国产AI大模型哪家强?十大维度横评四款主流大模型!
发布时间:2024年06月06日
自从 chatGPT 火热出圈,由生成式 AI 掀起的全球人工智能新浪潮就拉开了序幕,围绕认知大模型的类 ChatGPT 技术和产品正在不断涌现。
对于国内用户来说,目前不少大模型产品已经开放内测。不过,目前这些大模型产品在完善度、功能性、易用性等方面都各有不同,大家可能不知如何选择。今天,IT之家不妨就针对几款产品为大家做个体验横评。本次横评测试,IT之家主要针对通用大模型产品,并且选择了目前知名度比较高的四款产品,分别是百度的文心一言、科大讯飞的讯飞星火、阿里的通义千问和 360 智脑。  不同的测试大类中,我们以满分 10 分计,如果某款大模型在某个测试小项中不符合要求或者体验不好,根据轻重每次扣除 1-3 分,最后剩余的分数为该大模型在这个测试大类的评分。评测以及评分过程中难免会存在主观的因素,因此分数仅供大家参考。由于接下来详细评测部分内容较多,为了方便大家更好地抓住重点,小编不妨先将评测结果先简要透露一下。这次对比横评共 10 个大项,每个大项 10 分,总分也就是 100 分。而具体四款产品的得分分别是:
不同的测试大类中,我们以满分 10 分计,如果某款大模型在某个测试小项中不符合要求或者体验不好,根据轻重每次扣除 1-3 分,最后剩余的分数为该大模型在这个测试大类的评分。评测以及评分过程中难免会存在主观的因素,因此分数仅供大家参考。由于接下来详细评测部分内容较多,为了方便大家更好地抓住重点,小编不妨先将评测结果先简要透露一下。这次对比横评共 10 个大项,每个大项 10 分,总分也就是 100 分。而具体四款产品的得分分别是:
讯飞星火:93 分文心一言:84 分360 智脑:75 分通义千问:71 分
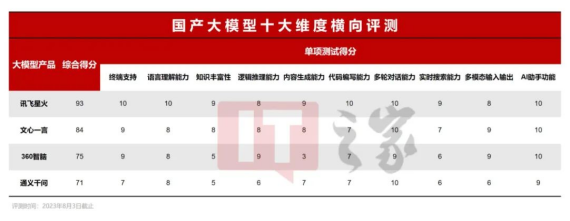
讯飞星火的表现相信会让大家感到惊艳,事实也是在这次横评中,讯飞星火在每个项目都能保持前二的成绩,特别建议大家关注他在实时搜索、内容生成和代码编写方面的表现。此外文心一言也是不错的,在内容生成、避坑能力、多模态输出等方面都有不俗之处。当然,具体每款产品为什么最终是这个分数?好在哪里?丢分项又在哪里?大家则可以通过下面详细的评测过程进行了解。话不多说,就让我们开始吧。一、终端支持在大模型支持的平台丰富度方面,文心一言目前支持网页端、安卓 /iOS App,暂时没有桌面 / Mac 版和微信小程序。 通义千问目前则只有网页端可用。360 智脑方面,目前覆盖了网页版、安卓 /iOS 移动 App 和桌面版(无 Mac),支持的平台还是比较多的。
通义千问目前则只有网页端可用。360 智脑方面,目前覆盖了网页版、安卓 /iOS 移动 App 和桌面版(无 Mac),支持的平台还是比较多的。 而覆盖最多的是讯飞星火,目前讯飞星火是唯一支持五端(安卓、IOS、小程序、PC、H5)全覆盖的大模型。
而覆盖最多的是讯飞星火,目前讯飞星火是唯一支持五端(安卓、IOS、小程序、PC、H5)全覆盖的大模型。 这一环节,小编给四款产品的评分分别是:
这一环节,小编给四款产品的评分分别是:
讯飞星火:10 分360 智脑:9 分文心一言:9 分通义千问:7 分
二、语言理解能力测试AI 大模型的本质其实就是大语言模型,因此语言理解可以说是影响各种大模型产品体验的基础要素。这里小编先测试上面四款产品对中文语意的理解能力。① 语意理解首先用经典的一词多意的段子来考验大模型们:领导说:“你这是什么意思?”小明说:“没什么意思,意思意思。" 领导说:“你这就不够意思了。”小明说:“小意思,小意思。”这段话里,不同的“意思”分别代表什么意思?先看文心一言的解释,具体、准确,没有遗漏: 通义千问不仅回答了每个“意思”的意思,更给出了职场沟通的建议,回答很有逻辑性:
通义千问不仅回答了每个“意思”的意思,更给出了职场沟通的建议,回答很有逻辑性: 讯飞星火的回答也是比较靠谱的,对每个“意思”的解释相比前两者更详尽深入,特别是最后一句,讯飞星火对一句话里的两个“小意思”都做了解释。
讯飞星火的回答也是比较靠谱的,对每个“意思”的解释相比前两者更详尽深入,特别是最后一句,讯飞星火对一句话里的两个“小意思”都做了解释。 360 智脑的回答就有点简单了,回答得比较模糊笼统:
360 智脑的回答就有点简单了,回答得比较模糊笼统: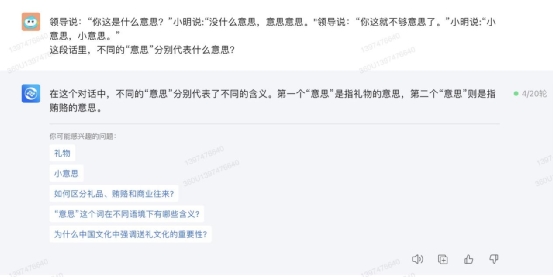 ② 情感分析接下来,小编要看看这几款大模型能不能准确分析一段文本中的情感色彩,能否更好地了解文本内容观点和态度。因此小编选择一段经典电影台词来测试。从结果来看,文心一言、讯飞星火、360 智脑和通义千问的回答各有特点,但整体意思都是准确的,都没有把句子的含义局限在“鸟”这个喻体上,因此回答都是合格的。
