Embedding开源模型重磅玩家:北京智源人工智能研究院最新Embedding模型发布!登顶MTEB,免费商用授权!
发布时间:2024年06月06日
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。
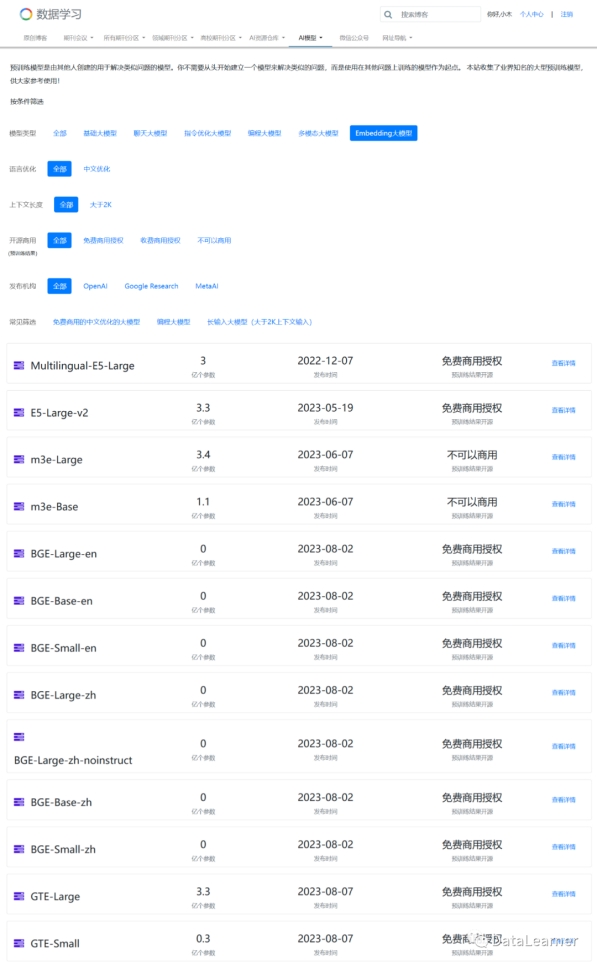
来源:https://www.datalearner.com/ai-models/pretrained-models?&aiArea=1005&language=-1&contextLength=-1&openSource=-1&publisher=-1
·
Embedding模型的重要性
·
·
BGE系列Embedding模型介绍和训练细节
·
·
BGE系列Embedding模型的效果
·
·
BGE系列Embedding模型的使用
·
·
BGE系列的Embedding模型的总结
·
Embedding模型的重要性
Embedding模型,简单来说,是一种能够将词、短语或整个句子转化为向量形式的技术。这些向量能够捕捉到语义的丰富含义,使计算机可以像处理数字一样来处理文本。在大语言模型时代,Embedding模型可以帮助大模型处理更长的上下文,也可以将大模型与私有数据结合。
关于Embedding的具体介绍和其重要性参考:AI大模型领域的热门技术——Embedding入门介绍以及为什么Embedding在大语言模型中很重要:https://www.datalearner.com/blog/1051683647195362,这里就不再赘述。
尽管开源的LLM很多,强大的embedding模型却很少,尤其是支持中文的可商用的开源embedding模型更少。而此次BAAI发布的BGE系列Embedding模型则是一个天大的好消息!
BGE系列Embedding模型介绍和训练细节
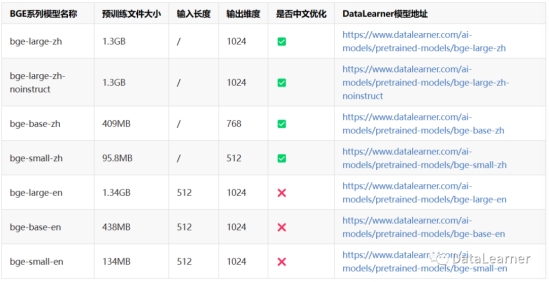
BGE全称是BAAI General Embedding,即北京智源人工智能研究院通用Embedding模型,它可以将任意文本映射到低维的稠密向量。本次发布的BGE系列包含7个版本,其中4个是中文优化的Embedding模型,3个是英文的Embedding模型。
BGE模型的训练有2个阶段:分别是预训练阶段和微调阶段。
在预训练阶段,BGE模型通过使用RetroMAE方法在中英文数据集上进行了预训练。其中英文数据集维Pile、维基百科和msmarco,而中文数据集则来自于wudao。训练使用了24个A100(40G)。
wudao数据集:https://www.datalearner.com/blog/1051648084659749
在微调阶段,BGE使用三元组数据(query, positive, negative)进行微调。使用了48个A100(40G)的资源。目前,该数据没有开源,不过官方宣称未来将开源。
BGE系列模型如下:
BGE系列Embedding模型的效果
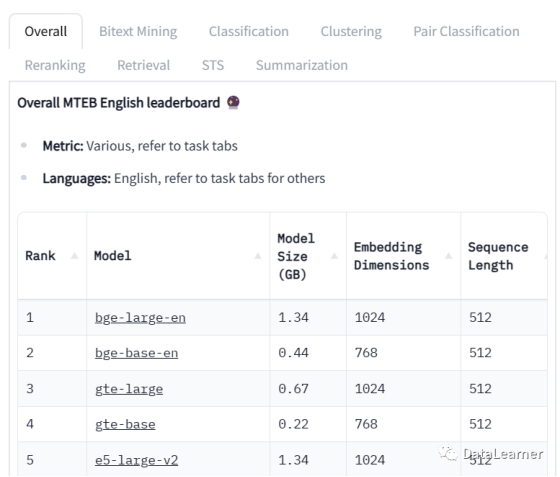
目前,Embedding领域的评测比较有影响力范围覆盖较全的是HuggingFace的MTEB排行榜。MTEB全称Massive Text Embedding Benchmark,收集了97个Embedding模型的数据,在74个数据集上评测结果。不过这个排行榜的评测只支持英文。
在MTEB目前的排行榜中,排名前2的就是BGE的两个英文模型,分别是bge-large-en和bge-base-en。
而中文的embedding评测目前缺少足够有权威的排行榜。因此,BAAI自己也发布了一个关于Embedding模型的评测数据,称为C-MTEB,这里的C就是Chinese了。在这个榜单中,目前覆盖了10个模型的评测结果:
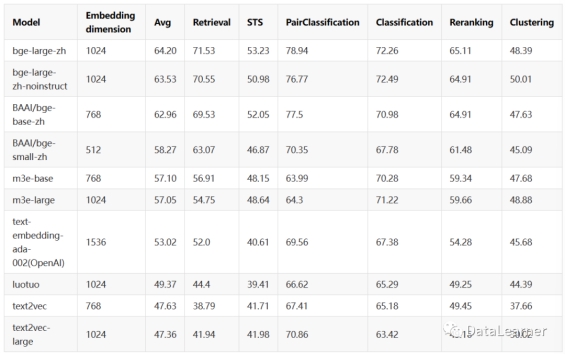
可以看到,BGE的模型效果也都是很好的。
BGE系列Embedding模型的使用
BGE模型支持BAAI自己的FlagEmbedding框架,也支持HuggingFace的Sentence-Transformers框架,使用很简单。这里给出Sentence-Transformers框架使用方法:
1.
from sentence_transformers importSentenceTransformer
2.
3.
sentences =["样例数据-1","样例数据-2"]
4.
5.
model =SentenceTransformer('BAAI/bge-large-zh')
6.
7.
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
8.
9.
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
10.
11.
smilarity = embeddings_1 @ embeddings_2.T
12.
13.
print(smilarity)
14.
需要注意的是,如果你用BGE来做检索任务,那么需要对每一个查询增加一条指令,如下所示:
1.
from langchain.embeddings importHuggingFaceInstructEmbeddings
2.
3.
encode_kwargs ={'normalize_embeddings':True}
4.
5.
model =HuggingFaceInstructEmbeddings(
6.
7.
model_name='BAAI/bge-large-en',
8.
9.
embed_instruction="",
10.
11.
query_instruction="Represent this sentence for searching relevant passages: ",
12.
13.
encode_kwargs=encode_kwargs
14.
15.
)
16.
BGE系列的Embedding模型的总结
BGE系列模型在MTEB榜单霸榜之后就引起了很多人的关注。对于我们来说,BGE最大的好处是支持中文,且商用免费授权,是中文embedding模型中为数不多的优质选择。而它英文榜单霸榜也引起了很多人的使用,推特上也十分火爆。
BGE一个问题是它的输入序列只有512,这在很多场景下可能不够用。而OpenAI的text-embedding-ada-002最高支持8K的序列长度。不过,在开源领域,512的序列长度输入是主流的输入长度了。MTEB榜单前20名中,除了OpenAI的模型支持8K序列输入,其它模型都是只支持512序列输入。
关于BGE的开源地址、模型权重下载地址等,请参考DataLearner的Embedding模型列表:
https://www.datalearner.com/ai-models/pretrained-models?&aiArea=1005&language=-1&contextLength=-1&openSource=-1&publisher=-1
Embedding模型筛选也是DataLearner大模型筛选新增的一个功能,目前涵盖的模型还是相对较少,正在完善中~
出自:https://mp.weixin.qq.com/s/WImNAKML6F-9Aj3WtXu0vA
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
SparkAi系统支持GPT4.0、Midjourney绘画、GPT3.5 API绘画、GPT联网功能、绘画广场功能、Prompt功能,后台自定义添加,用户也可自定义添加+实时语音识别输入、用户会员套餐、用户每日签到功能、支持手机电脑不同布局页面自适应。