Stable Diffusion的模型分类以及使用
发布时间:2024年06月06日
在上一篇文章里我们列举了国内可以下载StableDiffusion模型的两个著名网站,那么小伙伴们下载下来模型之后,模型文件放到哪里呢?不同模型又是怎么用的呢?我们今天来讨论这个。
01
SD模型的管理建议
开始SD模型的分类及使用介绍之前,这里先给大家在模型管理方面一点点小的建议。
首先,SD模型存放的文件夹是可以添加子文件夹的,并且支持中文,因此你可以根据自己的需求将模型进行分类存放:
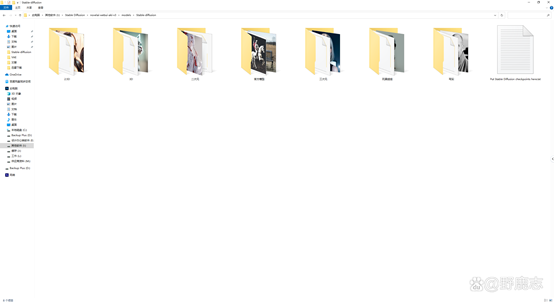
其次你在C站或者其他网站下载模型的时候,建议最好把该模型的效果图也下载一张下来,和对应的模型放在一起并且重命名为相同的名字:
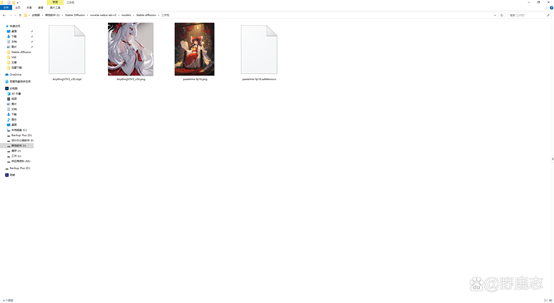
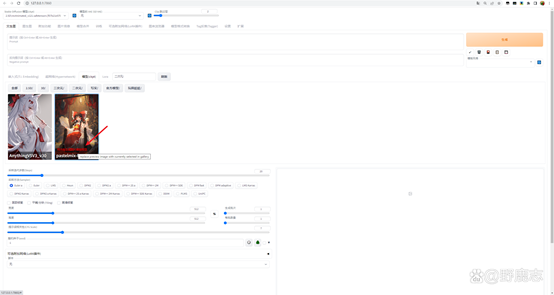
这样你在SD界面点击显示附加网络面板的红色按钮时,不仅可以看到该模型的效果图:
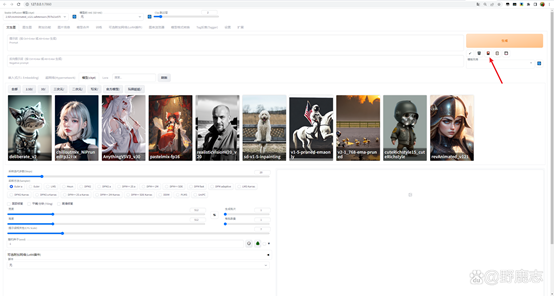
还可以根据你新建的子文件夹进行分类展示和选择:
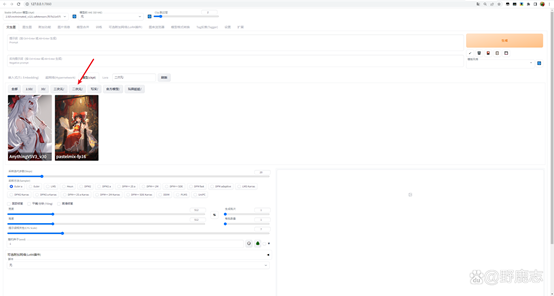
另外当你生成出一张你觉得不错的图片的时候,也可以鼠标停留在该模型名称的位置。
会弹出用当前生成图片替换预览的提示,点击这串提示就可以将你生成的图片替换为模型封面了:
如果你在其他网站上下载,不清楚模型的类型,可以到秋叶开发的spell.novelai.dev/这个网站:
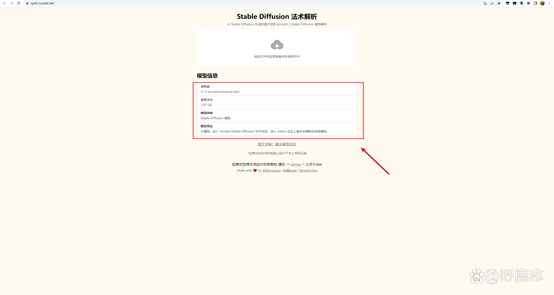
