大语言模型综述<演进,技术路线,区别,微调,实践,潜在问题与讨论>
发布时间:2024年06月06日
| 模型 | 训练数据 | 训练数据量 | 模型参数量 | 词表大小 |
|---|---|---|---|---|
| LLaMA | 以英语为主的拉丁语系,不包含中日韩文 | 1T/1.4T tokens | 7B、13B、33B、65B | 32000 |
| ChatGLM-6B | 中英双语,中英文比例为1:1 | 1T tokens | 6B | 130528 |
| Bloom | 46种自然语言和13种编程语言,包含中文 | 350B tokens | 560M、1.1B、1.7B、3B、7.1B、176B | 250880 |
| 模型 | 模型结构 | 位置编码 | 激活函数 | layer norm |
|---|---|---|---|---|
| LLaMA | Casual decoder | RoPE | SwiGLU | Pre RMS Norm |
| ChatGLM-6B | Prefix decoder | RoPE | GeGLU | Post Deep Norm |
| Bloom | Casual decoder | ALiBi | GeLU | Pre Layer Norm |
LLama
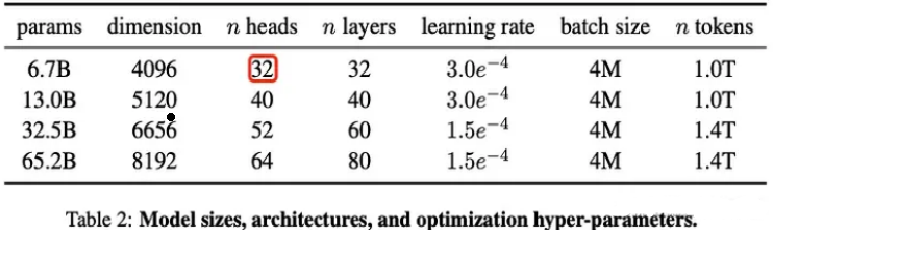
LLaMA[2]是Meta提出的大语言模型。训练数据是以英语为主的拉丁语系,另外还包含了来自GitHub的代码数据。训练数据以英文为主,不包含中韩日文,所有训练数据都是开源的,分词之后大约有1400B的tokens。
按照模型参数量,LLaMA模型有7B、13B、33B、65B这四个不同参数规模的模型版本。7B和13B版本使用了1T的tokens进行训练,33B和65B的版本使用了1.4T的tokens进行训练。[3]证明了在给定训练预算的情况下,即使减少模型参数量,只要增加预训练的数据大小和训练时长(更多的训练tokens数),可以达到甚至超过原始大小模型的效果。作为对比,280B的Gopher模型只训练了300B的tokens,176B的BLOOM模型只训练了350B的tokens,GLM-130B只训练了400B的tokens,LLaMA模型则训练了1T/1.4T的tokens,显著增大了训练数据量。从结果来看,虽然LLaMA-13B模型参数量只有GPT3的不到1/10,但在大部分任务上效果都超过了GPT3。
模型结构上,与GPT相同,LLaMA采用了causal decoder-only的transformer模型结构。在模型细节上,做了以下几点改动:
- Pre-layer-normalization [参考GPT3]. 为了提高训练稳定性,LLaMA 对每个 transformer 子层的输入进行归一化,使用
RMSNorm(即只有均方根,没有均值u)归一化函数,Pre-normalization 由Zhang和Sennrich(2019)引入。 SwiGLU激活函数 [参考PaLM]. 没有采用ReLU激活函数,而是采用了SwiGLU激活函数。FFN通常有两个权重矩阵,先将向量从维度d升维到中间维度4d,再从4d降维到d。而使用SwiGLU激活函数的FFN增加了一个权重矩阵,共有三个权重矩阵,为了保持参数量一致,中间维度采用了\frac{2}{3}\cdot d ,而不是4d.- 位置编码:
Rotary Embeddings[参考GPTNeo]. 模型的输入不再使用positional embeddings,而是在网络的每一层添加了 positional embeddings (RoPE),RoPE 方法由Su等人(2021)引入。 - 使用了AdamW优化器,并使用cosine learning rate schedule,
- 使用因果多头注意的有效实现来减少内存使用和运行时间。该实现可在xformers找到
下面是一些基于LLaMA衍生出来的大模型:
- Alpaca:斯坦福大学在52k条英文指令遵循数据集上微调了7B规模的LLaMA。
- Vicuna:加州大学伯克利分校在ShareGPT收集的用户共享对话数据上,微调了13B规模的LLaMA。
- baize:在100k条ChatGPT产生的数据上,对LLaMA通过LoRA微调得到的模型。
- StableLM:Stability AI在LLaMA基础上微调得到的模型。
- BELLE:链家仅使用由ChatGPT生产的数据,对LLaMA进行了指令微调,并针对中文进行了优化。
词表扩展:Chinese LLaMa
词表扩充的必要性。 LLaMA原模型的词表大小是32000,tokenizer主要是在英文语料上进行训练的,在中文上和多语种上效果比较差。LLaMA在中文上效果差,一方面是由于LLaMA模型是在以英文为主的拉丁语系语料上进行训练的,训练语料不包含中文;另一方面,与tokenizer有关,词表规模小,可能将一个汉字切分为多个token,编码效率低,模型学习难度大。LLaMA词表中只包含了很少的中文字符,在对中文文本进行分词时,会将中文切分地更碎,需要多个token才能表示一个汉字,编码效率很低。扩展中文词表后,单个汉字倾向于被切分为1个token,避免了一个汉字被切分为多个token的问题,提升了中文编码效率。
如何扩展词表呢?[6]尝试扩展词表,将中文token添加到词表中,提升中文编码效率,具体方式如下。
- 在中文语料上使用Sentence Piece训练一个中文tokenizer,使用了20000个中文词汇。然后将中文tokenizer与原始的 LLaMA tokenizer合并起来,通过组合二者的词汇表,最终获得一个合并的tokenizer,称为Chinese LLaMA tokenizer。词表大小为49953。
- 为了适应新的tokenizer,将transformer模型的embedding矩阵从 V*h 扩展到 V'*h ,新加入的中文token附加到原始embedding矩阵的末尾,确保原始词表表的embedding矩阵不受影响。(这里输出层应该也是要调整的)
- 在中文语料上进一步预训练,冻结和固定transformer的模型参数,只训练embedding矩阵,学习新加入中文token的词向量表示,同时最小化对原模型的干扰。
- 在指令微调阶段,可以放开全部模型参数进行训练。
SwiGLU介绍
Swish激活函数f
"="">
贝塔是常数或者可训练参数,
Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数.