② 情感分析接下来,小编要看看这几款大模型能不能准确分析一段文本中的情感色彩,能否更好地了解文本内容观点和态度。因此小编选择一段经典电影台词来测试。从结果来看,文心一言、讯飞星火、360 智脑和通义千问的回答各有特点,但整体意思都是准确的,都没有把句子的含义局限在“鸟”这个喻体上,因此回答都是合格的。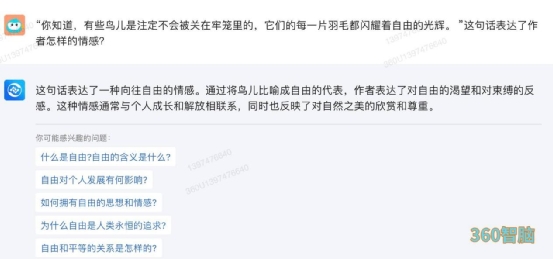


 ③ 摘要提炼这部分的最后,我们来看看四款大模型对文本的总结提炼能力。小编从IT之家随机选择了一篇新闻资讯,分别让四款大模型将这篇新闻总结成一句话的摘要。先看文心一言的表现,虽然是总结了,意思也正确,但总结得比较啰嗦,而且不符合“一句话”的要求:
③ 摘要提炼这部分的最后,我们来看看四款大模型对文本的总结提炼能力。小编从IT之家随机选择了一篇新闻资讯,分别让四款大模型将这篇新闻总结成一句话的摘要。先看文心一言的表现,虽然是总结了,意思也正确,但总结得比较啰嗦,而且不符合“一句话”的要求: 通义千问也有类似的问题,总结啰嗦,而且超过一句话的限制:
通义千问也有类似的问题,总结啰嗦,而且超过一句话的限制: 360 智脑在这一项中表现不错,一句话准确总结了这段文章的大意:
360 智脑在这一项中表现不错,一句话准确总结了这段文章的大意: 讯飞星火提炼得也很精炼,一句话搞定,而且意思准确。
讯飞星火提炼得也很精炼,一句话搞定,而且意思准确。 在这一环节,四款大模型产品的得分分别为:
在这一环节,四款大模型产品的得分分别为:
讯飞星火:10 分通义千问:8 分(摘要提炼 - 2)360 智脑:8 分(语意理解 - 2)文心一言:8 分(摘要提炼 - 2)
三、知识丰富性测试很多人会用 AI 大模型会取代搜索引擎,因为用大模型搜索各种知识类信息很方便,还没有广告。这时候大模型的知识丰富度就比较重要了。本次测试IT之家针对四个类别的知识对所选大模型进行考验测试。① 生活常识类生活常识方面,IT之家首先用“平桥豆腐属于哪个菜系?”分别问四款大模型。其中,讯飞星火和文心一言给出了正确回答,属于淮扬菜,而且还给出了这道菜的做法。
 这个问题中,通义千问和 360 智脑回答错误,分别说成了豫菜和川菜。
这个问题中,通义千问和 360 智脑回答错误,分别说成了豫菜和川菜。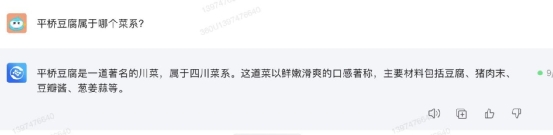
 ② 工作技能类在工作技能类知识方面,IT之家用“如何在 WPS 中连续使用格式刷”这个问题来询问。文心一言给出了两个方法,分别是点击按钮和快捷键,其中快捷键的方法正确,按钮法错误,应该扣 1 分。
② 工作技能类在工作技能类知识方面,IT之家用“如何在 WPS 中连续使用格式刷”这个问题来询问。文心一言给出了两个方法,分别是点击按钮和快捷键,其中快捷键的方法正确,按钮法错误,应该扣 1 分。 讯飞星火之给出了双击格式刷按钮的方法,虽然正确,但缺少快捷键法,也应扣 1 分。
讯飞星火之给出了双击格式刷按钮的方法,虽然正确,但缺少快捷键法,也应扣 1 分。 360 智脑和通义千问给的方法,都不是小编需要的格式刷连续刷的方法,也没有给出快捷键法,因此扣 2 分。
360 智脑和通义千问给的方法,都不是小编需要的格式刷连续刷的方法,也没有给出快捷键法,因此扣 2 分。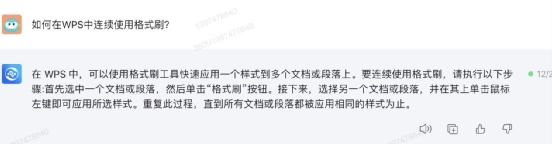
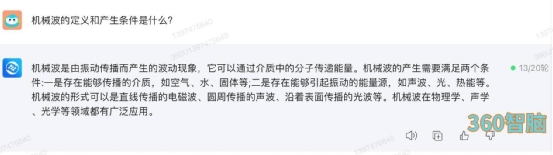
 ③理工专业知识类理工专业知识方面,小编随便选择一个大学物理相关的知识点来考这四款大模型。从结果来看,四款产品的回答都是不错的,其中百度文心一言的回答尤其详细,还顺带介绍了横波与纵波的定义。
③理工专业知识类理工专业知识方面,小编随便选择一个大学物理相关的知识点来考这四款大模型。从结果来看,四款产品的回答都是不错的,其中百度文心一言的回答尤其详细,还顺带介绍了横波与纵波的定义。

 ④ 历史人文类接下来是历史人文类知识,IT之家用“《红楼梦》中结的两个大型诗社和社长分别是谁?”这个问题来考验。这是一个相对难且小众的问题。首先看文心一言,两个诗社答对了,但是社长答错了一个,海棠社的社长是李纨。
④ 历史人文类接下来是历史人文类知识,IT之家用“《红楼梦》中结的两个大型诗社和社长分别是谁?”这个问题来考验。这是一个相对难且小众的问题。首先看文心一言,两个诗社答对了,但是社长答错了一个,海棠社的社长是李纨。 通义千问对这个问题的回答有点离谱,诗社和社长都答错了,而且会让人有一种“咱们看的是同一本《红楼梦》吗”的感觉。