把你需要查询的模型拖进去,它就会告诉你模型的类型,不过有些模型它会分析不出来,对于新手来说够用了:
02
Checkpoint模型
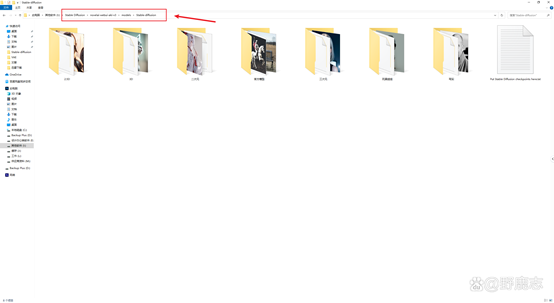
接下来说一说模型的分类,SD常用模型大致分为五种,第一种我们称为大模型或者主模型,主模型的存放路径为SD安装目录\models\Stable-diffusion:
大模型中首先有一类模型我们需要了解,那就是官方模型,例如我这里下载的有官方模型1.5版本和2.1版本:
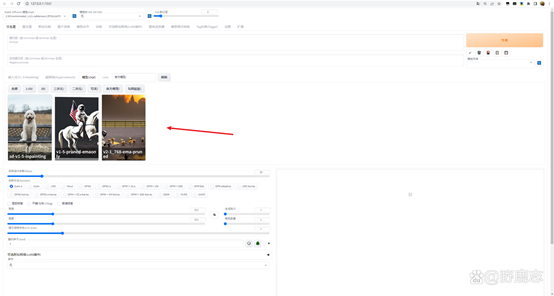
官方模型我们日常很少直接用它来生成图片,它更多被当做底模用于训练模型,C站上可以看到和选择基础模型的版本号:
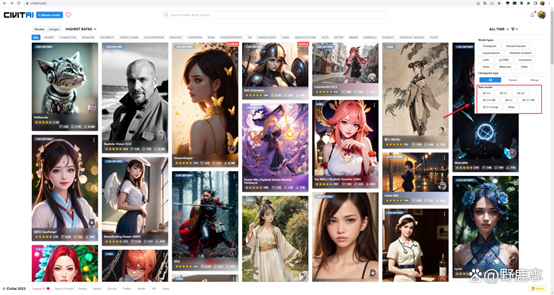
而我们最常用的其实是除了官方模型之外的主模型,叫做Checkpoint,你甚至可以简单理解几乎所有模型都是基于官方模型作为底模来进行训练得到的:
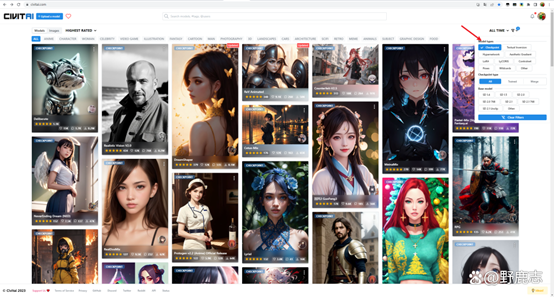
Checkpoint模型通常体积比较大,一般至少2个G,它可以直接用于生成图像,不需要搭配其他的文件:
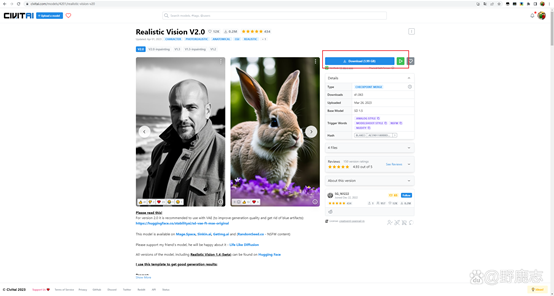
并且它们都有比较擅长生成的图像类型,例如这个Anything v3就是专门用来生成二次元的:
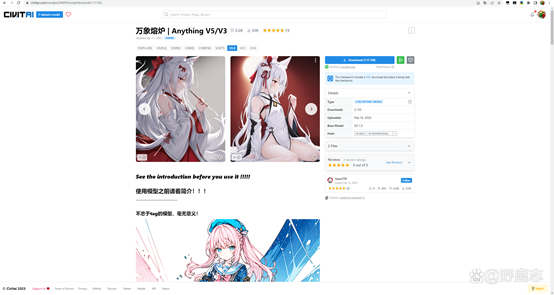
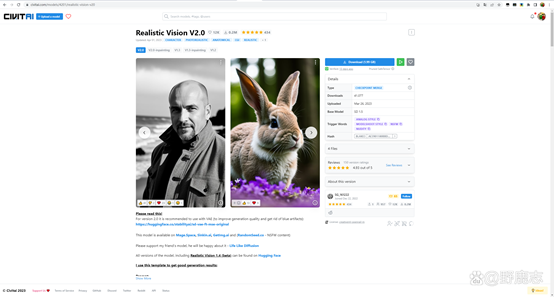
而这个Realistic Vision v2就比较偏向写实类别的:
03
VAE模型
