造梦师手记:腾讯加入Stable Diffusion的ControlNet模型开发,效果艳丽
发布时间:2024年06月06日
周末读了一篇ghostmix模型作者的文章,也引起了我对Stable Diffusion发展方向的思考。
由于访问C站需要科学上网,很长一段时间国内获取AI大模型的方式比较不便。近期随着liblibai等国内AI绘画网站的加入,并通过资本拿真金白银激励创作者,甚至掀起了一股模型创作热潮。
但是,量多不代表质优。
很多所谓大模型不过是融了几个热门lora,并没有真正经过原始图片的训练过程。
形成了ckpt的lora化,这是一个很不好的风向。真正潜心做模型的创作者,甚至陷入了低谷。
ghostmix模型作者认为,应该尽可能的少做大模型,然后使用lora、ControlNet等微调工具来适配更多的场景。
私以为,这个思路是非常正确的。虽然我有4T的SSD不担心下载模型,但是越来越多的模型,动辄3、5个G起步,会大大抬高Stable Diffusion的门槛。
新版的Stable Diffusion XL 0.9刚刚发布(我正在调试,过几天会发个“迟到”但会非常细致的保姆级教程),基础模型更是达到了惊人的13G,如果模型这么泛滥下去,4T的SSD怕是也不够用。

