使用自己的数据训练清华ChatGLM2-6B 模型
发布时间:2024年06月06日
服务器准备
不想折腾mac了,正好腾讯云有活动,GPU服务器,8核32G内存16G显存,60块钱半个月,刚好买来试试,活动链接在结尾处。
查看服务器配置
购买完成后收件箱会收到站内消息,包含机器配置和密码,进入服务器后输入命令,可以看到系统中安装的 NVIDIA 显卡的实时信息和状态。
nvidia-smi
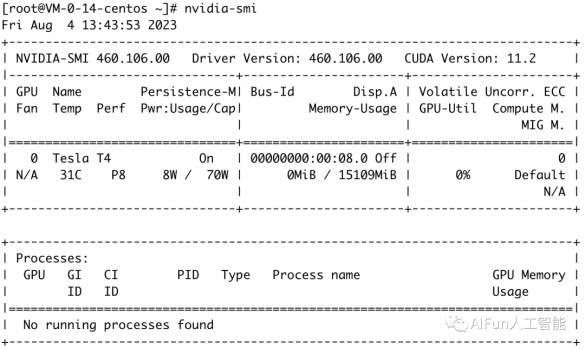 image-20230804134407122
image-20230804134407122
安装python
升级一下系统默认的python版本,此处使用pyenv。
安装pyenv
curl https://pyenv.run | bash
# 安装相应依赖
yum install gcc zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel git libffi-devel
# 安装软件库,否则无法安装openssl11
yum install epel-release
# 安装新版本的openssl
yum install openssl11 openssl11-devel
# 设置编译FLAG,以便使用最新的openssl库
export CFLAGS=$(pkg-config --cflags openssl11)
export LDFLAGS=$(pkg-config --libs openssl11)
# 安装python3.10
pyenv install 3.10.4
# 查看已有环境版本
pyenv versions
# 全局切换 3.10.4 版本
pyenv global 3.10.4
下载源码
https://github.com/THUDM/ChatGLM2-6B
进入项目目录,创建虚拟环境。
python -m venv env
# 进入虚拟环境
source env/bin/activate
# 安装相关依赖
pip install -f requirements.txt
# 退出虚拟环境
deactivate
tree -L 2看一下目录结构:ptuning 目录是模型训练的相关代码
├── FAQ.md
├── MODEL_LICENSE
├── README.md
├── README_EN.md
├── api.py
├── cli_demo.py
├── evaluation
│ ├── README.md
│ └── evaluate_ceval.py
├── openai_api.py
├── ptuning
│ ├── README.md
│ ├── arguments.py
│ ├── deepspeed.json
│ ├── ds_train_finetune.sh
│ ├── evaluate.sh
│ ├── evaluate_finetune.sh
│ ├── main.py
│ ├── train.sh
│ ├── train_chat.sh
│ ├── trainer.py
│ ├── trainer_seq2seq.py
│ ├── web_demo.py
│ └── web_demo.sh
├── requirements.txt
├── resources
│ ├── WECHAT.md
│ ├── cli-demo.png
│ ├── knowledge.png
│ ├── long-context.png
│ ├── math.png
│ ├── web-demo.gif
│ ├── web-demo2.gif
│ └── wechat.jpg
├── utils.py
├── web_demo.py
└── web_demo2.py
代码实现了对于 ChatGLM2-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
什么是P-tuning-v2
我们让claude.ai解释一下:
P-tuning-v2是基于Prompt-tuning方法的NLP模型微调技术。
P-tuning的全称是Prefix-tuning,意为“前缀调优”。它通过在模型输入前添加小段Discrete prompt(类似填空句),并只优化这个prompt来实现模型微调。
P-tuning-v2相较于v1版本主要有以下改进:
o
• 支持连续Prompt,即可以针对不同input动态生成prompt,而不是固定的Discrete prompt。
o
o
• 支持在prompt后接text,而不仅是接[MASK]。
o
o
• prompt可以自定义初始化,并在微调中进行优化。
o
o
• 增加了自动学习prompt长度的机制。
o
o
• 支持Prompt生成。
o
o
• 效果上,P-tuning-v2相比v1提升更明显,效率也有很大提升。
o
总体来说,P-tuning-v2是Prompt tuning技术的升级版本,使得Prompt的表示能力更强,应用也更灵活广泛。它被认为是Prompt tuning类方法中效果最优且易用性最好的版本。
下面以自己的数据集为例介绍代码的使用方法。
软件依赖
运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
准备数据集
可以参考官方示例制作自己的数据集:
官方ADGEN数据集示例是根据输入(content)生成一段广告词(summary)。可以从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到ptuning目录下。
可以看到解压后的文件有两个,分别是train.json和dev.json。
o