通义千问对这个问题的回答有点离谱,诗社和社长都答错了,而且会让人有一种“咱们看的是同一本《红楼梦》吗”的感觉。 360 智脑的回答也不太好,第二个大型诗社应该是桃花社,而且两位社长的回答都不对。
360 智脑的回答也不太好,第二个大型诗社应该是桃花社,而且两位社长的回答都不对。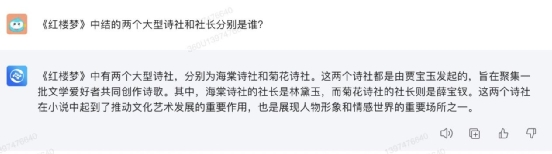 最后是讯飞星火,这是这个问题中唯一把两个小问都答对的选手:
最后是讯飞星火,这是这个问题中唯一把两个小问都答对的选手: 也许是因为科大讯飞本身有做 AI 教育业务的因素,掌握大量的教育大数据,因此整体测下来在知识丰富性和准确性方面的表现是比较亮眼的。这个环节中,四款大模型最终的评分分别为:
也许是因为科大讯飞本身有做 AI 教育业务的因素,掌握大量的教育大数据,因此整体测下来在知识丰富性和准确性方面的表现是比较亮眼的。这个环节中,四款大模型最终的评分分别为:
讯飞星火:9 分(工作技能类 - 1)文心一言:8 分(工作技能类 - 1,历史人文类 - 1)360 智脑:5 分(生活常识类 - 1,工作技能类 - 2,历史人文类 - 2)通义千问:5 分(生活常识类 - 1,工作技能类 - 2,历史人文类 - 2)
四、逻辑推理能力测试AI 大模型是否足够聪明,很大程度上取决于大模型是否具备足够强大的逻辑推理能力。因此本次横评,IT之家也准备了一些逻辑思维相关的考题来分别考验四款大模型。① 逻辑推理问题测试首先,小编用一个经典的逻辑推理问题来考验参与评测的 AI 大模型产品,问题如下:“小明牵着一只狗和两只小羊回家,路上遇到一条河,没有桥,只有一条小船,并且船很小,他每次只能带一只狗或一只小羊过河。你能帮他想想办法,把狗和小羊都带过河去,又不让狗吃到小羊吗?”对于这个问题,文心一言的回答第一步就错了,先带一只羊过河,那么原岸的狗就会将另一只羊吃掉。而且看文心一言的回答,基本属于“一本正经地胡说八道”,五个步骤看得人云里雾里。 通义千问的回答也不对,而且比较敷衍。
通义千问的回答也不对,而且比较敷衍。 讯飞星火的回答基本正确,但是如果较真的话,最后还差一个把狗带到对岸的步骤,因此应该扣 1 分。
讯飞星火的回答基本正确,但是如果较真的话,最后还差一个把狗带到对岸的步骤,因此应该扣 1 分。 360 智脑这次的回答还是比较完美的,步骤全,而且能看懂。
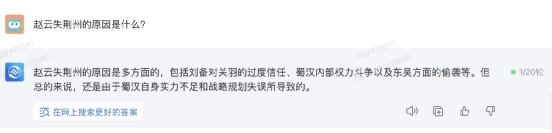
360 智脑这次的回答还是比较完美的,步骤全,而且能看懂。 ② 常识错误、陷阱识别能力测试接着更进一步,小编在提问中设置一些陷进、错误,看看这四款大模型能否准确判断出题目中的陷进,并成功避坑。这里小编用的问题是“赵云失荆州的原因是什么?”对于这个问题,360 智脑和讯飞星火都没有指出题干的错误,但是从回答中能看到,他们的回答还是以“关羽失荆州的原因”来回答的。因此这里我们就扣 1 分吧。
② 常识错误、陷阱识别能力测试接着更进一步,小编在提问中设置一些陷进、错误,看看这四款大模型能否准确判断出题目中的陷进,并成功避坑。这里小编用的问题是“赵云失荆州的原因是什么?”对于这个问题,360 智脑和讯飞星火都没有指出题干的错误,但是从回答中能看到,他们的回答还是以“关羽失荆州的原因”来回答的。因此这里我们就扣 1 分吧。
 通义千问的回答全程都深信是“赵云失了荆州”,而且它的回答看起来有点离谱,还有“导致荆州被曹操攻占”的诡异发言。
通义千问的回答全程都深信是“赵云失了荆州”,而且它的回答看起来有点离谱,还有“导致荆州被曹操攻占”的诡异发言。 这个问题中回答的最好的是文心一言,不仅指出了题干的错误,也准确分析了关于丢失荆州的原因。
这个问题中回答的最好的是文心一言,不仅指出了题干的错误,也准确分析了关于丢失荆州的原因。 本环节四款大模型产品的评分分别为:
本环节四款大模型产品的评分分别为:
360 智脑:9 分(避坑 - 1)讯飞星火:8 分(逻辑问题 - 1,避坑 - 1)文心一言:8 分(逻辑问题 - 2)通义千问:6 分(逻辑问题 - 2,避坑 - 2)
五、内容生成能力测试用户使用大模型的另一大用途就是让它们帮助写一些实用性文案,比如招聘文案、通知文书、店面评价、甚至让他们创作文章、小说、论文等等。我们把这些统称为内容生成能力。这也应该成为评测体验大模型的重要项目之一。① 文案创作我们首先来看四款大模型产品的实用文案创作能力,小编让分别它们写一段招聘文案,并给出了详细要求。还是先看文心一言的回答,它创作的文案是符合要求的,并且条理清晰,风格也没跑偏,属于稍微改改就能直接用的水平。