GELU激活函数
GELU(高斯误差线性单元)是一个非初等函数形式的激活函数,是RELU的变种。由16年论文 Gaussian Error Linear Units (GELUs) 提出,随后被GPT-2、BERT、RoBERTa、ALBERT 等NLP模型所采用。论文中不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式。函数曲线如下:
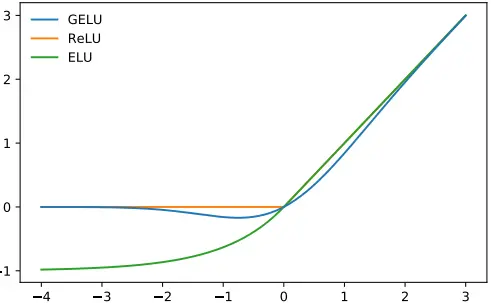
RELU及其变种与Dropout从两个独立的方面来决定网络的输出,有没有什么比较中庸的方法把两者合二为一呢?在网络正则化方面,Dropout将神经单元输出随机置0(乘0),Zoneout将RNN的单元随机跳过(乘1)。两者均是将输出乘上了服从伯努利分布的随机变量m ~ Bernoulli(p),其中p是指定的确定的参数,表示取1的概率。
然而激活函数由于在训练和测试时使用方式完全相同,所以是需要有确定性的输出,不能直接对输入x乘随机变量m,这点与Dropout不同(Dropout在测试时并不随机置0)。由于概率分布的数学期望是确定值,因此可以改为求输出的期望:E[mx]=xE[m],即对输入乘上伯努利分布的期望值p=E[m]。
论文中希望p能够随着输入x的不同而不同,在x较小时以较大概率将其置0。 由于神经元的输入通常服从正态分布,尤其是在加入了Batch Normalization的网络中,因此令p等于正态分布的累积分布函数即可满足
正态分布的累积分布函数曲线与sigmoid曲线相似。
GELU:
"="">
其中 "="">
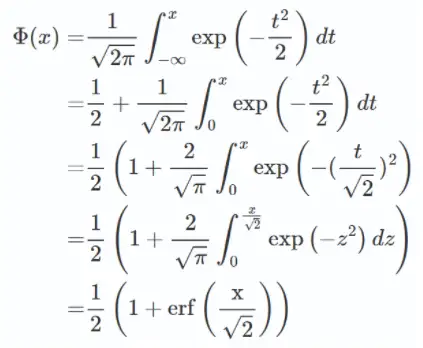
在数学中,误差函数(也称之为高斯误差函数)定义如下
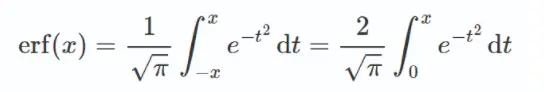
erf(x) 与 tanh(x) 比较接近
在代码实现中可以用近似函数来拟合erf(x)。论文给出的两个近似如下:

"="">
不过很多框架已经有精确的erf计算函数了,可以直接使用,参考代码如下:
# BERT、GPT-2 的旧式 GELU 实现
def gelu(x):
return x * 0.5 * (1 + tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x,3))))
# 使用erf函数的 GELU 实现
def gelu(x):
cdf = 0.5 * (1.0 + tf.erf(x / tf.sqrt(2.0)))
return x * cdfGELU vs Swish
GELU 与 Swish 激活函数(x · σ(βx))的函数形式和性质非常相像,一个是固定系数 1.702,另一个是可变系数 β(可以是可训练的参数,也可以是通过搜索来确定的常数),两者的实际应用表现也相差不大。
GLU(Gated Linear Unit)
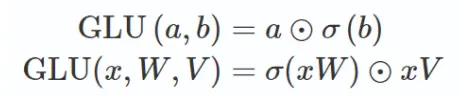
圆圈代表哈达玛积,按位乘
在公式中,首先通过中间向量g(x)=xW进行门控操作,使用Sigmoid函数σ将其映射到0到1之间的范围,表示每个元素被保留的概率。然后,将输入向量x与门控后的向量进行逐元素相乘(即 ⊗ 操作),得到最终的输出向量。
GLU通过门控机制对输出进行把控,像Attention一样可看作是对重要特征的选择。其优势是不仅具有通用激活函数的非线性,而且反向传播梯度时具有线性通道,类似ResNet残差网络中的加和操作传递梯度,能够缓解梯度消失问题。
为什么?对比下sigmoid 及 LSTM中使用的 gated tanh unit (GTU) 的梯度:
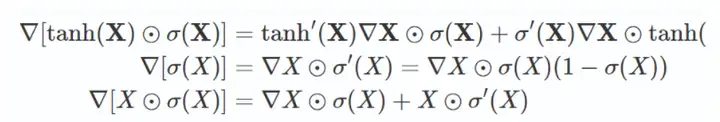

GEGL
是GLU的激活函数变体
将GLU中的sigmoid替换为GELU,函数形式如下(忽略bias项的书写):
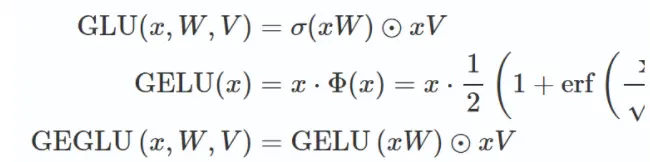
GLU包含W和V两个可学习的参数
GEGLU也包含W和V两个可学习的参数,用GELU替换SIGMOD
SwiGLU
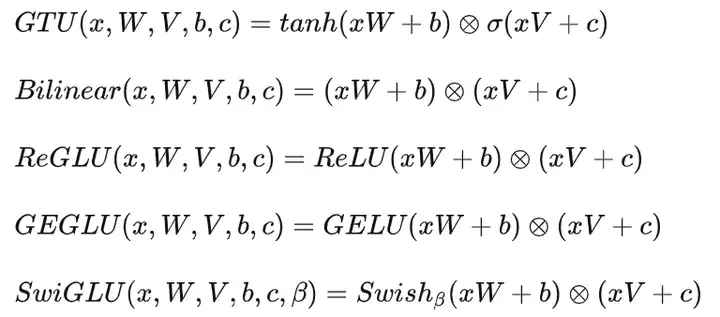
在PaLM论文中使用了SwiGLU激活函数。
在FFN中,即FC->激活函数->FC中,一般定义如下:
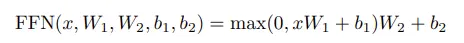
在T5论文中没有使用偏置项,也就是:
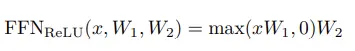
同理可得:

结合激活函数+未使用偏置项+GLU就得到:
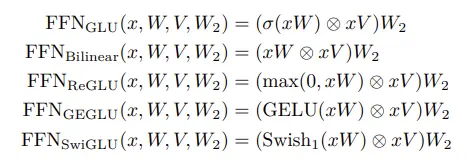
这就是PaLM中的激活函数了,效果也是不错的:
PALM
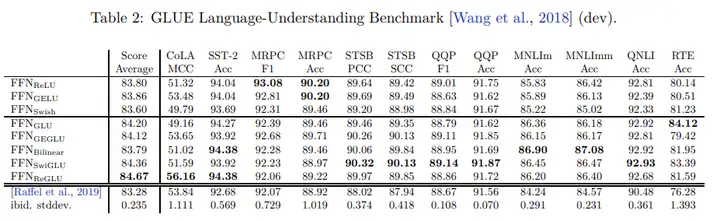
- 采用SwiGLU激活函数:用于 MLP 中间激活,采用SwiGLU激活函数:用于 MLP 中间激活,因为与标准 ReLU、GELU 或 Swish 激活相比,《GLU Variants Improve Transformer》论文里提到:SwiGLU 已被证明可以显著提高模型效果
- 提出Parallel Layers:每个 Transformer 结构中的“并行”公式:与 GPT-J-6B 中一样,使用的是标准“序列化”公式。并行公式使大规模训练速度提高了大约 15%。消融实验显示在 8B 参数量下模型效果下降很小,但在 62B 参数量下没有模型效果下降的现象。
- Multi-Query Attention:每个头共享键/值的映射,即“key”和“value”被投影到 [1, h],但“query”仍被投影到形状 [k, h],这种操作对模型质量和训练速度没有影响,但在自回归解码时间上有效节省了成本。
- 使用RoPE embeddings:使用的不是绝对或相对位置嵌入,而是RoPE,是因为 RoPE 嵌入在长文本上具有更好的性能 ,
- 采用Shared Input-Output Embeddings:输入和输出embedding矩阵是共享的,这个我理解类似于word2vec的输入W和输出W'
ChatGLM-6B
ChatGLM-6B是清华大学提出的支持中英双语问答的对话语言模型。ChatGLM-6B采用了与GLM-130B[4]相同的模型结构。截止到2022年7月,GLM-130B只训练了400B的tokens,中英文比例为1:1。ChatGLM-6B则使用了更多的训练数据,多达1T的tokens,训练语料只包含中文和英文,中英文比例为1:1。