一、ControlNet的革命
ControlNet是一位年轻的斯坦福大学的华人选手创作的,Lvmin Zhang,2021 年本科毕业,现为斯坦福 PHD,并发布了论文阐述其原理。
其实在AI领域,华人非常优秀,大量的AI论文都会看到汉语拼音。
ControlNet用一种极低成本的方案,来控制画面的主体构成。当然,这只是使用者的角度,原作者还是成本(时间、精力等成本,费用反而不算高)很高的。
ControlNet 在论文里提到,Canny Edge detector 模型的训练用了 300 万张边缘-图像-标注对的语料,A100 80G 的 600 个 GPU 小时。Human Pose (人体姿态骨架)模型用了 8 万张 姿态-图像-标注 对的语料, A100 80G 的 400 个 GPU 时。
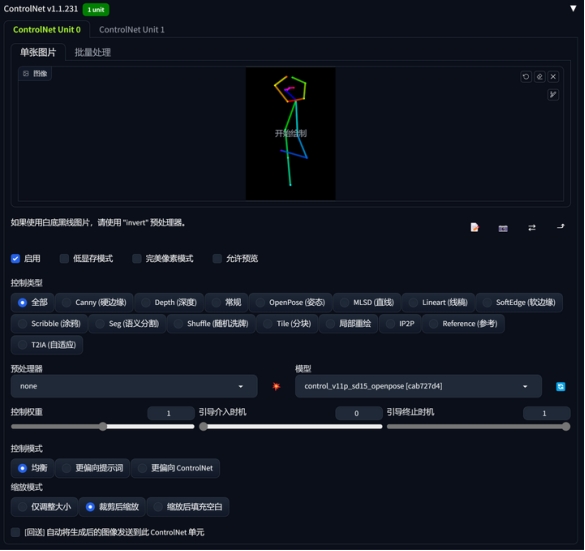
二、腾讯做的一点点工作
在大模型“群模乱舞”的时代,阿里、百度甚至科大讯飞都拿出面向C端的可用的产品,而腾讯一直表现非常低调。
是腾讯缺乏技术吗?
非也。
我本人常年撰写公众号,对公众号的广告推流逻辑进行过细致的分析,大致可以得出结论,至少在广告推荐系统中,腾讯早就使用了专用大模型。
腾讯没有市值管理的需要,也没有业绩之忧,从经营的视角看,比较踏实(其他视角大家观点各异,在此不表),在大模型领域声音比较小,也很正常。
T2I-Adapter 的训练是在 4 块 Tesla 32G-V100 上只花了 2 天就完成,包括 3 种 condition,sketch(15 万张图片),Semantic segmentation map(16 万张)和 Keypose(15 万张)。
腾讯做的T2I-Adapter和ControlNet有一定的相似性,但从论文看,二者的思路又不完全一样。
发布 T2I-Adapter 的腾讯 ARC 是腾讯关注智能媒体相关技术的事业群,以视觉、音频和自然语言处理为主要方向 。
从某种意义上讲,二次元最强大的公司,是腾讯,真心希望Lvmin Zhang能和腾讯ARC珠联璧合。
这两套模型都被Stable Diffusion官方致谢,并将集成入官方代码库。
两套模型有什么区别吗?
ControlNet 目前提供的预训模型,可用性完成度更高,支持更多种的 condition detector (9 大类)。
T2I-Adapter 在工程上设计和实现得更简洁和灵活,更容易集成和扩展”此外,T2I-Adapter 支持一种以上的 condition model 引导,比如可以同时使用 sketch 和 segmentation map 作为输入条件,或 在一个蒙版区域 (也就是 inpaint ) 里使用 sketch 引导。
三、做个对比
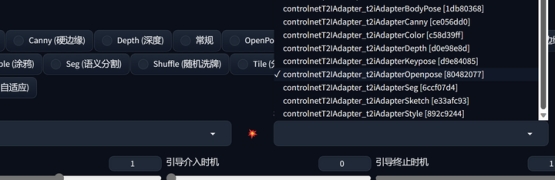
C站有人把腾讯的9个T2I-Adapter 模型进行了梳理和转化,整理成safetensors格式,并做好了配置文件,拷贝到ControlNet的模型库里,直接使用ControlNet调用即可。
模型库路径:extensions\sd-webui-controlnet\models
T2I-Adapter 模型下载地址(yaml文件需要一起下载):
https://www.123pan.com/s/ueDeVv-KJ0I.html 提取码:lgyh
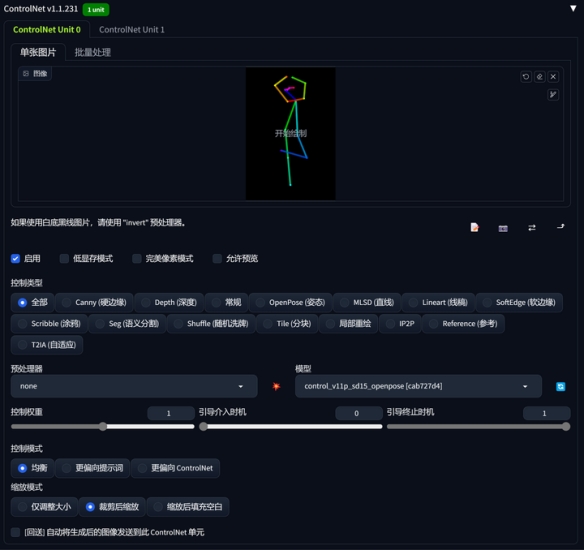
先试试最常用的openpose模型。
1、ControlNet标准模型
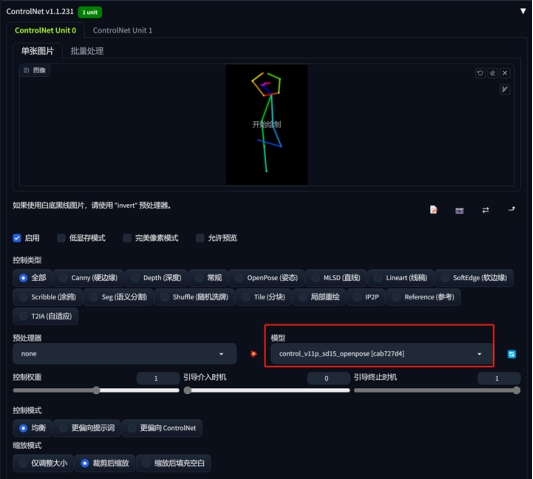
模型:MoonMix_Utopia_3.0(大家可能发现我最近真人模型基本只用这个,是因为这个模型相对“真实”)
提示词:
<lora:school_rooftop_v0.1:1> school rooftop, 1girl, school uniform, building, chain-link fence, wind lift, skirt tug,, masterpiece, best quality, highly detailed
负面提示词:
nsfw,logo,text,badhandv4,EasyNegative,ng_deepnegative_v1_75t,rev2-badprompt,verybadimagenegative_v1.3,negative_hand-neg,mutated hands and fingers,poorly drawn face,extra limb,missing limb,disconnected limbs,malformed hands,ugly