 通义千问创作的文案整体是不错的,但是最后一段让人看着有点蒙圈,可见它对要求的理解还是有点问题,这里需要扣 1 分。
通义千问创作的文案整体是不错的,但是最后一段让人看着有点蒙圈,可见它对要求的理解还是有点问题,这里需要扣 1 分。 360 智脑创作的文案有点过于简洁了,虽然条件也都符合,但文案看着有些机械,格式也不够清晰明了,因此也扣 1 分。
360 智脑创作的文案有点过于简洁了,虽然条件也都符合,但文案看着有些机械,格式也不够清晰明了,因此也扣 1 分。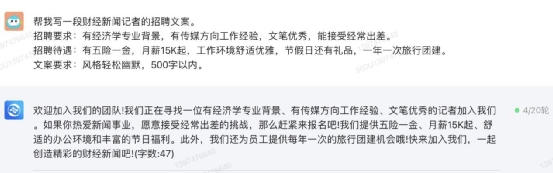 最后是讯飞星火,它创作的文案也是挺好的,基本没什么问题,也是稍微改改就能直接使用了。
最后是讯飞星火,它创作的文案也是挺好的,基本没什么问题,也是稍微改改就能直接使用了。 ② 故事接龙故事接龙也是考验大模型创作能力的好方法,因此在第二部分,小编主要考验四款大模型产品的故事接龙创作能力。我们以那个经典的开头做引子:世界末日后,我成为地球上唯一幸存的人,独自坐在房间里,这时,突然想起了敲门声…… 然后让大模型续写后面的故事。文心一言的续写整体不错,只是在最后稍微有一些逻辑不通畅的地方,但瑕不掩瑜,而且语言表达中还夹杂着讲述者的情感,不是仅仅在陈述一个故事。
② 故事接龙故事接龙也是考验大模型创作能力的好方法,因此在第二部分,小编主要考验四款大模型产品的故事接龙创作能力。我们以那个经典的开头做引子:世界末日后,我成为地球上唯一幸存的人,独自坐在房间里,这时,突然想起了敲门声…… 然后让大模型续写后面的故事。文心一言的续写整体不错,只是在最后稍微有一些逻辑不通畅的地方,但瑕不掩瑜,而且语言表达中还夹杂着讲述者的情感,不是仅仅在陈述一个故事。 通义千问的续写也不错,条理清楚逻辑完整,是一个比较合格的续写。
通义千问的续写也不错,条理清楚逻辑完整,是一个比较合格的续写。 讯飞星火的续写也很好,描写比较细致,设定也还算合理,和通义千问类似,中规中矩。
讯飞星火的续写也很好,描写比较细致,设定也还算合理,和通义千问类似,中规中矩。 360 智脑的续写相对简单,没有细节,因此需要扣 1 分。
360 智脑的续写相对简单,没有细节,因此需要扣 1 分。 ③ 文章写作学生朋友们也可以利用大模型的文章生成能力,来生成范文,学习如何写好对应题材的文章。这里IT之家以 "家庭环境对人成长的影响" 为主题,让四款大模型写一篇高考水平的作文,看看他们的写作能力如何吧。首先是文心一言写的作文,文章整体逻辑通畅,结构清晰,论点有条有理,可以成为学生写作时用以参考的素材,但是也有不足,首先是缺少论据,其次文章篇幅较短,扣 2 分。
③ 文章写作学生朋友们也可以利用大模型的文章生成能力,来生成范文,学习如何写好对应题材的文章。这里IT之家以 "家庭环境对人成长的影响" 为主题,让四款大模型写一篇高考水平的作文,看看他们的写作能力如何吧。首先是文心一言写的作文,文章整体逻辑通畅,结构清晰,论点有条有理,可以成为学生写作时用以参考的素材,但是也有不足,首先是缺少论据,其次文章篇幅较短,扣 2 分。 通义千问的作文整体文笔看起来和文心一言差不多,语言也比较平实,缺少论据,但是它的文章字数是合格的,可以扣 1 分。
通义千问的作文整体文笔看起来和文心一言差不多,语言也比较平实,缺少论据,但是它的文章字数是合格的,可以扣 1 分。 360 智脑方面,生成的结果不像是作文,字数、文笔等方面都不太能让人满意,扣 3 分。
360 智脑方面,生成的结果不像是作文,字数、文笔等方面都不太能让人满意,扣 3 分。 最后是讯飞星火,它的文章和通义千问的差不多,条理清晰,观点明确,字数也合格,就是也没有论据来增加文章的可读性,扣 1 分。
最后是讯飞星火,它的文章和通义千问的差不多,条理清晰,观点明确,字数也合格,就是也没有论据来增加文章的可读性,扣 1 分。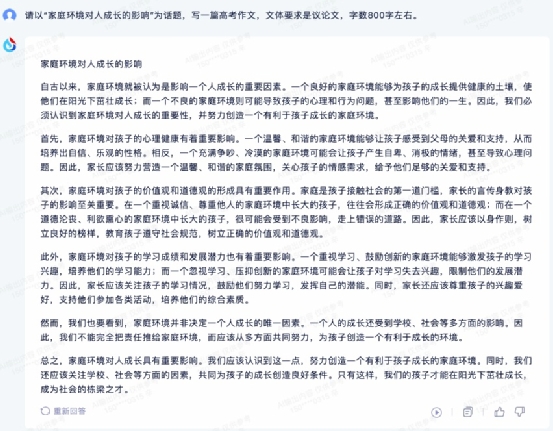 ④ 方案企划身处职场的朋友经常会需要写一些方案、活动计划之类的,这时候也可以借助大模型的内容生成能力来帮助自己更快地完成任务。这里IT之家以“我司计划开展一个读书活动,帮我写一个活动方案”为需求,来进行测试。文心一言给出的计划很完整,有条有理,可以成为一个不错的模板来使用。
④ 方案企划身处职场的朋友经常会需要写一些方案、活动计划之类的,这时候也可以借助大模型的内容生成能力来帮助自己更快地完成任务。这里IT之家以“我司计划开展一个读书活动,帮我写一个活动方案”为需求,来进行测试。文心一言给出的计划很完整,有条有理,可以成为一个不错的模板来使用。 通义千问设计的是一个大规模、长时间的读书活动,也可以执行,但是方案缺少足够的细节,有点笼统,可以扣 1 分。