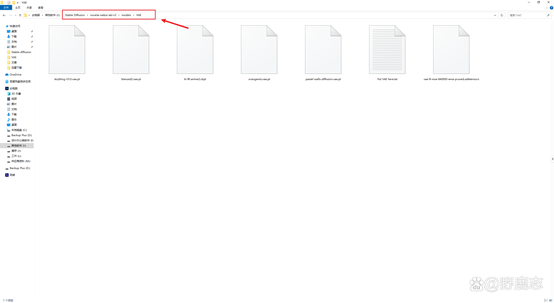
VAE模型的存放路径为SD安装目录\models\VAE:
说它是模型,但其实VAE更像是个滤镜,在生成图片过程中搭配着主模型使用,起到调色和微调的作用:
我们这里用Anything v3来简单示范一下VAE的作用吧,例如我这里的生成一只猫坐在地上的图像,并且没有加载VAE:
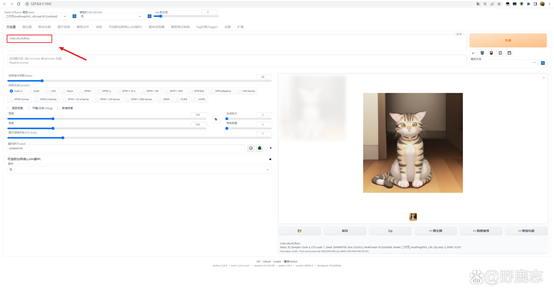
然后我在固定住随机种子的同时,加载这个叫做Anything v3的VAE,可以明显看到生成的图像色彩更鲜艳了:
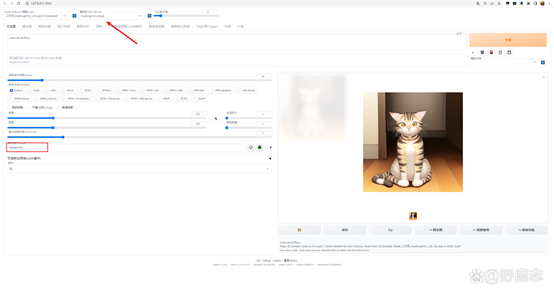
需要单独加载VAE的模型,在下载的时候都会有提示,并且VAE文件名称通常也是与它对应的主模型相同:
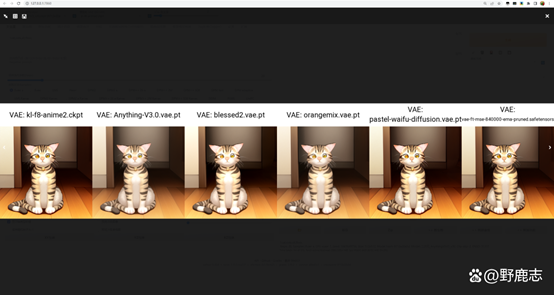
但其实你加载其他VAE也是可以的,效果上会有差异,我这里加载了其他的VAE生成了一个对比图大家可以看看:
另外现在大部分的主模型已经内置了VAE,一般来说不需要你单独下载。
如果模型里没有任何说明,那以生成图的效果为准,不必要的情况下就不用加载VAE了。
不过也有例外的,比如我下载了一个叫做ReV Animated的模型,它的说明里有推荐使用的VAE:
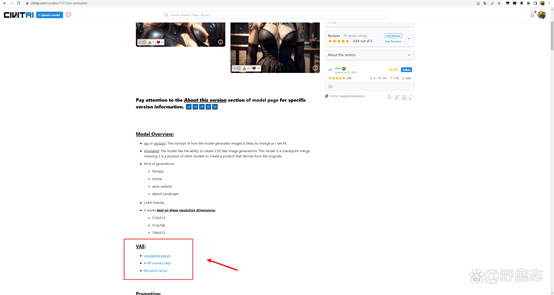
而当我仅仅使用这个主模型不加载VAE的时候,生成图时反而会出错:
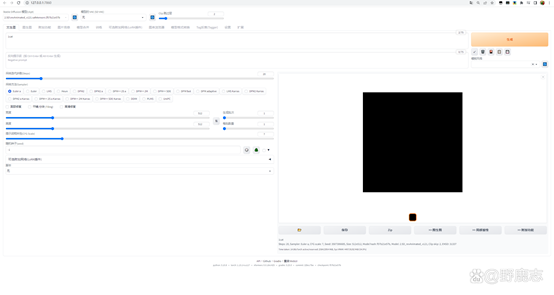
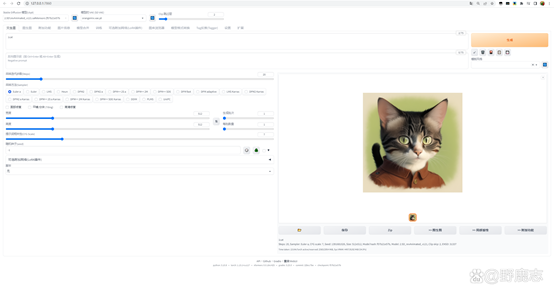
