预训练对话大模型深度解读
发布时间:2024年06月06日
作者:轻口味
链接:https://juejin.cn/post/7239393450906058810
1、背景介绍
ChatGPT爆火,大模表现的“涌现”现象,证明了大模型的这条路行得通。生成式对话大模型在Turing测试中已逐渐接近人类水平,现在ChatGPT生成的结果难免让人误以为 AI 有意识了开始人格觉醒了,一顿惊慌。前段时间看到吴军博士的一个分享:”ChatGPT不算新技术革命,带不来什么新机会“,里面讲到一个道理,这些都是资本家操作出来割大家韭菜的。其实它只是一个数学模型,它强大的原因是:用到的计算量很大、数据量很大、训练语言模型的方法比以前好。那么在这之前都有哪些机构在研究呢?我们先大概了解下生成式对话模型的发展历史。
2、生成式对话模型发展历史
目前 AI 的发展已经历三个时代:
- 基于规则时代,1966 年计算机发展之初,MIT 的教授基于规则研发了用于心理治疗的 Eliza,有点像我们的”正则表达式“;
- 智能助手时代,资本一顿狂追,成果则良莠不齐,小度、小爱,有点傻傻的”智能“;
- 深度学习时代,典型的ChatGPT。
3、模型家族介绍
3.1 DialoGPT
由微软研发的,基于GPT架构,包含三个参数量版本:117M、345M、762M。它从Reddit上抽取147M对话数据。它的特点是交互信息最大化(MMI):
- 避免生成无意义、无信息量的内容
- 给定目标生成内容,计算生成输入的概率p(source/target)
- 使用该概率作为所有生成结果的rerank参考值。
3.2 Meena
由谷歌研发,基于编码器-解码器的模型结构,参数量2.6B,预训练数据341GB。由于人工评价方法缺乏标准体系,它提出人工智能评价体系SSA:合理性(Sensibleness)与具体性(Specificity)的平均值(Average),它的性能显著超越DialoGPT,逼近人类水平。
论文地址:ai.googleblog.com/2020/01/tow…
3.3 CDial-GPT
由清华CoAI小组研发,基于Decoder-Only架构,参数量104M,预训练数据包含了大规模高质量中文开放域对话数据集LCCC,包含Base和Large两个版本:
- Base: 对话数680万,数据来源于7900万微博数据
- Large:1200万,数据来源于7900万微博数据及650万开源对话数据
目前人工测评结果优于原始Transformer模型和中文GPT-2模型:
- 测试数据集:STC微博数据集
- 人工评价维度:流畅度、相关性、信息量
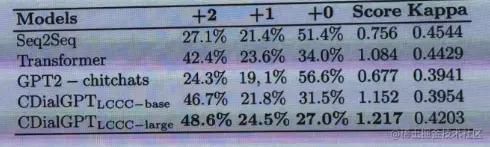
CDial-GPT获得了中文自然语言处理会议NLPCC 2020最佳学生论文奖,收到学术界和工业界的认可。
3.4 BlenderBot
由Meta AI研发,共包含3代版本:
-
第一代2020年
- 模型信息:Encoder-Decoder,参数量2.78B及9.4B
- 预训练数据:Reddit语料
- 微调数据:众包语料
- 主要能力:开放域闲聊+多技能融合,包含人格化、知识性、共情性等
-
第二代2021年
- 模型结构和第一代相同,沿用2.7B参数量的版本
- 新增能力:联网搜索+长时记忆(基于检索增强方法)
-
第三代(2022年)
- 改为采用Decoder-Only结构(基于30B和175B的OPT模型)
- 不再纯端到端生成,而是模块功能化+流水线执行(参数共享)
- 新增能力:完成开放域任务+终生学习
项目地址:blenderbot.ai/
3.5 EVA
由清华CoAI小组研发,共包含2代版本:
-
VEA1.0
- 28亿参数
- 在181G WDC-Dialogue上训练而成
- 开源首个十亿级别中文对话模型
-
EVA2.0
- 28亿参数
- 在精洗细洗的60G WDC-Dialogue上训练而成
- 详细探索了影响对话预训练效果的关键要素
- 目前规模大、效果最好的开源对话模型