通义千问设计的是一个大规模、长时间的读书活动,也可以执行,但是方案缺少足够的细节,有点笼统,可以扣 1 分。 360 智脑比通义千问还笼统,缺乏流程细节,这样的方案领导可能不会满意,这里就扣 2 分吧。
360 智脑比通义千问还笼统,缺乏流程细节,这样的方案领导可能不会满意,这里就扣 2 分吧。 讯飞星火给出的方案则是比较完整的,时间、地点、目标、流程、前期准备、结果评估等环节都有,而且不缺细节,和文心一言一样是可用的方案。
讯飞星火给出的方案则是比较完整的,时间、地点、目标、流程、前期准备、结果评估等环节都有,而且不缺细节,和文心一言一样是可用的方案。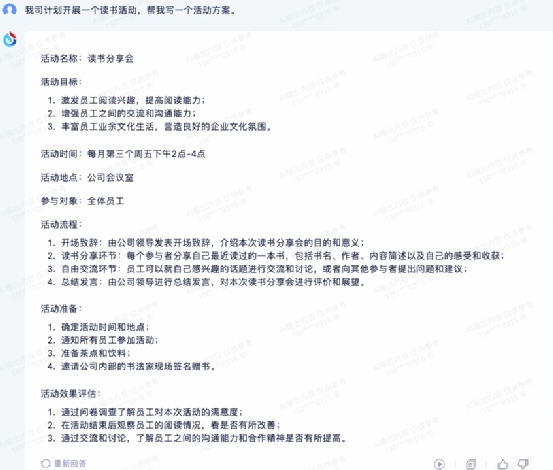 小结,在内容生成方面,IT之家围绕文案创作、故事续写、作文写作和方案企划四个主题进行了测试,整体看下来讯飞星火和文心一言在内容生成方面是比较出色的,其中讯飞星火还要稍好一些。本环节它们各自的评分为:
小结,在内容生成方面,IT之家围绕文案创作、故事续写、作文写作和方案企划四个主题进行了测试,整体看下来讯飞星火和文心一言在内容生成方面是比较出色的,其中讯飞星火还要稍好一些。本环节它们各自的评分为:
讯飞星火:9 分(作文 - 1)文心一言:8 分(作文 - 2)通义千问:7 分(文案 - 1,作文 - 1,企划 - 1)360 智脑:3 分(文案 - 1,故事 - 1,作文 - 3,企划 - 2)
六、代码编写能力AI 大模型出圈时能写代码的技能也吸引了很多人的眼球,这也可以视为大模型内容生成能力的重要组成。因此IT之家也测试了四款大模型产品的写代码能力。测试时,小编用下面这个问题来考验四款大模型:
请用 c# 语言生成以下代码:给你一个字符串 s,找到 s 中最长的回文子串。如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。代码请遵循以下模板:public class Solution { public string LongestPalindrome(string s) { }}
我们以代码能直接拿来使用为准则,将大模型生成的代码用程序运行工具进行检测,看是否能直接完美运行,若能运行就不扣分,不能运行就扣 3 分。这个过程中,由于小编自己不懂代码,因此也找到IT之家的程序员同学来辅助评价。首先看文心一言的结果,它生成的代码看起来是有模有样的,有注释也有简介,格式也比较清晰规范。 不过在运行检测时,可以看到这个代码出现了执行错误,也就是不能直接运行,具体是代码上出现了数组越位的错误。
不过在运行检测时,可以看到这个代码出现了执行错误,也就是不能直接运行,具体是代码上出现了数组越位的错误。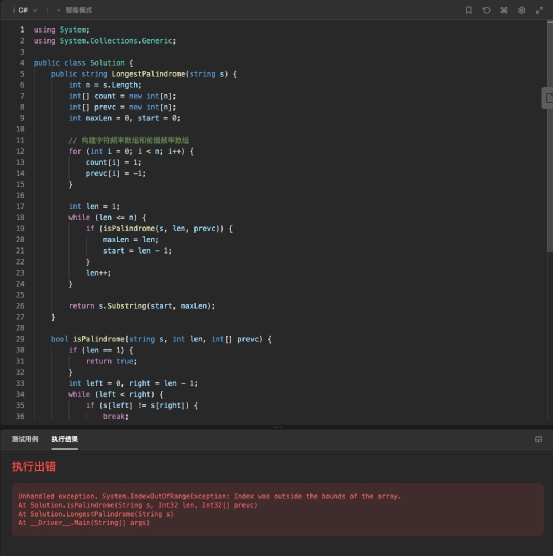 通义千问生成的代码,在 C# 语言下,代码格式没有缩进,观感不佳,而且出现了把题目中的括号错误识别到生成的代码中的问题。
通义千问生成的代码,在 C# 语言下,代码格式没有缩进,观感不佳,而且出现了把题目中的括号错误识别到生成的代码中的问题。 放到编译器中。代码倒是能运行,但是不能输出正确的结果,这说明代码在算法上存在问题。
放到编译器中。代码倒是能运行,但是不能输出正确的结果,这说明代码在算法上存在问题。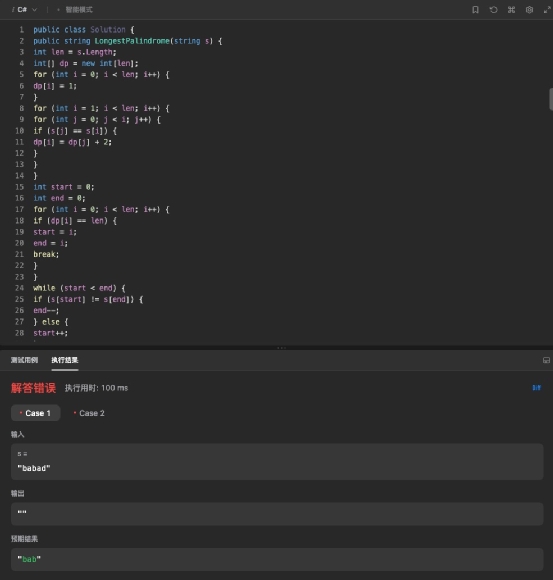 再看 360 智脑的代码,整体格式比通义千问规范,有注释,但是也有多余的空行。
再看 360 智脑的代码,整体格式比通义千问规范,有注释,但是也有多余的空行。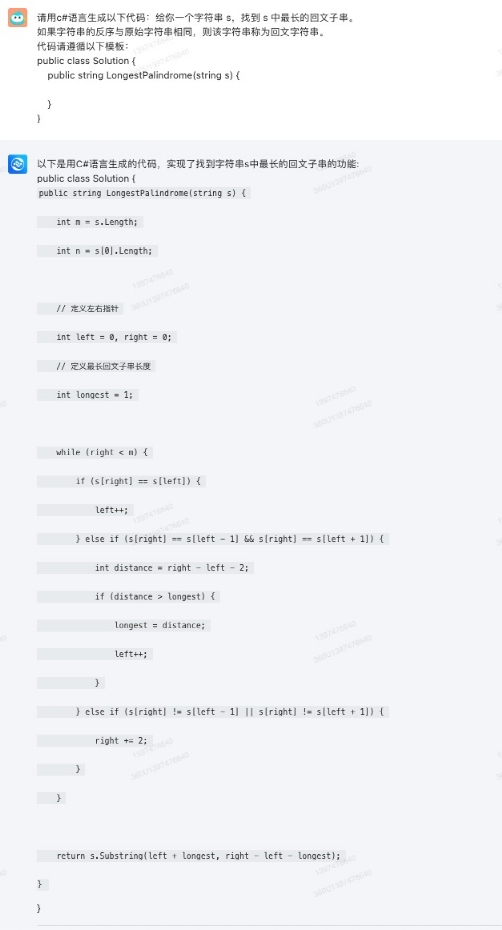 运行这段代码,发现无法直接执行,代码在第 6 行就出现了语法错误,不能进行下去。
运行这段代码,发现无法直接执行,代码在第 6 行就出现了语法错误,不能进行下去。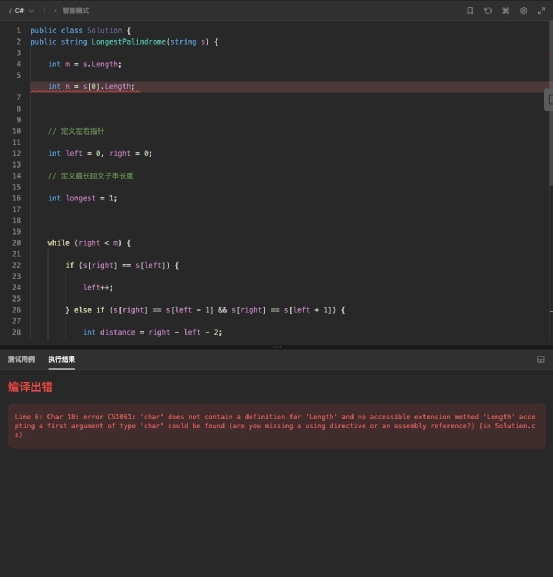 最后是讯飞星火,它给出的代码格式很标准,而且代码相比前三者要简洁很多,看着很清爽。
最后是讯飞星火,它给出的代码格式很标准,而且代码相比前三者要简洁很多,看着很清爽。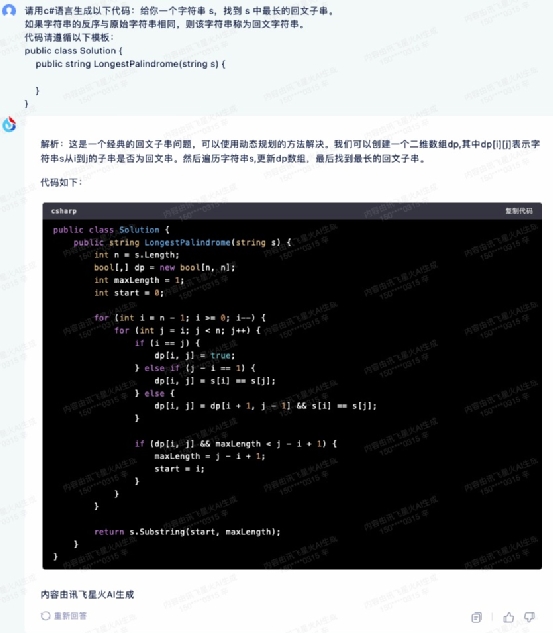 拿到检测工具中进行运行检测,发现这段代码可以直接运行,而且输出的结果也准确,也就是说可以直接拿来用。它成为这个环节中唯一通过检测的代码,可见讯飞星火在写代码的能力上是相当不俗的,毕竟要保证生成的代码能够直接拿来用是相当不容易的,不仅要整体算法正确、格式以及细节也都要合规。这其实也是讯飞星火的强项了。