• train.json文件是用于训练模型的数据集,里面包含了许多模拟的用户问答对,格式如您所述,每个样本包含一个"content"键表示问题文本,"summary"键表示对应的答案文本。
o
o
• dev.json文件也是一样的格式,但是它是用于验证的,会在训练过程中用于评估模型在这部分数据上的表现。
o
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
这里我使用自己的数据集,数据集来源是一份操作手操,使用Claude生成目标格式的train.json和dev.json,数据举例
{
"content": "修改业务客户信息的步骤是什么?",
"summary": "在客服管理-客户管理-业务客户信息页面,选择需要修改的客户,点击修改按钮,在弹出的修改页面填写客户新的名称、联系人、地址等信息,然后点击页面下方的保存按钮,即可完成客户信息的修改。"
}
修改一些代码
修改train.sh
# 这两处改为自己数据集的路径
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
# 数据集少的话,训练步数可以调小,我改为了100
--max_steps 3000
修改main.py
在代码的351行,代码注释掉了 trainer.save_model(),这是保存模型的语句。当训练完成后就会生成一个pytorch_model.bin文件,后面会用到。
解开这里的注释:
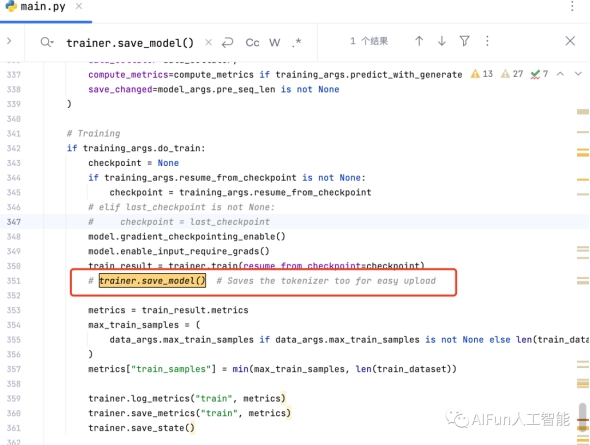 image-20230805174737559
image-20230805174737559
训练P-Tuning v2
运行以下指令进行训练:
./train.sh
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
如果你想要从本地加载模型,可以将 train.sh 中的 THUDM/chatglm2-6b 改为你本地的模型路径。
这是控制台输出
[INFO|trainer.py:1786] 2023-08-05 19:34:17,764 >> ***** Running training *****
[INFO|trainer.py:1787] 2023-08-05 19:34:17,764 >> Num examples = 38
[INFO|trainer.py:1788] 2023-08-05 19:34:17,764 >> Num Epochs = 50
[INFO|trainer.py:1789] 2023-08-05 19:34:17,764 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1790] 2023-08-05 19:34:17,764 >> Total train batch size (w. parallel, distributed & accumulation) = 16
[INFO|trainer.py:1791] 2023-08-05 19:34:17,764 >> Gradient Accumulation steps = 16
[INFO|trainer.py:1792] 2023-08-05 19:34:17,764 >> Total optimization steps = 100
[INFO|trainer.py:1793] 2023-08-05 19:34:17,765 >> Number of trainable parameters = 1,835,008
0%| | 0/100 [00:00<?, ?it/s]08/05/2023 19:34:17 - WARNING - transformers_modules.THUDM.chatglm2-6b.b1502f4f75c71499a3d566b14463edd62620ce9f.modeling_chatglm - `use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
{'loss': 3.0614, 'learning_rate': 0.018000000000000002, 'epoch': 4.21}
{'loss': 2.2158, 'learning_rate': 0.016, 'epoch': 8.42}
{'loss': 1.6043, 'learning_rate': 0.013999999999999999, 'epoch': 12.63}
{'loss': 1.1897, 'learning_rate': 0.012, 'epoch': 16.84}
41%|█████████████████████████▍ | 41/100 [08:52<12:45, 12.97s/it]
主要包含以下信息:
1.
1. 在*** Running training ***下面打印出训练数据集样本数量(Num examples)、训练轮数(Num Epochs)等超参数。
2.
3.
2. 前4行打印了batch size及优化信息,如每设备batch size、总batch size、梯度累积步数、总优化步数等。
4.
5.
3. 打印了模型的参数量(Number of trainable parameters),这里是1.8亿参数。
6.
7.
4. 打印了一条警告信息,提示不兼容的设置,已自动更改。
8.
9.
5. 接下来每隔几轮打印一次当前的训练loss、学习率和epoch信息,可以看到loss有下降的趋势。减小的Loss表示模型训练是有效的,性能得到了提升
10.
11.
6. 最后一行打印当前的训练进度,这里已经训练了41步,总计100步,每个step耗时约13秒。
12.
13.
7. 中间的进度条也直观显示训练进度。
14.