啊,小姐姐你站在楼顶干什么!
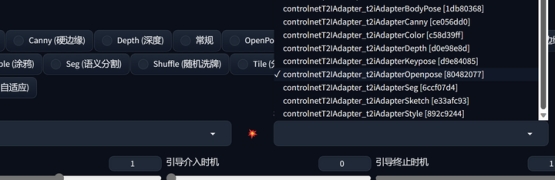
2、T2I-Adapter模型
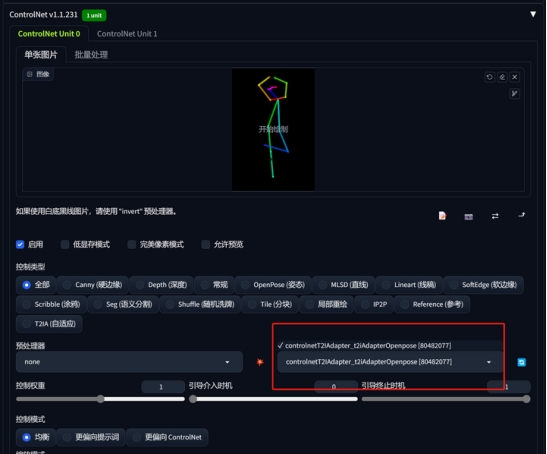
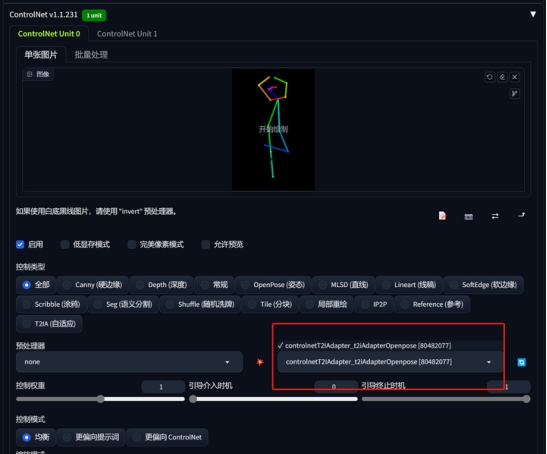
除了模型换成T21Adapter对应的openpose外,其余的保持不变。

从构图方面看,大同小异,基本都按照pose的构图来生成,但画面的色彩方面,略有差异,T21Adapter的画面更有胶片感。
C站上传这组模型的作者是theally,从发布的各种模型和作品看,大概率是一位女性。
她自称从事艺术方面的培训,之所以推荐T21Adapter的模型,是因为:可以产生与官方ControlNet模型相似的结果,但增加了样式和颜色功能。
另外,我发现T21Adapter的模型每个大多300m左右,而ControlNet标准模型每个1.3G左右,效果上二者区别不大,对于硬盘空间不足的选手,T21Adapter也是值得推荐的。
四、下载
1、官方下载:
https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
注意官方下载的pth文件不能直接用,需要自己做配置。
2、C站theally转换好的直接可用下载:
(yaml文件需要一起下载)
https://www.123pan.com/s/ueDeVv-KJ0I.html 提取码:lgyh
出自:https://mp.weixin.qq.com/s/FWi3sy7rsjLcnGQuSx3VAA
周末读了一篇ghostmix模型作者的文章,也引起了我对Stable Diffusion发展方向的思考。
由于访问C站需要科学上网,很长一段时间国内获取AI大模型的方式比较不便。近期随着liblibai等国内AI绘画网站的加入,并通过资本拿真金白银激励创作者,甚至掀起了一股模型创作热潮。
但是,量多不代表质优。
很多所谓大模型不过是融了几个热门lora,并没有真正经过原始图片的训练过程。
形成了ckpt的lora化,这是一个很不好的风向。真正潜心做模型的创作者,甚至陷入了低谷。
ghostmix模型作者认为,应该尽可能的少做大模型,然后使用lora、ControlNet等微调工具来适配更多的场景。
私以为,这个思路是非常正确的。虽然我有4T的SSD不担心下载模型,但是越来越多的模型,动辄3、5个G起步,会大大抬高Stable Diffusion的门槛。
新版的Stable Diffusion XL 0.9刚刚发布(我正在调试,过几天会发个“迟到”但会非常细致的保姆级教程),基础模型更是达到了惊人的13G,如果模型这么泛滥下去,4T的SSD怕是也不够用。