这个时候就需要你去加载作者推荐的VAE或者尝试用其他的VAE才行了:
04
Embedding模型
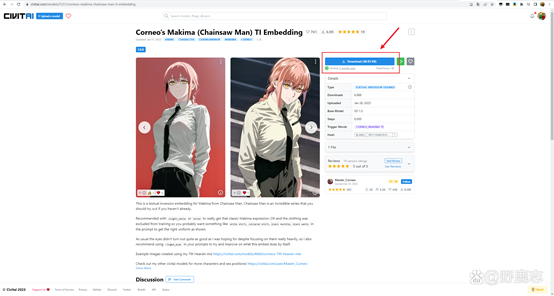
Embedding模型又叫Textual Inversion模型,需要和主模型一起搭配使用:
它的存放路径为SD安装目录\embeddings:

Embedding可以简单理解为提词打包模型,它可以生成指定角色的特征、风格或者画风。
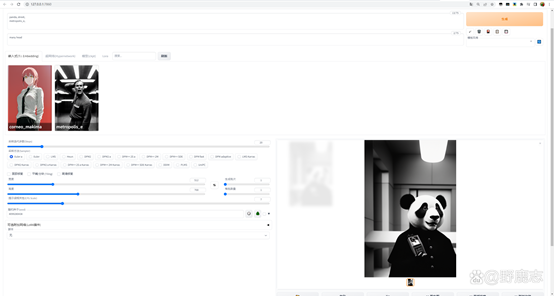
举个例子,我这里要生成电锯人中玛琪玛的形象,当我在提词框里输入makima,SD似乎不认识这个人,因此生成的图片和玛琪玛完全没有关系:
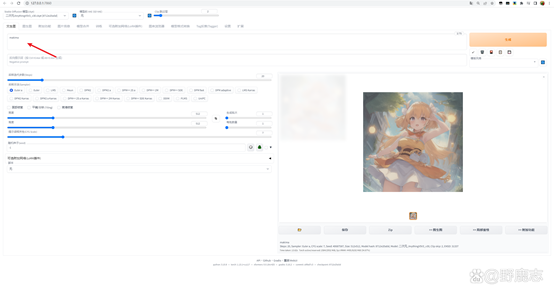
而当我们使用玛琪玛这个Embedding模型时,可以看到提词框内会添加一个模型的提词。
这个提词其实包含了很多用于描述玛琪玛的特征的提词内容,因此在没有其他额外提词的情况下,它就已经能够为我们生成带玛琪玛特征的图片了:
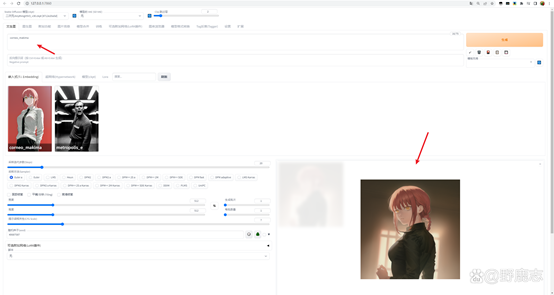
再比如我这里有一个复古科幻电影风格的Embedding模型,当我正常输入熊猫、街道等提词的时候,它是这样的:
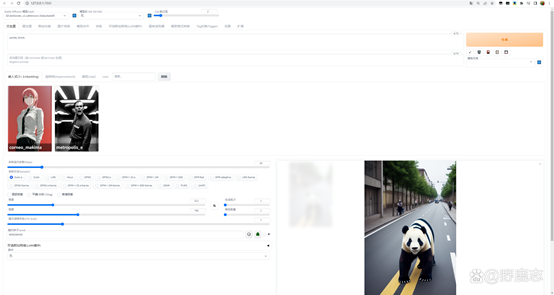
当我载入这个Embedding模型之后,画面的风格就变了,不过可能有时候会出错,例如这里头变多了:
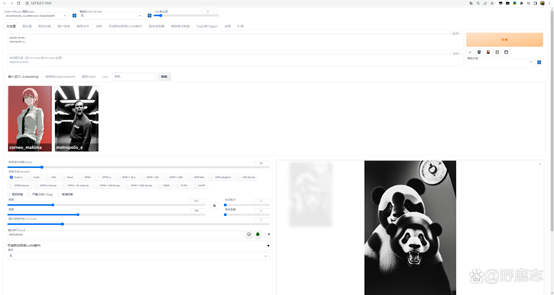
没关系,反向提词里我们输入many head,这样就好了:
由于Embedding模型本质是提词打包,所以这类模型的体积通常很小,这既是它的优点,也是它的缺点。