模型结构上,ChatGLM-6B采用了prefix decoder-only的transformer模型框架,在输入上采用双向的注意力机制,在输出上采用单向注意力机制。在模型细节上,做了以下几点改动:
- embedding层梯度缩减: 为了提升训练稳定性,减小了Embedding层的梯度。具体
"="">word\_embedding = word\_embedding ∗ α + word\_embedding . d e t a c h ( ) ∗ ( 1 − α ) " role="presentation" style="display: inline-block; font-style: normal; font-weight: normal; line-height: normal; font-size: 16px; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">word\_embedding 其中,alpha为0.1,这里detach的作用是返回一个新的tensor,并从计算图中分离出来(不计入梯度)。梯度缩减的效果相当于把Embedding层的梯度缩小了10倍 - Layer Normalization的顺序和残差连接被重新排列,用POST Normal,用Deep Normal
"="">( d e e p N o r m = L a y e r N o r m ( x ∗ α + f ( x ) ) )
,f(x)代表attention和FFN,相当于先做残差,再做标准化。
初始化对FFN,V_p,O_p用Xavier(w,gain=\beta)
对Q_p,k_p用Xavier(w,gain=1)- 用于输出标记预测的单个线性层;
- 用GEGLU作激活函数: 相比于普通的FFN,使用线性门控单元的GLU新增了一个权重矩阵,共有三个权重矩阵,为了保持参数量一致,中间维度采用了 "="">
8 3 d " role="presentation" style="display: inline-block; font-style: normal; font-weight: normal; line-height: normal; font-size: 16px; text-indent: 0px; text-align: left; text-transform: none; letter-spacing: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;"> 而非4d. - 位置编码:去除了绝对位置编码,采用旋转位置编码RoPE
- 训练目标:ChatGLM-6B的训练任务是自回归文本填空。相比于采用causal decoder-only结构的大语言模型,采用prefix decoder-only结构的ChatGLM-6B存在一个劣势:训练效率低。causal decoder结构会在所有的token上计算损失,而prefix decoder只会在输出上计算损失,而不计算输入上的损失。在有相同数量的训练tokens的情况下,prefix decoder要比causal decoder的效果差,因为训练过程中实际用到的tokens数量要更少。另外,ChatGPT的成功已经证明了causal decoder结构的大语言模型可以获得非常好的few-shot和zero-shot生成能力,通过指令微调可以进一步激发模型的能力。至于prefix decoder结构的大语言模型能否获得相当的few-shot和zero-shot能力还缺少足够的验证。
- 训练时对一个完整的单词做Mask,这样可以避免 一个单词被拆分成多个Tokens,然后根据自己推测自己
- tokenizer:关于tokenizer,ChatGLM在25GB的中英双语数据上训练了SentencePiece作为tokenizer,词表大小为130528。
下面是一些基于ChatGLM衍生出来的大模型应用:
- langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答。
- 闻达:大型语言模型调用平台,基于 ChatGLM-6B 实现了类 ChatPDF 功能。
BLOOM
BLOOM[5]系列模型是由BigScience团队训练的大语言模型。训练数据包含了英语、中文、法语、西班牙语、葡萄牙语等共46种语言,另外还包含13种编程语言。1.5TB经过去重和清洗的文本,转换为350B的tokens。训练数据的语言分布如下图所示,可以看到中文语料占比为16.2%。
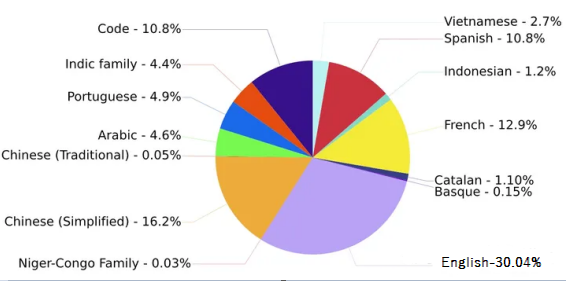
按照模型参数量,BLOOM模型有560M、1.1B、1.7B、3B、7.1B和176B这几个不同参数规模的模型。BLOOMZ系列模型是在xP3数据集上微调得到的,推荐用于英语提示的场景。BLOOMZ-MT系列模型是在xP3mt数据集上微调得到的,推荐用于非英语提示的场景。
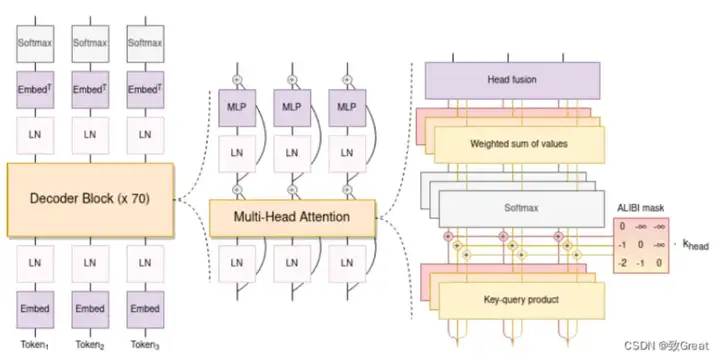
模型结构上,与GPT相同,BLOOM采用了causal decoder-only的transformer模型结构。在模型细节上,做了以下几点改动:
- 使用 ALiBi 位置嵌入,它根据键和查询的距离直接衰减注意力分数。与原始的 Transformer 和 Rotary 嵌入相比,它可以带来更流畅的训练和更好的下游性能。ALiBi不会在词嵌入中添加位置嵌入;相反,它会使用与其距离成比例的惩罚来偏向查询键的注意力评分。
- Embedding Layer Norm 在第一个嵌入层之后立即使用,以避免训练不稳定。
- layer normalization:为了提升训练的稳定性,没有使用传统的post layer norm,而是使用了pre layer Norm。
- 激活函数:采用了GeLU激活函数。
- 关于tokenizer,BLOOM在多语种语料上使用Byte Pair Encoding(BPE)算法进行训练得到tokenizer,词表大小为250880。使用了 25 万个标记的词汇表。使用字节级 BPE。这样,标记化永远不会产生未知标记
- 全连接层:
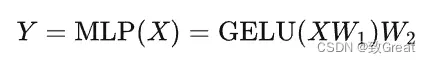
