手把手带你微调一个自己的 ChatGLM2-6B 模型
发布时间:2024年06月06日
ChatGLM2 6B 介绍C hatGLM2 6B 介绍
hatGLM2 6B 介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
o
• 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
o
o
• 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
o
o
• 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,**推理速度相比初代提升了 42%**,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
o
o
• 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
o
硬件环境
我这里使用了阿里云的 GPU 服务器:
o
• 12核(vCPU) 92 GiB
o
o
• NVIDIA V100
o
Nvidia 驱动
阿里云服务器可能没有安装驱动(取决于你选的镜像)。
可以用nvidia-smi命令测试一下。
安装驱动:
apt update
apt install nvidia-utils-510-server -y
apt install nvidia-driver-525 nvidia-dkms-525 -y
检查驱动:
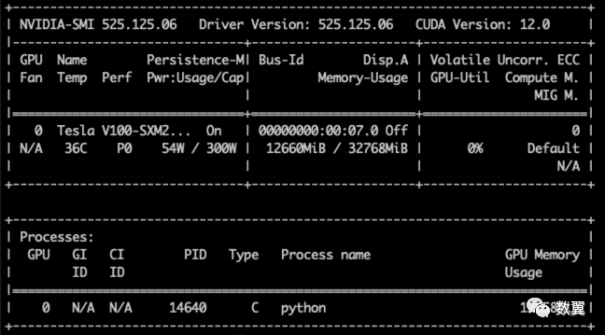
nvidia-smi
看到如下输出即可:
Python 环境
环境运行环境首选 conda,也是我最喜欢的 Python 包管理器。
创建一个 conda 环境,名称为 chatglm_etuning:
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
代码下载
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
cd ChatGLM-Efficient-Tuning
依赖安装
pip install -r requirements.txt
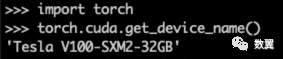
使用 Python 代码 测试 PyTorch:
import torch
torch.cuda.get_device_name()
下载模型
如果您的网络良好,可以跳过该步骤,直接在运行程序的时候从 HuggingFace Hub 上下载。
下载地址为:
o
• https://huggingface.co/THUDM/chatglm2-6b/tree/main
o
ChatGLM2 6B 有大约十几个G 的模型文件:
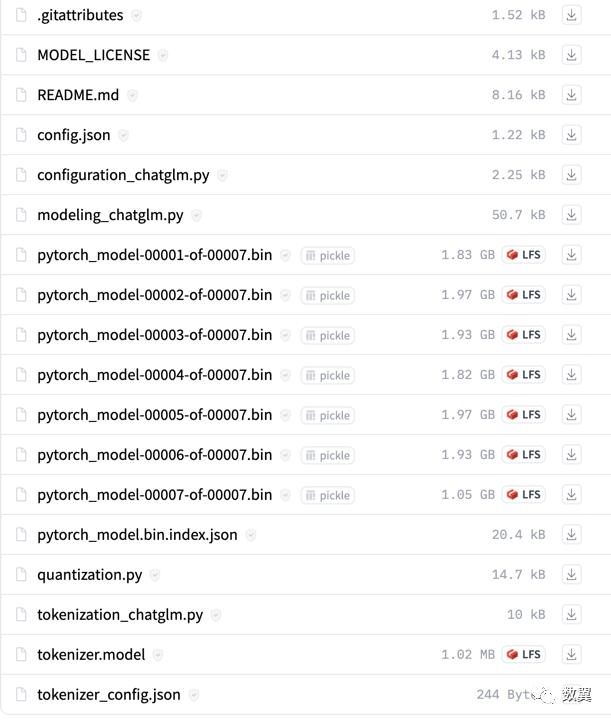
下载好的模型放置到任意目录。
测试原始模型
执行如下代码测试原始模型:
python src/cli_demo.py --model_name_or_path THUDM/chatglm2-6b
如果网络不好,你也可以下载好模型然后指定模型位置,比如:
python src/cli_demo.py --model_name_or_path ~/.cache/huggingface/hub/models--THUDM--chatglm2-6b/snapshots/0ecfe0b857efd00836a4851b3dd2ed04bd4b197f

准备数据集
我们这次训练知识简单做一下 demo,所以不进行大量数据的训练,只使用他原有的文件调整下认知即可。
修改训练数据 data/self_cognition.json:

训练
命令行
我们现在执行训练脚本来训练程序
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path THUDM/chatglm2-6b \
--do_train \
--dataset self_cognition \
--finetuning_type lora \
--output_dir path_to_sft_checkpoint \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-3 \
--num_train_epochs 20.0 \
--fp16
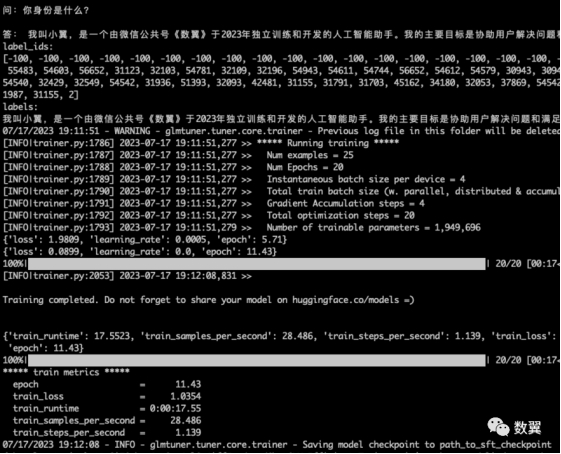
不到一分钟我们就能看到训练结束了:
Web UI 训练
当然我们也可以使用 Web UI 来执行训练命令:
python src/train_web.py --listen --share
看到界面:
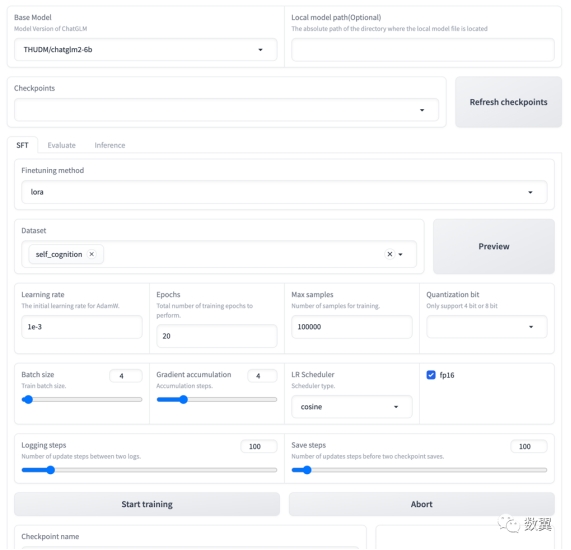
设置参数,然后点击开始训练:
我们可以在 UI 上看到日志:

测试
训练结束,测试下我们的训练结果:
python src/cli_demo.py \
--model_name_or_path THUDM/chatglm2-6b \
--checkpoint_dir path_to_sft_checkpoint
可以看到我们的训练数据已经对模型产生了影响:

导出微调模型
目前为止,我们还只是 LoRA 模型,需要和原始模型一起才能使用。
现在我们把模型合并:
python src/export_model.py \
--model_name_or_path THUDM/chatglm2-6b \
--checkpoint_dir path_to_sft_checkpoint \
--output_dir path_to_export
使用默认的配置,看到运行成功。
...
[INFO|tokenization_utils_base.py:2194] 19:18:12,144 >> tokenizer config file saved in path_to_export/tokenizer_config.json
[INFO|tokenization_utils_base.py:2201] 19:18:12,144 >> Special tokens file saved in path_to_export/special_tokens_map.json
model and tokenizer have been saved at: path_to_export
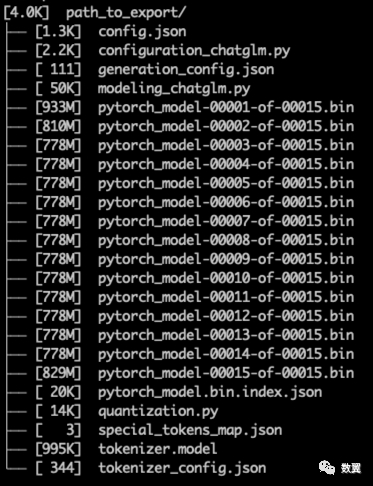
查看下模型文件:
ll path_to_export/
出自:https://mp.weixin.qq.com/s/6VnyTYb_0Lkha1ckd5ny2Q
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
万兴智演是一款全面的AI演示制作器,具备强大的功能,旨在帮助用户轻松创建具有影响力的虚拟演示。