训练完成
Saving PrefixEncoder
[INFO|configuration_utils.py:458] 2023-08-05 19:55:56,218 >> Configuration saved in output/adgen-chatglm2-6b-pt-128-2e-2/config.json
[INFO|configuration_utils.py:364] 2023-08-05 19:55:56,218 >> Configuration saved in output/adgen-chatglm2-6b-pt-128-2e-2/generation_config.json
[INFO|modeling_utils.py:1853] 2023-08-05 19:55:56,233 >> Model weights saved in output/adgen-chatglm2-6b-pt-128-2e-2/pytorch_model.bin
[INFO|tokenization_utils_base.py:2194] 2023-08-05 19:55:56,233 >> tokenizer config file saved in output/adgen-chatglm2-6b-pt-128-2e-2/tokenizer_config.json
[INFO|tokenization_utils_base.py:2201] 2023-08-05 19:55:56,233 >> Special tokens file saved in output/adgen-chatglm2-6b-pt-128-2e-2/special_tokens_map.json
***** train metrics *****
epoch = 42.11
train_loss = 1.0075
train_runtime = 0:21:38.44
train_samples = 38
train_samples_per_second = 1.232
train_steps_per_second = 0.077
Finetune
如果需要进行全参数的 Finetune,需要安装 Deepspeed,然后运行以下指令:
bash ds_train_finetune.sh
训练完成后的output目录文件:
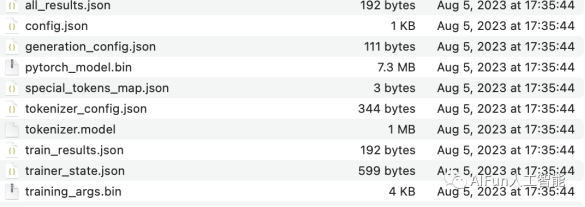 image-20230805174618513
image-20230805174618513
测试
修改web_demo.sh的ptuning_checkpoint参数
PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/ \
--pre_seq_len $PRE_SEQ_LEN
为什么要修改,可以看这里,需要加载的 P-Tuning 的 checkpoint:
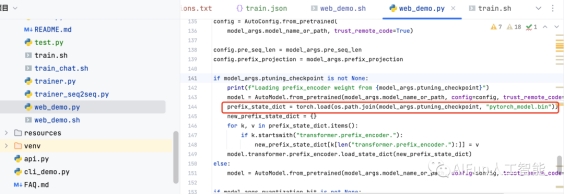 image-20230805200855314
image-20230805200855314
./web_demo.sh
Running on local URL: http://127.0.0.1:7860
我这里使用了nginx进行代理:
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://127.0.0.1:7860;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
}
}
输入访问地址,进行测试,成功!
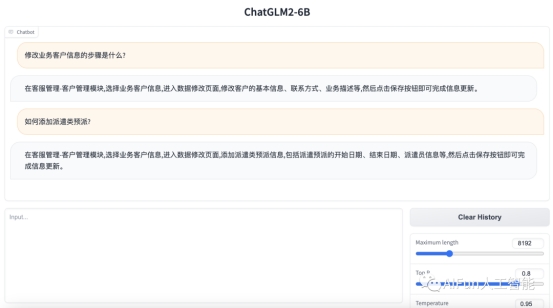 image-20230805200030528
image-20230805200030528
推理
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM2-6B 模型以及 PrefixEncoder 的权重,因此需要指定 evaluate.sh 中的参数:
--model_name_or_path THUDM/chatglm2-6b
--ptuning_checkpoint $CHECKPOINT_PATH
运行evaluate.sh,等完成后会输出:
***** predict metrics *****
predict_bleu-4 = 32.536
predict_rouge-1 = 58.1861
predict_rouge-2 = 31.1951
predict_rouge-l = 49.2416
predict_runtime = 0:04:09.78
predict_samples = 38
predict_samples_per_second = 0.152
predict_steps_per_second = 0.152
生成的结果保存在 ./output/adgen-chatglm2-6b-pt-128-2e-2/generated_predictions.txt。结果示例:
{"labels": "首先进入客服管理系统,打开业务客户信息管理页面,在列表中找到需要修改的客户,然后点击右边的修改按钮打开修改窗口,在窗口中可以修改客户的名称、联系人信息、地址等内容,修改完成后点击保存按钮,这样就可以更新客户的最新信息,完成修改操作",
"predict": "在客服管理-客户管理-业务客户信息页面,选择需要修改的客户,点击修改按钮,在弹出的修改页面填写客户新的名称、联系人、地址等信息,然后点击页面下方的保存按钮,即可完成客户信息的修改。"}
推理后生成的文件
 image-20230805183856057
image-20230805183856057
对话数据集
如需要使用多轮对话数据对模型进行微调,可以提供聊天历史,例如以下是一个三轮对话的训练数据:
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}
训练时需要指定 --history_column 为数据中聊天历史的 key(在此例子中是 history),将自动把聊天历史拼接。要注意超过输入长度 max_source_length 的内容会被截断。
可以参考以下指令:
bash train_chat.sh
结尾
活动链接:https://cloud.tencent.com/act/cps/redirect?redirect=35793&cps_key=d7ac5241b4606313a8f1a14a7df1f666
出自:https://mp.weixin.qq.com/s/--F6_0fSRybBpupwPEGotQ
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
利用数据和计算来创建越来越复杂和强大的大语言模型