- 在训练目标上,BLOOM的训练目标是语言模型,即根据已有的上文去预测下一个词。
下面是一些基于BLOOM衍生出来的大模型应用:
- 轩辕: 金融领域大模型,度小满在BLOOM-176B的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调。
- BELLE: 链家仅使用由ChatGPT生产的数据,对BLOOMZ-7B1-mt进行了指令微调。
tokenizer比较
以上几个基座模型的tokenizer的词表大小不同,对同一个中文文本的分词结果会产生不同的结果。在news_commentary的6.9万条中英文平行语料上进行分词处理,对比分词结果和分词耗时,结果如下。“中文平均token数”表示了tokenizer分词后,每个中文字符对应的平均token数。
| 模型 | 词表大小 | 中文平均token数 | 英文平均token数 | 中文处理时间(s) | 英文处理时间(s) |
|---|---|---|---|---|---|
| LLaMA | 32000 | 1.45 | 0.25 | 12.60 | 19.40 |
| Chinese LLaMA | 49953 | 0.62 | 0.249 | 8.65 | 19.12 |
| ChatGLM-6B | 130528 | 0.55 | 0.19 | 15.91 | 20.84 |
| Bloom | 250880 | 0.53 | 0.22 | 9.87 | 15.60 |
从结果来看,
- LLaMA的词表是最小的,LLaMA在中英文上的平均token数都是最多的,这意味着LLaMA对中英文分词都会比较碎,比较细粒度。尤其在中文上平均token数高达1.45,这意味着LLaMA大概率会将中文字符切分为2个以上的token。
- Chinese LLaMA扩展词表后,中文平均token数显著降低,会将一个汉字或两个汉字切分为一个token,提高了中文编码效率。
- ChatGLM-6B是平衡中英文分词效果最好的tokenizer。由于词表比较大,中文处理时间也有增加。
- BLOOM虽然是词表最大的,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。需要注意的是,BLOOM的tokenizer用了transformers的BloomTokenizerFast实现,分词速度更快。
从两个例子上,来直观对比不同tokenizer的分词结果。“男儿何不带吴钩,收取关山五十州。”共有16字。几个tokenizer的分词结果如下:
- LLaMA分词为24个token:(看着像是在Unicode编码级别做的BPE)
[ '男', '<0xE5>', '<0x84>', '<0xBF>', '何', '不', '<0xE5>', '<0xB8>', '<0xA6>', '<0xE5>', '<0x90>', '<0xB4>', '<0xE9>', '<0x92>', '<0xA9>', ',', '收', '取', '关', '山', '五', '十', '州', '。']- Chinese LLaMA分词为14个token:
[ '男', '儿', '何', '不', '带', '吴', '钩', ',', '收取', '关', '山', '五十', '州', '。']- ChatGLM-6B分词为11个token:
[ '男儿', '何不', '带', '吴', '钩', ',', '收取', '关山', '五十', '州', '。']- Bloom分词为13个token:
['男', '儿', '何不', '带', '吴', '钩', ',', '收取', '关', '山', '五十', '州', '。']“杂申椒与菌桂兮,岂维纫夫蕙茝。”的长度为15字。几个tokenizer的分词结果如下:
- LLaMA分词为37个token:
[ '<0xE6>', '<0x9D>', '<0x82>', '<0xE7>', '<0x94>', '<0xB3>', '<0xE6>', '<0xA4>', '<0x92>', '与', '<0xE8>', '<0x8F>', '<0x8C>', '<0xE6>', '<0xA1>', '<0x82>', '<0xE5>', '<0x85>', '<0xAE>', ',', '<0xE5>', '<0xB2>', '<0x82>', '<0xE7>', '<0xBB>', '<0xB4>', '<0xE7>', '<0xBA>', '<0xAB>', '夫', '<0xE8>', '<0x95>', '<0x99>', '<0xE8>', '<0x8C>', '<0x9D>', '。']- Chinese LLaMA分词为17个token:
[ '杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '纫', '夫', '蕙', '<0xE8>', '<0x8C>', '<0x9D>', '。']- ChatGLM-6B分词为17个token:
[ '杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '纫', '夫', '蕙', '<0xE8>', '<0x8C>', '<0x9D>', '。']- Bloom分词为17个token:
['杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '夫', '蕙', '。']从上面的例子可以看到,LLaMA词表中包含了极少数的中文字符,常见字“儿”也被切分为了3个token。Chinese LLaMA、ChatGLM-6B和Bloom的词表中则覆盖了大部分中文常见字,另外也包含了一些中文常用词,比如都把“收取”这个词切分为了一个token;对于一些生僻词,比如“茝”也会切分为2-3个token。总的来说,LLaMA通常会将一个中文汉字切分为2个以上的token,中文编码效率低;Chinese LLaMA、ChatGLM-6B和Bloom对中文分词的编码效率则更高。
Layer Normalization
如下图所示,按照layer normalization的位置不同,可以分为post layer norm和pre layer norm。
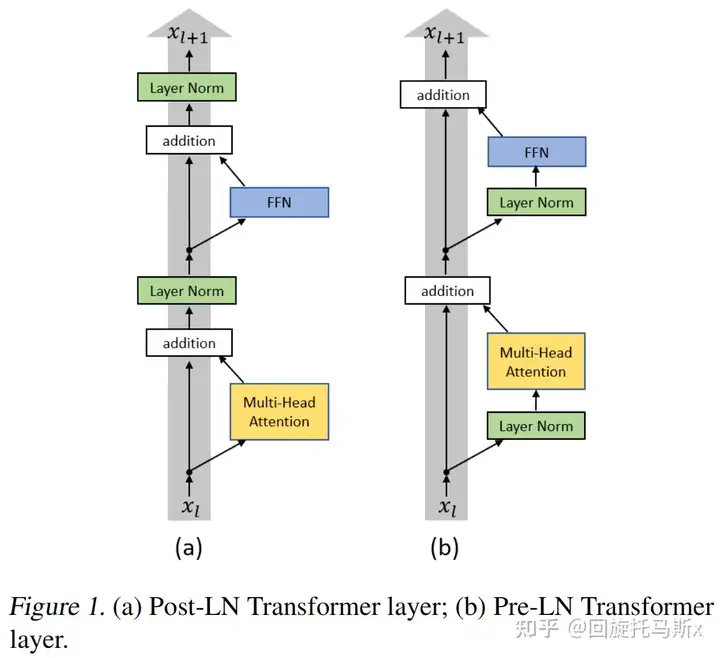
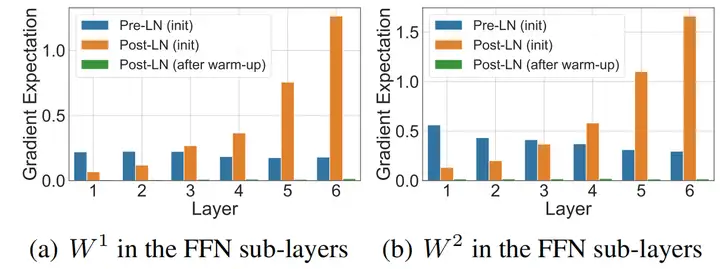