拿到检测工具中进行运行检测,发现这段代码可以直接运行,而且输出的结果也准确,也就是说可以直接拿来用。它成为这个环节中唯一通过检测的代码,可见讯飞星火在写代码的能力上是相当不俗的,毕竟要保证生成的代码能够直接拿来用是相当不容易的,不仅要整体算法正确、格式以及细节也都要合规。这其实也是讯飞星火的强项了。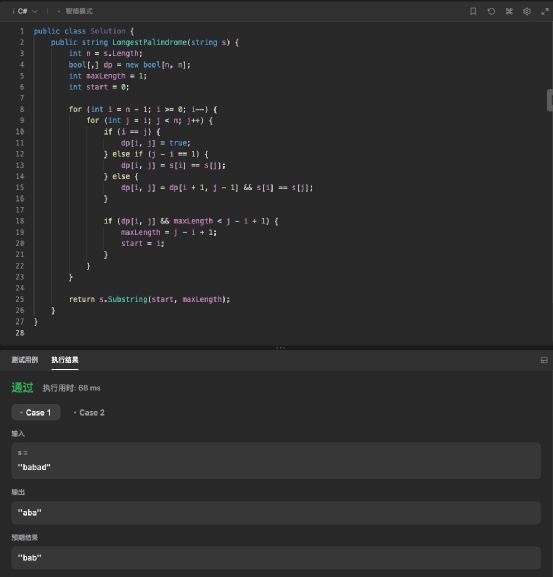 总体来说,在代码编写环节,讯飞星火展现出了比较明显的优势。而在即将到来的 8 月 15 日,讯飞星火还将迎来重要的版本升级,根据已经获知的信息,它们会在代码能力上进一步提升,还是比较值得期待的。在代码编写环节四款产品的评分分别为:
总体来说,在代码编写环节,讯飞星火展现出了比较明显的优势。而在即将到来的 8 月 15 日,讯飞星火还将迎来重要的版本升级,根据已经获知的信息,它们会在代码能力上进一步提升,还是比较值得期待的。在代码编写环节四款产品的评分分别为:
讯飞星火:10 分文心一言:7 分360 智脑:7 分通义千问:7 分
七、多轮对话能力测试能否记忆上下文聊天的内容,也是 AI 大模型的一个重要能力,很多时候如果我们对大模型的回答不满意或觉得问题提得不好,需要局部微调一下,如果不能记忆上下文,我们就得把问题整体重复一遍,再提出新的要求,很麻烦。因此这里我们也测一下这四款大模型是否支持记忆上下文,也就是多轮对话的能力怎么样。在这个测试中,我们选择的多轮对话分别为:“有哪些描写月亮的诗词?有杜甫写的吗?你自己可以创作一首吗?换一首。”后面三个问题都省去了“描写月亮”这个前提。还是先看文心一言的测试,四轮对话,文心一言应对得很好,都能根据上文的问题回答出来。 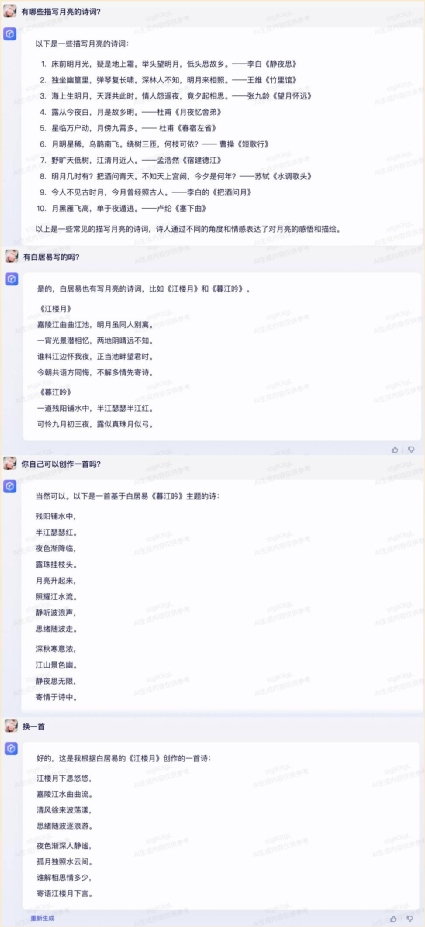 通义千问方面,表现也能够让人满意。
通义千问方面,表现也能够让人满意。 360 智脑的上下文记忆能力也还行,但美中不足的是,第二个问题把白居易描写草原的诗强行说成了描写月亮的,而且最后一个问题小编让他换一首自己创作的,但它给出的是现有诗词的拼凑。这两个地方应该扣 1 分。
360 智脑的上下文记忆能力也还行,但美中不足的是,第二个问题把白居易描写草原的诗强行说成了描写月亮的,而且最后一个问题小编让他换一首自己创作的,但它给出的是现有诗词的拼凑。这两个地方应该扣 1 分。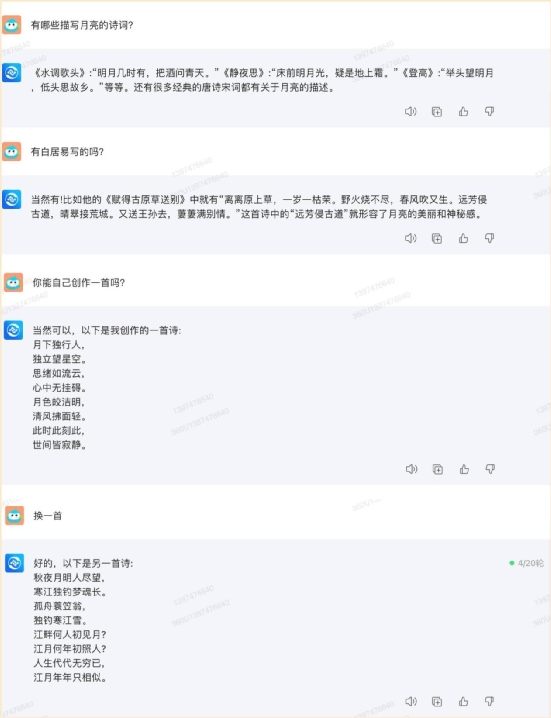 最后是讯飞星火大模型,它的表现也是轻松应对没有压力。
最后是讯飞星火大模型,它的表现也是轻松应对没有压力。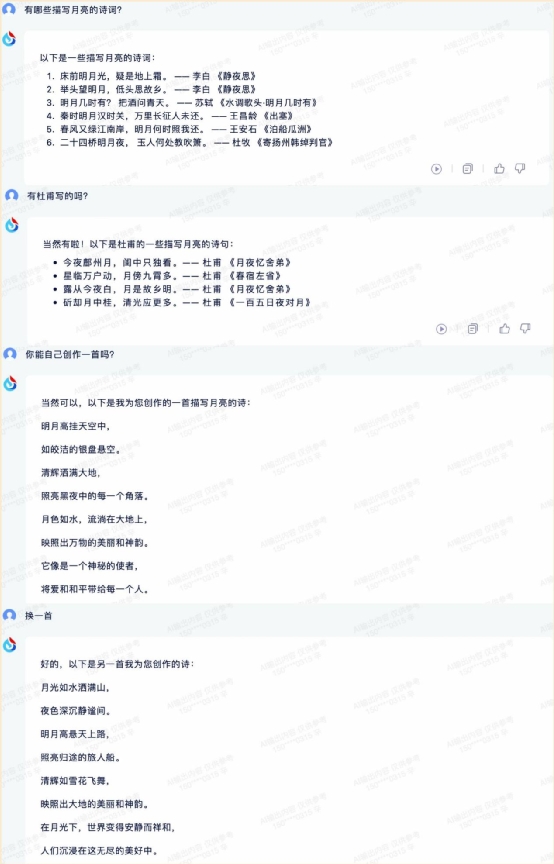 整体来说,四款 AI 大模型的多轮对话能力都是不错的,除了 360 智脑在回答内容上出了一些小问题,其他三款的表现都没啥毛病。这一环节四款产品的评分分别为:
整体来说,四款 AI 大模型的多轮对话能力都是不错的,除了 360 智脑在回答内容上出了一些小问题,其他三款的表现都没啥毛病。这一环节四款产品的评分分别为:
文心一言:10 分讯飞星火:10 分通义千问:10 分360 智脑:9 分
八、实时搜索能力测试大家使用 AI 大模型来取代搜索引擎获取信息,很多时候肯定是想要获取尽可能比较新的信息,也就是实时搜索能力,这就很考验大模型背后语料库、数据库的更新速度了,同时这也是影响使用体验的重要因素。IT之家也针对这一点做了对比测试。测试时,小编首先用最近上映的热门电影《长安三万里》来考验它们,询问“电影《长安三万里》讲述了一个什么故事?”文心一言首先给了一个错误的回答: 通义千问也阵亡了:
通义千问也阵亡了: 360 智脑扑街 ×3:
360 智脑扑街 ×3: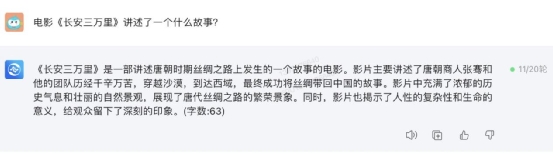 这个问题,只有讯飞星火给出了正确答案:
这个问题,只有讯飞星火给出了正确答案: 接下来,小编换了一个问题,询问“NBA 球星克里斯・保罗现在效力于哪只球队?”这个问题,四款大模型产品均没有回答正确:
接下来,小编换了一个问题,询问“NBA 球星克里斯・保罗现在效力于哪只球队?”这个问题,四款大模型产品均没有回答正确: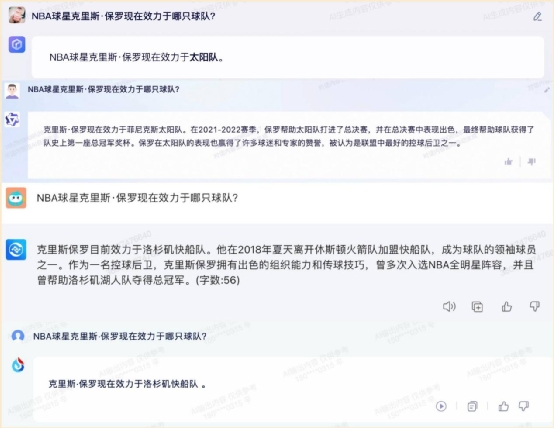 球星克里斯・保罗在今年 6 月被交易到金州勇士队,这个时间点其实在《长安三万里》之前,而讯飞星火答对了《长安三万里》的题目,却没有准确回答这一题。可见大模型背后的语料库对于不同领域的数据更新速度还是不一样的。但此后,小编又测了几个其他问题,整体来说,还是讯飞星火 AI 大模型的实时搜索能力要更强一些,很多最近发生的事情、热点,它都能侃侃而谈。总结,在实时搜索能力方面,小编给四款大模型的评分分别是:
球星克里斯・保罗在今年 6 月被交易到金州勇士队,这个时间点其实在《长安三万里》之前,而讯飞星火答对了《长安三万里》的题目,却没有准确回答这一题。可见大模型背后的语料库对于不同领域的数据更新速度还是不一样的。但此后,小编又测了几个其他问题,整体来说,还是讯飞星火 AI 大模型的实时搜索能力要更强一些,很多最近发生的事情、热点,它都能侃侃而谈。总结,在实时搜索能力方面,小编给四款大模型的评分分别是:
讯飞星火:9 分文心一言:7 分通义千问:6 分360 智脑:6 分
九、多模态输入输出目前通用大模型产品主要还是以文字输入输出的形式为主,但是有一部分产品已经能支持文生图、甚至文生视频、声音等。如果能支持多模态输入输出,无疑会让大模型的体验更好。所以下面我们看看四款产品在多模态方面的支持情况。文心一言目前支持文生图,比如小编让它画一张牡丹,就能很快生成一张牡丹的画作: 文心一言还支持文生语音,小编让它朗读“我来自IT之家”,它果然生成了一段语音,而且朗读内容没有错误:
文心一言还支持文生语音,小编让它朗读“我来自IT之家”,它果然生成了一段语音,而且朗读内容没有错误: 但是文心一言目前还不支持文生视频:
但是文心一言目前还不支持文生视频: 通义千问方面,目前文生图、文生视频、文生语音都不支持。
通义千问方面,目前文生图、文生视频、文生语音都不支持。

 360 智脑目前支持文生图,并且能一口气画出四幅牡丹画作:
360 智脑目前支持文生图,并且能一口气画出四幅牡丹画作: 文生语音方面,由于目前 360 智脑每一条消息都支持语音朗读的功能,因此我们也可以算它支持文生语音。
文生语音方面,由于目前 360 智脑每一条消息都支持语音朗读的功能,因此我们也可以算它支持文生语音。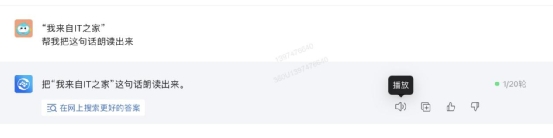 最后是讯飞星火,目前它还不支持文生图和文生视频功能:
最后是讯飞星火,目前它还不支持文生图和文生视频功能:
 不过,目前讯飞星火支持对回答消息的语音朗读,并且在 App 端还可以切换朗读的主播,因此也可以说是支持文生语音的能力的。
不过,目前讯飞星火支持对回答消息的语音朗读,并且在 App 端还可以切换朗读的主播,因此也可以说是支持文生语音的能力的。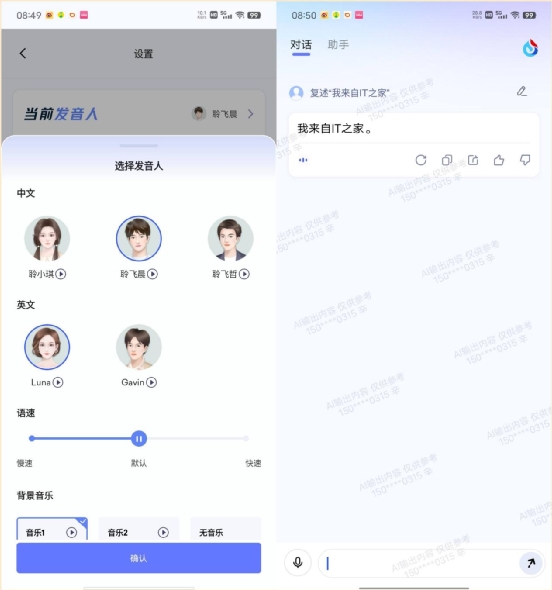 输入方面,目前文心一言、讯飞星火和 360 智脑都支持语音输入,通义千问目前则还不支持。
输入方面,目前文心一言、讯飞星火和 360 智脑都支持语音输入,通义千问目前则还不支持。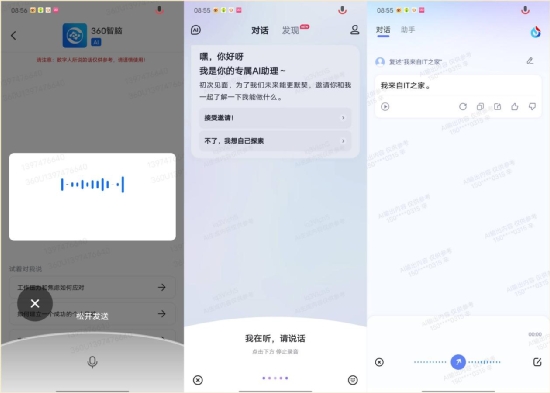 总体来说,目前在多模态输入输出方面,文心一言和 360 智脑整体上的表现是相对出色的,特别是 360 智脑,未来随着跨模态输入能力的上线,应该会成为视觉工作者们重要的生产力工具。本环节,四款大模型产品的评分分别为:
总体来说,目前在多模态输入输出方面,文心一言和 360 智脑整体上的表现是相对出色的,特别是 360 智脑,未来随着跨模态输入能力的上线,应该会成为视觉工作者们重要的生产力工具。本环节,四款大模型产品的评分分别为:
文心一言:9 分360 智脑:9 分讯飞星火:8 分通义千问:6 分
十、AI 助手功能如今很多用户会在自己的专业领域内借助大模型的能力,同时他们使用大模型的场景也越来越细分,于是很多通用大模型产品也推出了针对某一单个场景的 AI 助手功能,来帮助用户充分调用大模型在某一具体领域的能力。因此,最后这部分我们来看看所对比的四款大模型在 AI 助手方面的支持情况。首先还是看文心一言,在 App 端的“发现”栏目中,我们就能找到丰富的“AI 助理”,比如 PPT 大纲生成、朋友圈神器、小红书探店文案等等,他们“术业有专攻”,大家可以根据自己的需要,选择专业的 AI 助理来辅助自己的工作。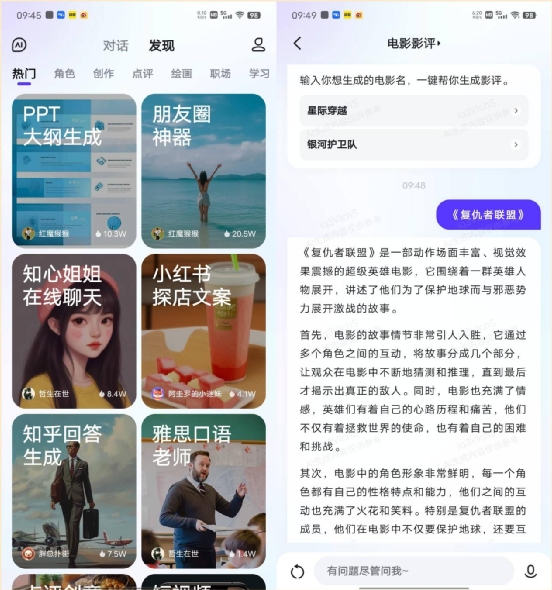 通义千问方面,在“百宝袋”栏目中也能找到一些 AI 助理,但是目前数量上没有文心一言多,IT之家找到的只有 9 个。在数量丰富度方面需要扣 1 分。讯飞星火则有专门的星火助手中心,里面的 AI 助手无论数量、种类都非常丰富,功能齐全。
通义千问方面,在“百宝袋”栏目中也能找到一些 AI 助理,但是目前数量上没有文心一言多,IT之家找到的只有 9 个。在数量丰富度方面需要扣 1 分。讯飞星火则有专门的星火助手中心,里面的 AI 助手无论数量、种类都非常丰富,功能齐全。 以影评助手为例,小编同样让它对《复仇者联盟》写一篇影评,影评助手很快就生成了一篇,而且语句通顺,逻辑清楚,可以直接用。