- 开源多规模版本模型
目前EVA在所有自动指标,人工指标上显著超越其它开源的baseline模型。
3.6 PLATO
由百度研发,共包含4代版本
-
第一代PLATO(2019年)
-
基于UniLM,参数量110M
-
方法:
- 引入离散隐变量建模上下文和回复一对多的关系
- 使用角色嵌入向量区分对话中的角色
-
-
第三代PLATO-XL(2021年)
-
参数量11B
-
方法:
- 去掉隐变量
- 数据引入多方对话
-
性能
- 在连贯性、一致性、信息量、事实性、趣味性上取得优异表现
-
-
第四代PLATO-K(2022年)
-
旨在解决开放域对话系统中信息量缺乏和事实不准确的问题,规模22B
-
两阶段训练:
- 常规对话数据训练
- 首先生成query,基于该query搜索外部信息并加入上下文进行回复生成
-
各项评估解决均优于PLAT-XL
-
在知识性上有大幅提升
-
3.7 LaMDA
由Google研发,基于Decoder-Only架构,参数量137B,在2.81T的token上进行了预训练。使用众包数据进行微调,主要能力包含:合理、趣味、安全的开放域闲聊,引入Toolset(TS),包括计算器、翻译器和检索器。
LaMDA: our breakthrough conversation technology
3.8 OPD
由清华CoAI小组联合聆心智能研发,基于UniLM架构,在预训练阶段引入Soft Prompt,促进下游任务上做参数高效的微调,参数量6.3B,在70GB高质量对话数据进行预训练。
主要能力包括:
- 兼顾出色的闲聊能力和知识问答能力。得益于此,OPD的多轮交互能力突出,能够与用户进行多轮、深入的对话交互,性能显著优于EVA2.0,百度PLATO和华为PANGU-BOT
- 支持根据用户反馈实时修复模型生成结果中的问题,从而在交互中不断迭代优化模型。
3.9 ChatGPT
-
核心技术
-
指令学习:构造各种任务的指令数据并用于微调模型,使模型拥有强大的任务泛化能力。
-
基于人类反馈的强化学习(RLHF)
- 从人类反馈中学习
- 通过人来的偏好训练奖励模型,使用PPO算法优化策略模型(即生成模型)
- 将模型的输出结果对齐至人类偏好
-
-
突出特点:
-
遵循指令能力出色
- 多轮交互中能很好的遵从指令,例如对于之前指令的修改、补充
- 可以轻易的使用prompt让模型完成各种任务,例如角色对话,文字游戏
-
对话历史建模能力突出:在多轮交互中具有很强的长程记忆能力,能够完成很早轮次指令的修改
-
多语言能力强:支持各类主流语言,如英语、汉语、日语等,并且在英语之外的语言上没有明显的性能下降
-
回复信息性强:倾向于生成较长的回复,回复中包含很多相关信息(可能存在幻觉)
-
安全性好:ChatGPT的安全漏洞很少,并且还在持续优化
-
3.10 Character AI
是一家创业公司,不过创始人为Transformer和LaMDA的作者,估值超过10亿美元,是角色扮演类聊天机器人,主要功能包含:
- 与AI扮演的角色自由聊天
- 通过定义角色描述自由创建角色
- 通过声音、图片和橘色进行多模态交互
- 角色类型多样,包括人物、物品、工具、文字冒险游戏系统等。
突出优势体现为:
- 角色属性多样,泛化性强
- 用户反馈系统和用户社区建设完善
技术路线主要采用大模型+提示,并且外接了文生图模块。
产品地址:beta.character.ai/
4、总结
本文介绍了十款模型家族的模型,从中我们可以看到大模型确实不是新技术,但是ChatGPT做的更好,引入了反馈机制。整体而言整个大模型的发展模型架构都区域统一,参数规模持续增长。目前还有一些量化技术支持将大模型离线部署到手机、电脑等,除了受限于CPU算力,推理慢,生成结果效果已经很不错。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
百度搜索AI伙伴浏览器助手集成了AI对话和AI助手,可以帮你高效解答问题,辅助你进行内容理解,激发你的灵感和想象。