post layer norm。在原始的transformer中,layer normalization是放在残差连接之后的,称为post LN。使用Post LN的深层transformer模型容易出现训练不稳定的问题。如下图所示,post LN随着transformer层数的加深,梯度范数逐渐增大,导致了训练的不稳定性。
pre layer norm。改变layer normalization的位置,将其放在残差连接的过程中,self-attention或FFN块之前,称为“Pre LN”。如下图所示,Pre layer norm在每个transformer层的梯度范数近似相等,有利于提升训练稳定性。相比于post LN,使用pre LN的深层transformer训练更稳定,可以缓解训练不稳定问题。但缺点是pre LN可能会轻微影响transformer模型的性能 大语言模型的一个挑战就是如何提升训练的稳定性。为了提升训练稳定性,GPT3、PaLM、BLOOM、OPT等大语言模型都采用了pre layer norm。
layer normalization重要的两个部分是平移不变性和缩放不变性。 [8]认为layer normalization取得成功重要的是缩放不变性,而不是平移不变性。因此,去除了计算过程中的平移,只保留了缩放,进行了简化,提出了RMS Norm(Root Mean Square Layer Normalization),即均方根norm。
layer normalization的计算过程:
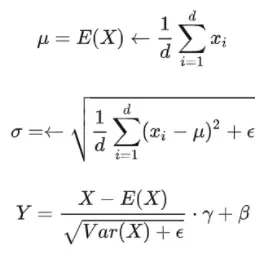
RMS计算过程:
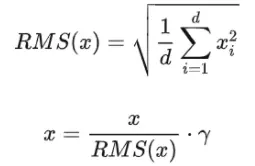
相比于正常的layer normalization,RMS norm去除了计算均值进行平移的部分,计算速度更快,效果基本相当,甚至略有提升。Gopher、LLaMA、T5等大语言模型都采用了RMS norm。
[9]提出了Deep Norm可以缓解爆炸式模型更新的问题,把模型更新限制在常数,使得模型训练过程更稳定。具体地,Deep Norm方法在执行Layer Norm之前,up-scale了残差连接(\alpha>1);另外,在初始化阶段down-scale了模型参数(\beta<1)。ChatGLM-6B采用了基于Deep Norm的post LN。
激活函数
每个transformer层分为self attention块和FFN块两部分。FFN通常先将向量从维度d升维到中间维度4d,再从4d降维到d。FFN的计算公式如下:
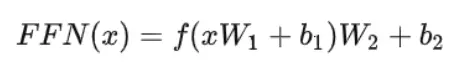
其中,f()为非线性激活函数。广泛使用的激活函数有gelu(Gaussian Error Linear Unit)函数和swish函数。swish函数是一种自门控激活函数。
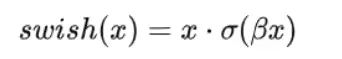
gelu也是一种通过门控机制调整输出值的激活函数,与swish函数类似,可以用tanh函数或 \sigma函数近似。
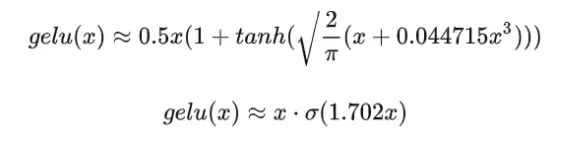
[10]提出了门控线形单元GLU(Gated Linear Units),相比于正常的FFN只有两个权重矩阵,使用GLU的FFN额外增加了一个权重矩阵,即下式中的V,共有三个权重矩阵,获得了更好的模型性能。
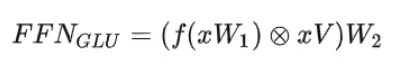
使用gelu激活函数的GLU计算公式为:
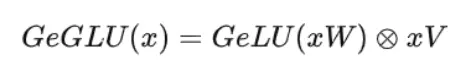
使用swish激活函数的GLU计算公式为:
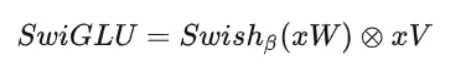
位置编码
对于transformer模型,位置编码是必不可少的。因为attention模块是无法捕捉输入顺序的,无法区分不同位置的token。位置编码分为绝对位置编码和相对位置编码。
最直接的方式是训练式位置编码,将位置编码当作可训练参数,训练一个位置编码向量矩阵。GPT3就采用了这种方式。训练式位置编码的缺点是没有外推性,即若训练时最大序列长度为2048,在推断时最多只能处理长度为2048的序列,超过这个长度就无法处理了。
苏神[11]提出了旋转位置编码RoPE。训练式的位置编码作用在token embedding上,而旋转位置编码RoPE作用在每个transformer层的self-attention块,在计算完Q/K之后,旋转位置编码作用在Q/K上,再计算attention score。旋转位置编码通过绝对编码的方式实现了相对位置编码,有良好的外推性。值得一提的是,RoPE不包含可训练参数。LLaMA、GLM-130B、PaLM等大语言模型就采用了旋转位置编码RoPE。
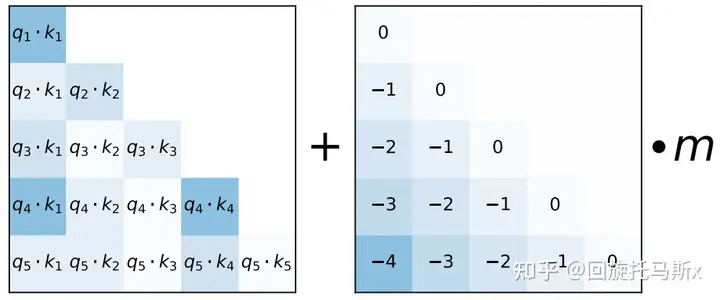
ALiBi(Attention with Linear Biases)[12]也是作用在每个transformer层的self-attention块,如下图所示,在计算完attention score后,直接为attention score矩阵加上一个预设好的偏置矩阵。这里的偏置矩阵是预设好的,固定的,不可训练。这个偏置根据q和k的相对距离来惩罚attention score,相对距离越大,惩罚项越大。相当于两个token的距离越远,相互贡献就越小。ALiBi位置编码有良好的外推性。BLOOM就采用了这种位置编码。
高效参数微调方法 PEFT
随着大语言模型的参数量越来越大,进行大模型的全量微调成本很高。高成本主要体现在硬件资源要求高,显存占用多;训练速度慢,耗时长;存储成本高。高效参数微调(parameter-efficient finetuning techniques,PEFT)在微调大模型时只训练一小部分参数,而不是训练全量多模型参数。高效参数微调方法有以下几方面优点:
- 显存占用少,对硬件资源要求低
- 训练速度快,耗时更短
- 更低的存储成本,不同的任务可以共享大部分的权重参数
- 可能会有更好的模型性能,减轻了过拟合问题
prompt tuning
prompt tuning[13]原本的含义指的是通过修改输入prompt来获得更好的模型效果。这里的提示是“硬提示(hard prompt)”。我们直接修改输入prompt,输入prompt是不可导的。