一、ControlNet的革命
ControlNet是一位年轻的斯坦福大学的华人选手创作的,Lvmin Zhang,2021 年本科毕业,现为斯坦福 PHD,并发布了论文阐述其原理。
其实在AI领域,华人非常优秀,大量的AI论文都会看到汉语拼音。
ControlNet用一种极低成本的方案,来控制画面的主体构成。当然,这只是使用者的角度,原作者还是成本(时间、精力等成本,费用反而不算高)很高的。
ControlNet 在论文里提到,Canny Edge detector 模型的训练用了 300 万张边缘-图像-标注对的语料,A100 80G 的 600 个 GPU 小时。Human Pose (人体姿态骨架)模型用了 8 万张 姿态-图像-标注 对的语料, A100 80G 的 400 个 GPU 时。
二、腾讯做的一点点工作
在大模型“群模乱舞”的时代,阿里、百度甚至科大讯飞都拿出面向C端的可用的产品,而腾讯一直表现非常低调。
是腾讯缺乏技术吗?
非也。
我本人常年撰写公众号,对公众号的广告推流逻辑进行过细致的分析,大致可以得出结论,至少在广告推荐系统中,腾讯早就使用了专用大模型。
腾讯没有市值管理的需要,也没有业绩之忧,从经营的视角看,比较踏实(其他视角大家观点各异,在此不表),在大模型领域声音比较小,也很正常。
T2I-Adapter 的训练是在 4 块 Tesla 32G-V100 上只花了 2 天就完成,包括 3 种 condition,sketch(15 万张图片),Semantic segmentation map(16 万张)和 Keypose(15 万张)。
腾讯做的T2I-Adapter和ControlNet有一定的相似性,但从论文看,二者的思路又不完全一样。
发布 T2I-Adapter 的腾讯 ARC 是腾讯关注智能媒体相关技术的事业群,以视觉、音频和自然语言处理为主要方向 。
从某种意义上讲,二次元最强大的公司,是腾讯,真心希望Lvmin Zhang能和腾讯ARC珠联璧合。
这两套模型都被Stable Diffusion官方致谢,并将集成入官方代码库。
两套模型有什么区别吗?
ControlNet 目前提供的预训模型,可用性完成度更高,支持更多种的 condition detector (9 大类)。
T2I-Adapter 在工程上设计和实现得更简洁和灵活,更容易集成和扩展”此外,T2I-Adapter 支持一种以上的 condition model 引导,比如可以同时使用 sketch 和 segmentation map 作为输入条件,或 在一个蒙版区域 (也就是 inpaint ) 里使用 sketch 引导。
三、做个对比
C站有人把腾讯的9个T2I-Adapter 模型进行了梳理和转化,整理成safetensors格式,并做好了配置文件,拷贝到ControlNet的模型库里,直接使用ControlNet调用即可。
模型库路径:extensions\sd-webui-controlnet\models
T2I-Adapter 模型下载地址(yaml文件需要一起下载):
https://www.123pan.com/s/ueDeVv-KJ0I.html 提取码:lgyh
先试试最常用的openpose模型。
1、ControlNet标准模型

模型:MoonMix_Utopia_3.0(大家可能发现我最近真人模型基本只用这个,是因为这个模型相对“真实”)
提示词:
<lora:school_rooftop_v0.1:1> school rooftop, 1girl, school uniform, building, chain-link fence, wind lift, skirt tug,, masterpiece, best quality, highly detailed
负面提示词:
nsfw,logo,text,badhandv4,EasyNegative,ng_deepnegative_v1_75t,rev2-badprompt,verybadimagenegative_v1.3,negative_hand-neg,mutated hands and fingers,poorly drawn face,extra limb,missing limb,disconnected limbs,malformed hands,ugly

啊,小姐姐你站在楼顶干什么!
2、T2I-Adapter模型
除了模型换成T21Adapter对应的openpose外,其余的保持不变。

从构图方面看,大同小异,基本都按照pose的构图来生成,但画面的色彩方面,略有差异,T21Adapter的画面更有胶片感。
C站上传这组模型的作者是theally,从发布的各种模型和作品看,大概率是一位女性。
她自称从事艺术方面的培训,之所以推荐T21Adapter的模型,是因为:可以产生与官方ControlNet模型相似的结果,但增加了样式和颜色功能。
另外,我发现T21Adapter的模型每个大多300m左右,而ControlNet标准模型每个1.3G左右,效果上二者区别不大,对于硬盘空间不足的选手,T21Adapter也是值得推荐的。
四、下载
1、官方下载:
https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
注意官方下载的pth文件不能直接用,需要自己做配置。
2、C站theally转换好的直接可用下载:
(yaml文件需要一起下载)
https://www.123pan.com/s/ueDeVv-KJ0I.html 提取码:lgyh
出自:https://mp.weixin.qq.com/s/FWi3sy7rsjLcnGQuSx3VAA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Simplify Your Video Creation Process