子三元组和评分句对,支持三类对比学习损失函数、CoSentLoss、SoftmaxContrastLoss 以及 SigmoidContrastLoss。“通过对这些组件的组合,我们可以轻松的复现各种对比学习算法和文本嵌入论文,如 SimCSE, Instructor,SGPT 等。”王宇昕说。
模型训练阶段,M3E 在项目前期就使用了规模较小的模型进行超参数实验和调优,因此,在实际训练的超参数调优上并没有消耗多少精力。为了保证批次内负采样的效果, M3E 的模型均使用 A100 80G 机器最大化单节点的 batch size。M3E-base 模型在 A100 上进行了 2200万 样本的一轮次训练,共计 34 个小时。
评估数据准备阶段,为了评估中文文本嵌入模型的效果, M3E 研究团队效仿和使用 HuggingFace MTEB 的评测集构造的形式,收集了 7 种不同的数据集,包括电商文本、股票文本、长文本以及社区问答等类型。
评估代码准备阶段,M3E 使用 MTEB BenchMark 中的数据格式对收集到的评测数据进行整理和代码设置,形成了 MTEB-zh 评测脚本,通过和 MTEB 相同的方式,就可以对中文嵌入模型进行一键评估。M3E 团队在第一期对 text-embedding-ada-002、text2vec、M3E-small 和 M3E-base 进行了详细的评估和分析。
模型发布阶段,M3E 团队整理了训练数据集,训练代码,模型权重,评估数据集,评估代码,并一一进行开源和文档撰写。
该项目的主要作者包括 MokaHR 自然语言处理工程师王宇昕、算法实习生孙庆轩、算法实习生何思成。据悉,该团队的后续研究计划,包括完成 Large 模型的训练和开源、支持代码检索的模型、对 M3E 数据集进行清洗,并开源商用版本的 M3E models 等。
参考资料:
https://huggingface.co/moka-ai/m3e-base
出自:https://new.qq.com/rain/a/20230712A0904D00/
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个在线智能写作应用,妙话AI提供了包括自动生成绘画、语音对话机器人等多种功能。它集成了100多个智能AI大模型,用户可以通过一键操作进行聊天、写作、绘画和语音生成,轻松解决复杂问题。