优点是节省空间资源,但由于体积小所携带的信息少,因此在画面、风格的还原度上可能差强人意,所以现在使用这种模型的也越来越少了:
05
Hypernetwork模型
Hypernetwork模型同样需要搭配主模型一起使用,它最常用于画风、效果的转换,但同样也可以用于生成指定的角色:
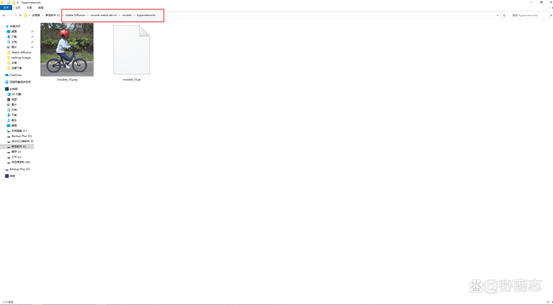
它的存放路径为SD安装目录\models\hypernetworks:
例如我这里同样生成一个男人的图像:
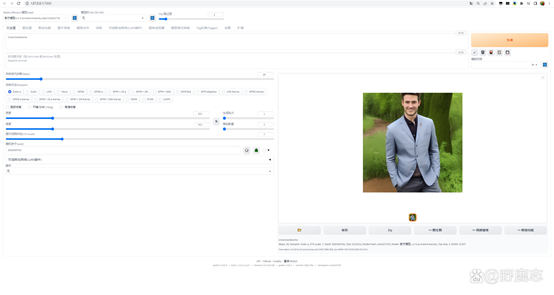
然后我固定住了随机种子,载入这个带有透明人特效的Hypernetwork模型,可以看到提词框里多了一些内容:<hypernet:invisble_10:1>
Hypernet代表模型的类型,invisble_10代表模型的名称,冒号后面的1代表着这个模型的使用权重,直接点击生成就能得到一个透明人的效果了:
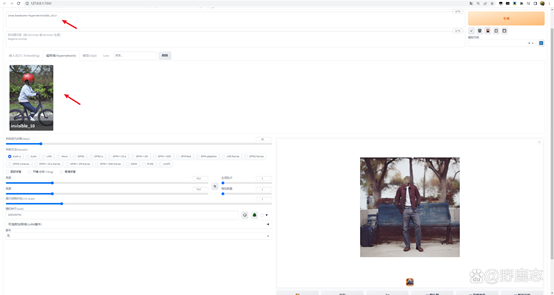
Hypernetwork模型相比于Embedding体积要大一些,在一些比较精细的效果上不是特别出众,所以现在在使用度上也越来越少了:
06
Lora模型
最后就是最近最火的Lora模型了,它最大的特点就是几乎图像上的信息它都可以训练,并且还原度非常高。
现在网络上流行的很多Ai真人绘图基本都是用的这类模型,甚至你可能会看到很多画出来的网红形象都很像,这是由于他们用的是同一款Lora:
这里额外提示一句,大家在使用Lora的过程中一定要有版权和法律意识,否则你可能会给自己带来麻烦,具体详见秋叶整合包中的用户协议:
它的存放路径为SD安装目录\models\Lora:
Lora模型同样需要搭配主模型来使用,并且由于Lora训练的时候是基于大模型训练的,因此使用Lora配套的大模型通常效果会更好。
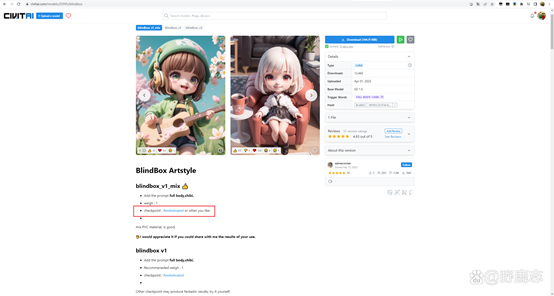
例如我很喜欢这个盲盒风格的Lora,在它的介绍页面通常作者会写是基于什么模型训练的:
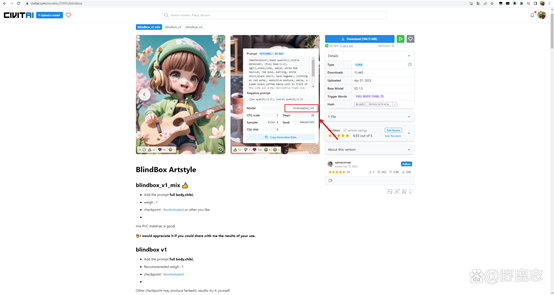
如果介绍页面没有写,也可以通过作者生成的图以及评论区点击图片右下角的符号看到是用的什么模型:
然后可以直接搜索把这个主模型也下载下来:
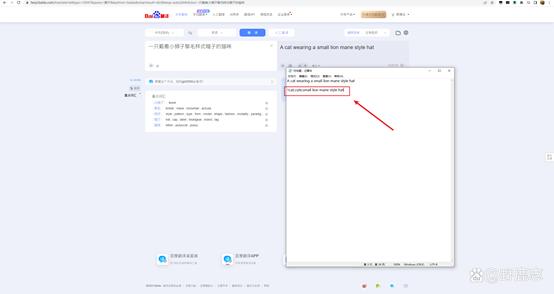
我们来尝试使用一下这个Lora吧,例如我这里先用百度翻译了一下一只可爱的猫咪戴着小狮子鬃毛样式的帽子,提取到的关键词是1cat,cute,hat in the style of a little
lion's mane:
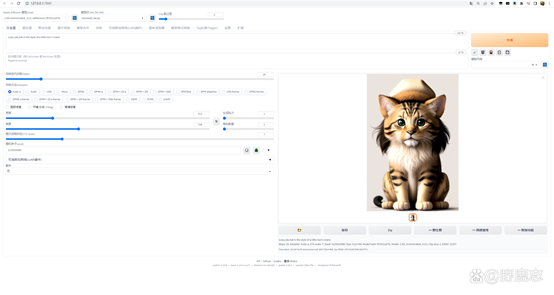
先生成一下图找一个感觉不错的随机种子固定住,然后再进一步调整:
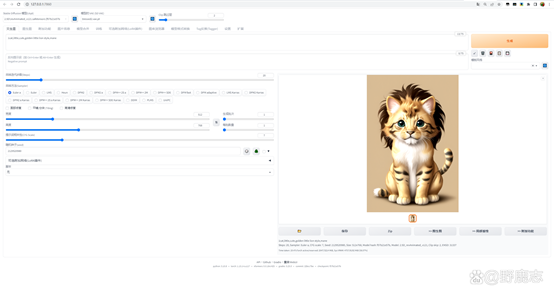
现在生成的图我想把帽子去掉,但是保留小狮子鬃毛的那种感觉,所以我把hat in the style of a little lion's mane拆分成了little
lion style,mane。
并且在小狮子前面加了一个golden金色的形容词,在猫咪后面加了一个little的提词:
先这样吧,这个时候我们直接载入这个Lora模型,盲盒玩偶的感觉就出来了:
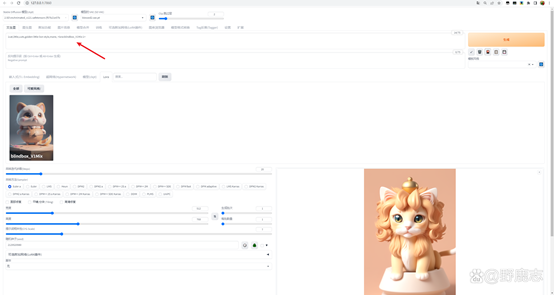