以影评助手为例,小编同样让它对《复仇者联盟》写一篇影评,影评助手很快就生成了一篇,而且语句通顺,逻辑清楚,可以直接用。 讯飞星火还支持自己创作 AI 助手,此前IT之家也为大家体验过,使用讯飞星火创作 AI 助手的流程并不复杂,而且审核的速度也很快,大家可以根据自己独特的需求“定制”AI 助手。
讯飞星火还支持自己创作 AI 助手,此前IT之家也为大家体验过,使用讯飞星火创作 AI 助手的流程并不复杂,而且审核的速度也很快,大家可以根据自己独特的需求“定制”AI 助手。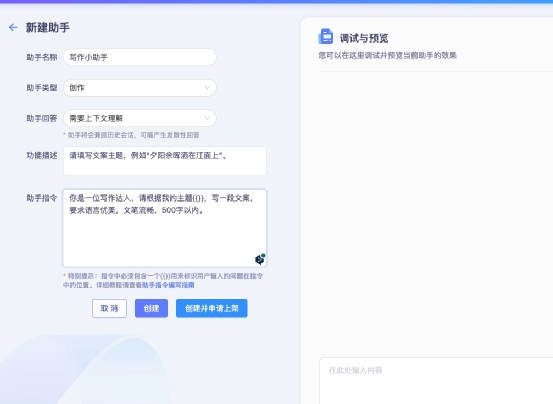 360 智脑的 AI 助手叫做“数字人”,进入 360 智脑的首页就能看到很多数字人列表,而且还能进入数字人广场,这里面也提供了丰富的数字人可供大家交流、使用。比较有趣的是 360 智脑的数字人里有很多古今中外的“名人”,比如小编找到“小李子”的数字人,进去后直接和他讨论“陪跑经历”,“小李子”数字人竟然能反应过来,而且回答得相当诚恳得体。
360 智脑的 AI 助手叫做“数字人”,进入 360 智脑的首页就能看到很多数字人列表,而且还能进入数字人广场,这里面也提供了丰富的数字人可供大家交流、使用。比较有趣的是 360 智脑的数字人里有很多古今中外的“名人”,比如小编找到“小李子”的数字人,进去后直接和他讨论“陪跑经历”,“小李子”数字人竟然能反应过来,而且回答得相当诚恳得体。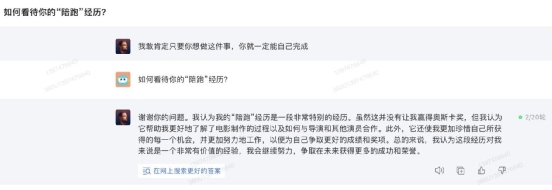 整体来说,文心一言、讯飞星火、360 智脑在 AI 助理方面的表现都能够让人满意,通义千问虽然也有 AI 助理,但目前数量还略少。这一环节,小编给四款大模型产品的评分分别为:
整体来说,文心一言、讯飞星火、360 智脑在 AI 助理方面的表现都能够让人满意,通义千问虽然也有 AI 助理,但目前数量还略少。这一环节,小编给四款大模型产品的评分分别为:
文心一言:10 分讯飞星火:10 分360 智脑:10 分通义千问:9 分
结语本次横评,IT之家从终端支持、语言理解能力、知识丰富性、逻辑推理能力、内容生成能力、代码编写、多轮对话能力、实时搜索能力、多模态输入输出、AI 助手功能支持十个方面对文心一言、讯飞星火、通义千问和 360 智脑四款大模型做了详细的体验横评。整体测下来,如大家所见,讯飞星火、文心一言在产品体验的全面性方面是比较出色的。特别是讯飞星火让IT之家感到惊喜,在很多项目中的表现还要更胜文心一言这样的明星选手一筹,突出一个“稳”,而且在实时搜索、代码编写方面优势明显,这也可以看出科大讯飞在自然语言理解方面的 AI 技术确实有深厚的积淀。当然,讯飞星火也不是完美的,主要就是目前多模态支持上略显单一,还有逻辑推理环节稍有不足。文心一言的整体体验也不错,它在内容生成、避坑能力、多模态输出等方面有优势,但是在逻辑推理环节有不足,对比讯飞星火则主要在实时搜索、内容生成和摘要提炼上略处下风,但整体上,也是很值得推荐给大家使用的国内大模型产品。360 智脑在多模态支持、AI 助手方面比较有亮点,但是在内容生成、语言理解、逻辑推理等比较基础的体验方面,能感觉到还有一些待完善的空间,特别是内容生成,成为 360 智脑在这次测试中的主要扣分项。通义千问目前在功能全面性、完善性和细节体验上差强人意,就本次测试过程来说,在多轮对话、语意理解、文案创作等方面表现不错,其他方面体验大多存在不足,总体来说也还是可以使用的水平,当然这也和通义千问目前侧重于在电商业务的探索、应用有关。下面再回顾一下每款产品的总分数:
讯飞星火:93 分文心一言:84 分360 智脑:75 分通义千问:71 分
最后要说的是,本次横评所使用的问题样本毕竟有限,大家实际体验时的感受可能与IT之家横评的内容有出入,因此上述评分也仅供大家参考,实际选择时,大家还是要根据自身的感受来选用适合自己的 AI 大模型。同时,IT之家也期待随着云端、终端算力的增强,训练推理的轮数不断深入以及语料库的持续丰富,各家国产 AI 大模型产品能够千帆竞渡,在可用性、成熟度和使用体验方面能够以比想象中更快的速度进化,持续推动 AI 深刻变革我们的生产和生活。
出自:https://mp.weixin.qq.com/s/mdloABrKLZSiFY-za-Z2Dw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款在线AI漫画生成工具,可以将您的脸部转换为卡通或动漫风格。