与“硬提示”相对应,“软提示微调(soft prompt tuning)”将一个可训练张量与输入文本的embeddings拼接起来,这个可训练张量可以通过反向传播来优化,进而提升目标任务的模型效果。这里的可训练张量可以理解为prompt文本对应的embedding,是一个soft prompt。如下图所示,这个可训练张量的形状是[virtal_tokens_sum,embed_size]
prompt tuning冻结大模型原始的参数,只训练这个新增加的prompt张量。prompt tuning随着基座模型参数量的增大效果会变好。
prefix tuning
prefix tuning[14]与prompt tuning相似,将一个特定任务的张量添加到输入,这个张量是可训练的,保持预训练模型的参数不变。主要区别如下:
- prefix tuning将prefix参数(可训练张量)添加到所有的transformer层,而prompt tuning只将可训练矩阵添加到输入embedding。具体地,prefix tuning会将prefix张量作为past_key_value添加到所有的transformer层。
- 用一个独立的FFN来编码和优化prefix参数,而不是直接优化soft prompt,因为它可能造成不稳定并损害性能。在更新完soft prompt后,就不再使用FFN了。
prefix tuning与prompt tuning的作用位置不同,有点类似于可训练式位置编码和旋转位置编码RoPE。前者是直接作用在输入embedding上,后者是作用在所有transformer层的self-attention块,在计算得到K和V后,与可训练的prefix张量拼接起来。
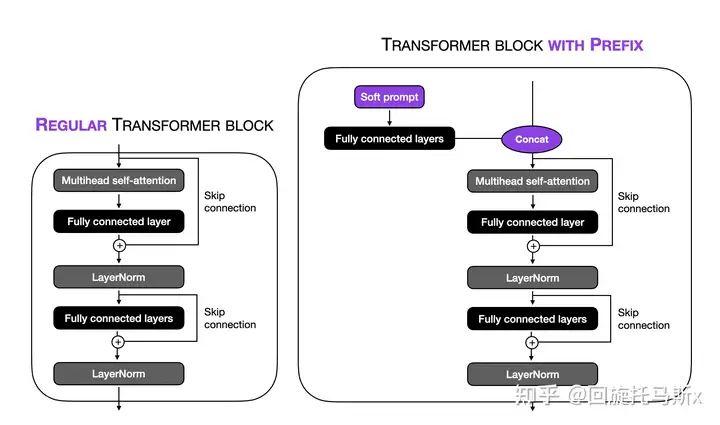
prefix tuning可训练张量的形状是 [virtual\_tokens\_num,2\times layer\_num \times hidden\_size]。下图是LLaMA-7B进行prefix tuning的例子,LLaMA-7B有32个transformer层,隐藏维度为4096,有 30,262144=2\times 32 \times 4096。30对应虚拟词数量,这里的2对应的是K和V。
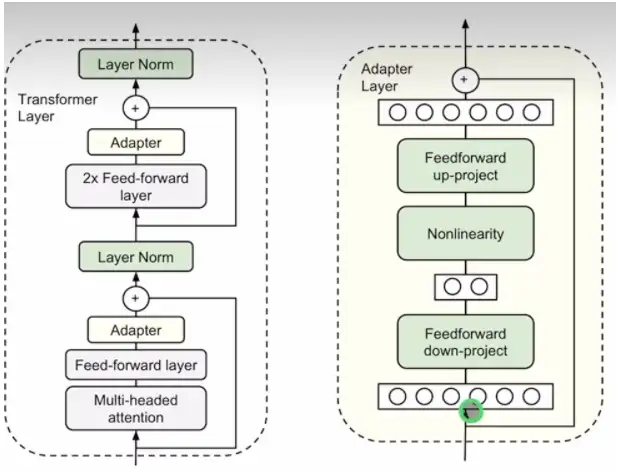
Adapter
adapter[16]在某种程度上与prefix tuning是类似的,二者都是把额外的可训练参数添加到每个transformer层。不同之处是:prefix tuning是把prefix添加到输入embedding;而adapter在两个位置插入了adapter 层,如下图所示。

LLaMA-Adapter
LLaMA-adapter[16]结合了prefix tuning和adapter。与prefix tuning类似,LLaMA-adapter在输入embed上添加了可训练的prompt张量。需要注意的是:prefix是以一个embedding矩阵学习和保持的,而不是外部给出的。每个transformer层都有各自不同的可学习prefix,允许不同模型层进行更量身定制的适应。
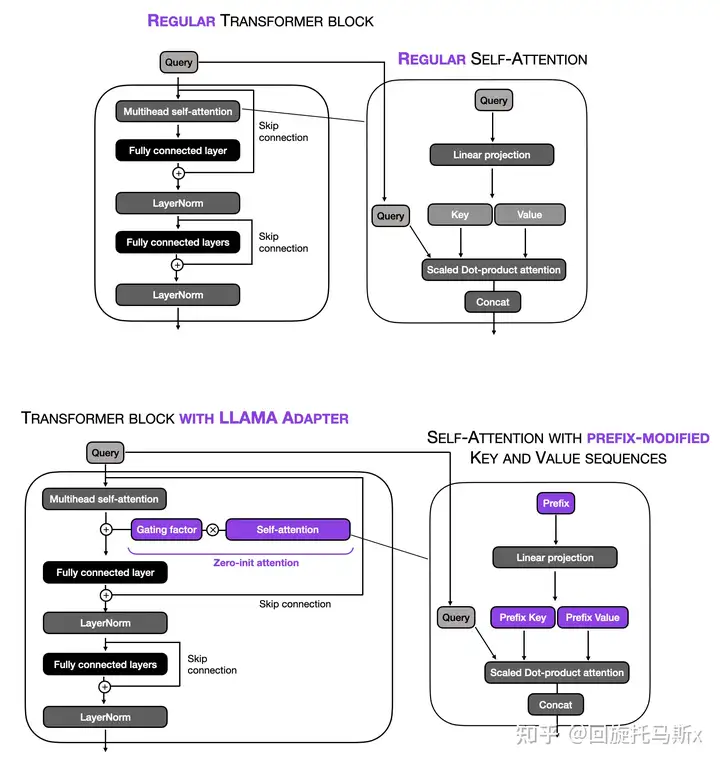
如上图所示,LLaMA-adapter引进了零初始化的注意力机制和门控机制。动机是adapter和prefix tuning结合了随机初始化的张量(prefix prompts和adapter layers)很大可能会损害预训练语言模型的语义学知识,导致在训练初始阶段的微调不稳定和很高的性能损失。
另一个重要的区别是,LLaMA-adapter只给L个深层transformer层添加了可学习的adaption prompts,而不是给所有的transformer层都添加。作者认为,这种方法可以更有效的微调专注于高级语义信息的语言表示。
再重复补充一些Efficient PEFT
1-Adapter-2019
思路是在Transformer Block里加入一些小层Adapter
Adapter是紧跟其他组件后面的,又做了特征缩减,可能会导致模型表达能力降低(不如Lora)
2-Prompt Tuning
手工Prompt叫Hard Prompt,需要先验知识
来学Prompt,用Soft Prompt
模型锁住,在Prompt添加一些可学习的vector prompt,让模型去调整这些vector使得可以对各种任务都有提升,当然每个任务有各自的可学习prompt
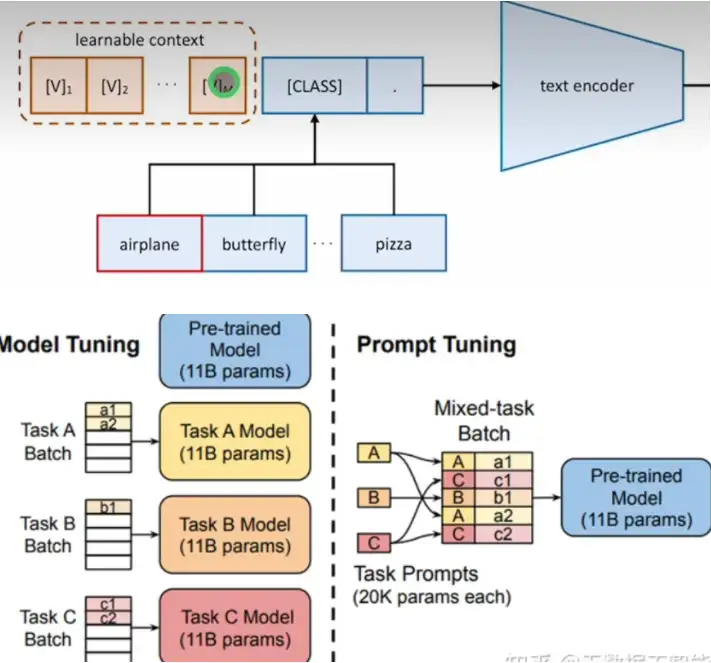
固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。左图为单任务全参数微调,右图为prompt tuning。
Prefix Tuning
prefix tuning依然是固定预训练参数,但除为每一个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)P-Tuning v1-v2
P-Tuning v1,用LSTM对Prompt进行编码
- 相比prefix-tuning,这里加了可微的virtual token,但是仅限于输入,没有在每层加;另外virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。
- 优化这种virtual token的挑战:经过预训练的LM的词嵌入已经变得高度离散,如果随机初始化virtual token,容易优化到局部最优值;这些virtual token理论是应该有相关关联的,如何建模这种关联也是问题。当然实际在实验中,作者发现的是用一个prompt encoder来编码收敛更快,效果更好。也就是说,用一个LSTM+MLP去编码这些virtual token以后,再输入到模型
- 作者还发现其实可以加一些anchor token,比如文本蕴含任务:输入是前提和假设,判断是否蕴含。一个连续化的模版是:【前提的输入】【continuous tokens】【假设的输入】【continuous tokens】【MASK】,作者提出加一个anchor token:【?】效果会更好,也就是【前提的输入】【continuous tokens】?【假设的输入】【continuous tokens】【MASK】