让我们在此基础上进一步调整一下图像吧,这里我们先把秋叶安装包里的起手式填写进去,这些提词基本就是对画质的描述,比较通用:
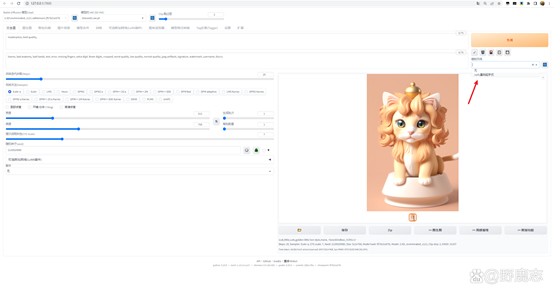
然后再把我们之前的提词填写进去生成看看效果:
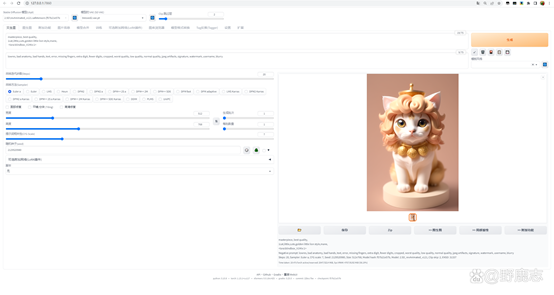
接着提词中我额外加了open mouth,flower,outdoors,grass,等内容:
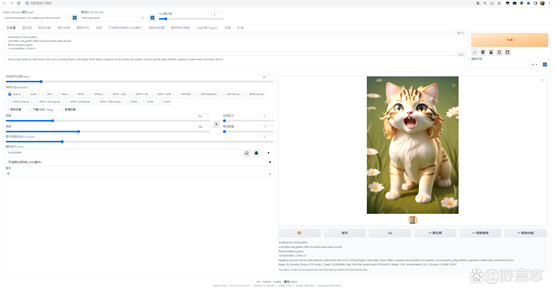
然后我觉得现在小狮子鬃毛的感觉又有点少了,所以用小括号括起来加冒号跟数值的方式提高鬃毛的权重,并且提高了一点点采样步数:
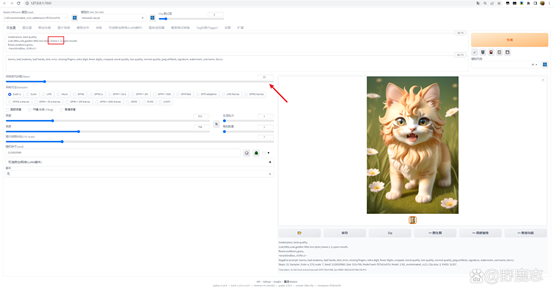
最后PS里简单调色加点文字看看效果吧:

我觉得还挺可爱的,没想到就分享了一下SD的五种模型就写了这么多内容。
不知道大家有没有晕,最后再用一个不太准确的例子类比一下这几种模型的关系:
官方主模型:安卓原生系统
Checkpoint模型:基于安卓原生系统开发的其他安卓系统,例如小米的Miui,魅族的Flyme。
VAE模型:手机设置中调整显示的亮度、对比度以及色彩模式的功能。
至于Embedding、Hypernetwork和Lora这三种模型,都是用来微调主模型的小模型。
可以简单理解为主题市场中的各种主题,有的主题效果好点,有的主题效果差点,有的主题体积小点,有的主题体积大点。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
基于Kimi Chat模型技术,让你进入到不同场景之中,用语言技巧和沟通能力去哄你的对象。