- 至于continuous tokens插入位置,token的数量是多少,应该也有影响,作者这里采用的是用3个continuous token去分割开多个输入,比如上面这里文本蕴含的例子。
P-Tuning v2
- Deep Prompt Tuning on NLU
- 采用Prefix-tuning的做法,在输入前面的每层加入可微调的参数
- 去掉重参数化的编码器
- 以前的方法利用重参数化功能来提高训练速度和鲁棒性(例如,用于prefix-tunning的 MLP 和用于 P-tuning的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现
- 可选的多任务学习
- Deep Prompt Tuning的优化难题可以通过增加额外的任务数据或者无标注数据来缓解,同时可微调的prefix continuous prompt也可以用来做跨任务的共享知识。比如说,在NER中,可以同时训练多个数据集,不同数据集使用不同的顶层classifer,但是prefix continuous prompt是共享的
- 回归传统的CLS和token label classifier
- 主要是为了解决一些没有语义的标签的问题
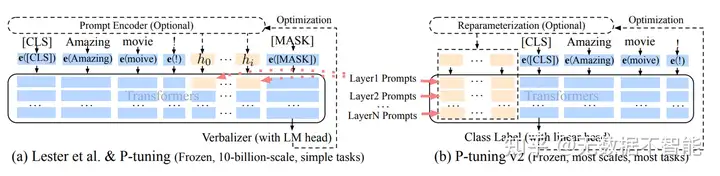

Prefix,Prompt,P-Tuning 的区别
Prefix最早,把control code换成虚拟Token,每个任务对应一些虚拟Token,且只放在句首,使用MLP先做一层转换
Prompt Tuning是Prefix Tuning的简化版本,使用100个prefix token,只对Embedding微调,丢掉MLP
P-Tuning v1使用双向LSTM+两层MLP做prompt变换,这样模型更新的是LSTM+MLP部分
P-Tuning v2在每层都加入可学习prompt vector,这里加入的prompt是在预训练模型之外的,相当于每一层的输出传递到下一层时,前面加上了length*embedding dimension的几个向量,模型计算attention会利用这些prompt,但是prompt本身不会计算后面的句子去输出结果,只是每一层都加在前面,所以总的可训练的参数量是number of layers * prompt length * embedding dimensions
对视觉端添加Prompt
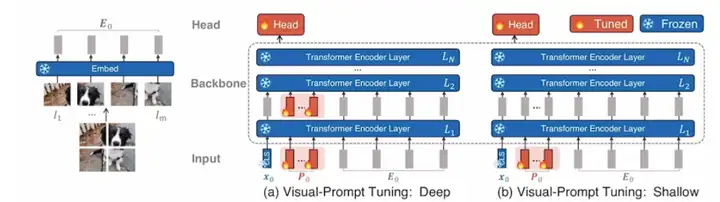
把图片当成文本看待
VPT shallow只在prompt看待,
deep就是prefix tuning,每一层Transformer都加入一些可学习的Vector,这个Vector只作为输入,不是别人的输出
Lora
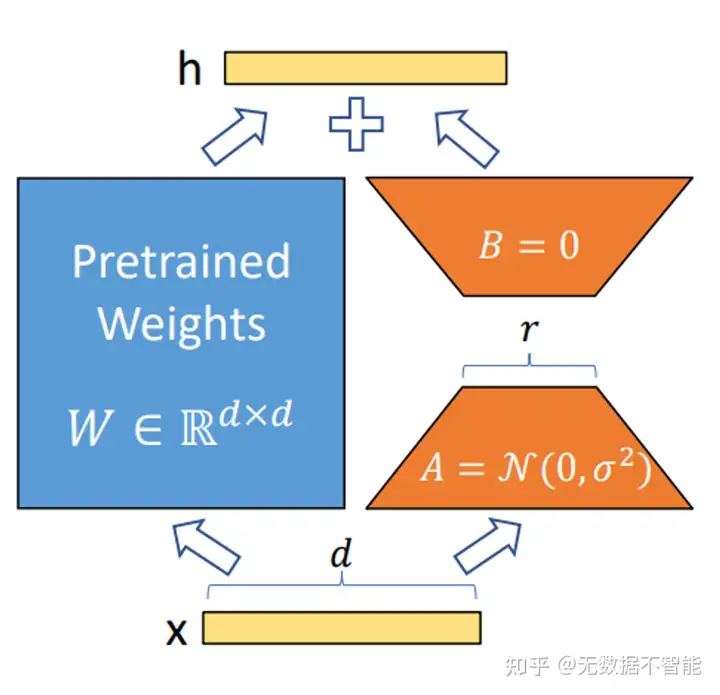
LoRA冻结了预训练模型的参数,并在每一层decoder中加入dropout+Linear+Conv1d额外的参数
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)AdaLoRA
20230318
预训练语言模型中的不同权重参数对下游任务的贡献是不同的。因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。
具体来说,通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
后记
为什么用Decoder only
LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
众所周知,Attention矩阵一般是由一个低秩分解的矩阵加softmax而来,具体来说是一个 n × d 的矩阵与 d × n 的矩阵相乘后再加softmax(n ≫ d ),这种形式的Attention的矩阵因为低秩问题而带来表达能力的下降,具体分析可以参考《Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth》。而Decoder-only架构的Attention矩阵是一个下三角阵,注意三角阵的行列式等于它对角线元素之积,由于softmax的存在,对角线必然都是正数,所以它的行列式必然是正数,即Decoder-only架构的Attention矩阵一定是满秩的!满秩意味着理论上有更强的表达能力,也就是说,Decoder-only架构的Attention矩阵在理论上具有更强的表达能力,改为双向注意力反而会变得不足。
prefix LM和causal LM的区别?
attention mask不同,前者的prefix部分的token互相能看到,后者严格遵守只有后面的token才能看到前面的token的规则。
ChatGLM-6B[1] prefix LM
LLaMA-7B[2] causal LM
GPT系列就是Causal LM,目前除了T5和GLM,其他大模型基本上都是Causal LM。
说一下LLM常见的问题?
出现复读机问题。
比如:ABCABCABC不断循环输出到max length。
对于这种现象我有一个直观的解释(猜想):prompt部分通常很长,在生成文本时可以近似看作不变,那么条件概率 P(B|A)也不变,一直是最大的。
生成重复内容,是语言模型本身的一个弱点,无论是否微调,都有可能出现。并且,理论上良好的指令微调能够缓解大语言模型生成重复内容的问题。[3]但是因为指令微调策略的问题,在实践中经常出现指令微调后复读机问题加重的情况。
另外,可能出现重复用户问题的情况,原因未知。
如何缓解复读机问题?
解码方式里增加不确定性,既然容易复读那我们就增加随机性,开启do_sample选项,调高temperature。
如果学的太烂,do_sample也不顶用呢?加重复惩罚,设置repetition_penalty,注意别设置太大了。不然你会发现连标点符号都不会输出了。
llama 输入句子长度理论上可以无限长吗?
这里引用苏神(RoPE作者)在群里的回复。
限制在训练数据。理论上rope的llama可以处理无限长度,但问题是太长了效果不好啊,没训练过的长度效果通常不好。而想办法让没训练过的长度效果好,这个问题就叫做“长度外推性”问题。
所以接受2k的长度限制吧。
为什么大模型推理时显存涨的那么多还一直占着?
首先,序列太长了,有很多Q/K/V。
其次,因为是逐个预测next token,每次要缓存K/V加速解码。
大模型大概有多大,模型文件有多大?
一般放出来的模型文件都是fp16的,假设是一个 n B的模型,那么模型文件占 2n G,fp16加载到显存里做推理也是占 2n G,对外的pr都是 10n 亿参数的模型。
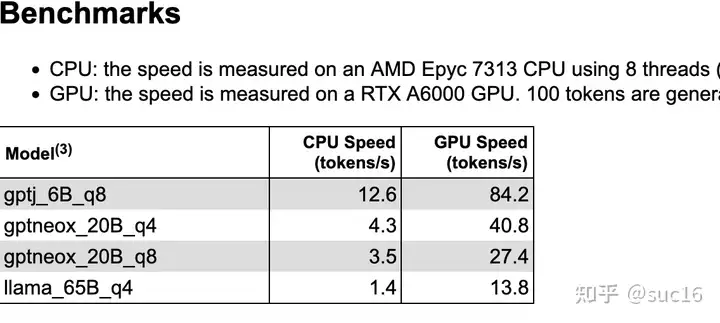
大模型在gpu和cpu上推理速度如何?
7B量级下,cpu推理速度约10token/s,单卡A6000和8核AMD的推理速度通常为 10:1。[5]
能否用4 * v100 32G训练vicuna 65b?
不能。
首先,llama 65b的权重需要5* v100 32G才能完整加载到GPU。
其次,vicuna使用flash-attention加速训练,暂不支持v100,需要turing架构之后的显卡。
(刚发现fastchat上可以通过调用train脚本训练vicuna而非train_mem,其实也是可以训练的)
V100下不要进行 8bit 模式的训练,alpaca_lora的复现上很多人遇到了loss突变为0的bug。
如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
一般 n B的模型,最低需要 16-20 n G的显存。(cpu offload基本不开的情况下)
vicuna-7B为例,官方样例配置为 4*A100 40G,测试了一下确实能占满显存。(global batch size 128,max length 2048)当然训练时用了FSDP、梯度累积、梯度检查点等方式降显存。
推理速度上,int8和fp16比起来怎么样?
根据实践经验,int8模式一般推理会明显变慢(huggingface的实现)
如果就是想要试试65b模型,但是显存不多怎么办?
最少大概50g显存,可以在llama-65b-int4(gptq)模型基础上LoRA[6],当然各种库要安装定制版本的。
LoRA权重是否可以合入原模型?
可以,将训练好的低秩矩阵(B*A)+原模型权重合并(相加),计算出新的权重。
ChatGLM-6B LoRA后的权重多大?
rank 8 target_module query_key_value条件下,大约15M。
SFT(有监督微调)的数据集格式?
一问一答
RM(奖励模型)的数据格式?
一个问题 + 一条好回答样例 + 一条差回答样例
PPO(强化学习)的数据格式?
理论上来说,不需要新增数据。需要提供一些prompt,可以直接用sft阶段的问。另外,需要限制模型不要偏离原模型太远(ptx loss),也可以直接用sft的数据。
奖励模型需要和基础模型一致吗?
不同实现方式似乎限制不同。(待实践确认)colossal-ai的coati中需要模型有相同的tokenizer,所以选模型只能从同系列中找。在ppo算法实现方式上据说trlx是最符合论文的。
如何给LLM注入领域知识?
第一种办法,检索+LLM,先用问题在领域数据库里检索到候选答案,再用LLM对答案进行加工。
第二种方法,把领域知识构建成问答数据集,用SFT让LLM学习这部分知识。[7]
为什么SFT之后感觉LLM傻了?
- SFT的重点在于激发大模型的能力,SFT的数据量一般也就是万恶之源alpaca数据集的52k量级,相比于预训练的数据还是太少了。如果抱着灌注领域知识而不是激发能力的想法,去做SFT的话,可能确实容易把LLM弄傻。
- 指令微调是为了增强(或解锁)大语言模型的能力。
其真正作用:
指令微调后,大语言模型展现出泛化到未见过任务的卓越能力,即使在多语言场景下也能有不错表现 。微调数据集:
应该选择多个有代表性的任务,每个任务实例数量不应太多(比如:数百个)否则可能会潜在地导致过拟合问题并影响模型性能 。
同时,应该平衡不同任务的比例,并且限制整个数据集的容量(通常几千或几万),防止较大的数据集压倒整个分布。
如果想要快速体验各种模型,该怎么办?
推荐fastchat,集成了各路开源模型,从自己的vicuna到stable AI的stableLM。
找数据集哪里找?
推荐Alpaca-COT,数据集整理的非常全,眼花缭乱。
转载ChatGLM2微调的几个常见问题
1. torch>=2.0, 否则微调会报很多错误(单纯推理可以用低版本);
2. tokenizer.encode输出为 [gMASK, sop, 真实文本token]
64789 = {str} '[MASK]'
64790 = {str} '[gMASK]'
64791 = {str} '[sMASK]'
64792 = {str} 'sop'
64793 = {str} 'eop'
3. modeling_chatglm.py自带get_masks()的代码full_attention_mask -= padding_mask.unsqueeze(-1) - 1改为
full_attention_mask = full_attention_mask.long() - padding_mask.unsqueeze(-1).long() - 1
4. 不支持gradient_checkpointing, 修复的话需要modeling_chatglm.py新增get_input_embeddings, set_input_embeddings;
5. modeling_chatglm.py中的ChatGLMForConditionalGeneration类forward函数中的
if full_attention_mask is None: 前加入 batch_size, seq_length = input_ids.shape
6. get_mask(), 一直以来都对chatglm的mask/position有一些疑惑;
def get_masks(seq, bos_token_id):
""" code from model_chatglm.py """
if seq.count(bos_token_id) == 2:
context_length = seq[2:].index(bos_token_id) + 2
else:
context_length = seq.index(bos_token_id)
attention_mask = torch.ones((1, len(seq), len(seq)))
attention_mask.tril_()
attention_mask[..., :context_length] = 1
# attention_mask.unsqueeze_(1)
attention_mask = (attention_mask < 0.5).bool()
return attention_mask
7. 严格按照官方prompt构建输入输出:
输入:"[Round 1]\n\n问:{}\n\n答:"
输出:"{}"
输入id: [gMASK, BOS, 输入tokens]
输出id: [gMASK, BOS, 输出tokens, EOS]如何应对LLM微调过程中的“灾难性遗忘”问题?
1. teacher-student training,训练的时候损失函数用teacher的输出与真实标注一起:
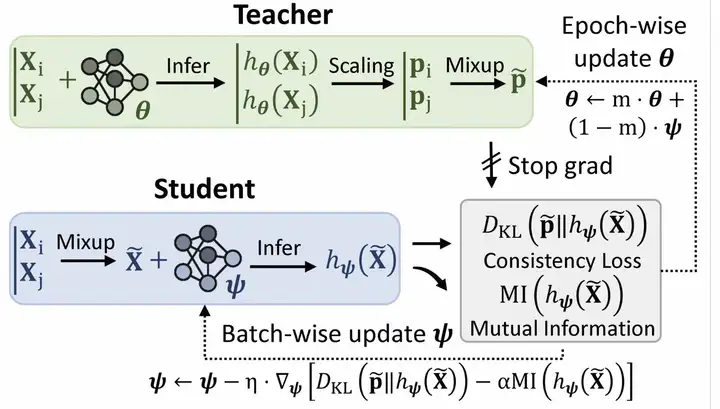
2. 在微调时,混入一些正常的对话语料,作为正则项约束大模型不要过拟合。最好是与微调目标比较相关相似的预料。
声明:
文章的很多内容来自站内站外,这篇文章整理出来是为了自己学习记录所用,分享自己的心得如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款免费的人工智能电子邮件助手,适用于时间紧迫的专业人士。使用 Scribbly 创建电子邮件的速度可以提高 10 倍,这要归功于听起来与您一样的特定于上下文的内容推荐。